系列文章目录
【模型部署】人脸检测模型DBFace C++ ONNXRuntime推理部署(0)
【模型部署】人脸检测模型DBFace C++ ONNXRuntime推理部署(1)
【模型部署】人脸检测模型DBFace C++ ONNXRuntime推理部署(2)
文章目录
- 系列文章目录
- 1 C++推理流程
- 2 关键API介绍
- 3 DBFace推理C++代码展示
- 4 推理结果及比较
- 参考资料
在实际应用中,由于语言的特性,通常选择C++环境进行部署,从而更快地得到推理结果。上一篇博客中已经介绍了ONNX模型转换以及Python环境下的ONNXRuntime推理,而本篇博客将分享C++环境下的ONNXRuntime推理部署流程和关键API,并以DBFace模型为例进行展示。
1 C++推理流程
C++环境下的推理并不像Python那样简单易操作,它需要先定义好相关的环境变量,并通过相应的API从ONNX模型得到节点信息,从而分配内存并创建输入输出Tensor,最后进行推理运算,基本流程及所用的API如下图所示。

2 关键API介绍
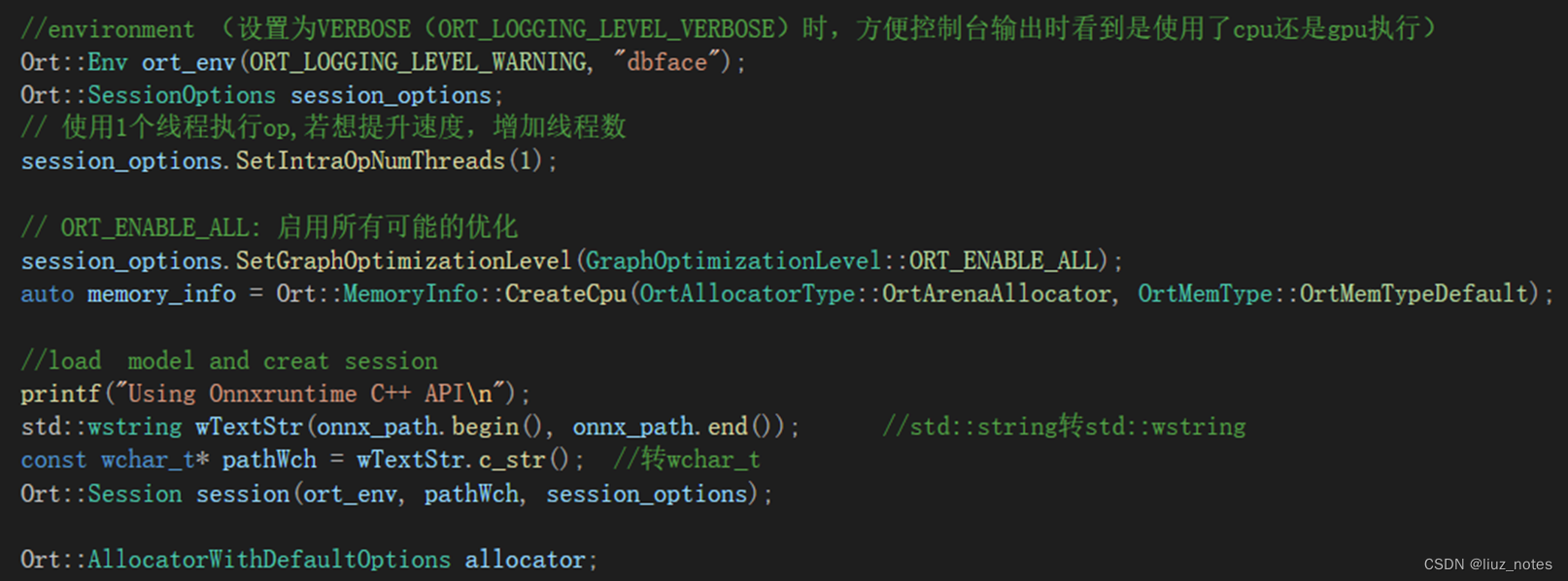
首先创建环境变量并设置好Session选项,所有的API都封装在Ort这个类中。Ort::Env只是用来设置日志级别以及日志输出文件,而关键的设置在Ort::SessionOptions & Ort::Session。
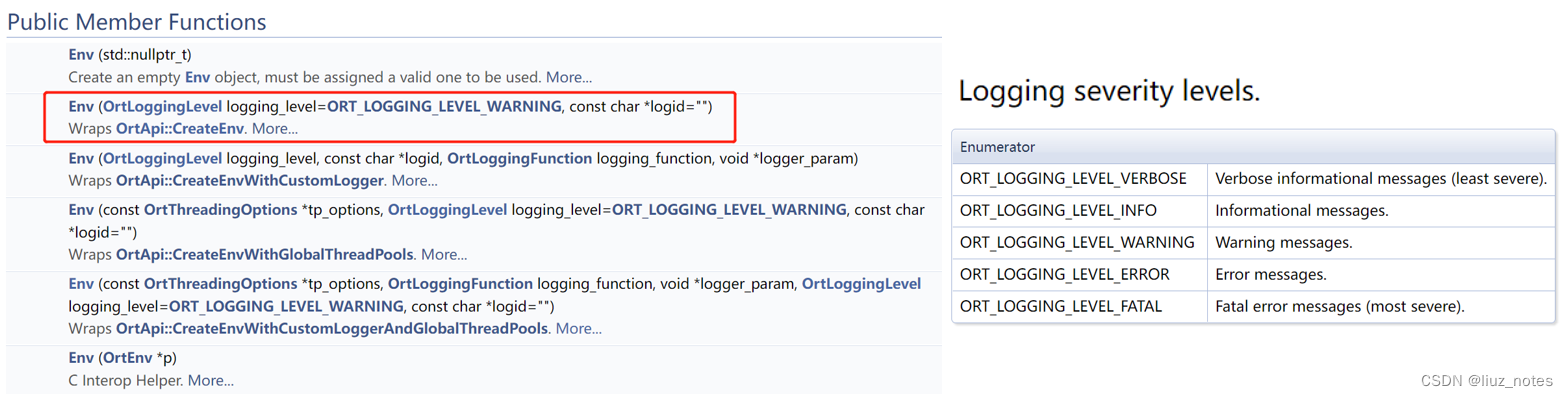
设置运行的线程数和计算图优化级别,以及模型的路径。
Ort::Env ort_env(ORT_LOGGING_LEVEL_WARNING, “default");
