文章目录
- 链表
- 链表的结构
- 使用链表的优点
- 模拟实现链表
链表
在之前的学习中我们讲解了顺序表ArrayList,Java模拟实现顺序表,如果需要大家可以去看一看,顺序表底层的实现逻辑其实就是数组,在物理存储结构和逻辑上都是连续的,而今天我们要学习的链表呢?链表是一种物理存储结构上不连续的存储结构,但是逻辑上链表又是连续的,这是如何实现的呢?下面通过一张图来给大家讲解。

链表是由很多个节点组成,每个节点中包含了两个东西一个是value用于储存数据,另一个是next用于储存下一个节点的地址,如果是双向链表还会多一个前驱prev储存的是前一个节点的地址。如上图,每个节点的存储地址并不连续,但是通过每个节点的next可以将节点都串起来,形成逻辑上的连续。向这样的存储结构我们成为链表。
链表的结构
在链表中的结构非常多样,例如链表是双向还是单向,带不带头结点,循环或者是非循环链表。将这些要素组合起来一共可以组合成8种结构的链表。这些要素都是什么意思呢,我们还是通过画图来给大家讲解一下。
循环和非循环
例如:上一个链表最后一个节点为null,我们将null更改为第一个节点的地址,这样就是循环链表了。

是否带头节点
链表是否带头结点,就是看有没有一个固定的结点充当头节点。

双向链表单向链表
像这样既可以从前向后访问节点,又可以从后向前回退回来的链表就是双向链表。单项链表顾名思义只能从前向后访问。

使用链表的优点
经过上面的讲解,大家都会发现这好像跟顺序表存储数据也差不多,那链表相较于顺序表有什么优点和注意事项呢?我们说顺序表在物理地址上必须是连续的,所以插入删除元素时需要整体挪动后续元素,效率较低,而链表在插入或者删除元素时只需要改变某一处节点的next指向的地址,就可以实现插入删除元素,更省时间。
注意:
1、链式结构在逻辑上时连续的,但在物理上不一定连续。
2、结点一般都是从堆上申请出来的
3、从堆上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,可能不连续。
模拟实现链表
说了这么多,让我们来模拟实现一下链表吧,我们写一个无头单向非循环的链表。
public class MyLinkedList {
static class LinkNode {
public int val;//用于储存数据
public LinkNode next;//用于找到下一个节点
public LinkNode(int val) {
this.val = val;
}
}
public LinkNode head;//假设充当一个头节点,不固定所以链表还是无头的。
}
因为链表是由节点组成的,而节点内部由储存数据的空间和存储下个结点的地址空间组成,所以我们可以用内部类来解决这个问题。
头插法添加元素
//头插法
public void addFirst(int data){
LinkNode newNode = new LinkNode(data);
newNode.next = head;
head = newNode;
}
头插法首先我们需要创建一个新的节点用于存储先添加的元素数据,因为是头插法,是在链表的最前面插入元素,所以新创建的节点的next需要指向head结点(我们假设的头结点),并且将新的节点设置为head。

