理论部分参考:李宏毅机器学习——对抗生成网络(GAN)_iwill323的博客-CSDN博客
目录
任务和数据集
评价方法
FID
AFD (Anime face detection) rate
DCGAN和WGAN
代码
导包
建立数据集
显示一些图片
模型设置
生成器
判别器
权重初始化
训练函数
训练
读取数据
Set config
推断
GAN效果
任务和数据集
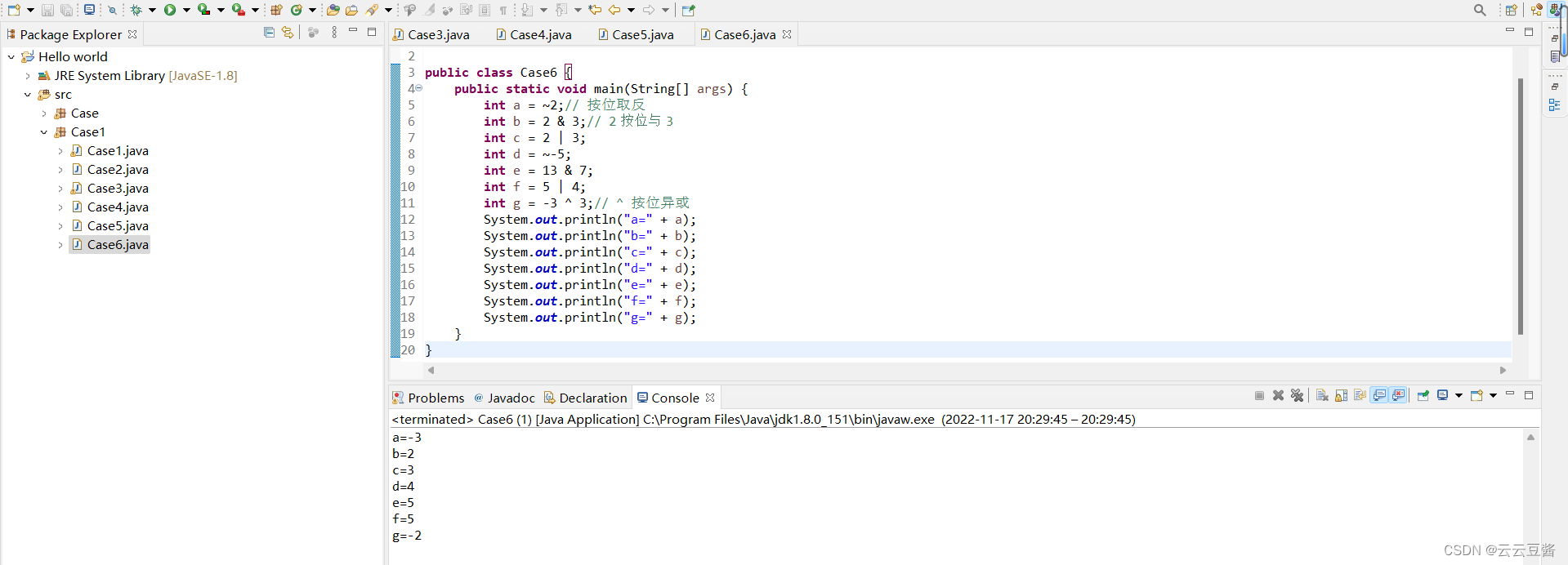
1. Input: 随机数,输入的维度是(batch size, 特征数)
2. Output: 动漫人物脸
3. Implementation requirement: DCGAN & WGAN & WGAN-GP
4. Target:产生1000动漫人物脸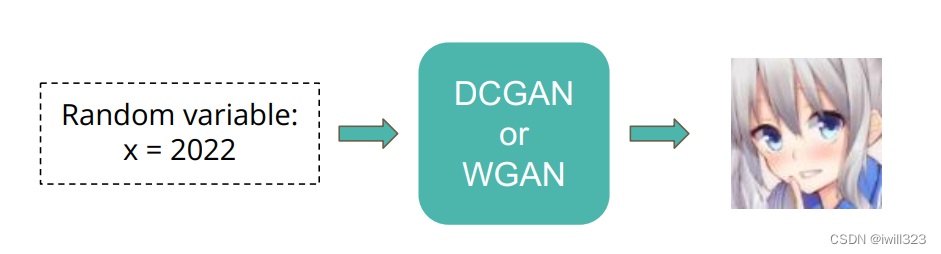
数据来自Crypko网站,有71,314个图像
评价方法
FID
将真假图片送入另一个模型,产生对应的特征,计算真假特征的距离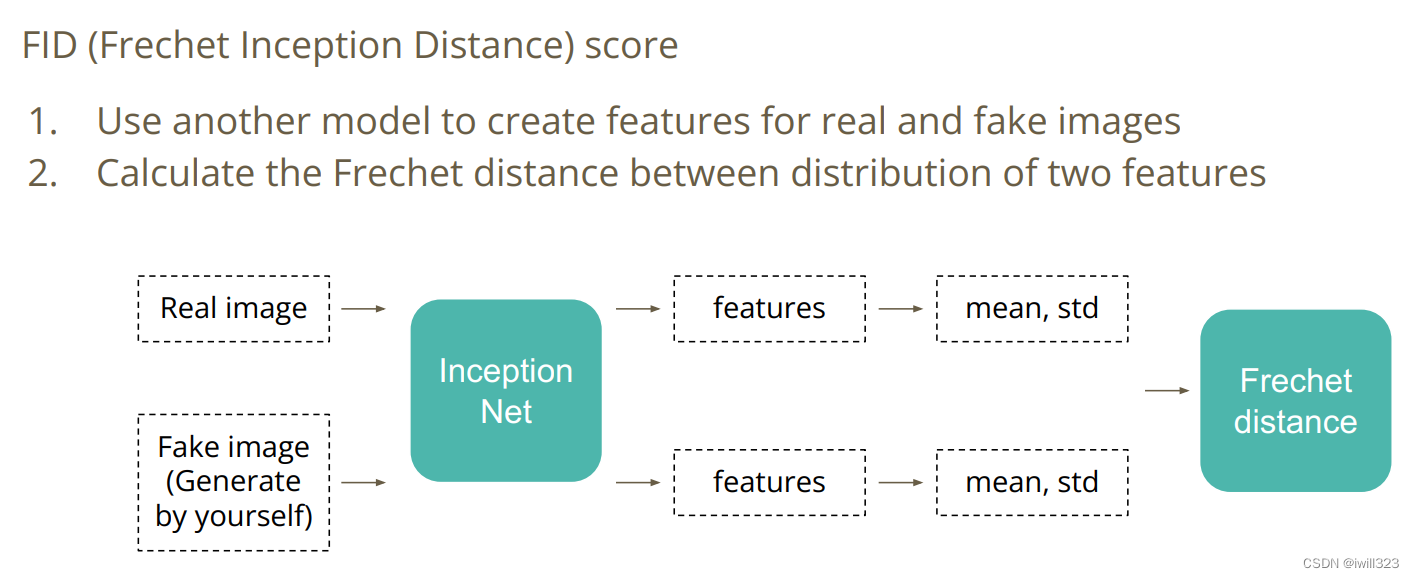
AFD (Anime face detection) rate
1. To detect how many anime faces in your submission
2. The higher, the better
DCGAN和WGAN


代码
导包
# import module
import os
import glob
import random
from datetime import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch import optim
from torch.utils.data import Dataset, DataLoader
from torch import autograd
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import logging
from tqdm import tqdm
from d2l import torch as d2l
# seed setting
def same_seeds(seed):
# Python built-in random module
random.seed(seed)
# Numpy
np.random.seed(seed)
# Torch
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
same_seeds(2022)
workspace_dir = 'data/faces'建立数据集
# prepare for CrypkoDataset
class CrypkoDataset(Dataset):
def __init__(self, fnames, transform):
self.transform = transform
self.fnames = fnames
self.num_samples = len(self.fnames)
def __getitem__(self,idx):
fname = self.fnames[idx]
img = Image.open(fname)
img = self.transform(img)
return img
def __len__(self):
return self.num_samples
def get_dataset(root):
# glob.glob返回匹配给定通配符的文件列表
fnames = glob.glob(os.path.join(root, '*')) # list
transform = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
])
dataset = CrypkoDataset(fnames, transform)
return dataset显示一些图片
temp_dataset = get_dataset(os.path.join(workspace_dir, 'faces'))
images = [temp_dataset[i] for i in range(4)]
grid_img = torchvision.utils.make_grid(images, nrow=4)
plt.figure(figsize=(10,10))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
模型设置
生成器
# Generator
class Generator(nn.Module):
"""
Input shape: (batch, in_dim)
Output shape: (batch, 3, 64, 64)
"""
def __init__(self, in_dim, feature_dim=64):
super().__init__()
#input: (batch, 100)
self.l1 = nn.Sequential(
nn.Linear(in_dim, feature_dim * 8 * 4 * 4, bias=False),
nn.BatchNorm1d(feature_dim * 8 * 4 * 4),
nn.ReLU()
)
self.l2 = nn.Sequential(