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(1);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
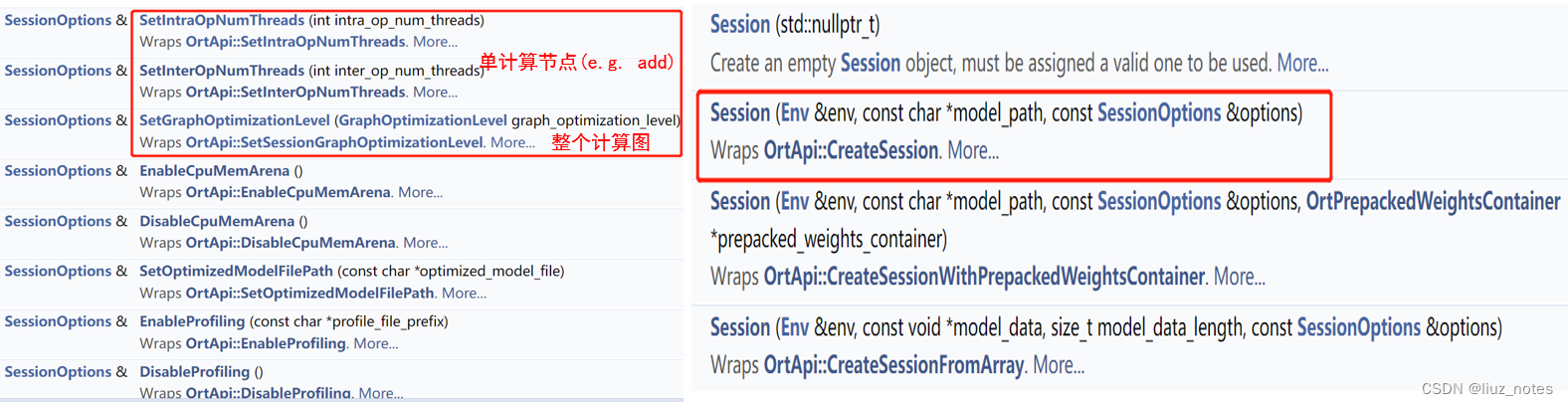
Ort::Session session(ort_env, pathWch, session_options);
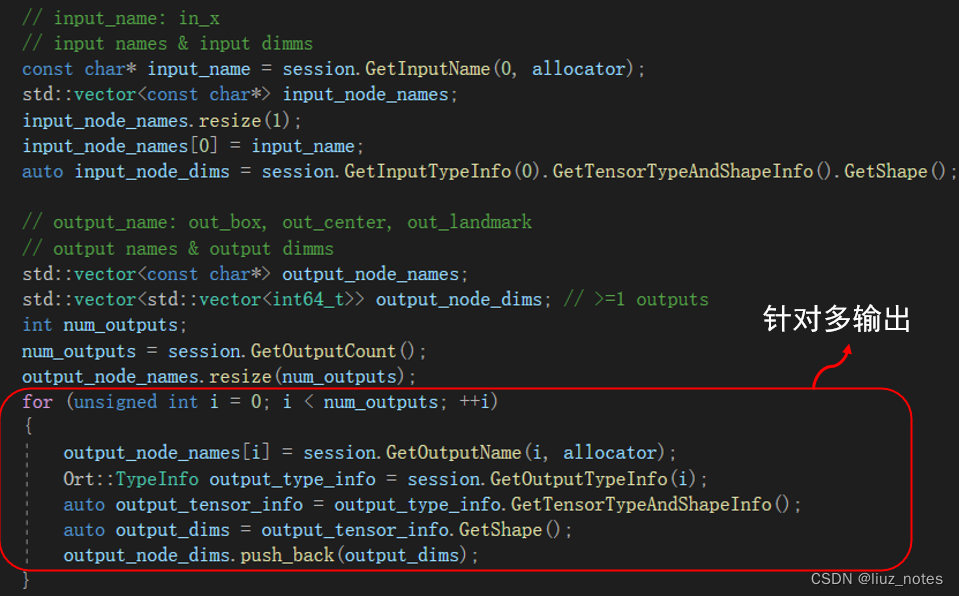
然后通过以下API得到输入输出节点信息。

Ort::AllocatorWithDefaultOptions allocator;
const char* input_name = session.GetInputName(0, allocator);
auto input_info = session.GetInputTypeInfo(0).GetTensorTypeAndShapeInfo();
