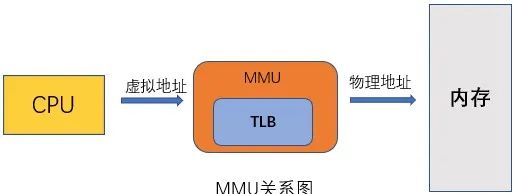
最近一直在学习内存管理,也知道MMU是管理内存的映射的逻辑IP,还知道里面有个TLB。
今天刚刚好看到了几篇前辈的文章,很是不错,于是这里来一起学习一下吧。
PART 一:MMU 架构篇
MMU(Memory Management Unit,内存管理单元)是一种硬件模块,用于在CPU和内存之间实现虚拟内存管理。
其主要功能是将虚拟地址转换为物理地址,同时提供访问权限的控制和缓存管理等功能。
放在整个大系统多核架构里面,每个处理器内置了MMU模块,MMU模块包含了TLB和TWU两个子模块。

1-宏观理解
地址空间是一个抽象的概念,由CPU体系架构的地址总线决定,一般等同于CPU的寻址范围、x位处理器中的x。地址空间一般分为 虚拟地址空间 和 物理地址空间 。
任何时候,计算机上都存在一个程序能够访问的地址集合,我们称之为地址空间。这个空间的大小由CPU的位数决定,例如一个32位的CPU,它的地址范围是0 ~ 0xFFFFFFFF(4G),而对于一个64位的CPU,它的地址范围为0 ~ 0xFFFFFFFFFFFFFFFF。
这个空间就是我们的程序能够产生的地址范围,我们把这个地址范围称为 虚拟地址空间 ,该空间中的某一个地址我们称之为虚拟地址。与虚拟地址空间和虚拟地址相对应的则是物理地址空间和物理地址,大多数时候我们的系统所具备的物理地址空间只是虚拟地址空间的一个子集。
举一个例子,对于一台内存为 256MB的 32bit x86主机来说,它的虚拟地址空间范围是 0 ~ 0xFFFFFFFF(4G),而物理地址空间范围是 0x000000000 ~ 0x0FFFFFFF(256MB)。
为什么需要这样的转换呢?其实这个就是现在多进程多线程、以及解决内存碎片化的途径。这里就不展开了。
虚拟地址又被简称为虚地址,物理地址又被称为实地址。虚拟地址和物理地址之间的转换,又称为虚实地址转化。
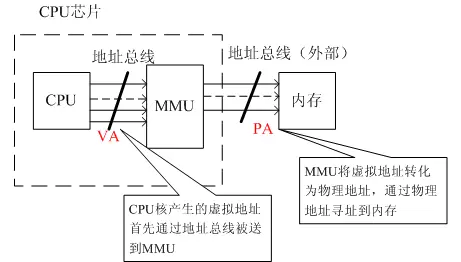
而这个转换的过程是硬件执行的:虚拟地址不是被直接送到内存地址总线上,而是送到内存管理单元MMU。他由一个或一组芯片组成,一般存在与协处理器中,其功能是把虚拟地址映射为物理地址。
2-微观理解
内存管理单元(MMU)的一个重要功能是使系统能够运行多个任务,作为独立的程序运行在他们自己的 私有虚拟内存空间。
它们不需要了解系统的物理内存图,即硬件实际使用的地址,也不需要了解可能在同一时间执行的其他程序。
所以在这种时候其实也要注意,你到底是使用的物理内存还是虚拟内存,使用的同一片内存,会不会出现踩踏内存的现象。

你可以为每个程序使用相同的虚拟内存地址空间。
你也可以使用一个连续的虚拟内存地图,即使物理内存是碎片化的。
这个虚拟地址空间与系统中的实际物理内存地图是分开的。
你可以编写、编译和链接应用程序以在虚拟内存空间中运行。
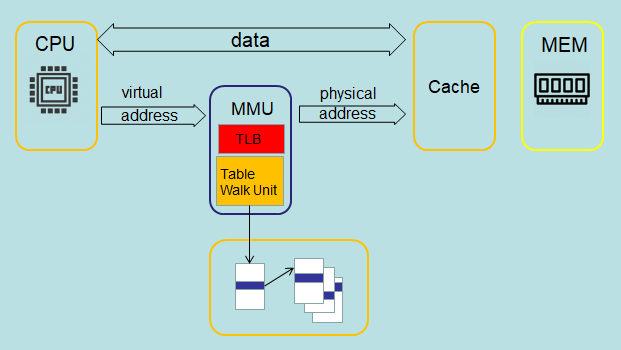
如下图所示的内存虚拟和物理视图的系统实例,一个系统中的不同处理器和设备可能有不同的虚拟和物理地址图。
