您好,我是码农飞哥(wei158556),感谢您阅读本文,欢迎一键三连哦。
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 2.网上优质的Python题库很少,这里给大家推荐一款非常棒的Python题库,从入门到大厂面试题👉点击跳转刷题网站进行注册学习
❤️ 3. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当 。python爬虫入门进阶
❤️ 4. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 5. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
😁 6. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
文章目录
- 1. 项目场景
- 2. 问题描述
- 3. 原因分析
- 4. 问题解决
- 4.1. 方式一:关闭derived_merge特性
- 4.2. 方式二:采用DISTINCT函数使得 derived_merge 参数合并派生类失效
- 最后说一句
- 参考
- 总结
1. 项目场景
现有课堂活动评价的需求:教师对学生提交的活动进行评价, 教师可重复评价,即对同一个学生同一个活动进行多次评价,这种情况下需要取最新的那个评价。
2. 问题描述
本来期望直接使用 rank() over() 开窗函数,就像下面这样,但是奈何开窗函数只在mysql 8.0 及其以上的版本支持。
rank() over(
partition by activity_id,
comment_open_id
order by
report_date desc
) RK
而项目组使用的是MySQL的版本是 5.7,此版本不支持开窗函数,故放弃此方案。
经过一番调研之后,决定采用子查询,在子查询中先按照时间report_date倒序排列,然后在外层查询中按照 activity_id+comment_open_id 分组,因为分组的话会取该分组中的第一条数据。
理想是丰满的,显示是骨感的!!!!
如下:原始数据有4条数据,其中第一条数据(id=11)和第四条数据(id=19)的活动ID(activity_id)和用户id(comment_open_id)都相同。按照我们期望的这两条数据只取id=19的那条数据,因为那条数据更新。而第二条数据和第三条数据正常保留。故期望的分组结果是 13,17,19 这三条数据。
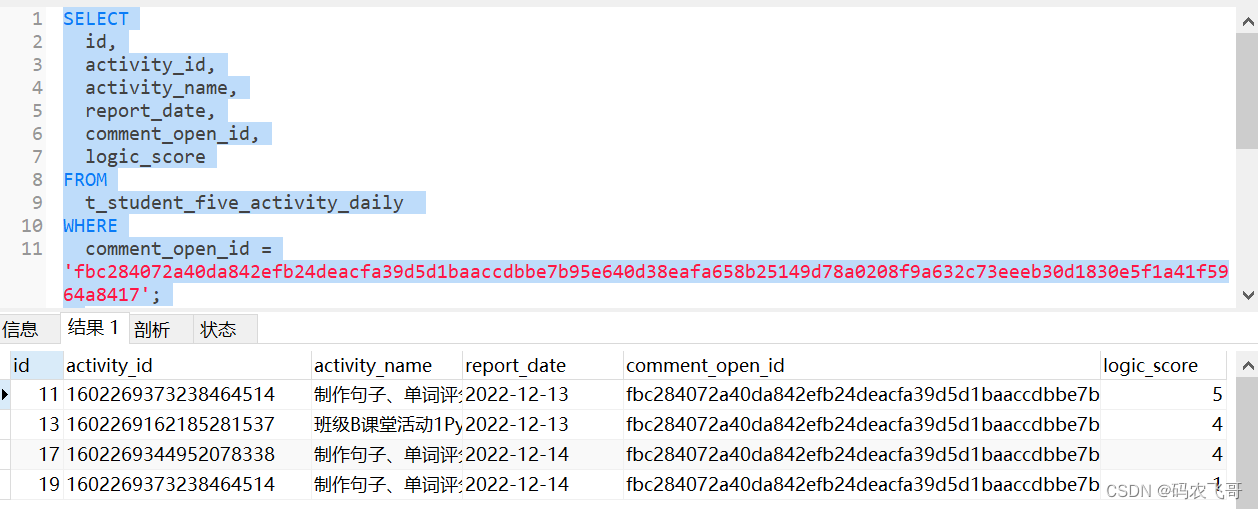
第一步:子查询先按照时间排序,按照时间分组之后发现id=19的数据排在了id=11的数据前面
SELECT
id,
activity_id,
activity_name,
report_date,
comment_open_id,
logic_score
FROM
t_student_five_activity_daily
WHERE
comment_open_id = 'fbc284072a40da842efb24deacfa39d5d1baaccdbbe7b95e640d38eafa658b25149d78a0208f9a632c73eeeb30d1830e5f1a41f5964a8417'
ORDER BY