self.dconv_bn_relu(feature_dim * 8, feature_dim * 4), #(batch, feature_dim * 16, 8, 8)
self.dconv_bn_relu(feature_dim * 4, feature_dim * 2), #(batch, feature_dim * 16, 16, 16)
self.dconv_bn_relu(feature_dim * 2, feature_dim), #(batch, feature_dim * 16, 32, 32)
)
self.l3 = nn.Sequential(
nn.ConvTranspose2d(feature_dim, 3, kernel_size=5, stride=2,
padding=2, output_padding=1, bias=False),
nn.Tanh()
)
self.apply(weights_init)
def dconv_bn_relu(self, in_dim, out_dim):
return nn.Sequential(
nn.ConvTranspose2d(in_dim, out_dim, kernel_size=5, stride=2,
padding=2, output_padding=1, bias=False), #double height and width
nn.BatchNorm2d(out_dim),
nn.ReLU(True)
)
def forward(self, x):
y = self.l1(x)
y = y.view(y.size(0), -1, 4, 4)
y = self.l2(y)
y = self.l3(y)
return y判别器
# Discriminator
class Discriminator(nn.Module):
"""
Input shape: (batch, 3, 64, 64)
Output shape: (batch)
"""
def __init__(self, model_type, in_dim, feature_dim=64):
super(Discriminator, self).__init__()
#input: (batch, 3, 64, 64)
"""
Remove last sigmoid layer for WGAN
"""
self.model_type = model_type
self.l1 = nn.Sequential(
nn.Conv2d(in_dim, feature_dim, kernel_size=4, stride=2, padding=1), #(batch, 3, 32, 32)
nn.LeakyReLU(0.2),
self.conv_bn_lrelu(feature_dim, feature_dim * 2), #(batch, 3, 16, 16)
self.conv_bn_lrelu(feature_dim * 2, feature_dim * 4), #(batch, 3, 8, 8)
self.conv_bn_lrelu(feature_dim * 4, feature_dim * 8), #(batch, 3, 4, 4)
nn.Conv2d(feature_dim * 8, 1, kernel_size=4, stride=1, padding=0)
)
# WGAN的思路是将discriminator训练为距离函数,所以discriminator不需要最后的非线性sigmoid层
if self.model_type == 'GAN':
self.l1.add_module(
'sigmoid', nn.Sigmoid()
)
self.apply(weights_init)
def conv_bn_lrelu(self, in_dim, out_dim):
layer = nn.Sequential(
nn.Conv2d(in_dim, out_dim, 4, 2, 1),
nn.BatchNorm2d(out_dim),
nn.LeakyReLU(0.2),
)
if self.model_type == 'WGAN-GP':
layer[1] = nn.InstanceNorm2d(out_dim)
return layer
def forward(self, x):
y = self.l1(x)
y = y.view(-1)
return y权重初始化
# setting for weight init function
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)训练函数
- prepare_environment: prepare the overall environment, construct the models, create directory for the log and ckpt
- train: train for generator and discriminator, you can try to modify the code here to construct WGAN or WGAN-GP
- inference: after training, you can pass the generator ckpt path into it and the function will save the result for you
