前言
这两个函数优点是通过GPU 运算速度快
目录:
1 where
2 Gather
一 where
原理:
torch.where(condition,x,y)
输入参数:
condition: 判断条件
x,y: Tensor
返回值:
符合条件时: 取x, 不满足取y
优点: 可以使用GPU,加快运算速度
# -*- coding: utf-8 -*-
"""
Created on Thu Dec 22 21:48:02 2022
@author: cxf
"""
import torch
def statistics():
ans = torch.rand(4,2)
x = torch.tensor([[1,2],
[1,2],
[1,2],
[1,2]])
y = torch.tensor([[3,4],
[3,4],
[3,4],
[3,4]])
out =torch.where(ans>0.5,x,y)
print("\n ans: \n",ans)
print("\n out: \n",out)
statistics()

二 Gather
输入:
Input
函数说明:
data. gather(dim=d, index=idx)
输入参数:
index: 映射的索引值
data 的shape 和 index的shape 必须一致
但是各维度的size 可以不一致
dim:
映射的维度
输出参数
输出张量的shape 的大小和index 一样
例一 dim =0
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 28 15:34:09 2022
@author: chengxf2
"""
import torch
def gather():
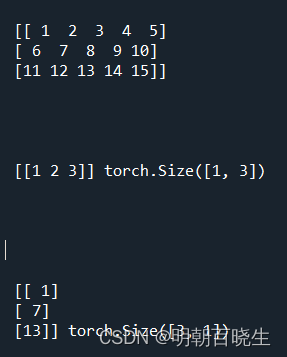
data = torch.arange(1, 16, 1).view(3,5)
print("\n\n",data.numpy())
idx = torch.LongTensor([[0,0,1]])
idx1 = torch.LongTensor([[0],
[0],
[2]])
a = data.gather(dim=0, index= idx)
b = data.gather(dim=0, index= idx1)
print("\n\n\n\n",a.numpy(),idx.shape)
print("\n\n\n\n\n",b.numpy(),idx1.shape)
gather()data 的shape [3,5]

idx=[[0,0,2]] shape [1,3]

0,0,1 分别代表取data[0,:] data[0,:] .data[1,:],
对应列为索引所在的位置 [0,0,1] 所在位置分别为 【0,1,2】
输出为:

同理 idx1=[[0],[0],[2]],shape: torch.Size([3, 1])


例2 dim=1
def gather():
data = torch.arange(1, 16, 1).view(3,5)
print("\n\n",data.numpy())
idx = torch.LongTensor([[0,1,2]])
idx1 = torch.LongTensor([[0],
[1],
[2]])
a = data.gather(dim=1, index= idx)
b = data.gather(dim=1, index= idx1)
print("\n\n\n\n",a.numpy(),idx.shape)
print("\n\n\n\n\n",b.numpy(),idx1.shape)index 内元素值指定所在列,
行是由index 元素所在行指定
输出的shape 保持一致