report_date DESC;

第二步:在外层查询中按照activity_id和comment_open_id 进行分组
SELECT a.* FROM
(
SELECT
id,
activity_id,
activity_name,
report_date,
comment_open_id,
logic_score
FROM
t_student_five_activity_daily
WHERE
comment_open_id = 'fbc284072a40da842efb24deacfa39d5d1baaccdbbe7b95e640d38eafa658b25149d78a0208f9a632c73eeeb30d1830e5f1a41f5964a8417'
ORDER BY
report_date DESC
) as a
GROUP BY
a.activity_id,
a.comment_open_id
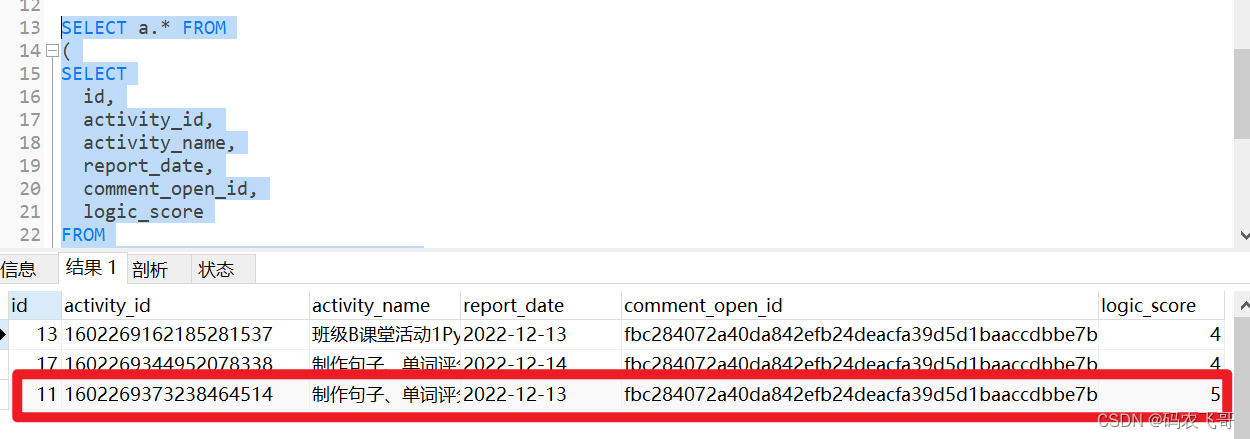
但是分组之后,我们发现最终取的结果是13,17,11 这三条数据,与我们期望的 13,17,19 有出入。
直觉告诉我们应该是子查询里面的排序没有生效,不然的话应该取的就是id=19那条数据
3. 原因分析
遇到数据库的SQL问题不要慌,首先查询一下执行计划。
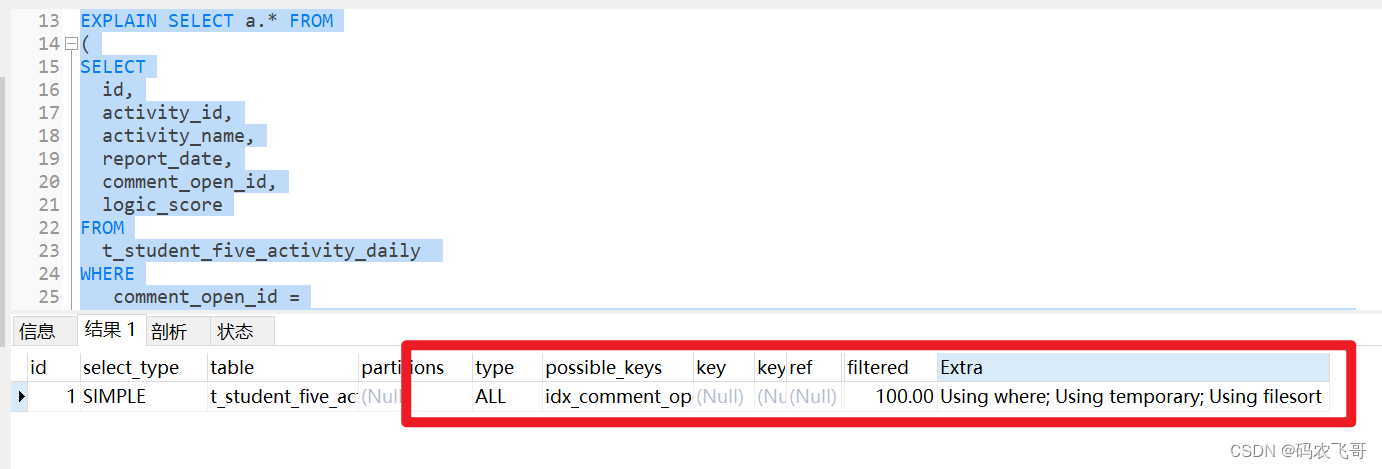
执行计划显示只有一个表的处理,不对呀,应该是两张表,先子查询查出一张临时表,然后外层查询再从这张临时表筛选出一张新表,总共两张表才对。而是采用了临时表,磁盘排序的方式。这就说明查询优化器对我们的SQL进行了查询优化。
