版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
大数据系列文章目录
官方网址:https://flink.apache.org/
学习资料:https://flink-learning.org.cn/

目录
- Flink程序模型
- Flink流处理程序的一般流程
- 搭建Flink工程
- 创建Maven项目
- 导入pom依赖
- 批处理的单词统计
- 开发步骤
- 批处理代码
- 流处理的单词统计
- 开发步骤
- 流处理代码
- Flink程序提交部署
- 以UI的方式递交
- 以命令的方式递交
Flink程序模型
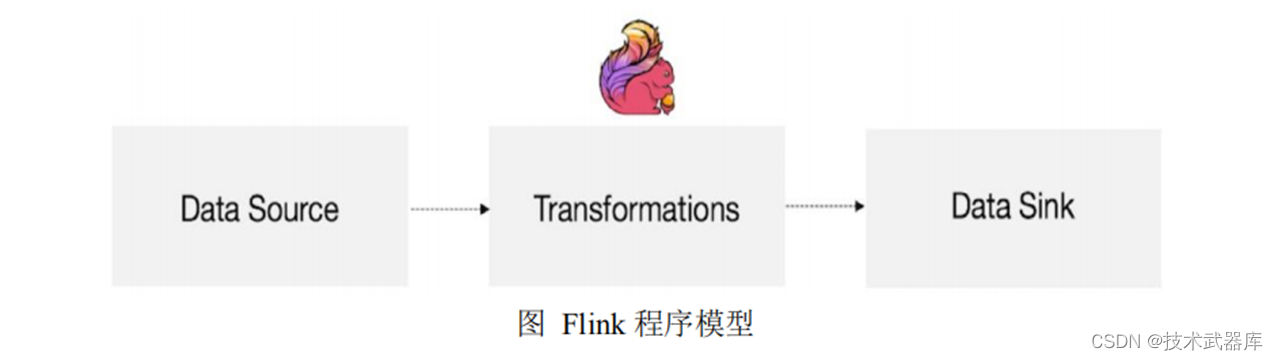
Flink流处理程序的一般流程
- 获取Flink流处理执行环境
- 构建source
- 数据处理
- 构建sink
搭建Flink工程
创建Maven项目
创建maven项目,项目名称:flinkbase
导入pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lee</groupId>
<artifactId>flinkbase</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.10.0</flink.version>
<hive.version>2.1.1</hive.version>
<mysql.version>5.1.48</mysql.version>
<vertx.version>3.9.0</vertx.version>
<commons.collections4>4.4</commons.collections4>
<fastjson.version>1.2.68</fastjson.version>
<!-- sdk -->
<java.version>1.8</java.version>
<scala.version>2.11</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<repositories>
<repository>
<id>apache.snapshots</id>
<name>Apache Development Snapshot Repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<!-- Apache Flink 的依赖 -->
<!-- 这些依赖项,不应该打包到JAR文件中. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 导入kafka连接器jar包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 导入redis连接器jar包-->
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_${scala.version}</artifactId>
<version>1.0</version>
</dependency>
<!-- 导入filesystem连接器jar包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 导入hive连接器jar包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 指定mysql-connector的依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- 高性能异步组件:Vertx-->
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-core</artifactId>
<version>${vertx.version}</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-jdbc-client</artifactId>
<version>${vertx.version}</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-redis-client</artifactId>
<version>${vertx.version}</version>
</dependency>
<!-- Apache提供的Collections4组件提供的一些特殊数据结构-->
<!-- 参考:https://blog.csdn.net/f641385712/article/details/84109098-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>${commons.collections4}</version>
</dependency>
<!-- flink操作hdfs,所需要导入该包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
<!-- streaming File Sink所需要的jar包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.avro/avro -->
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.10.0</version>
</dependency>
<!-- 使用布隆过滤器需要导入jar包 -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.2-jre</version>
</dependency>
<!-- 用于通过自定义功能,格式等扩展表生态系统的通用模块-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- <!– 适用于使用Java编程语言的纯表程序的Table&SQL API(处于开发初期,不建议使用!)。–>-->
<!-- <dependency>-->
<!-- <groupId>org.apache.flink</groupId>-->
<!-- <artifactId>flink-table-api-java</artifactId>-->
<!-- <version>${flink.version}</version>-->
<!-- </dependency>-->
<!-- 使用Java编程语言,带有DataStream / DataSet API的Table&SQL API支持。-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 表程序计划程序和运行时。这是1.9版本之前Flink的唯一计划者。仍然是推荐的。-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 使用blink执行计划的时候需要导入这个包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink sql-》jdbc连接器-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink sql-》kafka连接器-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink json序列化jar包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 操作hive所需要的jar包-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>${hive.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.thrift/libfb303 -->
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libfb303</artifactId>
