谷歌大脑出品
paper: https://arxiv.org/abs/1805.09501
这里是个论文的阅读心得,笔记,不等同论文全部内容
文章目录
- 一、摘要
- 1.1 翻译
- 1.2 笔记
- 二、(第3部分)自动增强:直接在感兴趣的数据集上搜索最佳增强策略
- 2.1 翻译
- 2.2 笔记
- 三、跳出论文,转入应用——timm包
- 3.1 timm包的自动增强搜索策略
- 3.2 随机增强参数解释
- 3.3 策略增强的imagenet官方给的参数注释
- 3.4 数据增强效果实验
一、摘要
1.1 翻译
数据增强是提高现代图像分类器准确率的一种有效技术。然而,当前的数据增强实现是手工设计的。在本文中,我们描述了一个称为AutoAugment的简单过程,用于自动搜索改进的数据增强策略。在我们的实现中,我们设计了一个搜索空间,其中一个策略由许多子策略组成,其中一个子策略是为每个mini-batch中的每个图像随机选择的。子策略由两个操作组成,每个操作都是一个图像处理函数,如平移、旋转或剪切,以及应用这些函数的概率和大小。
我们使用搜索算法来找到最佳策略,使神经网络在目标数据集上产生最高的验证精度。我们的方法在CIFAR-10、CIFAR-100、SVHN和ImageNet上达到了最先进的精度(不需要额外的数据)。在ImageNet上,我们获得了83.5%的Top-1准确率,比之前83.1%的记录提高了0.4%。在CIFAR-10上,我们实现了1.5%的错误率,比以前的核心状态好0.6%。我们发现增强策略在数据集之间是可转移的。在ImageNet上学习的策略可以很好地转移到其他数据集上,例如Oxford Flowers、Caltech-101、Oxford- iit Pets、FGVC Aircraft和Stanford Cars。
1.2 笔记
主要陈述了自动数据增广的概念,这里比较重要的,我比较感兴趣的是搜索算法来找到最佳策略,结合第一段,也就是作者提出一个搜索空间,一个策略分解为多个子策略,子策略也是随机生成,而且每个子策略有2个数据增强的方法,然后搜索出最佳的子策略,然后表现在各大数据集上效果不错,转移到其他数据集也可以。
这里我比较好奇,如何去搜索最佳的策略?所以往下直接看方法。
二、(第3部分)自动增强:直接在感兴趣的数据集上搜索最佳增强策略
2.1 翻译
我们将寻找最佳增强策略的问题表述为一个离散搜索问题(参见图1)。我们的方法由两个部分组成:搜索算法和搜索空间。在高层次上,搜索算法(作为控制器RNN实现)对数据增强策略S进行采样,该策略包含要使用的图像处理操作、在每个批处理中使用该操作的概率以及操作的大小等信息。我们方法的关键是策略S将用于训练具有固定架构的神经网络,其验证精度R将被发送回更新控制器。由于R不可微,控制器将通过策略梯度方法进行更新。在下一节中,我们将详细描述这两个组件。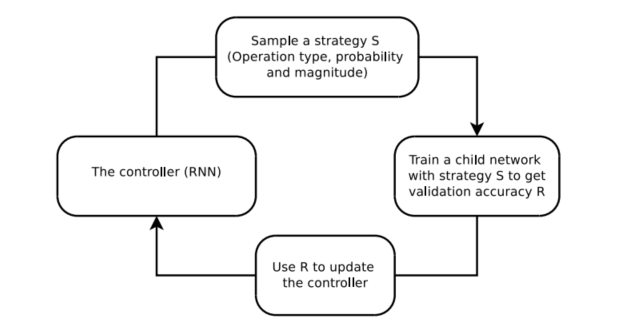