操作系统对MMU进行编程,在这两个内存视图之间进行转换。

要做到这一点,虚拟内存系统中的硬件必须提供地址转换,即把处理器发出的虚拟地址转换为主内存中的物理地址。
虚拟地址是你、编译器和链接器在内存中放置代码时使用的地址。
物理地址是由实际的硬件系统使用的。
MMU使用虚拟地址的最重要的位来索引映射表中的条目,并确定哪个块被访问。
MMU将代码和数据的虚拟地址映射成实际系统中的物理地址。
这种转换是在硬件中自动进行的,对应用程序是透明的。
除了地址转换外,MMU还控制内存访问权限、内存排序和每个区域内存的缓存策略。
(安全地址与非安全地址的访问控制权限,检查页标签)
MMU使任务或应用程序的编写方式要求它们对系统的物理内存图或可能同时运行的其他程序一无所知。这使你可以为每个程序使用相同的虚拟内存地址空间。
它还允许你使用一个连续的虚拟内存地图,即使物理内存是碎片化的。这个虚拟地址空间与系统中的实际物理内存地图是分开的。应用程序被编写、编译和链接以在虚拟内存空间中运行。
这个就回到了我之前说的这个MMU本质上提供的能力。
相关视频推荐
搞懂底层原理-linux内核,高级程序员的必经之路:linux内核源码(进程管理、内存管理、网络协议栈、设备驱动、文件系统)![]() https://www.bilibili.com/video/BV1Pd4y1H7aL/
https://www.bilibili.com/video/BV1Pd4y1H7aL/
Linux C/C++开发(后端/音视频/游戏/嵌入式/高性能网络/存储/基础架构/安全)
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

1-CPU发出的虚拟地址
CPU发出的虚拟地址由两部分组成:VPN和offset,VPN(virtual page number)是页表中的条目number,而offset是指页内偏移。
最终转换后的物理地址也有两部分:PFN和offset,PFN( Physical frame number)是物理页框number,offset和上面虚拟地址的offset相同,是页内偏移。

2-MMU包含两个模块
MMU包含两个模块TLB(Translation Lookaside Buffer)和TWU(Table Walk Unit)。
TLB是一个高速缓存,用于缓存页表转换的结果,从而缩短页表查询的时间。
TWU是一个页表遍历模块,页表是由操作系统维护在物理内存中,但是页表的遍历查询是由TWU完成的,这样减少对CPU资源的消耗。
MMU由两部分组成:TLB(Translation Lookaside Buffer)和table walk unit。TLB 是一种地址转换cache,这里我们略过TLB的工作细节。
table walk unit在不同的CPU架构上有不同的叫法,但其作用是相同的,就是把内存页表走一走进行查表,完成虚拟地址到物理地址的转换。
3-访问权限控制