<version>0.9.3</version>
<type>pom</type>
<scope>provided</scope>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<scope>provided</scope>
</dependency>
<!-- flink-cep的依赖包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--alibaba 序列化/反序列化jar包-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<!-- 添加logging框架, 在IDE中运行时生成控制台输出. -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<!-- 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<!--<encoding>${project.build.sourceEncoding}</encoding>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<!-- 打jar包插件(会包含所有依赖) -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<!--
zip -d learn_spark.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF -->
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- 可以设置jar包的入口类(可选) -->
<mainClass>batch.word.BatchWordCountDemo</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
批处理的单词统计
编写Flink程序,读取文件中的字符串,并以空格进行单词拆分打印。
开发步骤
- 获取批处理运行环境
- 指定读取文件路径,获取数据
- 对获取到的数据进行空格拆分
- 对拆分后的单词,每个单词记一次数
- 对拆分后的单词进行分组
- 根据单词的次数进行聚合
- 打印输出
- 启动执行
批处理代码
package batch.word;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.*;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @author: lwh
**/
public class BatchWordCountDemo {
public static void main(String[] args) throws Exception {
// 1:创建一个批处理的执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2:从文件中读取数据
DataSource<String> inputDataSet = env.readTextFile("datas/wordcount.txt");
// DataSource<String> inputDataSet = env.readTextFile("hdfs://node01:8020/export/data/wordcount.txt");
// 基于 DataSet做转换,首先按空格分词打散,然后按照word作为key做group by
//3:对接收到的数据进行空格拆分
FlatMapOperator<String, String> words = inputDataSet.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
// 切分
String[] words = line.split(" ");
for (String word : words) {
// 输出
collector.collect(word);
}
}
});
// 4:对拆分后的单词,每个单词记一次数
MapOperator<String, Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1);
}
});
// 5:对拆分后的单词进行分组
UnsortedGrouping<Tuple2<String, Integer>> groupedStream = wordAndOne.groupBy(0);
// 6:根据单词的次数进行聚合
AggregateOperator<Tuple2<String, Integer>> summed = groupedStream.sum(1);
// summed.writeAsText("/export/datas/output", FileSystem.WriteMode.OVERWRITE).setParallelism(1);
// 打印输出
summed.print();
// env.execute();
}
}
流处理的单词统计
编写Flink程序,接收socket的单词数据,并以空格进行单词拆分打印。
开发步骤
安装nc: yum install -y nc
nc -lk 9999 监听9999端口的信息
- 获取流处理运行环境
- 构建socket流数据源,并指定IP地址和端口号
- 对接收到的数据进行空格拆分
- 对拆分后的单词,每个单词记一次数
- 对拆分后的单词进行分组
- 根据单词的次数进行聚合
- 打印输出
- 启动执行
- 在Linux中,使用nc -lk 端口号监听端口,并发送单词
流处理代码
package streaming.test;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author: lwh
**/
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1、获取一个流处理运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、构建socket流数据源,并指定IP地址和端口号
DataStreamSource<String> lines = env.socketTextStream("localhost", 9999);
// 3、对接收到的数据进行空格拆分
SingleOutputStreamOperator<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
// 切分
String[] words = line.split(" ");
for (String word : words) {
// 输出
collector.collect(word);
}
}
});
// 4、对拆分后的单词,每个单词记一次数
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1);
}
});
// 5、对计数单词进行分组
KeyedStream<Tuple2<String, Integer>, Tuple> groupedStream = wordAndOne.keyBy(0);
// 6、根据单词的次数进行聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = groupedStream.sum(1);
// 7、打印输出
summed.print();
// 8、启动执行
env.execute("stream.StreamWordCount");
}
}
Flink程序提交部署
Flink程序递交方式有两种:
- 以UI的方式递交
- 以命令的方式递交
以UI的方式递交
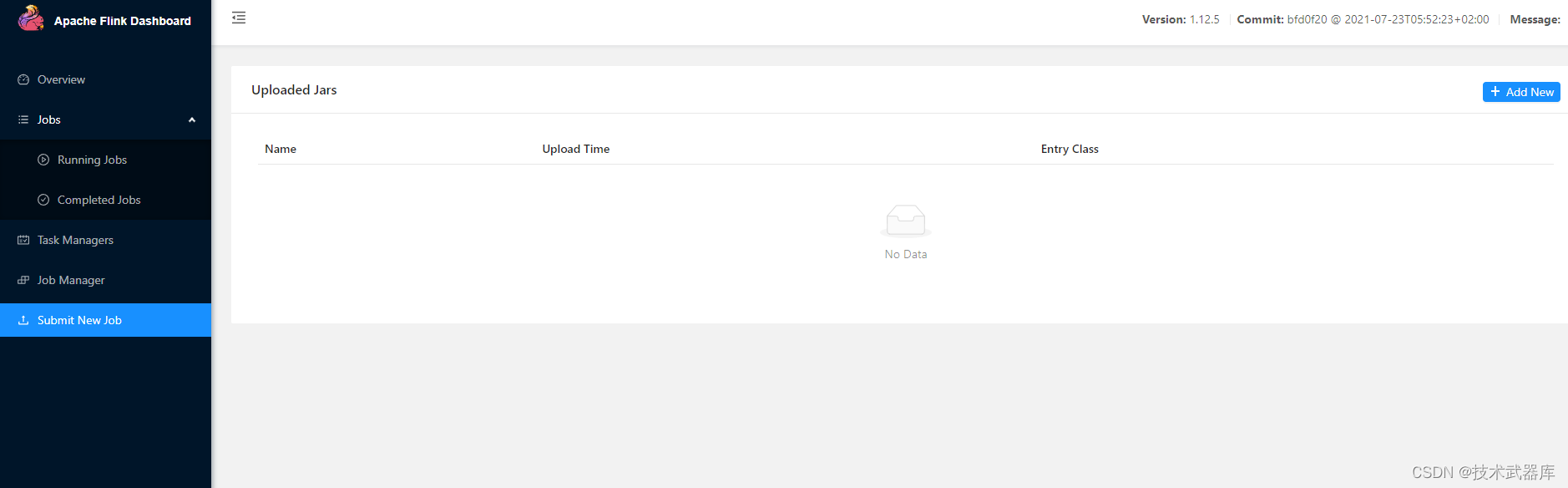
以命令的方式递交
- 上传作业jar包到linux服务器
- ./flink run -c cn.StreamWordCountDemo /export/jars/original-flinkbase-1.0-SNAPSHOT.jar
- 查看任务运行概述