图1:概述我们使用搜索方法(例如,强化学习)来搜索更好的数据增强策略的框架。控制器RNN从搜索空间预测增强策略。具有固定架构的子网络被训练到收敛,达到精度R。奖励R将与策略梯度方法一起使用来更新控制器,以便它可以随着时间的推移生成更好的策略。
搜索空间细节:在我们的搜索空间中,一个策略由5个子策略组成,每个子策略由顺序应用的两个图像操作组成。此外,每个操作还与两个超参数相关联:1)应用该操作的概率,以及2)操作的幅度。图2显示了在我们的搜索空间中具有5个子策略的策略示例。第一个子策略指定ShearX的顺序应用程序,然后是Invert。这个应用ShearX的概率为0.9,当应用时,其大小为7(满分为10)。然后我们以0.8的概率应用Invert。反相操作不使用幅度信息。我们强调这些操作是按照指定的顺序进行的。

图2:在SVHN上发现的策略之一,以及如何使用它来生成增强数据给定用于训练神经网络的原始图像。该策略有5个子策略。对于小批处理中的每个图像,我们均匀随机地选择一个子策略来生成变换后的图像来训练神经网络。每个子策略由2个操作组成,每个操作与两个数值相关联:调用操作的概率和操作的大小。有可能调用某个操作,因此该操作可能不会应用到该小批处理中。但是,如果施加,则以固定的幅度施加。我们通过展示如何在不同的小批量中对一个图像进行不同的转换来强调应用子策略的随机性,即使使用相同的子策略。正如文中所解释的,在SVHN上,AutoAugment更经常地选择几何变换。可以看出为什么在SVHN上通常选择反转操作,因为图像中的数字对于该变换是不变的。
我们在实验中使用的操作来自PIL,一个流行的Python图像库为了通用性,我们考虑PIL中所有函数接受图像作为输入和输出一个图像。我们还使用了另外两种很有前景的增强技术:Cutout[12]和samplep播[24]。我们搜索的操作是ShearX/Y, TranslateX/Y, Rotate, AutoContrast, Invert, Equalize, solalize, Posterize, Contrast, Color, Brightness, sharpening, cutout [12], Sample Pairing [24].总的来说,我们在搜索空间中有16项操作。每个操作还附带一个默认的幅度范围,这将在第4节中更详细地描述。我们将震级范围离散为10个值(均匀间隔),这样我们就可以使用离散搜索算法来找到它们。同样,我们也将应用该操作的概率离散为11个值(均匀间隔)。在(16×10×11)2种可能性的空间中查找每个子策略成为一个搜索问题。然而,我们的目标是同时找到5个这样的子政策,以增加多样性。有5个子策略的搜索空间大约有(16×10×11)10≈2.9×1032种可能性。
我们使用的16个操作及其默认值范围如附录中的表1所示。注意,在我们的搜索空间中没有显式的“Identity”操作;这个操作是隐式的,可以通过调用一个概率设置为0的操作来实现。
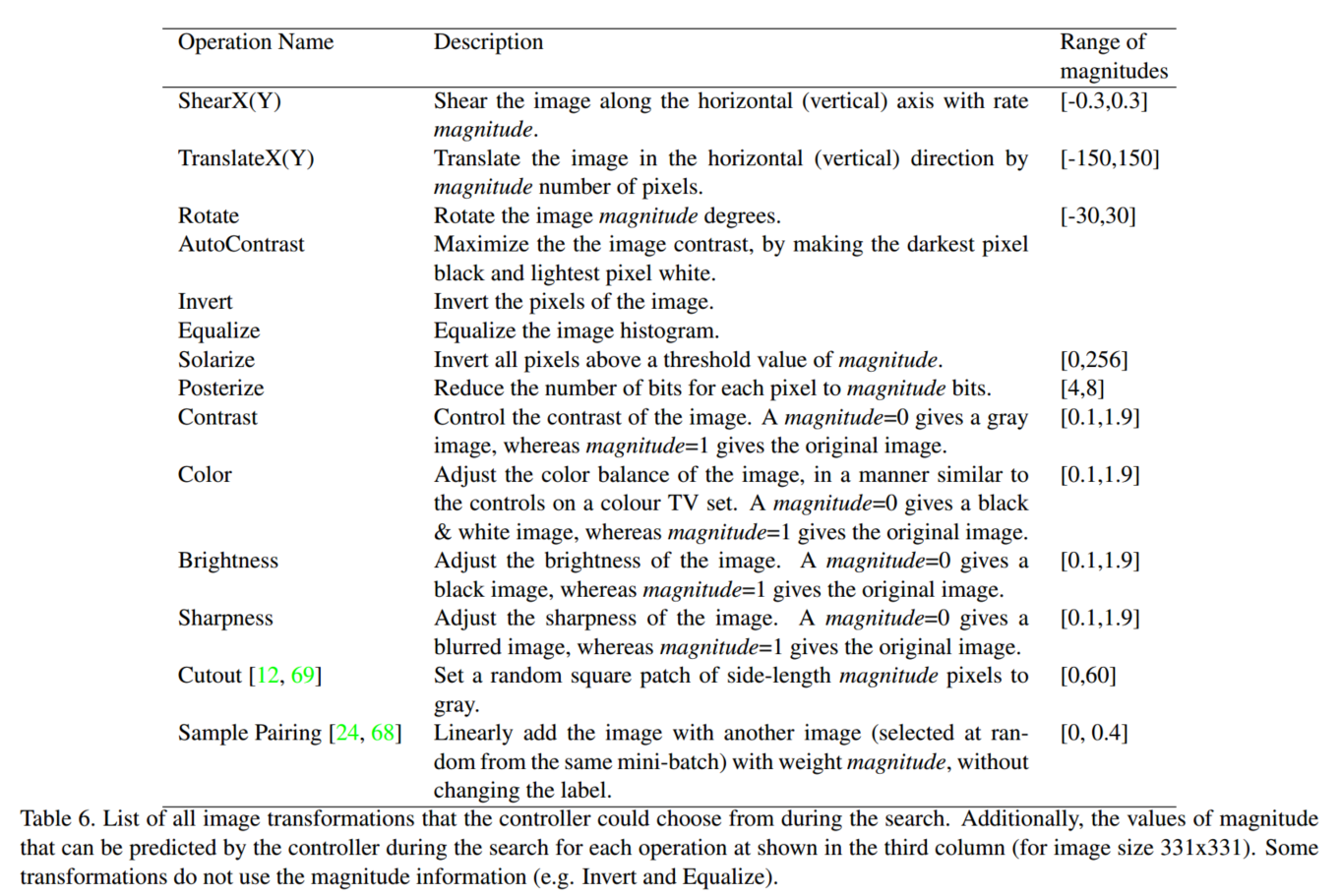