TrustZone技术之所以能提高系统的安全性,是因为对外部资源和内存资源的硬件隔离。这些硬件隔离包括中断隔离、片上RAM和ROM的隔离、片外RAM和ROM的隔离、外围设备的硬件隔离、外部RAM和ROM的隔离等。
实现硬件层面的各种隔离,需要对整个系统的硬件和处理器核做出相应的扩展。这些扩展包括:
-
• □ 对处理器核的虚拟化,也就是将AMR处理器的运行状态分为安全态和非安全态。
-
• □ 对总线的扩展,增加安全位读写信号线。
-
• □ 对内存管理单元(Memory Management Unit, MMU)的扩展,增加页表的安全位。
-
• □ 对缓存(Cache)的扩展,增加安全位。
-
• □ 对其他外围组件进行了相应的扩展,提供安全操作权限控制和安全操作信号。
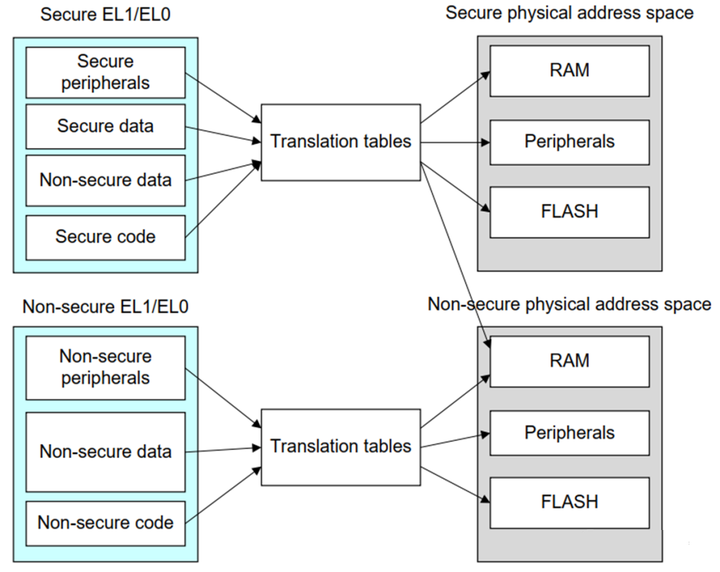
在支持TrustZone的SoC上,会对MMU进行虚拟化,使得寄存器TTBR0、TTBR1、TTBCR在安全状态和非安全状态下是相互隔离的,因此两种状态下的虚拟地址转换表是独立的。
存放在MMU中的每一条页表描述符都会包含一个安全状态位,用以表示被映射的内存是属于安全内存还是非安全内存。
虚拟化的MMU共享转换监测缓冲区(Translation Lookaside Buffer, TLB),同样TLB中的每一项也会打上安全状态位标记,只不过该标记是用来表示该条转换是正常世界状态转化的还是安全世界状态转化的。
Cache也同样进行了扩展,Cache中的每一项都会按照安全状态和非安全状态打上对应的标签,在不同的状态下,处理器只能使用对应状态下的Cache。
在REE(linux)和TEE(optee)双系统的环境下,可同时开启两个系统的MMU。在secure和non-secure中使用不同的页表.secure的页表可以映射non-secure的内存,而non-secure的页表不能去映射secure的内存,否则在转换时会发生错误:
在EL2系统中,MMU地址转换时,会自动使用TTBR2_EL1指向的页表。
在EL3系统中,MMU地址转换时,会自动使用TTBR3_EL1指向的页表。
4-启用hypervisor
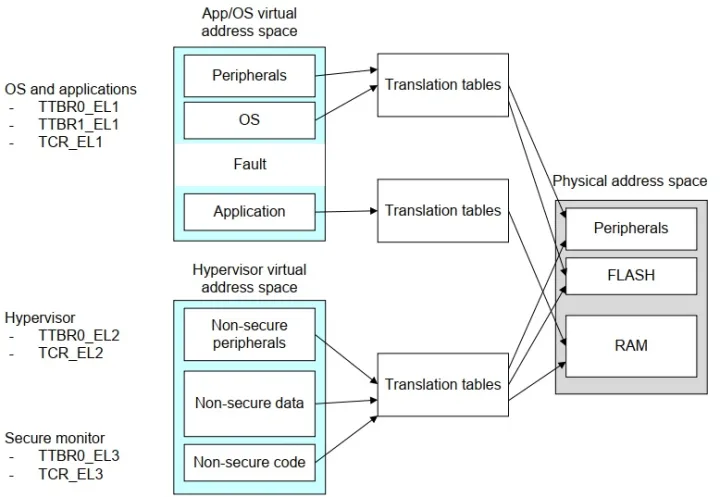
如果启用了hypervisor那么虚拟地址转换的过程将有VA—>PA变成了VA—>IPA—>PA, 也就是要经过两次转换.在guestos(如linux kernel)中转换的物理地址,其实不是真实的物理地址(假物理地址),然后在EL2通过VTTBR0_EL2基地址的页表转换后的物理地址,才是真实的硬件地址。
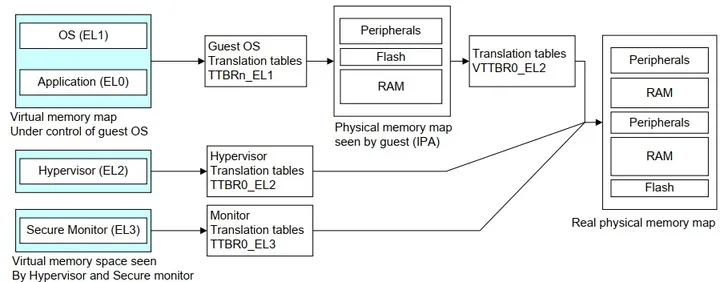
IPA : intermediate physical address5-MMU与C15协处理器
在ARM嵌入式应用系统中, 很多系统控制由ARM CP15协处理器来完成的。CP15协处理器包含编号0-15的16个32位的寄存器。例如,ARM处理器使用C15协处理器的寄存器来控制cache、TCM(Tightly-Coupled Memory)和存储器管理。
