目录
一、Fast R-CNN论文解读
二、Faster R-CNN论文解读
一、Fast R-CNN论文解读
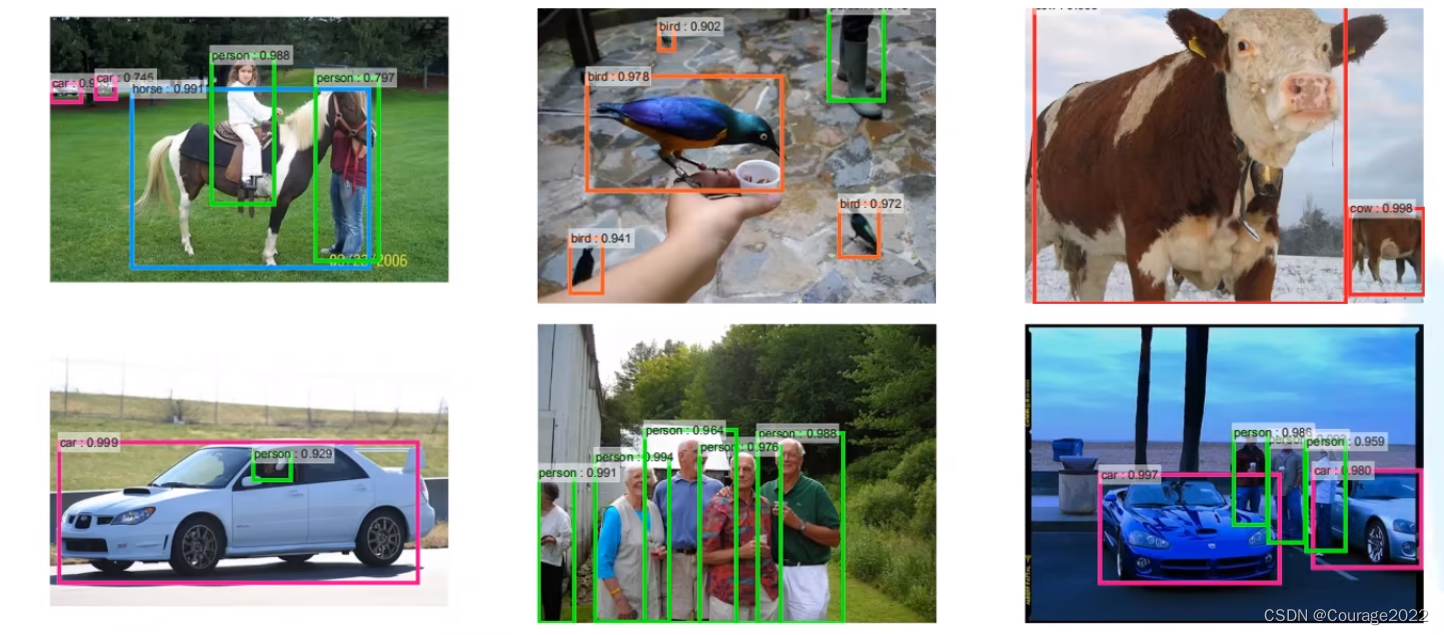
Fast R-CNN是作者Ross Girshick继R-CNN后的又一力作。同样使用VGG16作为网络的backbone,与R-CNN相比训练时间快9倍,测试推理时间快213倍,准确率从62%提升至66%(在Pascal voc数据集上)。
RCNN算法流程可分为4个步骤
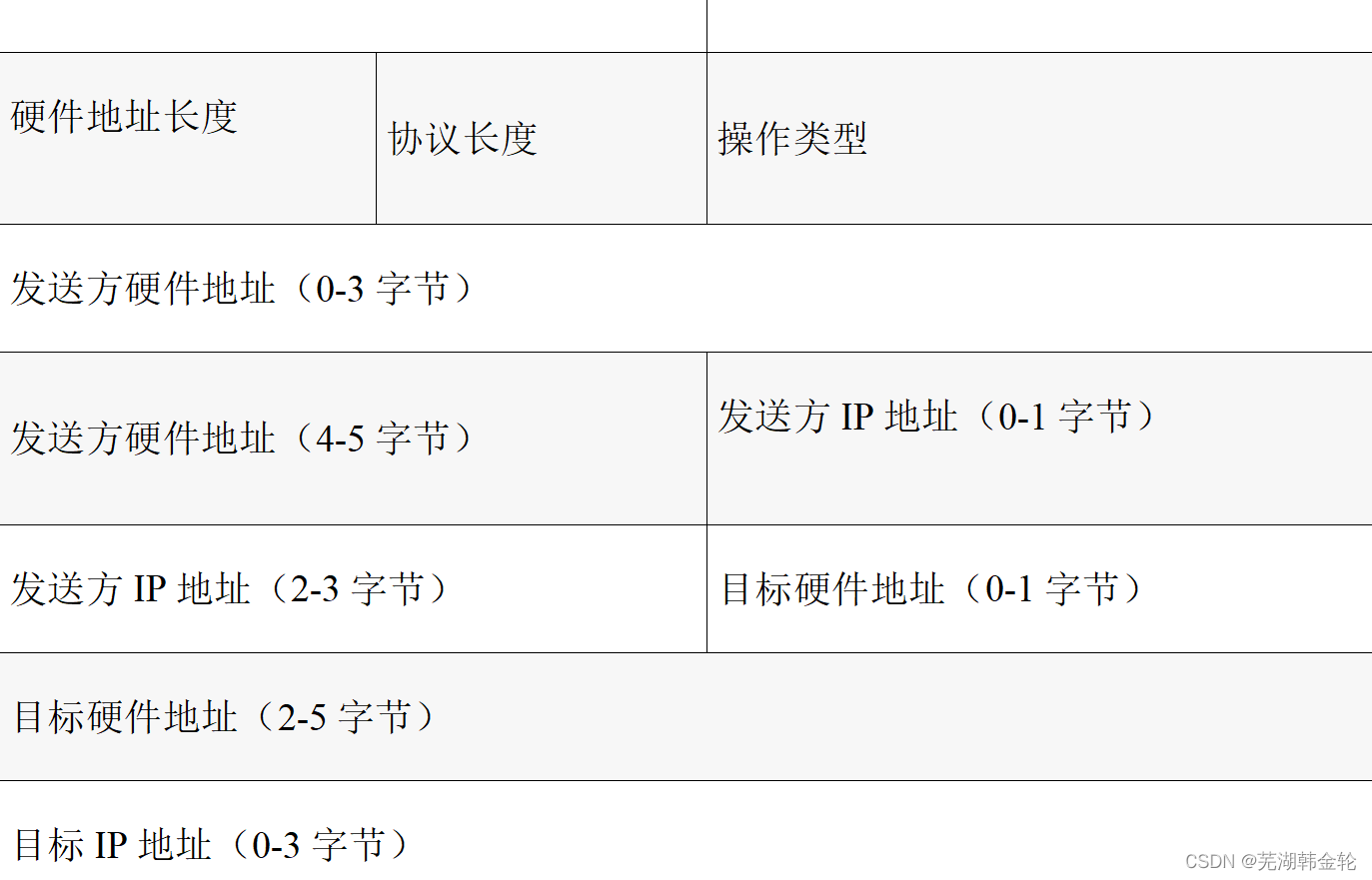
