MySQL语言汇总[DQL,DDL,DCL,DML]
- SQL分类
- 1.DDL:操作数据库,表
- 创建 删除 查询 修改
- 对数据库的操作
- 对表的操作
- 复制表(重点)!!!!!
- 2.DML:增删改表中数据
- 3.DQL:查询表中的记录
- 语法顺序
- 基础查询
- where 子句后面跟的条件
- if 和 case when语句
- 字符串函数拼接
- 聚合函数
- 分组查询
- 分页查询 limit
- 4.DCL (管理用户授权)
- 1.管理用户
- 添加,删除,修改,查询用户:
- 2.权限管理:
- 查询权限:
- 授予权限:
- 撤销权限:
- 5.多表查询
- 子查询
- 约束
- 主键约束
- 外键约束
- 6.用Python连接数据库进行调用和操作
SQL分类

1.DDL:操作数据库,表
创建 删除 查询 修改
对数据库的操作
# 创建数据库
create database 数据库名称;
# 查询数据库和表名
show databases;
show tables;
# 查看数据库的建库语句 表的建表语句
show create database 数据库名称;
show create table 表名称;
# 删除数据库
drop database 数据库名称;
# 使用数据库
use 数据库名称;
# 查看当前正在使用的数据库名称
select database();
# 修改数据库的字符集
alter database db4 character set utf8;
对表的操作
完整的建表语句

# 创建一个表
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
......
列名3 数据类型n
);
# 查询表
show tables;
# 查看表结构
show create table 表名;
# 修改表名
rename table 表名 to 新表名;
alter table 表名 rename to 新表名;
# 修改表的字符集
alter table 表名 character set 字符集名称;
# 查看某张表的字符集
show create table 表名;
# 添加一列
alter table 表名 add 列名 数据类型;
# 修改列名称 类型
alter table 表名 change 列名 新列名 新数据类型;
alter table 表名 modify 列名 新数据类型;
# 删除列
alter table 表名 drop 列名;
# 删除表
drop table 表名;
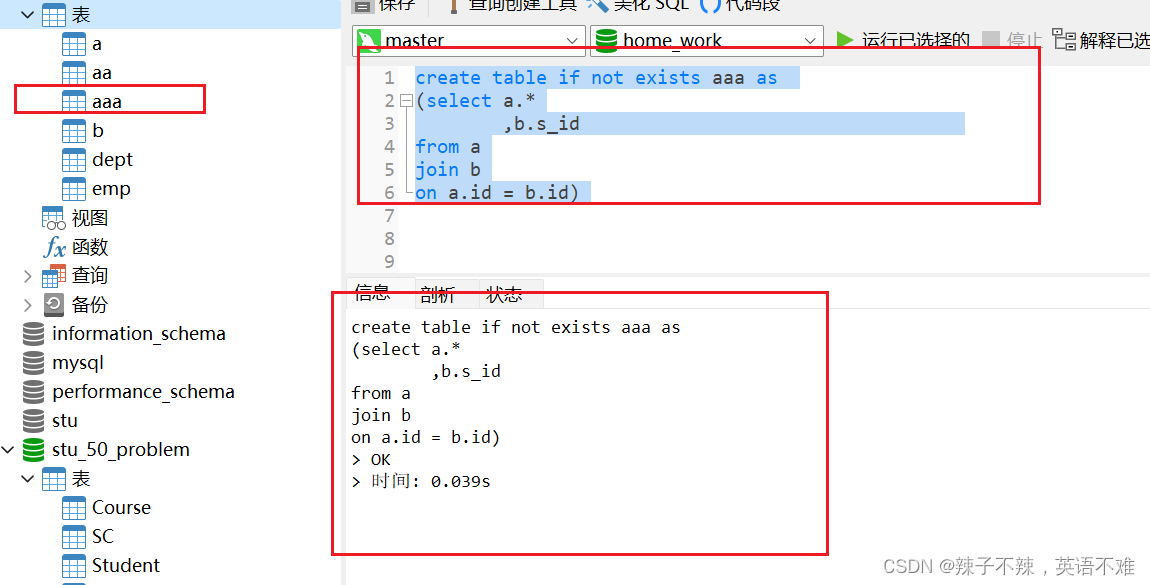
复制表(重点)!!!!!