WGAN-GP部分运行不来,一个很大的问题是网上找到的代码,训练到10个epoch才能看到训练效果,之前全是噪音图,调试代价太大,不想改了。
class TrainerGAN():
def __init__(self, config, devices):
self.config = config
self.model_type = self.config["model_type"]
self.devices = devices
self.G = Generator(self.config["z_dim"])
self.D = Discriminator(self.model_type, 3) # 3代表输入通道数
self.loss = nn.BCELoss()
if self.model_type == 'GAN' or self.model_type == 'WGAN-GP':
self.opt_D = torch.optim.Adam(self.D.parameters(), lr=self.config["lr"], betas=(0.5, 0.999))
self.opt_G = torch.optim.Adam(self.G.parameters(), lr=self.config["lr"], betas=(0.5, 0.999))
elif self.model_type == 'WGAN':
self.opt_D = torch.optim.RMSprop(self.D.parameters(), lr=self.config["lr"])
self.opt_G = torch.optim.RMSprop(self.G.parameters(), lr=self.config["lr"])
self.dataloader = None
self.log_dir = os.path.join(self.config["save_dir"], 'logs')
self.ckpt_dir = os.path.join(self.config["save_dir"], 'checkpoints')
FORMAT = '%(asctime)s - %(levelname)s: %(message)s'
logging.basicConfig(level=logging.INFO,
format=FORMAT,
datefmt='%Y-%m-%d %H:%M')
self.steps = 0
self.z_samples = torch.randn(100, self.config["z_dim"], requires_grad = True).to(self.devices[0]) # 打印100个看看生成的效果
def prepare_environment(self):
"""
Use this funciton to prepare function
"""
os.makedirs(self.log_dir, exist_ok=True)
os.makedirs(self.ckpt_dir, exist_ok=True)
# update dir by time
time = datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
self.log_dir = os.path.join(self.log_dir, time+f'_{self.config["model_type"]}')
self.ckpt_dir = os.path.join(self.ckpt_dir, time+f'_{self.config["model_type"]}')
os.makedirs(self.log_dir)
os.makedirs(self.ckpt_dir)
# model preparation
self.G = self.G.to(self.devices[0])
self.D = self.D.to(self.devices[0])
self.G.train()
self.D.train()
def gp(self, r_imgs, f_imgs):
"""
Implement gradient penalty function
"""
Tensor = torch.FloatTensor
alpha = Tensor(np.random.random((r_imgs.size(0), 1, 1, 1))).to(devices[0])
interpolates = (alpha*r_imgs + (1 - alpha)*f_imgs).requires_grad_(True)
d_interpolates = self.D(interpolates)
fake = Tensor(r_imgs.shape[0]).fill_(1.0).to(devices[0])
fake.requires_grad = False
gradients = autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(1, dim=1) - 1)**2).mean()
return gradient_penalty
def train(self, dataloader):
"""
Use this function to train generator and discriminator