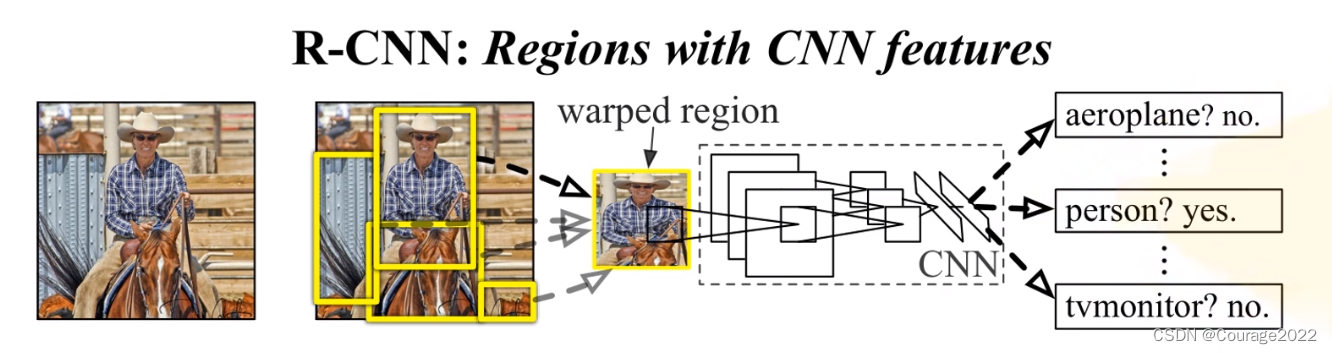
①一张图像生成1K~2K个候选区域(使用Selective Search方法)-②对每个候选区域,使用深度网络提取特征
③特征送入每一类的SVM分类器,判别是否属于该类④使用回归器精细修正候选框位置
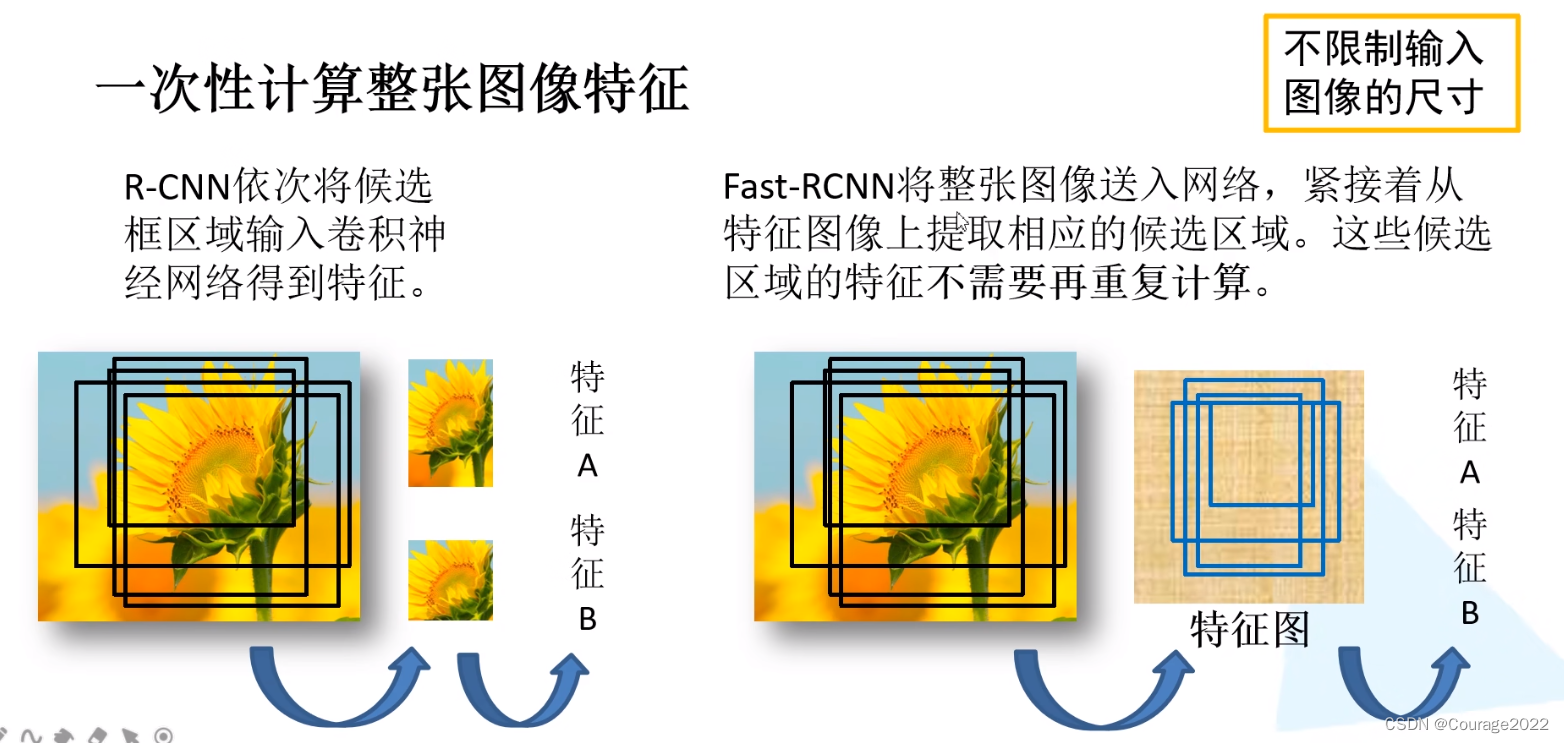
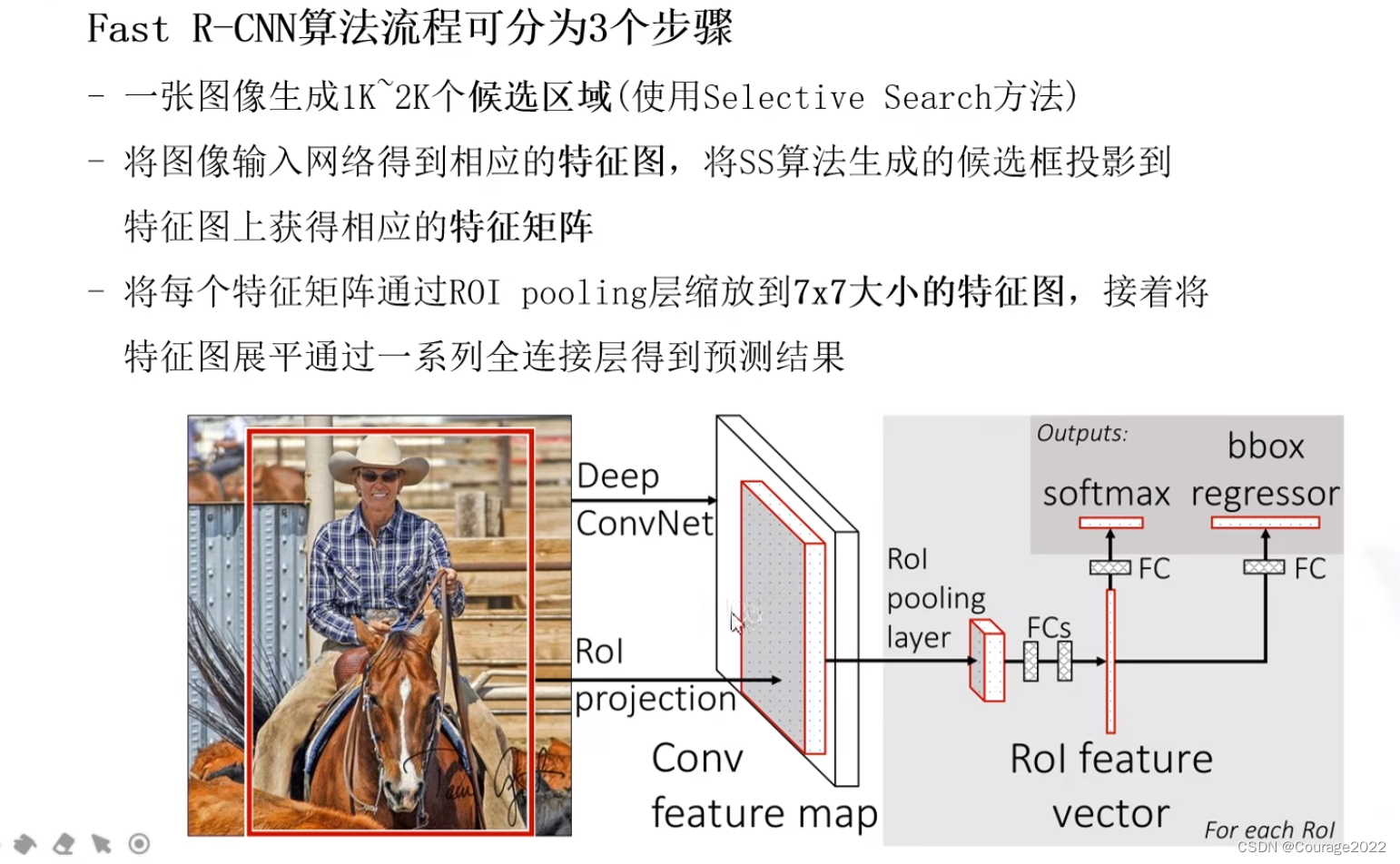
Fast R-CNN算法流程可分为3个步骤
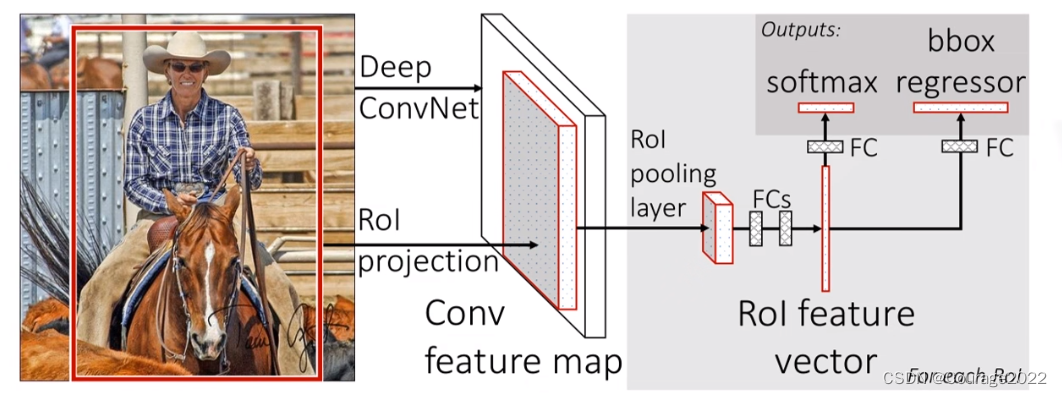
①一张图像生成1K~2K个候选区域(使用Selective Search方法)