-- 复制表的结构
create table if not exists 表名 like 被复制的表名;
-- 新建一个查询表的内容
create table if not exists 表名 as select语句;
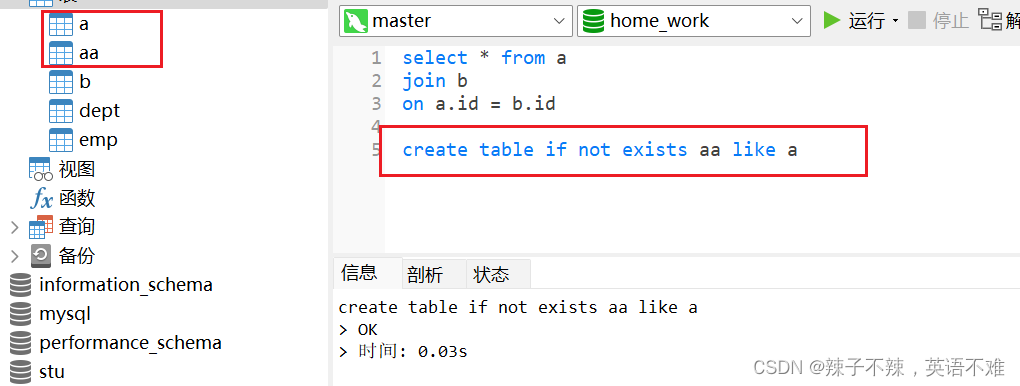
这个方法 就是把一个你想要的临时表变成一个表 保存起来非常好用!!!
2.DML:增删改表中数据
# 向表中添加数据
insert into 表名
(列名1,列名2,列名3,......,列名n)
values(值1,值2,......值n);
# insert select 将select查询出来的数据插入到目标表中
insert into 表名 select语句;
# 删除数据
delete from 表名 [where条件]; 如果没有where条件则是删除这个表中的所有记录
如果行删除所有记录推荐使用
truncate table 表名; (截断表 删除这个表在重新创建)
# 修改数据
update 表名 set 列名1 = 值1,列名2 = 值2,......[where条件];
如果不加where条件则是全部修改
3.DQL:查询表中的记录
语法顺序
select
字段列表
from
表名列表
where
条件列表
group by
分组字段
having
分组之后的条件
order by
排序
limit
分页限定
基础查询
# 多个字段的查询
select 字段名1,字段名2... from 表名;
去除重复:distinct 去除重复的数据 全部去重
# select 列的时候可以添加一些四则运算法则
select age + 4 as new_age from student;
# 排序查询
order by 排序字段1 排序方式1,排序字段2 排序方式2...;
DESC:降序
where 子句后面跟的条件
>、<、<=、>=、=、<> 可以用符号表示 大于小于
BETWEEN...AND 在这两个条件之间 !! 是左闭右闭的区间
IN(集合) -- 集合可以写成子查询 但是结果应该只有一列
LIKE:模糊查询
_:单个任意字符
%:多个任意字符
IS NULL
IS NOT NULL
count(字段名) 时注意null的列
注意 null 和 空字符串'' 的区别 null是什么都没有 ''这是空的字符串 是有东西的
and
or
not
# 举例
SELECT * FROM student WHERE age > 20;
SELECT * FROM student WHERE age >= 20;
SELECT * FROM student WHERE age =20;
SELECT * FROM student WHERE age != 20;
SELECT * FROM student WHERE age <> 20;
SELECT * FROM student WHERE age >=20 && age <=30;
SELECT * FROM student WHERE age >=20 AND age <=30;
SELECT * FROM student WHERE age BETWEEN 20 AND 30;
SELECT * FROM student WHERE age=22 OR age=20 OR age=25;
SELECT * FROM student WHERE age IN(22,18,55);
SELECT * FROM student WHERE english IS NOT NULL;
SELECT * FROM student WHERE NAME LIKE '马%'; # 匹配姓马的
SELECT * FROM student WHERE NAME LIKE "_化%"; #匹配名字第二个是化的
SELECT * FROM student WHERE NAME LIKE "___"; ## 匹配名字是三个的学生
SELECT * FROM student WHERE NAME LIKE "%景%"
show variables like "%char%"
if 和 case when语句
-- if(condition,true_act,false_act) 函数 case when 的写法
# 条件 true false
select *,IF(age > 22,"old",'young') as age_type from students;
# if 语句嵌套
select *,IF(age > 22,
# 年龄>22 并且>23 false 是年龄>22 但是<=23
if(age>23,'big old','little old'),
'young') as age_type from students;
# case when 语句 用end 结尾
select *,case when age=22 then "young"
when age=23 then 'little old'