auto input_node_dims = input_info.GetShape();
根据得到的输入输出节点信息,创建Tensor并分配内存。
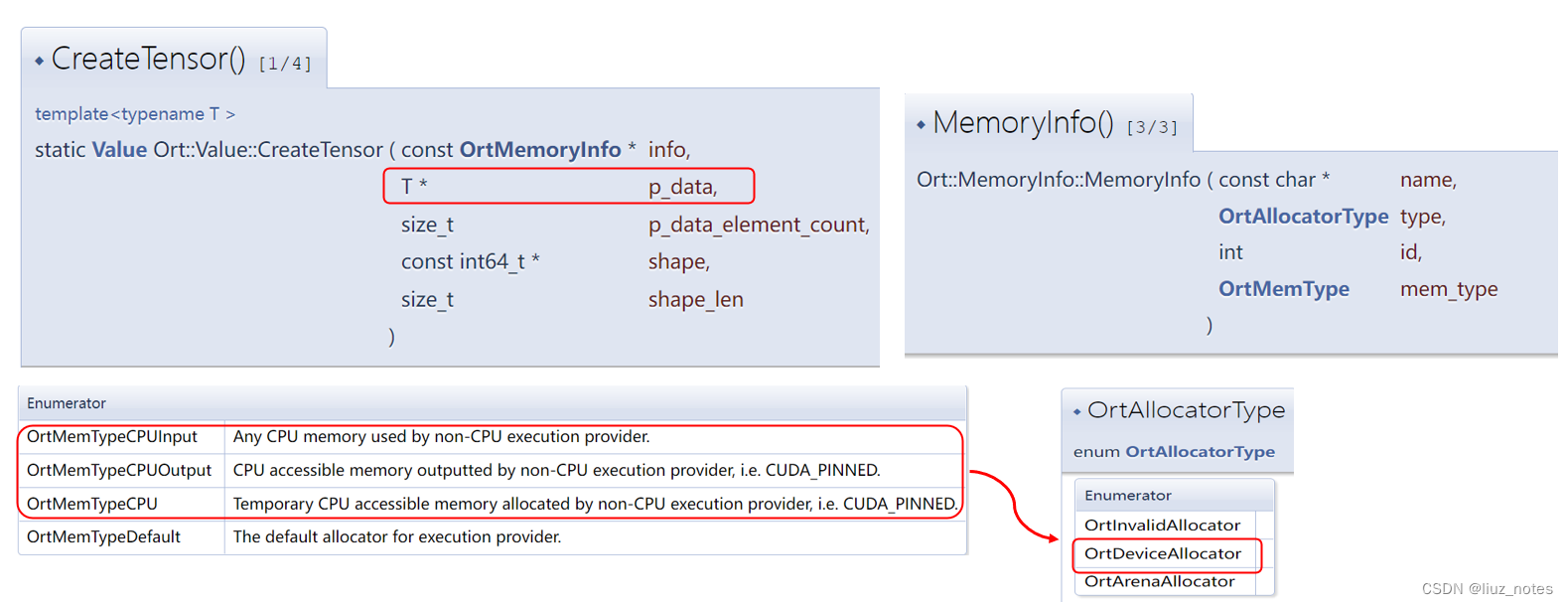
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
Ort::Value input_tensor;
input_tensor = Ort::Value::CreateTensor<float>(memory_info, in_x.data,target_size,input_dims.data(),input_dims.size())
注意其中in_x.data的类型为std::vector<float>。
最后用此前创建的session和Tensor变量进行推理,得到结果。
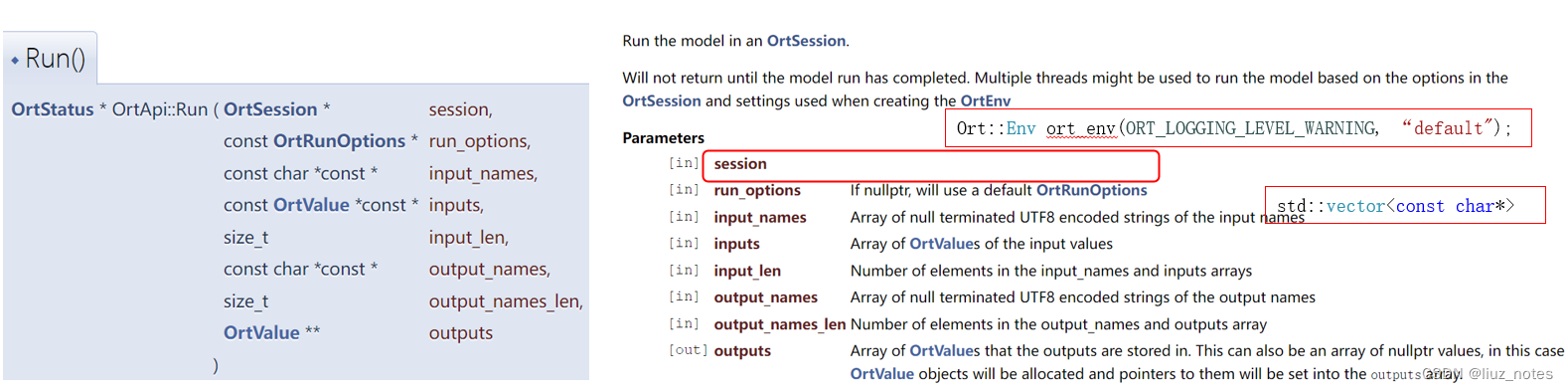