控制器在搜索过程中可以选择的所有图像转换的列表。此外,控制器在搜索每个操作期间可以预测的幅度值如第三列所示(对于图像大小为331x331)。有些变换不使用幅度信息(例如逆变和均衡)。
搜索算法细节: 我们在实验中使用的搜索算法使用了强化学习,灵感来自[71,4,72,5]。搜索算法由两个部分组成:控制器(递归神经网络)和训练算法(邻域策略优化算法)[53]。在每一步,控制器预测由softmax产生的决策;然后将预测作为嵌入馈送到下一步。为了预测5个子策略,控制器总共有30个softmax预测,每个子策略有2个操作,每个操作需要操作类型、大小和概率。
控制器RNN的训练: 控制器使用奖励信号进行训练,这表明该策略在改善“子模型”(作为搜索过程一部分训练的神经网络)的泛化方面有多好。在我们的实验中,我们设置了一个验证集来度量子模型的泛化。通过在训练集(不包含验证集)上应用5个子策略生成的增强数据来训练子模型。对于mini-batch中的每个示例,随机选择5个子策略中的一个来增强图像。然后在验证集上评估子模型以测量准确性,并将其用作训练循环网络控制器的奖励信号。在每个数据集上,控制器对大约15,000个策略进行采样。
控制器RNN的架构和训练超参数: 我们遵循[72]中的训练过程和超参数来训练控制器。更具体地,控制器RNN是一个单层LSTM[21],每层有100个隐藏单元,对与每个架构决策相关的两个卷积单元(其中B通常为5)进行2 × 5B softmax预测。控制器RNN的10B个预测中的每一个都与一个概率相关联。子网络的联合概率是这10B软最大值的所有概率的乘积。该联合概率用于计算控制器RNN的梯度。根据子网络的验证精度缩放梯度,以更新控制器RNN,使控制器为坏的子网络分配低概率,为好的子网络分配高概率。与[72]类似,我们采用学习率为0.00035的近端策略优化(PPO)[53]。为了鼓励探索,我们还使用了权重为0.00001的熵惩罚。在我们的实现中,基线函数是先前奖励的指数移动平均值,权重为0.95。控制器的权重在-0.1到0.1之间均匀初始化。出于方便,我们选择使用PPO来训练控制器,尽管先前的工作表明,其他方法(例如增强随机搜索和进化策略)可以表现得同样好,甚至略好[30]。
在搜索结束时,我们将最佳5个策略中的子策略连接到单个策略中(包含25个子策略)。最后这个包含25个子策略的策略用于训练每个数据集的模型。
上述搜索算法是我们可以用来寻找最佳策略的许多可能的搜索算法之一。也许可以使用不同的离散搜索算法,如遗传规划[48]甚至随机搜索[6]来改进本文的结果。
【关于训练迭代数在5部分Discuss有提到,这里放在一起】
