1、简介
TensorRT是一个针对已训练好模型的SDK,通过该SDK能够在NVIDIA的设备上进行高性能的推理。优点如下:
总结下来主要有以下6点:
- Reduced Precision:将模型量化成INT8或者FP16的数据类型(在保证精度不变或略微降低的前提下),以提升模型的推理速度。
- Layer and Tensor Fusion:通过将多个层结构进行融合(包括横向和纵向)来优化GPU的显存以及带宽。
- Kernel Auto-Tuning:根据当前使用的GPU平台选择最佳的数据层和算法。
- Dynamic Tensor Memory:最小化内存占用并高效地重用张量的内存。
- Multi-Stream Execution:使用可扩展设计并行处理多个输入流。
- Time Fusion:使用动态生成的核去优化随时间步长变化的RNN网络。
2、将模型转化为TensorRT的步骤
哪些格式的模型能够导出并转换成TensorRT模型呢,官方提到了三种方式:
- using TF-TRT: 使用TF-TRT(TensorFlow-TensorRT )
- automatic ONNX conversion from .onnx files:从ONNX通用格式转换得到(注意,这里需要自己提前将模型转成ONNX格式)
- manually constructing a network using the TensorRT API (either in C++ or Python):自己用TensorRT API构建模型(这个对新人不太友好,难度有点大)
对于TesorRT来说,最推荐的方式是:通过onnx转成TensorRT的方式。
如说对于Pytorch的模型,我们一般需要先转成ONNX通用格式,然后再转成TensorRT模型,最后部署的时候可以选择C++或者Python: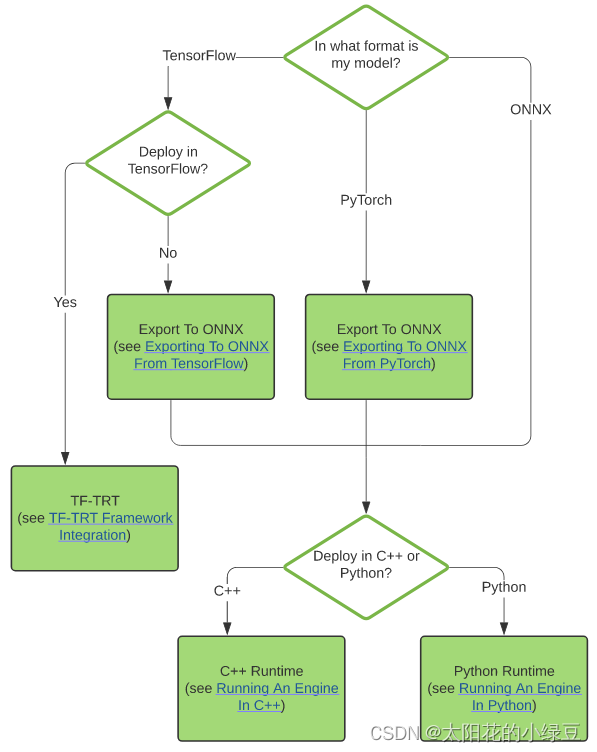
3、工作流程_步骤
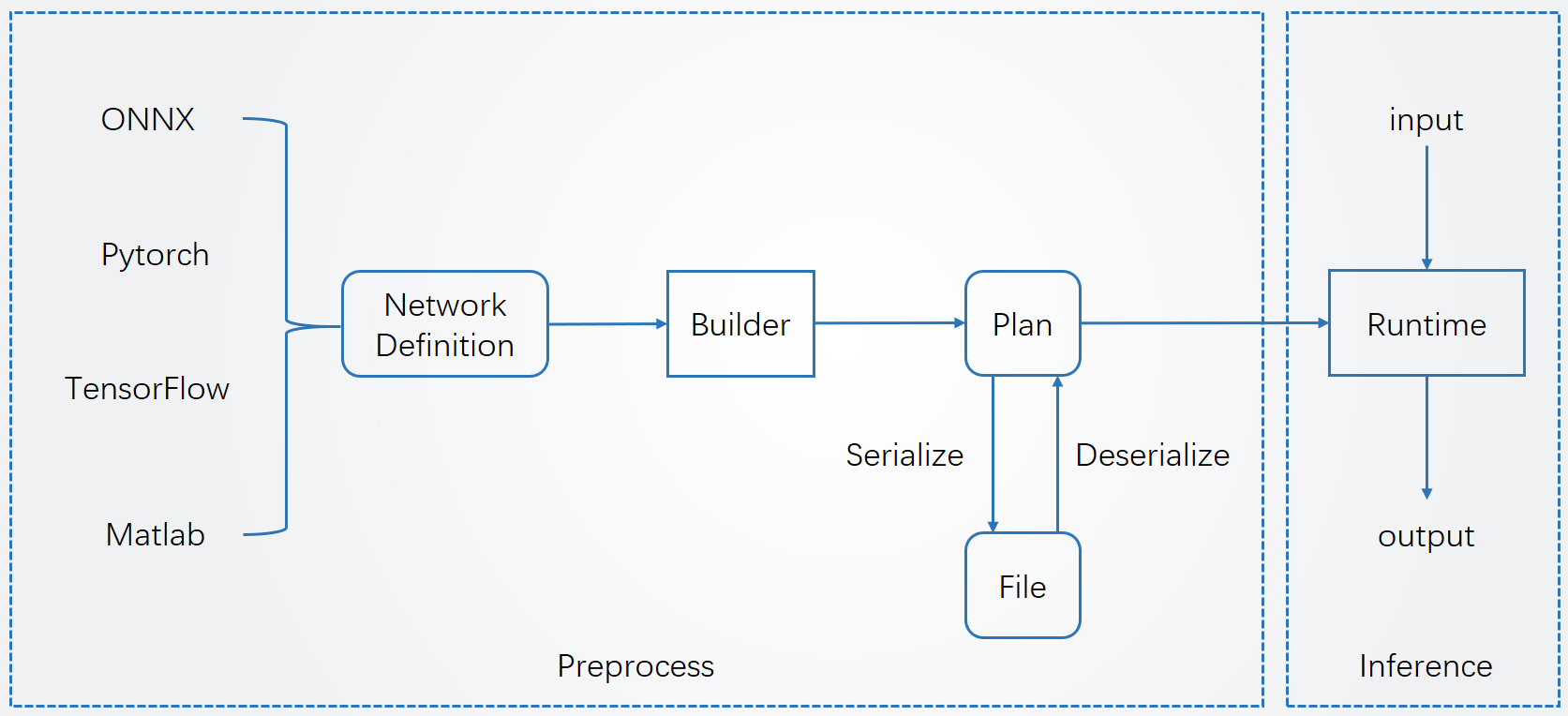
TensorRT使用流程分为两个阶段:预处理阶段和推理阶段。
其部署大致流程如下:
- 1.导出网络定义以及相关权重;
- 2.解析网络定义以及相关权重;
- 3.根据显卡算子构造出最优执行计划;
- 4.将执行计划序列化存储;
- 5.反序列化执行计划;
- 6.进行推理
ps: tensorrt实际上和硬件绑定的,所以在部署过程中,如果硬件(显卡)和软件(驱动、cudatoolkit、cudnn)发生了改变,那么这一步开始就要重新走一遍了。
4、关键操作
4.1、onnx文件导出
使用的是pytorch代码生成的pth,用python代码生成onnx文件
import torch
import torch.onnx
import onnx
import onnxruntime
import numpy as np
from torchvision.models import resnet50
device = torch.device("GPU")