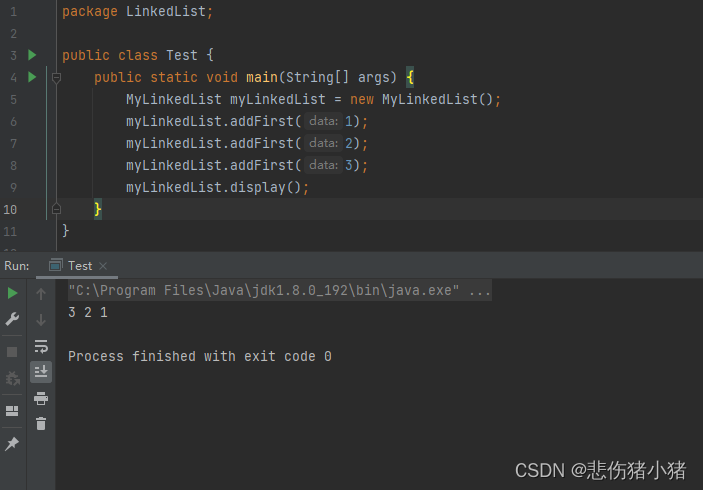
我们可以写一个打印链表的方法验证一下:
打印链表:
public void display() {
LinkNode cur = head;
while(cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();
}
因为最后一个节点的next等于null,所以如果希望遍历完链表就让cur != null,如果遍历到最后一个节点就停下来就cur.next != null。cur == cur.next就相当于顺序表中数组下标的i++,每次打印节点用于储存数据的value就可以完成遍历打印链表。
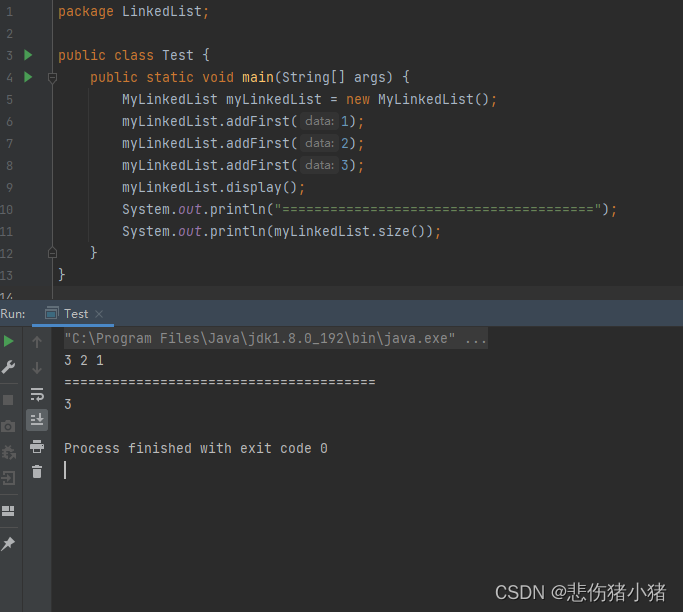
得到单链表的长度:
//得到单链表的长度
public int size(){
LinkNode cur = head;
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
同样我们需要遍历链表,将计数器count++就可以统计链表节点的个数,最后就是链表的长度。
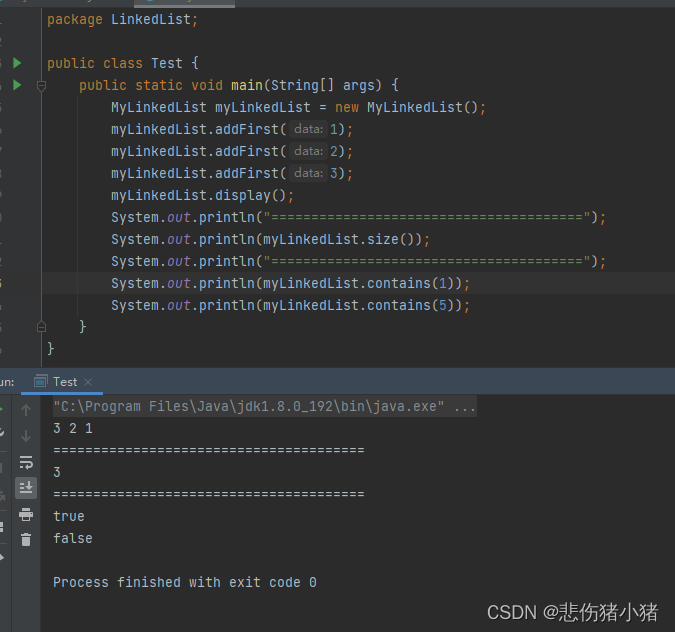
查找是否包含关键字key是否在单链表当中:
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key){
LinkNode cur = head;
while(cur != null) {
if(cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}
同样需要遍历链表,将节点的value的值跟需要查找的key值做比较,如果相同说明存在就返回true如果cur == null说明遍历完链表没有与key相同的元素,就返回false。
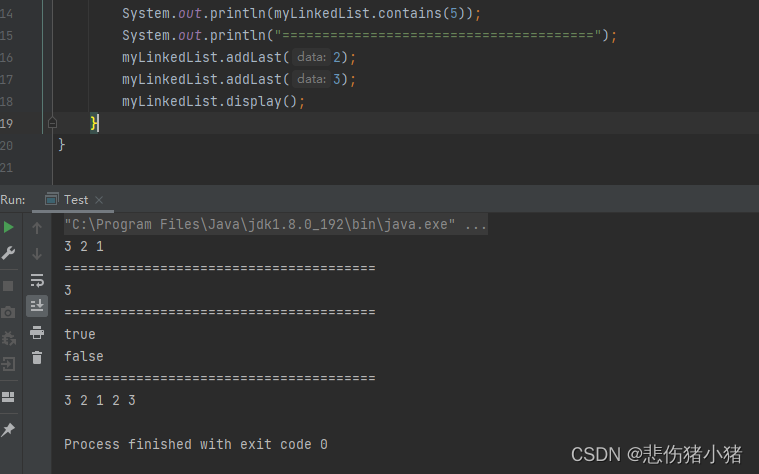
尾插法:
既然我们有头插法,那肯定会有尾插法,在链表最后插入元素:
//尾插法
public void addLast(int data){
LinkNode newNode = new LinkNode(data);
if(head == null) {
newNode = head;
}
LinkNode cur = head;
while (cur.next != null) {//找到最后一个结点停下来
cur = cur.next;
}
cur.next = newNode;
}
跟头插法一样,我们还是需要新建一个节点用于储存新的元素,如果链表为空,那么新插入的节点就是我们假设的头节点,如果不为空,那就遍历链表找到最后一个节点,让最后一个节点的next指向新的结点。