一番百度之后,发现其实是mysql5.7针对于5.6版本做了一个优化,针对mysql本身的优化器增加了一个控制优化器的参数叫 derived_merge ,什么意思呢,“派生类合并”。
什么意思呢,据mysql官方使用手册的说法:
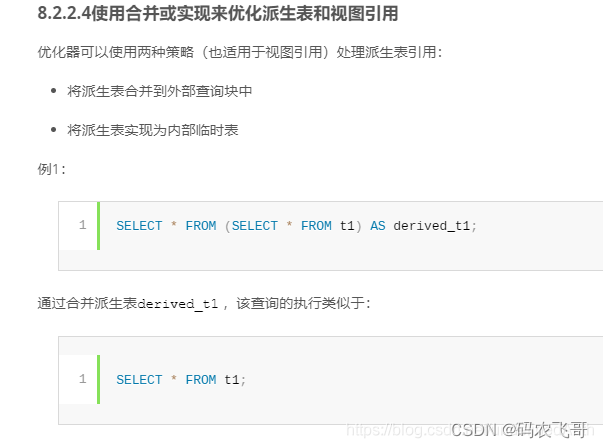
这里将派生表合并到外部查询块中,就相当于嵌套子查询没啥鸟用了。
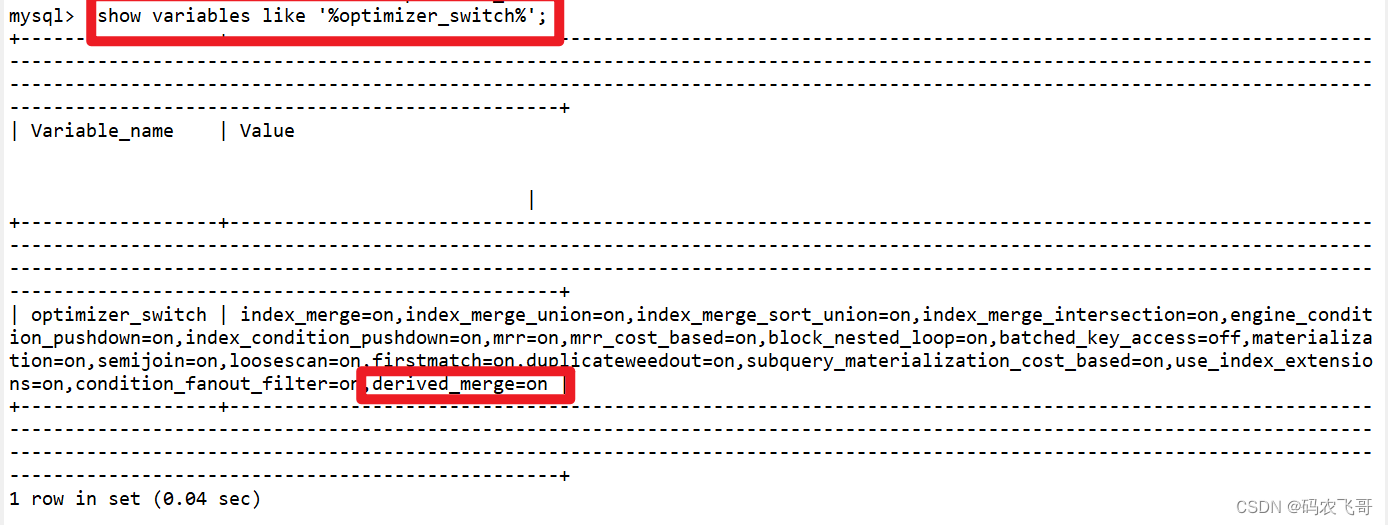
通过对mysql官方使用手册的了解,mysql5.7对 derived_merge 参数默认设置为on,也就是开启状态,当然我们也可以通过命令查看一下(在命令行窗口中执行该命令):
show variables like '%optimizer_switch%';
4. 问题解决
问题的原因找到了,那么解决问题就简单了,这里有两种方式来解决这个问题
4.1. 方式一:关闭derived_merge特性
我们在mysql5.7中把它关闭 shut downn 使用如下命令:
set optimizer_switch='derived_merge=off';
set global optimizer_switch='derived_merge=off';
这样如果from中查询出来的的结果就不会与外部查询块合并了,sql执行结果如下:
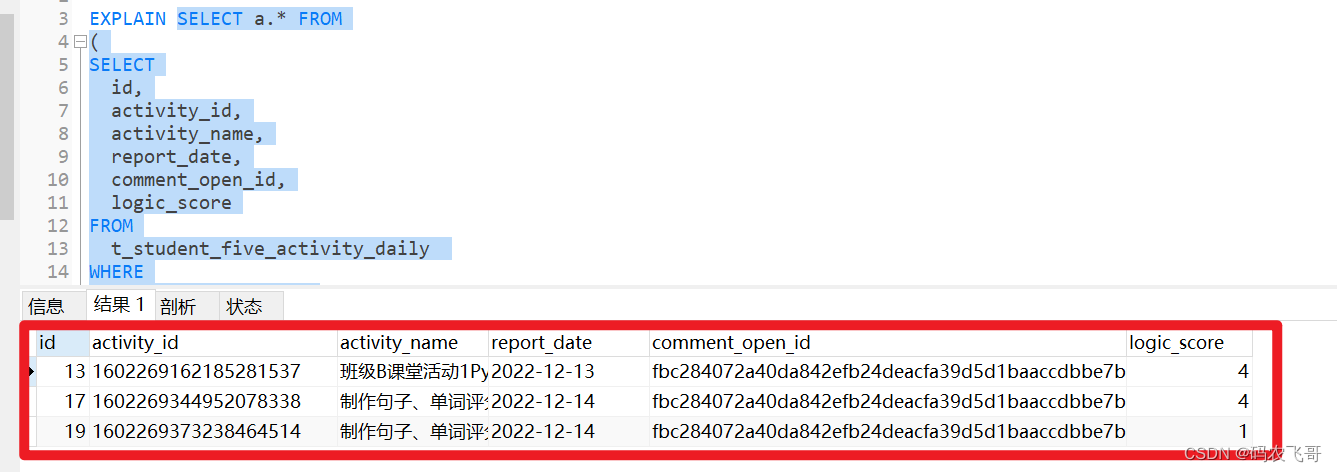
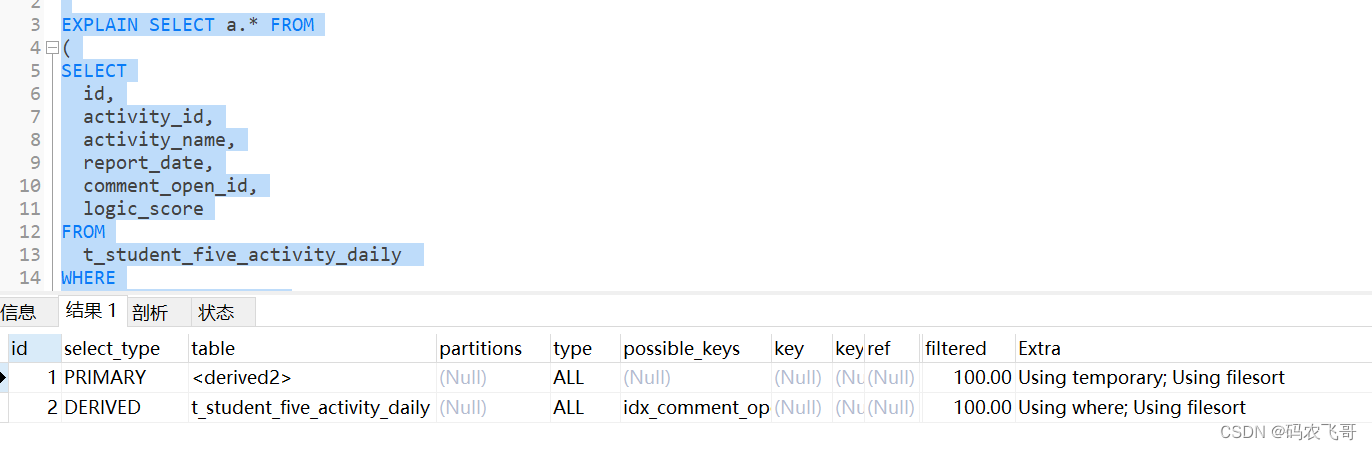
SQL的执行计划如下:在执行计划中发现了两个查询id=2的就是子查询。