训练步骤与子策略数量之间的关系:我们工作的一个重要方面是子策略在训练过程中的随机应用。每个图像仅由每个小批中可用的许多子策略中的一个增强,子策略本身具有进一步的随机性,因为每个转换都有与其关联的应用程序的概率。我们发现这种随机性要求每个子策略有一定数量的epoch才能使AutoAugment有效。由于每个子模型都用5个子策略进行训练,因此在模型完全受益于所有子策略之前,它们需要训练超过80-100个epoch的子策略。这就是为什么我们选择训练我们的child模型为120个epochs。每个子策略需要应用一定的次数,模型才能从中受益。在策略被学习之后,完整的模型被训练更长的时间(例如CIFAR-10上的Shake-Shake训练1800个epoch, ImageNet上的ResNet-50训练270个epoch),这允许我们使用更多的子策略。
2.2 笔记
这里讲了自动搜索算法,类似训练的概念,学习出一个最优的数据增强策略,讨论部分也提到了要更多的epoch来搜索。后面的实验也就是设置一个基准,然后跟没有用autoaugment或者跟其他方法比较,最后讨论和消融实验。这里就不往下看了,感兴趣可以直接进最上面的原文链接看原文。
这里再看下应用,研究autoAug也是因为需要提升训练精度,然后在timm包里发现了这个,进而来研究下,下面再做一下timm里面的学习笔记。
三、跳出论文,转入应用——timm包
参考:https://timm.fast.ai/AutoAugment#auto_augment_policy
原文:
在本教程中,我们将了解如何利用 AutoAugment 作为一种数据增强技术来训练神经网络。
我们看:
- 我们如何使用 timm 训练脚本来应用 AutoAugment 。
- 我们如何使用 AutoAugment 作为自定义训练循环的独立数据增强技术。
- 深入研究 AutoAugment 的源代码。
理解:
发现这里只是用了论文的预设结论或者其他的结论生成的一些策略,以及一些增强算子随机增强。以下是对自动增强策略的解读,以及实验看下每个随机增强的效果。
3.1 timm包的自动增强搜索策略
其中timm包的自动增强搜索策略包含:
- AutoContrast: 自动对比度调整。
- Equalize: 直方图均衡化。
- Invert: 反转图像颜色。
- Rotate: 随机旋转图像。
- Posterize: 减少图像的色阶。
- Solarize: 部分地反转图像的像素值。
- SolarizeAdd: 在图像上添加一些反转效果。
- Color: 随机调整图像的颜色。
- Contrast: 随机调整图像的对比度。
- Brightness: 随机调整图像的亮度。
- Sharpness: 随机调整图像的锐度。
- ShearX: 沿着 X 轴随机剪切图像。
- ShearY: 沿着 Y 轴随机剪切图像。
- TranslateXRel: 沿着 X 轴相对随机平移图像。
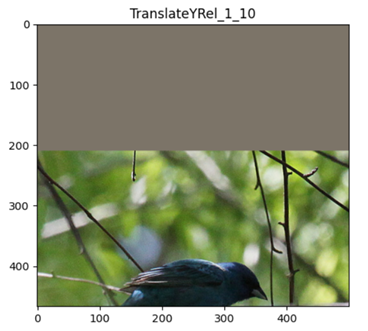
- TranslateYRel: 沿着 Y 轴相对随机平移图像。
3.2 随机增强参数解释
rand_augment_transform函数的注释
这段代码是用于创建一个 RandAugment 变换的函数。RandAugment 是一种数据增强的方法,通过对图像应用一系列随机的数据变换来增加训练数据的多样性。