任意位置插入,第一个数据节点为0号下标:
//任意位置插入,第一个数据节点为0号下标
public void addIndex(int index,int data){
try {
checkIndex(index);
} catch (ListIndexException ex) {
ex.printStackTrace();
}
if(index == 0) {
addFirst(data);
return ;
}
if(index == size()) {
addLast(data);
return ;
}
LinkNode tmp = FindIndexNode(index);
LinkNode newNode = new LinkNode(data);
newNode.next = tmp.next;
tmp.next = newNode;
}
private LinkNode FindIndexNode(int index) {//找到index位置的前一个结点
LinkNode cur = head;
int count = 0;
while (count != index - 1) {
cur = cur.next;
count++;
}
return cur;
}
private void checkIndex(int index) throws ListIndexException{
if(index < 0 || index > size()) {
throw new ListIndexException("index下标错误");
}
}
首先我们需要插入的位置进行判断是否合法,其次如果index为0那么就是头插,如果index为链表的长度,那就是尾插,如果是其他位置就需要,找到该位置的前一个位置停下来,让新节点的next指向index位置的节点,让index - 1位置的节点的next指向新节点,就完成了插入。

注意节点next的赋值顺序不能交换,如果先把index - 1位置结点的next替换为newNode就找不到index位置节点的地址了。
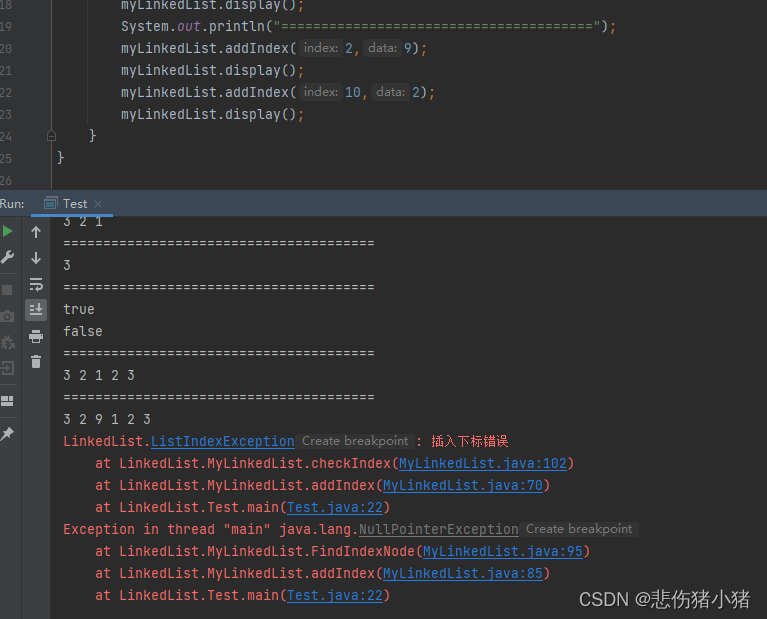
删除第一次出现关键字为key的节点:
//删除第一次出现关键字为key的节点
public void remove(int key){
if(head == null) {
return ;
}
if(head.val == key) {
head = head.next;
}
LinkNode prev = SearchRemoveNode(key);
if(prev == null) {
System.out.println("没有要删除的结点");
return ;//没有要删除的结点
}
LinkNode del = prev.next;
prev.next = del.next;
}
private LinkNode SearchRemoveNode(int key) {
LinkNode cur = head;
while (cur.next != null) {
if(cur.next.val == key) {//找到要删除结点的前一个结点
return cur;
}
cur = cur.next;
}
return null;
}
首先我们需要进行判断,如果链表为空那么就返回,说明没有要删除的元素,如果头节点为该元素那么就让头节点向后移动一下,判断都不符合之后,我们需要找到要删除元素的前一个元素,将前一个元素的next改为要删除元素的next就完成了删除。