当然修改 derived_merge 参数得谨慎而行之,因为mysql5.7版本有了这个优化的机制是有它的道理的,之所以去除派生类与外部块合并,是因为减少查询开销,派生类是个临时表,开辟一个临时表的同时还要维护和排序或者分组,都会影响效率,所以尽量不要去修改此参数。
其实也有多种办法不需要修改 derived_merge 参数而使合并派生类失效,具体做法可参考官方使用手册, 摘抄手册文:
4.2. 方式二:采用DISTINCT函数使得 derived_merge 参数合并派生类失效
在子查询中使用DISTINCT函数,使得子查询不会被合并到外部查询块中。
SELECT a.* FROM
(
SELECT
DISTINCT
id,
activity_id,
activity_name,
report_date,
comment_open_id,
logic_score
FROM
t_student_five_activity_daily
WHERE
comment_open_id = 'fbc284072a40da842efb24deacfa39d5d1baaccdbbe7b95e640d38eafa658b25149d78a0208f9a632c73eeeb30d1830e5f1a41f5964a8417'
ORDER BY
report_date DESC
) as a
GROUP BY
a.activity_id,
a.comment_open_id;
查询结果如下所示:
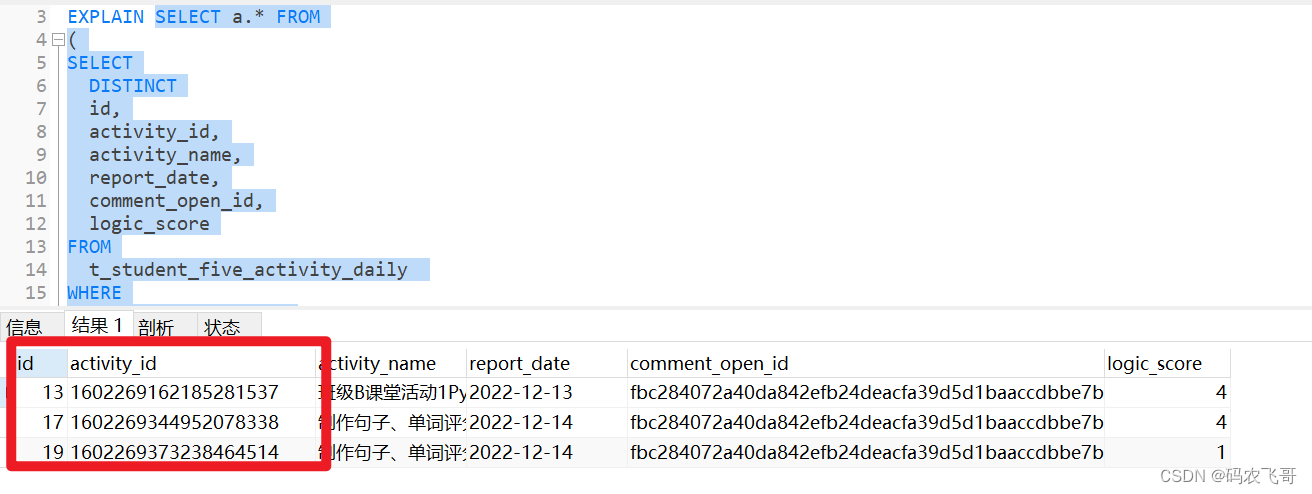
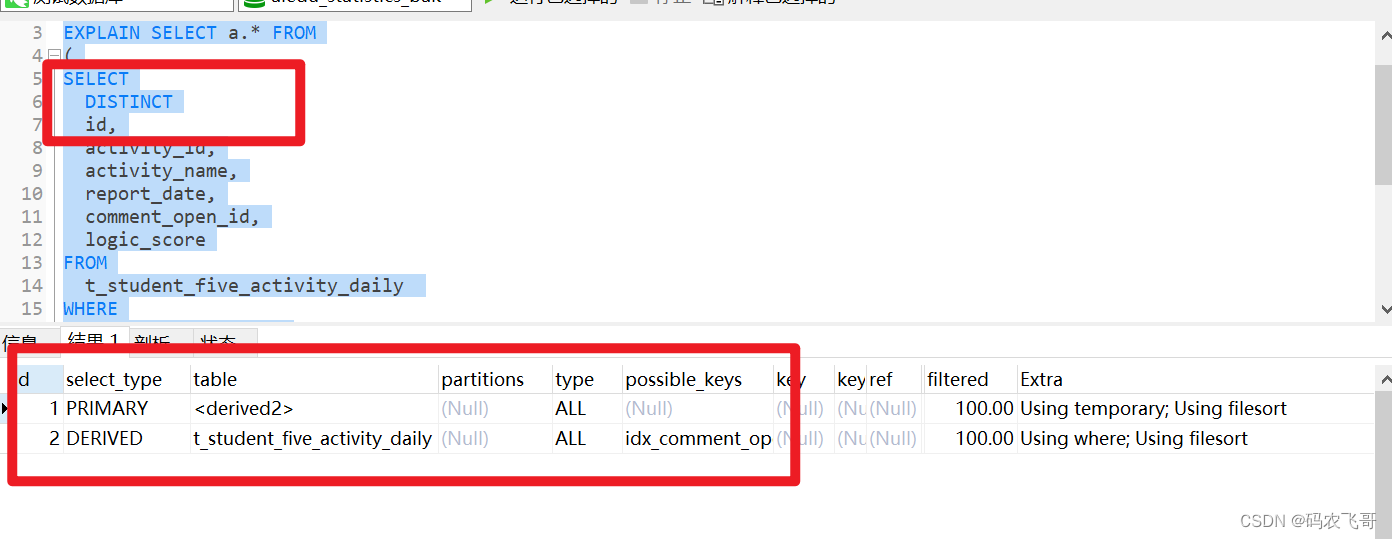