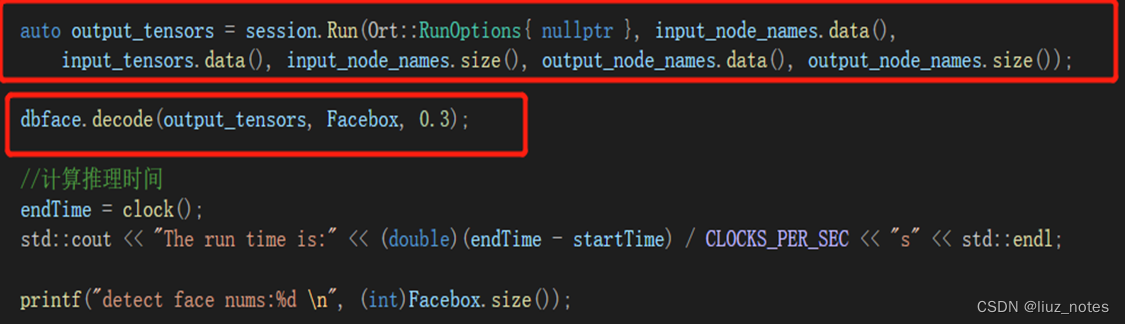
auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_node_names.data(), input_tensors.data(), input_node_names.size(), output_node_names.data(), output_node_names.size());
float* out_i = output_tensors[i].GetTensorMutableData<float>();
3 DBFace推理C++代码展示
数据结构定义,类封装,路径初始化


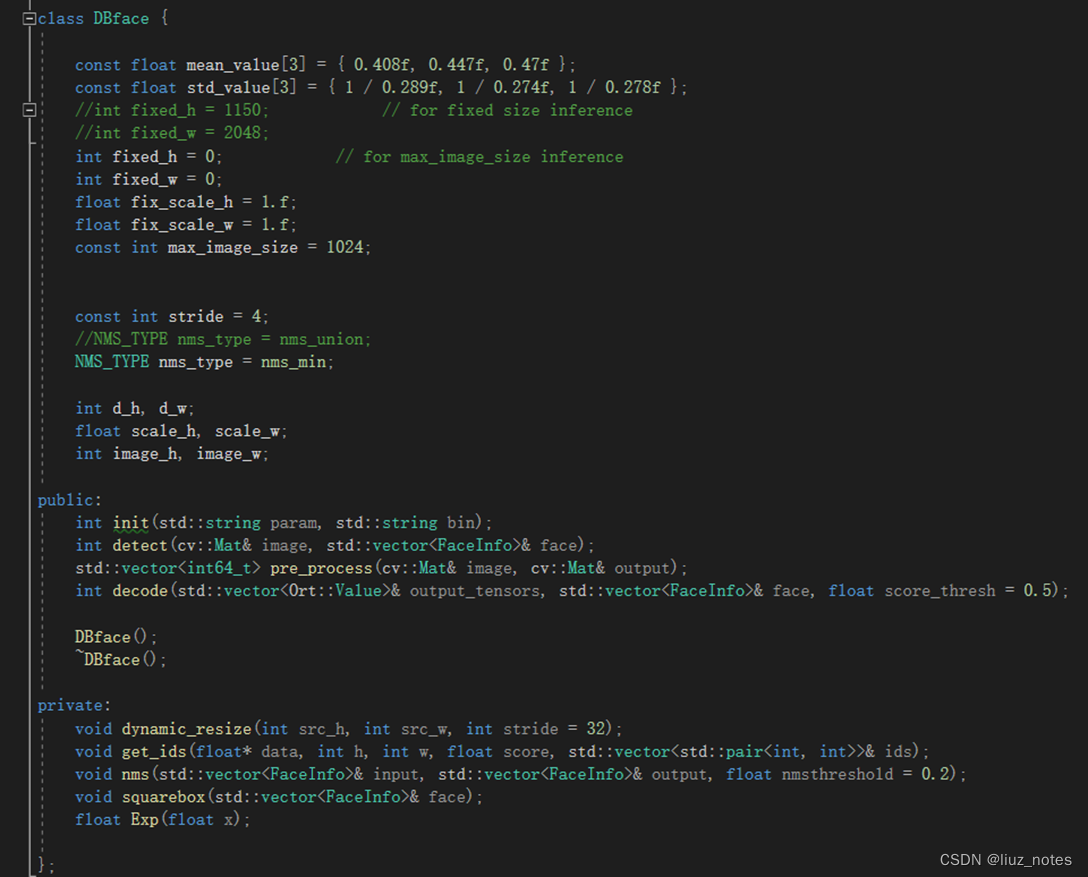
定义并配置相关环境变量
输入输出节点信息获取