when age=24 then 'big old'
else 'little young' end as type
from students;
字符串函数拼接
-- 字符串函数
-- 字符串拼接
-- concat(*strs) 如果字符串中有null 结果就是null
select CONCAT(name,',',gender,',','a') from students; # 将这些字符串合并起来成为一个
select CONCAT(name,gender,'a',null) from students;
-- CONCAT_WS(separator,str1,str2,...) 中间有分隔符 他会过滤null
select CONCAT_WS(',',name,gender,'a',null,'b') from students;
-- 字符串切分
-- SUBSTR(str FROM pos FOR len) , SUBSTR(str,pos),SUBSTR(str,pos,len)
select *,SUBSTR(name,2) from students; # 切分前两个
select *,SUBSTR(name,1,2) from students; # 从第一个开始 切两个
select *,SUBSTR(name from 1 for 2) from students;
select *,SUBSTRING(name,1,2) from students;
-- STRCMP 字符串对比
select *,STRCMP(SUBSTR(name,1,1),'施') from students;
# 切分第一个姓氏过后 与‘施’对比 选择施姓的
-- 数字类型的函数
select *,ABS(age),COS(age),LENGTH(clazz) from students;
聚合函数
将一列数据作为一个整体,进行纵向的计算
注意:聚合函数的计算,排除null值(可使用ifnull函数)
# max:计算最大值
SELECT MAX(math) FROM student;
# min:计算最小值
SELECT MIN(math) FROM student;
# sum:计算和
SELECT SUM(english) FROM student;
# avg:计算平均值
SELECT AVG(math) FROM student;
分组查询
语法:group by 分组字段
1.分组之后查询的字段:分组字段、聚合函数
2.where和having的区别?
where在分组之前进行限定,如果不满足条件,则不参与分组。
having在分组之后进行限定,如果不满足结果,则不会被查询出来
where后不可以跟聚合函数,having可以进行聚合函数的判断
# 按照性别分组,分别查询男、女同学的平均分
SELECT sex,AVG(math) FROM student GROUP BY sex;
# 按照性别分组,分别查询男、女同学的平均分,人数
SELECT sex,AVG(math),COUNT(id) FROM student GROUP BY sex;
# 按照性别分组,分别查询男、女同学的平均分,人数 要求:分数不低于70分的人,不参与分组。
SELECT sex,AVG(math),COUNT(id) FROM student WHERE math>70 GROUP BY sex;
# 按照性别分组,分别查询男、女同学的平均分,人数 要求:分数不低于70分的人,不参与分组,分组之后,人数大于2人。
SELECT sex,AVG(math),COUNT(id) FROM student WHERE math>70 GROUP BY sex HAVING COUNT(id)>2;
分页查询 limit
开始的索引 = (当前的页码 -1) * 每页显示的条数
SELECT * FROM student LIMIT 0,3; 第一页
SELECT * FROM student LIMIT 3,3; 第二页
SELECT * FROM student LIMIT 6,3; 第三页
4.DCL (管理用户授权)
1.管理用户
添加,删除,修改,查询用户:
关闭密码复杂验证
set global validate_password_policy=0;
set global validate_password_length=1;
# 用root用户添加一个新用户
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
例子:
CREATE USER 'zhangsan'@'localhost' IDENTIFIED BY '123';
CREATE USER 'lisi'@'%' IDENTIFIED BY '123';
# 删除用户
DROP USER '用户名'@'主机名';
例子:
DROP USER 'zhangsan'@'localhost';
# 修改用户密码
SET PASSWORD FOR '用户名'@'主机名' = PASSWORD('新密码');