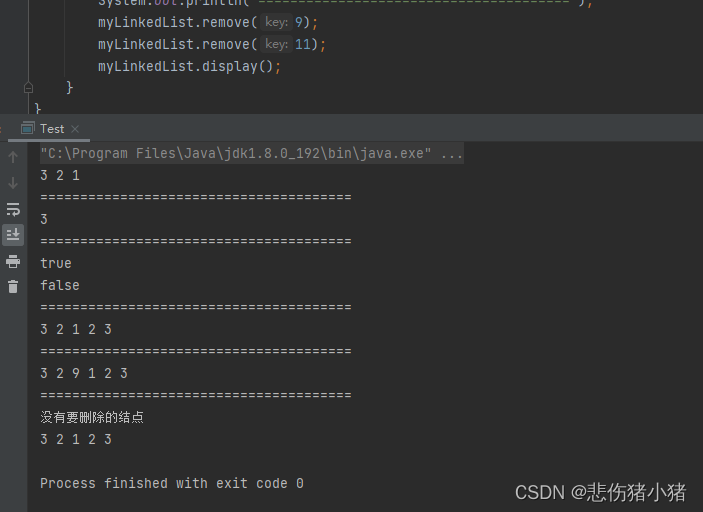
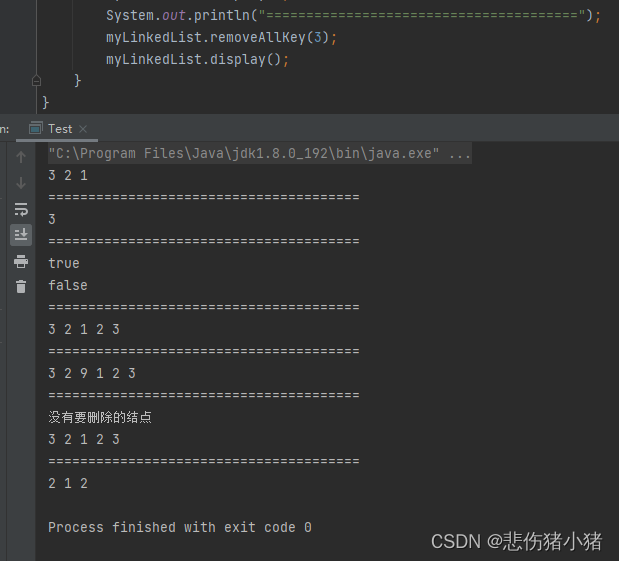
删除所有值为key节点:
//删除所有值为key的节点
public void removeAllKey(int key){
if(head == null) {
return ;
}
LinkNode prev = head;
LinkNode cur = head.next;
while(cur != null) {
if(cur.val == key) {
prev.next = cur.next;
cur = cur.next;
}else {
prev = cur;
cur = cur.next;
}
}
if(head.val == key) {
head = head.next;
}
}
使用的逻辑跟删除一个元素是一样的,我们只需要遍历链表,找到需要删除的元素时执行一次删除一个元素的逻辑,就可以了,值得注意的是每次删除元素后不要第一时间将prev == cur因为可能删除后的cur还是一个需要删除的节点,在进行判断当前cur节点不是删除元素后在进行操作,这样遍历完后除了head结点剩下的节点中值为key的都被删除了,最后判断一下head节点是否需要删除,就完成了删除所有值为key的节点。
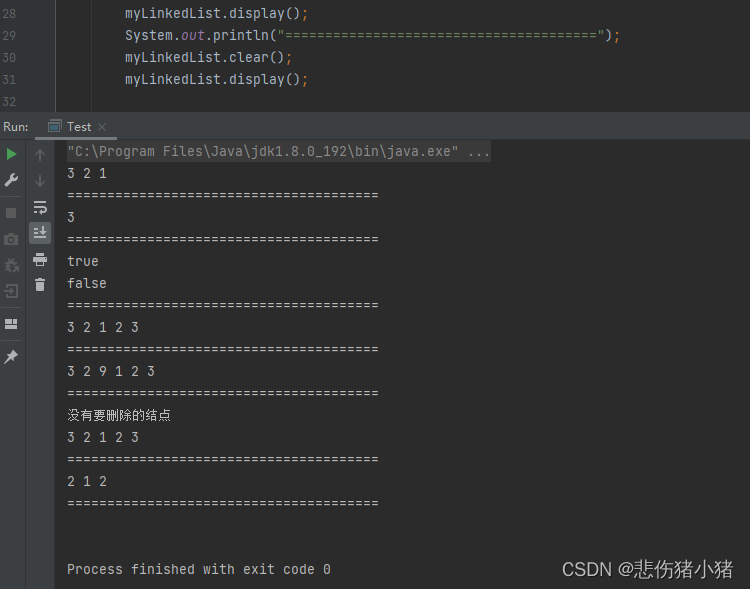
清空链表:
public void clear() {
head = null;
}
因为无论干什么都需要通过head节点来访问,将head置为null后面的节点也就都找不到了,达成了清空链表的需求。
以上就是链表的基础知识。