在这些C15寄存器中和MMU关系较大的有C2、C7、C17寄存器。
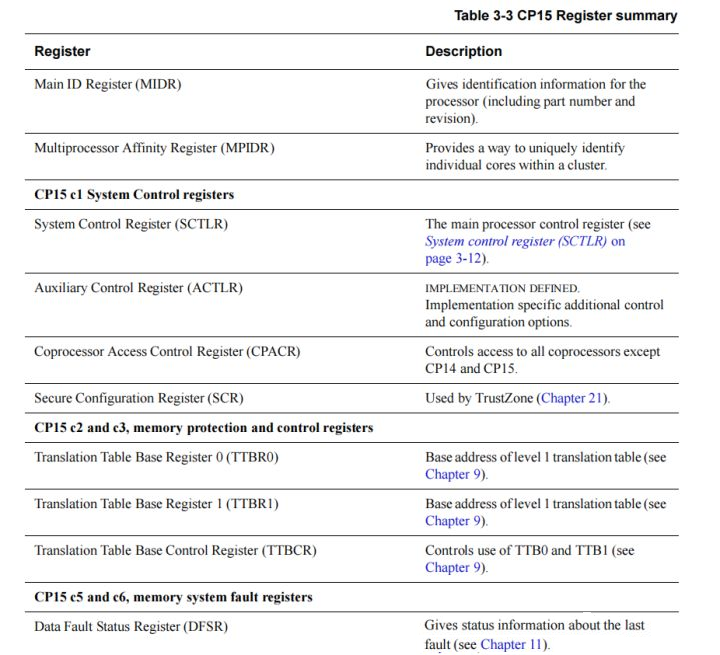
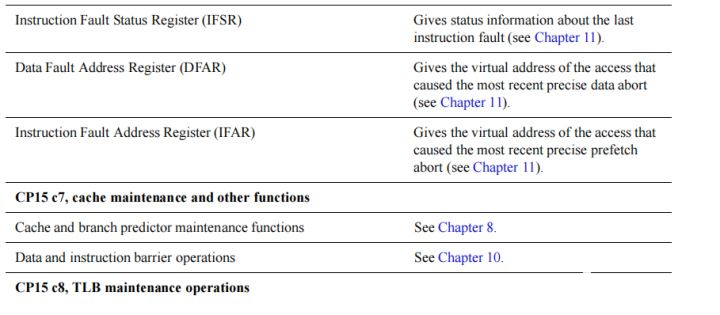

Memory protection and control registers,内存保护和控制寄存器,包含
-
• Translation Table Base Register 0 (TTBR0)、
-
• Translation Table Base Register 1 (TTBR1)
-
• Translation Table Base Control Register (TTBCR)。
TTBR0、TTBR1是L1转换页表的基地址,
TTCR控制TTBR0和TTBR1的使用。
-
• CP15 C7寄存器 Cache and branch predictor maintenance functions、Data and instruction barrier operations用于高速缓存和写缓存控制。
-
• CP15 C13寄存器 Context ID Register (CONTEXTIDR)、Software thread ID registers用于保存进程标识符(asid地址空间编号)
6-TLB缓存
1-为什么要有TLB
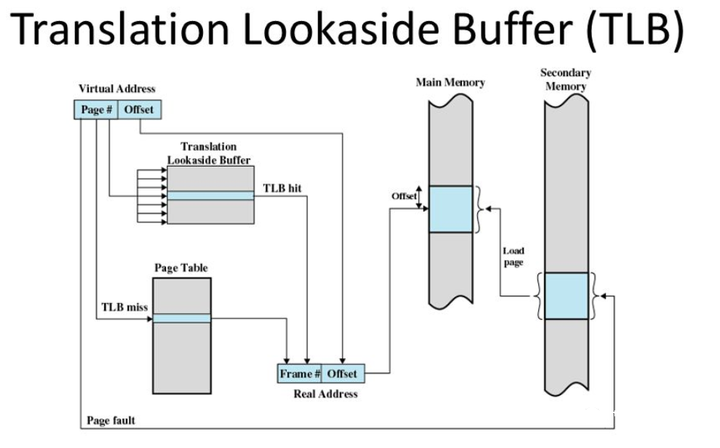
TLB 是 translation lookaside buffer 的简称。首先,我们知道 MMU 的作用是把虚拟地址转换成物理地址。

虚拟地址和物理地址的映射关系存储在页表中,而现在页表又是分级的。
64 位系统一般都是 3~5 级。
常见的配置是 4 级页表,就以 4 级页表为例说明。
分别是 PGD、PUD、PMD、PTE 四级页表。
在硬件上会有一个叫做页表基地址寄存器,它存储 PGD 页表的首地址。
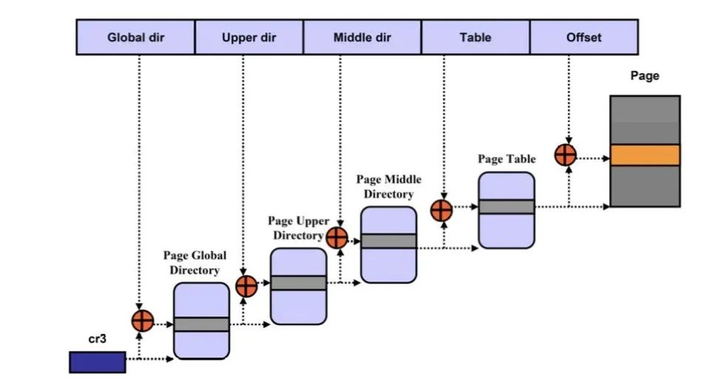
MMU 就是根据页表基地址寄存器从 PGD 页表一路查到 PTE,最终找到物理地址(PTE页表中存储物理地址)。
这就像在地图上显示你的家在哪一样,我为了找到你家的地址,先确定你是中国,再确定你是某个省,继续往下某个市,最后找到你家是一样的原理。一级一级找下去。(这个比喻真的不错)
这个过程你也看到了,非常繁琐。如果第一次查到你家的具体位置,我如果记下来你的姓名和你家的地址。下次查找时,是不是只需要跟我说你的姓名是什么,我就直接能够告诉你地址,而不需要一级一级查找。
四级页表查找过程需要四次内存访问。延时可想而知,非常影响性能。页表查找过程的示例如下图所示。以后有机会详细展开,这里了解下即可。
2-TLB 的本质是什么
TLB 其实就是一块高速缓存。
数据 cache 缓存地址(虚拟地址或者物理地址)和数据。TLB 缓存虚拟地址和其映射的物理地址。TLB 根据虚拟地址查找 cache,它没得选,只能根据虚拟地址查找。