读取图像,创建输入Tensor
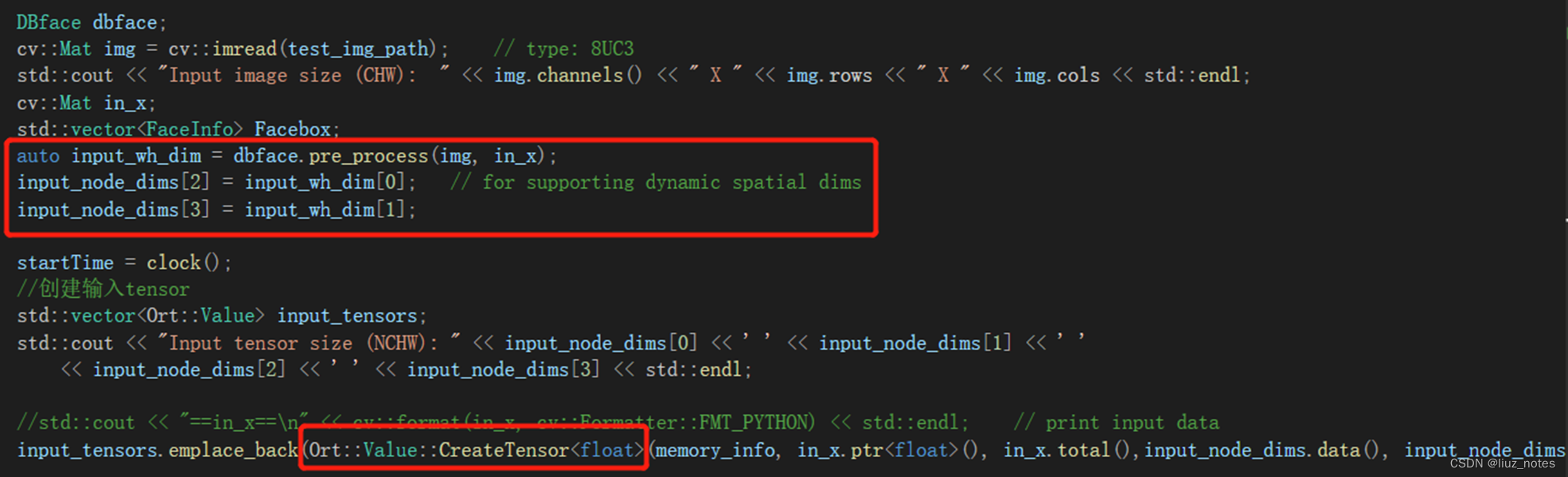
Ort推理,结果后处理
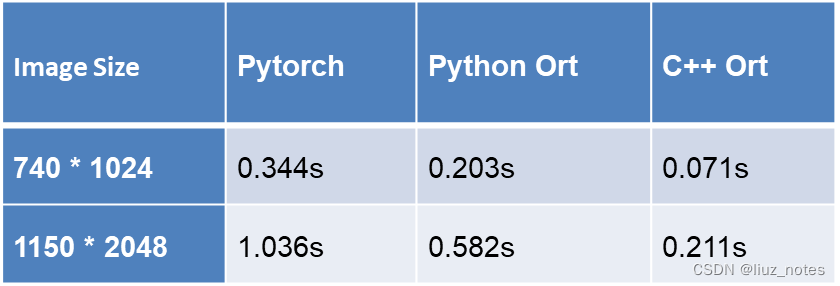
4 推理结果及比较


参考资料
- ONNX官方算子支持查询文档
- Pytorch对ONNX的算子支持查询文档
- ONNX对python的api文档
- ONNXRuntime官方网站及文档
- torch.onnx教程
- ONNXRuntime对C/C++和移动端部署的官方例程
- ONNXRuntime C++/Java/Python项目实操资料



![[综][PDPTW]A survey on pickup and delivery problems](https://img-blog.csdnimg.cn/1e736345a94a4beb9a6e12e20483629d.png)