执行计划如下所示:
当然处理DISTINCT函数以外,还有其他的函数也是可以的
可以通过在子查询中使用任何阻止合并的构造来禁用合并,尽管这些构造对实现的影响并不明确。 防止合并的构造对于派生表和视图引用是相同的:
1.聚合函数( SUM() , MIN() , MAX() , COUNT()等)
2.DISTINCT
3.GROUP BY
4.HAVING
5.LIMIT
6.UNION或UNION ALL
7.选择列表中的子查询
8.分配给用户变量
9.仅引用文字值(在这种情况下,没有基础表)
最后说一句
如果你使用的是MySQL 8.0及以上的版本,那么你可以直接使用开窗函数 rank() over()。参考SQL如下:
SELECT a.* FROM
(
SELECT
id,
activity_id,
activity_name,
report_date,
comment_open_id,
logic_score,
RANK() over(
partition by activity_id,
comment_open_id
order by
report_date desc
) RK
FROM
t_student_five_activity_daily
WHERE
comment_open_id = 'fbc284072a40da842efb24deacfa39d5d1baaccdbbe7b95e640d38eafa658b25149d78a0208f9a632c73eeeb30d1830e5f1a41f5964a8417'
) as a
WHERE a.RK=1
参考
记一次mysql5.7的新特性derived_merge的坑