所以 TLB 是一个虚拟高速缓存。硬件存在 TLB 后,虚拟地址到物理地址的转换过程发生了变化。虚拟地址首先发往 TLB 确认是否命中 cache,如果 cache hit 直接可以得到物理地址。
否则,一级一级查找页表获取物理地址。并将虚拟地址和物理地址的映射关系缓存到 TLB 中。
7-TWU
table walk unit:包含从内存中读取translation tables的逻辑
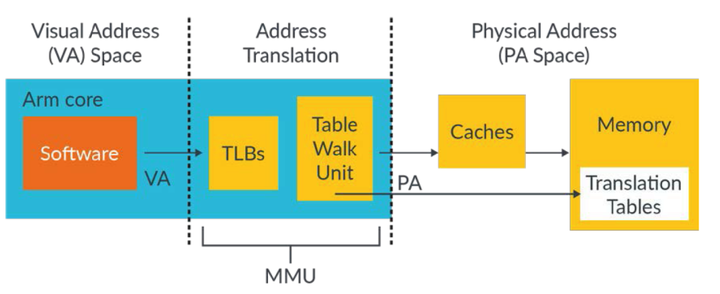
一个完整的页表翻译和查找的过程叫作页表查询(Translation Table Walk),页表查询的过程由硬件自动完成,但是页表的维护需要软件来完成。
页表查询是一个相对耗时的过程,理想的状态是TLB里缓存有页表转换的相关信息。当TLB未命中时,才会去查询页表,并且开始读入页表的内容。
page table
page table是每个进程独有的,是软件实现的,是存储在main memory(比如DDR)中的
Address Translation
因为访问内存中的页表相对耗时,尤其是在现在普遍使用多级页表的情况下,需要多次的内存访问,为了加快访问速度,系统设计人员为page table设计了一个硬件缓存 - TLB,CPU会首先在TLB中查找,因为在TLB中找起来很快。TLB之所以快,一是因为它含有的entries的数目较少,二是TLB是集成进CPU的,它几乎可以按照CPU的速度运行。
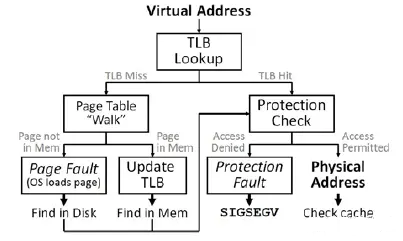
如果在TLB中找到了含有该虚拟地址的entry(TLB hit),则可从该entry中直接获取对应的物理地址,否则就不幸地TLB miss了,就得去查找当前进程的page table。这个时候,组成MMU的另一个部分table walk unit就被召唤出来了,这里面的table就是page table。
使用table walk unit硬件单元来查找page table的方式被称为hardware TLB miss handling,通常被CISC架构的处理器(比如IA-32)所采用。它要在page table中查找不到,出现page fault的时候才会交由软件(操作系统)处理。
与之相对的通常被RISC架构的处理器(比如Alpha)采用的software TLB miss handling,TLB miss后CPU就不再参与了,由操作系统通过软件的方式来查找page table。使用硬件的方式更快,而使用软件的方式灵活性更强。IA-64提供了一种混合模式,可以兼顾两者的优点。
如果在page table中找到了该虚拟地址对应的entry的p(present)位是1,说明该虚拟地址对应的物理页面当前驻留在内存中,也就是page table hit。找到了还没完,接下来还有两件事要做:
-
• 既然是因为在TLB里找不到才找到这儿来的,自然要更新TLB。
-
• 进行权限检测,包括可读/可写/可执行权限,user/supervisor模式权限等。如果没有正确的权限,将触发SIGSEGV(Segmantation Fault)。