这个函数接受两个参数:
- config_str:一个字符串,定义了随机增强的配置。这个字符串包括多个部分,由破折号(‘-’)分隔。第一个部分定义了具体的 RandAugment 变体(目前只有 ‘rand’)。其余的部分用于确定具体的配置参数,包括:
- ‘m’:整数,表示 RandAugment 的幅度(magnitude)。
- ‘n’:整数,表示每个图像选择的变换操作的数量。
- ‘w’:整数,表示概率权重的索引(一组权重集合的索引,用于影响操作的选择)。
- ‘mstd’:浮点数,表示幅度噪声的标准差,或者如果是无穷大(或大于100),则进行均匀采样。
- ‘mmax’:设置幅度的上限,而不是默认的 _LEVEL_DENOM(10)。
- ‘inc’:整数(布尔值),表示是否使用随着幅度增加而增加的增强(默认为0)。
- hparams:其他的超参数(关键字参数),用于配置 RandAugmentation 方案。
最终,这个函数返回一个与 PyTorch 兼容的变换(Transform),可以用于数据增强。这个变换将在训练过程中被应用于图像数据。
3.3 策略增强的imagenet官方给的参数注释
policy = [
[('PosterizeOriginal', 0.4, 8), ('Rotate', 0.6, 9)],
[('Solarize', 0.6, 5), ('AutoContrast', 0.6, 5)],
[('Equalize', 0.8, 8), ('Equalize', 0.6, 3)],
[('PosterizeOriginal', 0.6, 7), ('PosterizeOriginal', 0.6, 6)],
[('Equalize', 0.4, 7), ('Solarize', 0.2, 4)],
[('Equalize', 0.4, 4), ('Rotate', 0.8, 8)],
[('Solarize', 0.6, 3), ('Equalize', 0.6, 7)],
[('PosterizeOriginal', 0.8, 5), ('Equalize', 1.0, 2)],
[('Rotate', 0.2, 3), ('Solarize', 0.6, 8)],
[('Equalize', 0.6, 8), ('PosterizeOriginal', 0.4, 6)],
[('Rotate', 0.8, 8), ('Color', 0.4, 0)],
[('Rotate', 0.4, 9), ('Equalize', 0.6, 2)],
[('Equalize', 0.0, 7), ('Equalize', 0.8, 8)],
[('Invert', 0.6, 4), ('Equalize', 1.0, 8)],
[('Color', 0.6, 4), ('Contrast', 1.0, 8)],
[('Rotate', 0.8, 8), ('Color', 1.0, 2)],