例子:
set password for 'lisi'@'%' = password('234567');
# 查询用户
USE mysql;
select * from user;
通配符: % 表示可以在任意主机使用用户登录数据库
2.权限管理:
查询权限:
SHOW GRANTS FOR '用户名'@'主机名';
SHOW GRANTS FOR 'lisi'@'%';
授予权限:
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名' [with grant option];
例子:
-- 将数据库db3下account表的SELECT ,DELETE, UPDATE权限授予用户'lisi'@'%'
GRANT SELECT ,DELETE, UPDATE ON db3.account TO 'lisi'@'%';
-- 给zhangsan用户所有权限
GRANT ALL ON *.* TO 'zhangsan'@'localhost'
撤销权限:
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';
例子:
-- 将用户'lisi'@'%'对于表db3.account的更新权限撤销
REVOKE UPDATE ON db3.account FROM 'lisi'@'%';
-- 给lisi用户撤销所有权限
REVOKE ALL ON *.* FROM 'lisi'@'%';
5.多表查询
内连接 左连接 外连接
子查询
查询中嵌套查询,称嵌套查询为子查询
-- 查询工资最高的员工信息
-- 1.查询最高的工资是多少 9000
SELECT MAX(salary) FROM emp;
-- 2.查询员工信息,并且工资等于9000的
SELECT * FROM emp WHERE emp.salary=9000;
-- 一条sql就完成这个操作
SELECT * FROM emp WHERE emp.salary = (SELECT MAX(salary) FROM emp);
--子查询可以作为条件,使用运算符去判断。 运算符:> >= < <= =
--查询员工工资小于平均工资的人
SELECT * FROM emp WHERE emp.salary < (SELECT AVG(salary) FROM emp);
--子查询可以作为集合,使用in、not int
--查询财务部和市场部所有员工信息
SELECT id FROM dept WHERE `NAME`='财务部' OR `NAME`='市场部';
SELECT * FROM emp WHERE dept_id=3 OR dept_id=2;
--使用子查询
SELECT * FROM emp WHERE dept_id in (SELECT id FROM dept WHERE `NAME`='财务部' OR `NAME`='市场部');
--子查询可以作为一张虚拟表参与查询
--查询员工入职日期是2011-11-11日之后的员工信息和部门信息
-- 子查询
select * from dept t1 (select * from emp where emp.join_date > '2011-11-11') t2 where t1.id = t2.dept_id;
--普通内连接查询
select * from emp t1,dept t2 where t1.dept_id = t2.id and t1.join_date > '2011-11-11'
union 表的拼接 但是拼接时表的结构需要完全相同
* union 对数据进行去重
* union all
约束
主键约束
需要记住的为主键约束 : 条件 唯一 且非空
primary key
含义:非空且唯一
主键就是表中记录的唯一标识
CREATE TABLE stu (
id INT PRIMARY KEY, -- 给id添加主键约束
NAME VARCHAR(20)
);
ALTER TABLE stu DROP PRIMARY KEY; -- 去除主键
alter table stu modify id int; -- 移除not null的限约束
ALTER TABLE stu MODIFY id INT PRIMARY KEY;
外键约束
还有一个外键约束
foreign key,让表与表产生关系,从而保证数据的正确性。
create table 表名(
外键列
constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称)
);
添加级联操作
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY(外键列名称) REFERENCES 主表名称(主表列名称) ON UPDATE CASCADE ON DELETE CASCADE;
当修改一个表的值之后 另一个表的值也会修改 保证了数据的正确性