如果该虚拟地址对应的entry的p位是0,就会触发page fault,可能有这几种情况:
-
• 这个虚拟地址被分配后还从来没有被access过(比如malloc之后还没有操作分配到的空间,则不会真正分配物理内存)。触发page fault后分配物理内存,也就是demand paging,有了确定的demand了之后才分,然后将p位置1。
-
• 对应的这个物理页面的内容被换出到外部的disk/flash了,这个时候page table entry里存的是换出页面在外部swap area里暂存的位置,可以将其换回物理内存,再次建立映射,然后将p位置1。
后面再进一步就是看看这个TLB中具体是怎么找的,在page table中又是怎么"walk",这部分就是具体的地址是怎么转换的,翻译的。
虚拟地址转换的具体实现就在下面的PART 二。
有了这些基础之后我们来看看MMU内存是怎么分配的。
PART 二:MMU 使用篇
这部分可以了解CPU访问的虚拟地址是怎么转换成物理地址,然后通过物理地址在cache、主存或者EMMC中获取相应的数据。
1-MMU相关的基本概念
(1)虚拟地址相关基本概念
-
• 虚拟内存(Virtual Memory,VM):为每个进程提供了一致的、连续的、私有的内存空间,简化了内存管理。将主存看成是一个存储在磁盘上的地址空间的高速缓存,当运行多个进程或者一个进程需要更多的空间时,主存显然是不够用的,这时需要更大、更便宜的磁盘保存一部分数据。
-
• 虚拟地址空间(Virtual Address Space,VAS):每个进程独有。
-
• 虚拟页(Virtual Page,VP):把虚拟内存按照页表大小进行划分。
-
• 虚拟地址(Virtual Address,VA):处理器看到的地址。
-
• 虚拟页号(Virtual Page Number,VPN):用于定位页表的PTE。 (2)物理地址相关的基本概念
-
• 物理内存(Physical Memory,PM):主存上能够使用的物理空间。
-
• 物理页(Physical Page):把物理内存按照页表的大小进行划分。
-
• 物理地址(Physical Address,PA):物理内存划分很多块,通过物理内存进行定位。
-
• 物理页号(Physical Page Number,PPN):定位物理内存中块的位置。 (3)页表相关的基本概念
-
• 页表(Page Table):虚拟地址与物理地址映射表的集合。
-
• 页表条目(Page Table Entry,PTE):虚拟地址与独立地址具体对应的记录。
-
• 页全局目录(Page Global Directory,PGD):多级页表中的最高一级。
-
• 页上级目录(Page Upper Directory,PUD):多级页表中的次高一级。
-
• 页中间目录(Page Middle Directory,PMD):多级页表中的一级。
2-页命中、缺页
(1)页命中

-
• a) 处理器要对虚拟地址VA进行访问。
-