[('Color', 0.8, 8), ('Solarize', 0.8, 7)],
[('Sharpness', 0.4, 7), ('Invert', 0.6, 8)],
[('ShearX', 0.6, 5), ('Equalize', 1.0, 9)],
[('Color', 0.4, 0), ('Equalize', 0.6, 3)],
[('Equalize', 0.4, 7), ('Solarize', 0.2, 4)],
[('Solarize', 0.6, 5), ('AutoContrast', 0.6, 5)],
[('Invert', 0.6, 4), ('Equalize', 1.0, 8)],
[('Color', 0.6, 4), ('Contrast', 1.0, 8)],
[('Equalize', 0.8, 8), ('Equalize', 0.6, 3)],
]
分别是:变换名,变换概率,变换强度
3.4 数据增强效果实验
from timm.data.auto_augment import AugmentOp
from PIL import Image
from matplotlib import pyplot as plt
img_path = r"/path/to/imagenet-mini/val/n01537544/ILSVRC2012_val_00023438.JPEG"
mean = (0.485, 0.456, 0.406)
X = Image.open(img_path)
img_size_min = min(X.size)
plt.imshow(X)
plt.show()
all_policy_use_op = [
['AutoContrast', 1, 10], ['Equalize', 1, 10], ['Invert', 1, 10], ['Rotate', 1, 10], ['Posterize', 1, 10],
['PosterizeIncreasing', 1, 10], ['PosterizeOriginal', 1, 10], ['Solarize', 1, 10], ['SolarizeIncreasing', 1, 10],
['SolarizeAdd', 1, 10], ['Color', 1, 10], ['ColorIncreasing', 1, 10], ['Contrast', 1, 10],
['ContrastIncreasing', 1, 10], ['Brightness', 1, 10], ['BrightnessIncreasing', 1, 10], ['Sharpness', 1, 10],
['SharpnessIncreasing', 1, 10], ['ShearX', 1, 10], ['ShearY', 1, 10], ['TranslateX', 1, 10], ['TranslateY', 1, 10],
