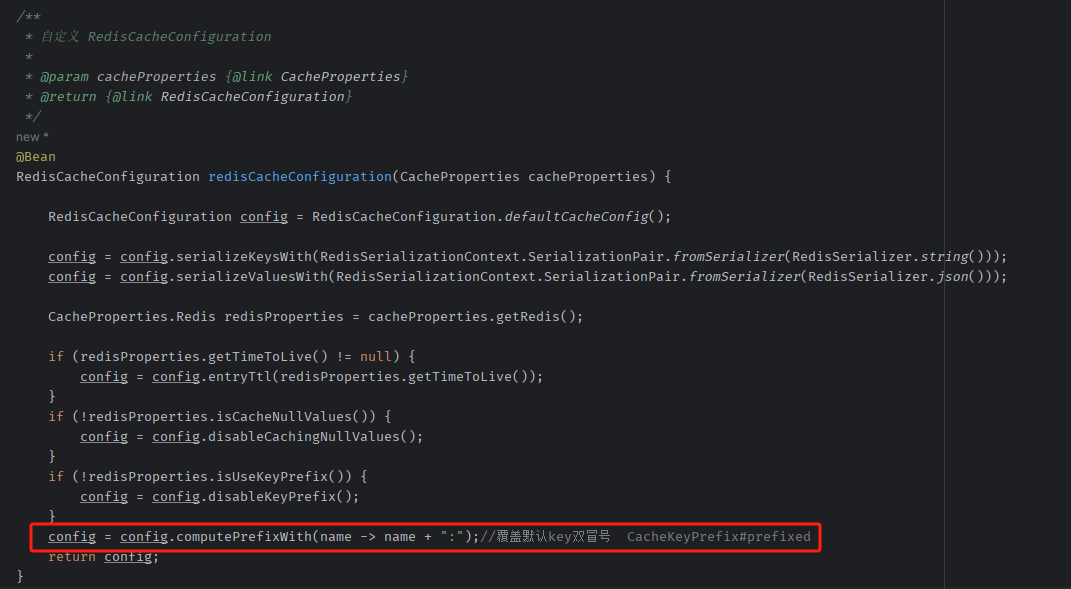
一、前言
关于序列化和反序列化的定义,在这篇文章中有详细介绍,此处简要说明:
- 序列化:将对象写入到 IO 流中
- 反序列化:从 IO 流中恢复对象
我们也可以借助下图来理解序列化和反序列化的过程。

二、Spark 的序列化器
Spark 提供了 2 个序列化库 (Java serialization 和 Kyro serialization),此外用户也可以自定义实现序列化:
- Java serialization (默认):Java 序列化非常灵活,但通常相当缓慢,而且会导致许多类的序列化格式过大。
- Kryo serialization (推荐使用):更快地序列化对象。Kryo 比 Java 序列化要快得多,也更紧凑(通常是 Java 序列化的 10 倍),但不支持所有可序列化类型,而且需要提前注册程序中使用的类,以便获得最佳性能。
- Custom Serializer
我们可以对比 Spark 使用了 Kyro Serialization 和 未使用