• b) MMU的TLB没有命中,通过TWU遍历主存页表中的PTEA(PTE地址)。
-
• c) 主存向MMU返回PTE。
-
• d) MMU通过PTE映射物理地址,并把它传给高速缓存或主存。
-
• e) 高速缓存或主存返回物理地址对应的数据给处理器。
(2)缺页
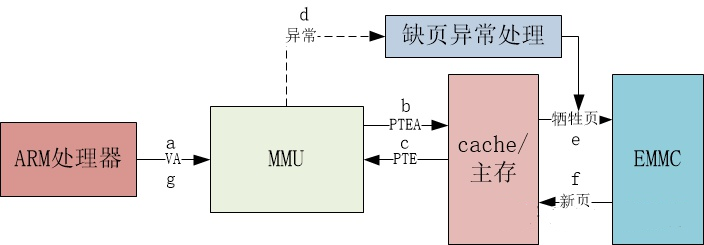
-
• a) 处理器要对虚拟地址VA进行访问。
-
• b) MMU的TLB没有命中,通过TWU遍历主存页表中的PTEA(PTE地址)。
-
• c) 主存向MMU返回PTE。
-
• d) PTE中有效位是0,MMU触发一次异常,CPU相应缺页异常,运行相应的处理程序。
-
• e) 缺页异常处理程序选出物理内存中的牺牲页,若这个页面已经被修改,将其换出到EMMC。
-
• f) 缺页异常处理程序从EMMC中加载新的页面,并更新内存中页表的PTE。
-
• g) 缺页异常处理程序返回到原来的进程,再次执行导致缺页的指令。CPU将引起缺页异常的虚拟地址重新发给MMU。由于虚拟页面现在缓存在主存中,主存会将所请求的地址对应的内容返回给cache和处理器。
3-多级页表映射过程
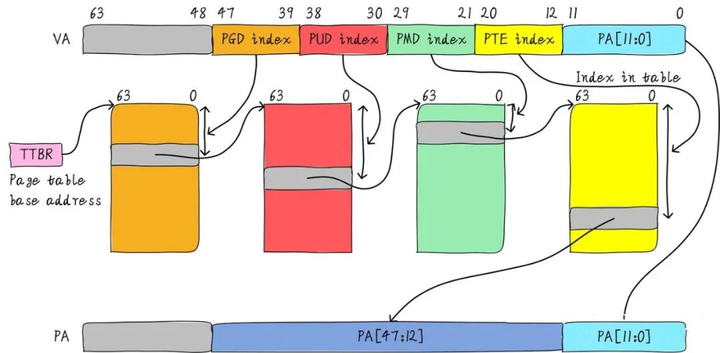
物理页面大小一级地址总线宽度不同,页表的级数也不同。以AArch64运行状态,4KB大小物理页面,48位地址宽度为例,页表映射的查询过程如图:

对于多任务操作系统,每个用户进程都拥有独立的进程地址空间,也有相应的页表负责虚拟地址到物理地址之间的转换。MMU查询的过程中,用户进程的一级页表的基址存放在TTBR0。操作系统的内核空间公用一块地址空间,MMU查询的过程中,内核空间的一级页表基址存放在TTBR1。当TLB未命中时,处理器查询页表的过程如下:
-
• 处理器根据虚拟地址第63位,来选择使用TTBR0或者TTBR1。当VA[63]为0时,选择TTBR0,TTBR中存放着L0页表的基址。
-
• 处理器以VA[47:39]作为L0的索引,在L0页表中查找页表项,L0页表有512个页表项。
-
• L0页表的页表项中存放着L1页表的物理基址。处理器以VA[38:30]作为L1索引,在L1页表中找到相应的页表项,L1页表中有512个页表项。
-
• L1页表的页表项中存放着L2页表的物理基址。处理器以VA[29:21]作为L2索引,在L2页表中找到相应的页表项,L2页表中有512个页表项。
-
• L2页表的页表项中存放着L3页表的物理基址。处理器以VA[20:12]作为L1索引,在L3页表中找到相应的页表项,L3页表中有512个页表项。
-
• L3页表的页表项里,存放着4KB页面的物理基址,然后加上VA[11:0],这样就构成了物理地址,至此处理器完成了一次虚拟地址到物理地址的查询与翻译的工作。
4-虚拟地址空间布局
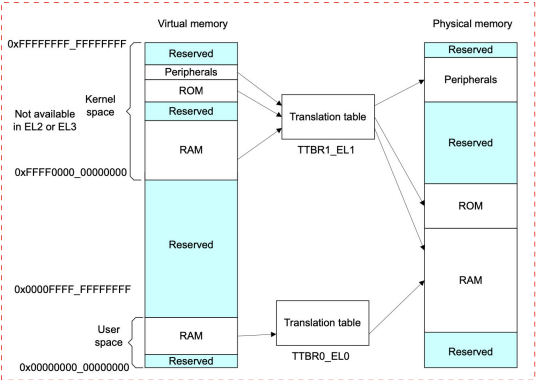
当然虚拟地址空间划分不只是如此。因为目前应用程序没有那么大的内存需求,所以ARM64处理器不支持完全的64位虚拟地址,实际支持情况如下。
(1)-虚拟地址位宽