['TranslateXRel', 1, 10], ['TranslateYRel', 1, 10]
]
for op_name, p, m in all_policy_use_op:
aug_op = AugmentOp(name=op_name, prob=p, magnitude=m,
hparams={'translate_const': int(img_size_min * 0.45),
'img_mean': tuple([min(255, round(255 * x)) for x in mean])})
plt.imshow(aug_op(X))
plt.title(f'{op_name}_{str(p)}_{str(m)}')
plt.show()
原图

AutoContrast

Equalize

Invert
Rotate
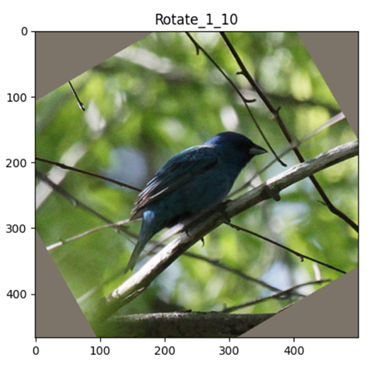
Posterize
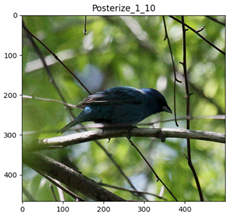
PosterizeIncreasing
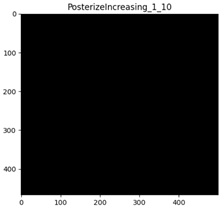
PosterizeOriginal
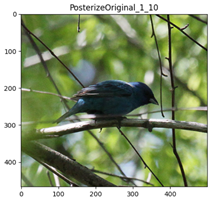
Solarize
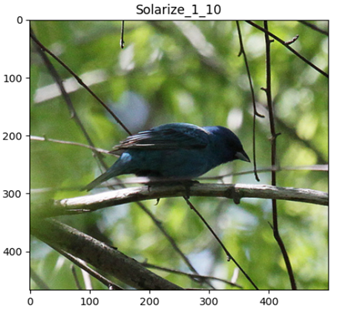
SolarizeIncreasing
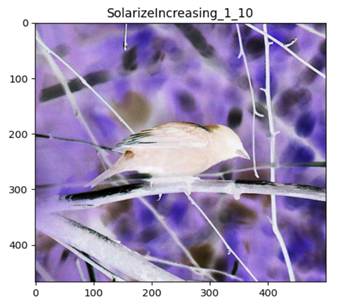
SolarizeAdd
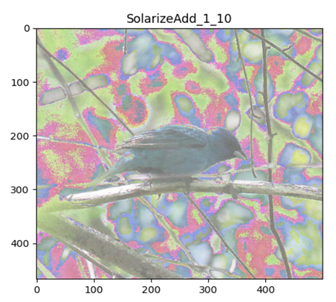
Color
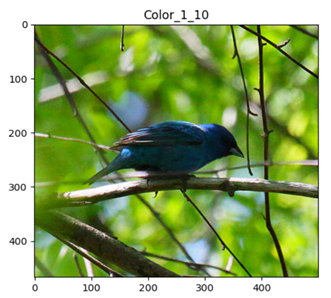
ColorIncreasing

Contrast
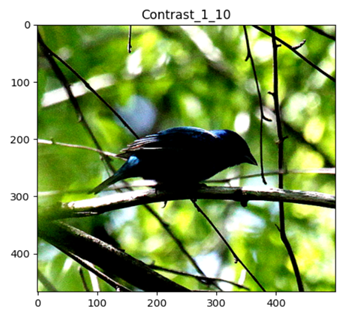
ContrastIncreasing
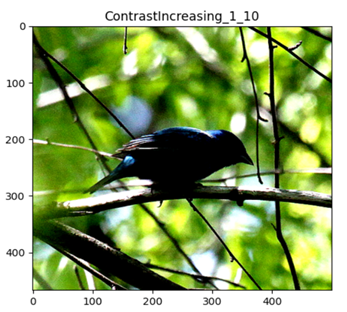
Brightness
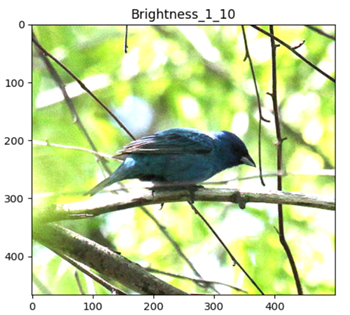
BrightnessIncreasing

Sharpness
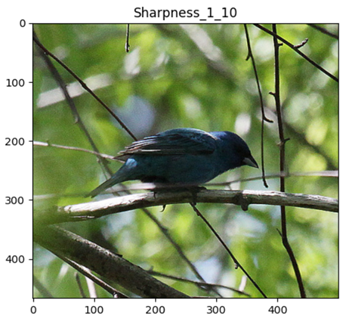
SharpnessIncreasing
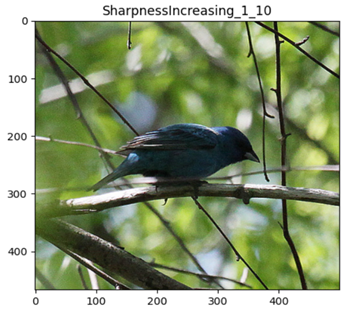
ShearX
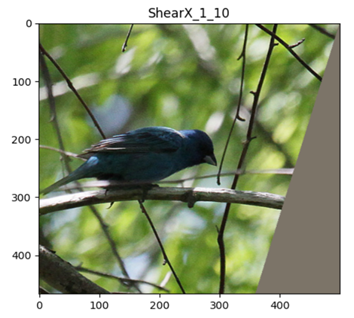
ShearY
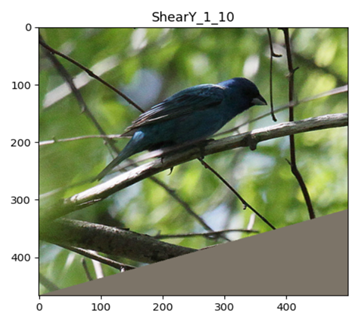
TranslateX

TranslateY
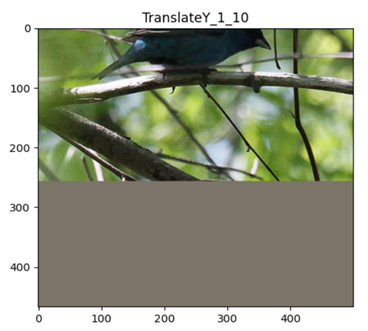
TranslateXRel
TranslateYRel