"""
self.prepare_environment()
legend = ['Gen loss', 'Dis acc']
animator = d2l.Animator(xlabel='epoch', xlim=[0, self.config["n_epoch"]], legend=legend)
num_batches = len(dataloader)
show_batch = num_batches // self.config["show_num"] # 多少batch打印一次loss
for e, epoch in enumerate(range(self.config["n_epoch"])):
progress_bar = tqdm(self.dataloader)
progress_bar.set_description(f"Epoch {e+1}")
for i, data in enumerate(dataloader):
bs = data.size(0) # batch size
# *********************
# * Train D *
# *********************
z = torch.randn(bs, self.config["z_dim"]).to(self.devices[0])
r_imgs = data.to(self.devices[0])
f_imgs = self.G(z)
# Discriminator forwarding
r_logit = self.D(r_imgs) # 判断真实图像
f_logit = self.D(f_imgs.detach()) # 判断生成的假图像 使用detach()是为了避免对G求导
# SETTING DISCRIMINATOR LOSS
if self.model_type == 'GAN':
r_label = torch.ones((bs)).to(self.devices[0])
f_label = torch.zeros((bs)).to(self.devices[0])
r_loss = self.loss(r_logit, r_label)
f_loss = self.loss(f_logit, f_label)
loss_D = (r_loss + f_loss) / 2
elif self.model_type == 'WGAN':
loss_D = -torch.mean(r_logit) + torch.mean(f_logit)
elif self.model_type == 'WGAN-GP':
loss_D = -torch.mean(r_logit) + torch.mean(f_logit) + self.gp(r_imgs, f_imgs) # 最后一项是gradient_penalty
# Discriminator backwarding
self.D.zero_grad()
loss_D.backward()
self.opt_D.step()
# SETTING WEIGHT CLIP:
if self.model_type == 'WGAN':
for p in self.D.parameters():
p.data.clamp_(-self.config["clip_value"], self.config["clip_value"])
# *********************
# * Train G *
# *********************
if self.steps % self.config["n_critic"] == 0:
# Generator forwarding
f_logit = self.D(f_imgs) # f_imgs没必要再生成一遍,甚至可以在训练前生成一个,来回使用
if self.model_type == 'GAN':
loss_G = self.loss(f_logit, r_label)
elif self.model_type == 'WGAN' or self.model_type == 'WGAN-GP':
loss_G = -torch.mean(self.D(f_imgs))
# Generator backwarding
self.G.zero_grad()
loss_G.backward()
self.opt_G.step()
loss_G_sum += loss_G.item()
if self.steps % 10 == 0:
progress_bar.set_postfix(loss_G=loss_G.item(), loss_D=loss_D.item())
self.steps += 1
self.G.eval()
# G()最后一层是tanh(), 输出是-1到1,也就是说,G()的输出要变成0-1才是图像
f_imgs_sample = (self.G(self.z_samples).data + 1) / 2.0
filename = os.path.join(self.log_dir, f'Epoch_{epoch+1:03d}.jpg')
torchvision.utils.save_image(f_imgs_sample, filename, nrow=10)
logging.info(f'Save some samples to {filename}.')