虚拟地址的最大宽度是48位 内核虚拟地址在64位地址空间的顶部,高16位是全1,范围是[0xFFFF 0000 0000 0000,0xFFFF FFFF FFFF FFFF];
用户虚拟地址在64位地址空间的底部,高16位是全0,范围是[0x00000000 0000 0000,0x0000 FFFF FFFF FFFF];
高16位是全1或全0的地址称为规范的地址,两者之间是不规范的地址,不允许使用。
如果处理器实现了ARMv8.2标准的大虚拟地址(Large Virtual Address,LVA)支持,并且页长度是64KB,那么虚拟地址的最大宽度是52位。这个也就是大页表,可以提升内存与访问速度。
可以为虚拟地址配置比最大宽度小的宽度,并且可以为内核虚拟地址和用户虚拟地址配置不同的宽度。
转换控制寄存器(Translation Control Register)TCR_EL1的字段T0SZ定义了必须是全0的最高位的数量,字段T1SZ定义了必须是全1的最高位的数量,用户虚拟地址的宽度是(64-TCR_EL1.T0SZ),内核虚拟地址的宽度是(64-TCR_EL1.T1SZ)。(全是0是代表的用户,全是1代表的是内核。)
(2)编译ARM64架构的Linux内核时,可以选择虚拟地址宽度
-
• (1)如果选择页长度4KB,默认的虚拟地址宽度是39位。
-
• (2)如果选择页长度16KB,默认的虚拟地址宽度是47位。
-
• (3)如果选择页长度64KB,默认的虚拟地址宽度是42位。
-
• (4)可以选择48位虚拟地址。
在ARM64架构的Linux内核中,内核虚拟地址和用户虚拟地址的宽度相同。
-
• 所有进程共享内核虚拟地址空间,
-
• 每个进程有独立的用户虚拟地址空间,
-
• 同一个线程组的用户线程共享用户虚拟地址空间,内核线程没有用户虚拟地址空间。
小结
1-几个问题
(1)为什么没有MMU就无法运行Linux系统?
这是因为 Linux 内核将虚拟地址空间分为多个页面,并将这些页面映射到物理地址空间上,以实现内存隔离、保护和虚拟内存等功能。
没有 MMU,就无法实现这种映射,从而无法运行 Linux 系统。
(2)为什么有些较为简单的SOC可能没有MMU,但仍然可以运行一些嵌入式操作系统或者裸机程序?
RTOS可以运行在没有MMU的系统上,因为RTOS通常不需要进行内存保护和虚拟地址映射等高级特性。
相反,RTOS的设计侧重于实时性和低延迟,因此通常只需要简单的内存管理和任务调度即可。
这使得RTOS可以运行在许多嵌入式系统上,包括一些没有MMU的系统。
内存真的是一个非常非常有意思且丰富的东西,不是我这一篇能讲完的,这肯定还是差的蛮多的,文章有很多的内容来自于前辈的文章和博客。如果看完有一点点的收获,那肯定就是值了的。






![【MySQL语言汇总[DQL,DDL,DCL,DML]以及使用python连接数据库进行其他操作】](https://img-blog.csdnimg.cn/direct/ead04ef734e543e2a76936299d316fee.png)