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
def main():
weights_path = "resNet34.pth"
onnx_file_name = "resnet34.onnx"
batch_size = 1
img_h = 224
img_w = 224
img_channel = 3
# create model and load pretrain weights
model = resnet34(pretrained=False, num_classes=5)
model.load_state_dict(torch.load(weights_path, map_location='cpu'))
model.eval()
# input to the model
# [batch, channel, height, width]
x = torch.rand(batch_size, img_channel, img_h, img_w, requires_grad=True)
torch_out = model(x)
# export the model
torch.onnx.export(model, # model being run
x, # model input (or a tuple for multiple inputs)
onnx_file_name,
input_names=["input"],
output_names=["output"],
verbose=False)
# check onnx model
onnx_model = onnx.load(onnx_file_name)
onnx.checker.check_model(onnx_model)
ort_session = onnxruntime.InferenceSession(onnx_file_name)
# compute ONNX Runtime output prediction
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(x)}
ort_outs = ort_session.run(None, ort_inputs)
np.testing.assert_allclose(to_numpy(torch_out), ort_outs[0], rtol=1e-03, atol=1e-05)
print("Exported model has been tested with ONNXRuntime, and the result looks good!")
if __name__ == '__main__':
main()
4.2 将ONNX格式转成TensorRT格式
这个需要用到TensorRT目录下的转换工具,这种方式是最简单的。
直接使用trtexec工具将其转为TensorRT engine格式。
命令:
trtexec.exe --onnx=resnet50.onnx --saveEngine=resnet50.engine下面就可以 使用engine反序列化推理了。