# Show some images during training.
grid_img = torchvision.utils.make_grid(f_imgs_sample.cpu(), nrow=10)
plt.figure(figsize=(10,10))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
self.G.train()
if (e+1) % 5 == 0 or e == 0:
# Save the checkpoints.
torch.save(self.G.state_dict(), os.path.join(self.ckpt_dir, f'G_{e}.pth'))
torch.save(self.D.state_dict(), os.path.join(self.ckpt_dir, f'D_{e}.pth'))
logging.info('Finish training')
def inference(self, G_path, n_generate=1000, n_output=30, show=False):
"""
1. G_path is the path for Generator ckpt
2. You can use this function to generate final answer
"""
self.G.load_state_dict(torch.load(G_path))
self.G.to(self.devices[0])
self.G.eval()
z = torch.randn(n_generate, self.config["z_dim"]).to(self.devices[0])
imgs = (self.G(z).data + 1) / 2.0
os.makedirs('output', exist_ok=True)
for i in range(n_generate):
torchvision.utils.save_image(imgs[i], f'output/{i+1}.jpg')
if show:
row, col = n_output//10 + 1, 10
grid_img = torchvision.utils.make_grid(imgs[:n_output].cpu(), nrow=row)
plt.figure(figsize=(row, col))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()训练
读取数据
devices = d2l.try_all_gpus()
print(f'DEVICE: {devices}')
# create dataset by the above function
batch_size = 512
num_workers = 4
dataset = get_dataset(os.path.join(workspace_dir, 'faces'))
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last = True)
print('训练集总长度是 {:d}, batch数量是 {:.2f}'.format(len(dataset), len(dataset)/batch_size))Set config
config = {
"model_type": "WGAN",
"lr": 1e-4,
"n_epoch": 60,
"n_critic": 5, # 训练一次generator,多训练几次discriminator,效果更好 n_critic=5意味着训练比是1:5
"z_dim": 100,
"workspace_dir": workspace_dir, # define in the environment setting
"save_dir": workspace_dir,
'clip_value': 1,
'show_num': 12
}
trainer = TrainerGAN(config, devices)
trainer.train(dataloader)推断
# save the 1000 images into ./output folder
trainer.inference(f'{workspace_dir}/checkpoints/2022-03-31_15-59-17_GAN/G_0.pth') # you have to modify the path when running this lineGAN效果
下面是GAN产生的图片,效果挺一般。我只是大体运行了一下,再调一调能好多了。

除了效果差,训练过中可以发现到了第22个epoch,图像突然会变差,前一个还是正常的人像(下面gif中暂停的那一幅图像),下一个epoch突然变坏,根据李宏毅2022机器学习HW6解析_机器学习手艺人的博客-CSDN博客,loss_G突然增大,loss_D接近于0,这说明后续的训练discriminator相对generator表现的太好,这与GAN的训练背道而驰,GAN训练最好的结果是loss_G小,loss_D大,也就是discriminator无法分辨generator的结果。

还有一个问题是,生成的图像多样性变差,具体原因老师上课讲过了








![[附源码]java毕业设计领导干部听课评课管理系统](https://img-blog.csdnimg.cn/623dfb74176e44a8915f06a72c96ea2f.png)
![P3205 [HNOI2010]合唱队](https://img-blog.csdnimg.cn/8f520dc1332045f7be8d9aad2709cd7c.png)