②将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
③将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果相比于Fast RCNN算法,Faster RCNN算法将整张图片送入backbone网络,得到特征图,再将SS区域投影映射到特征图上,避免了大量的计算。
在训练过程中,我们并不是使用ss算法提供的所有候选区域进行训练,通过ss算法我们得到了大约2000个候选框,我们在训练过程中只需要使用其中的一小部分就可以了。
对于采样的数据我们分成正样本和负样本,正样本是采样区域确实存在目标物体的样本,负样本可以简单理解成为背景。
作者从2000个候选区域中采集64个候选区域(正+负):如下规则
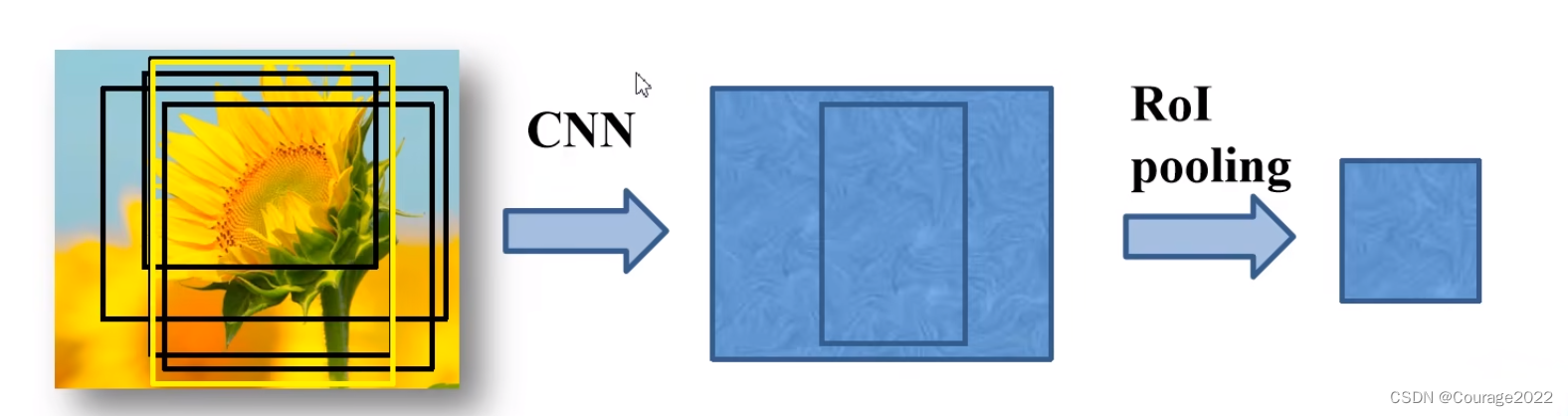
有了训练样本之后,我们将用于训练的样本框通过ROI Polling层缩放到统一的尺寸
ROI Polling层如何实现的呢?
假设左图是一个候选区域在我们特征图上的特征矩阵,划分为7*7,对每个区域进行最大池化下采样MaxPooling操作,得到了7*7的特征矩阵。
Fast RCNN的分类器:
我们将一张图片直接输入进我们的CNN网络中,得到了图像的特征图,根据映射关系我们能够得到每个候选区域的特征矩阵,我们将特征矩阵经过ROI Polling层缩放到一个统一的指定的尺寸,接着我们进行一个展平处理,通过两个全连接层得到我们的RoI feature,然后并联两个全连接层,分别进行目标概率预测和边界框预测。
目标概率预测部分:
输出N+1个类别的概率(N为检测目标的种类,1为背景)共N+1个节点(经过softmax处理概率和为1)。
边界框回归器部分:
如何根据回归参数和候选框得到最终的预测边界框呢?
P代表候选框的坐标,G为最总预测的边界框中心。通过上述计算我们可以将黄色的框框调整到红色的框框中。
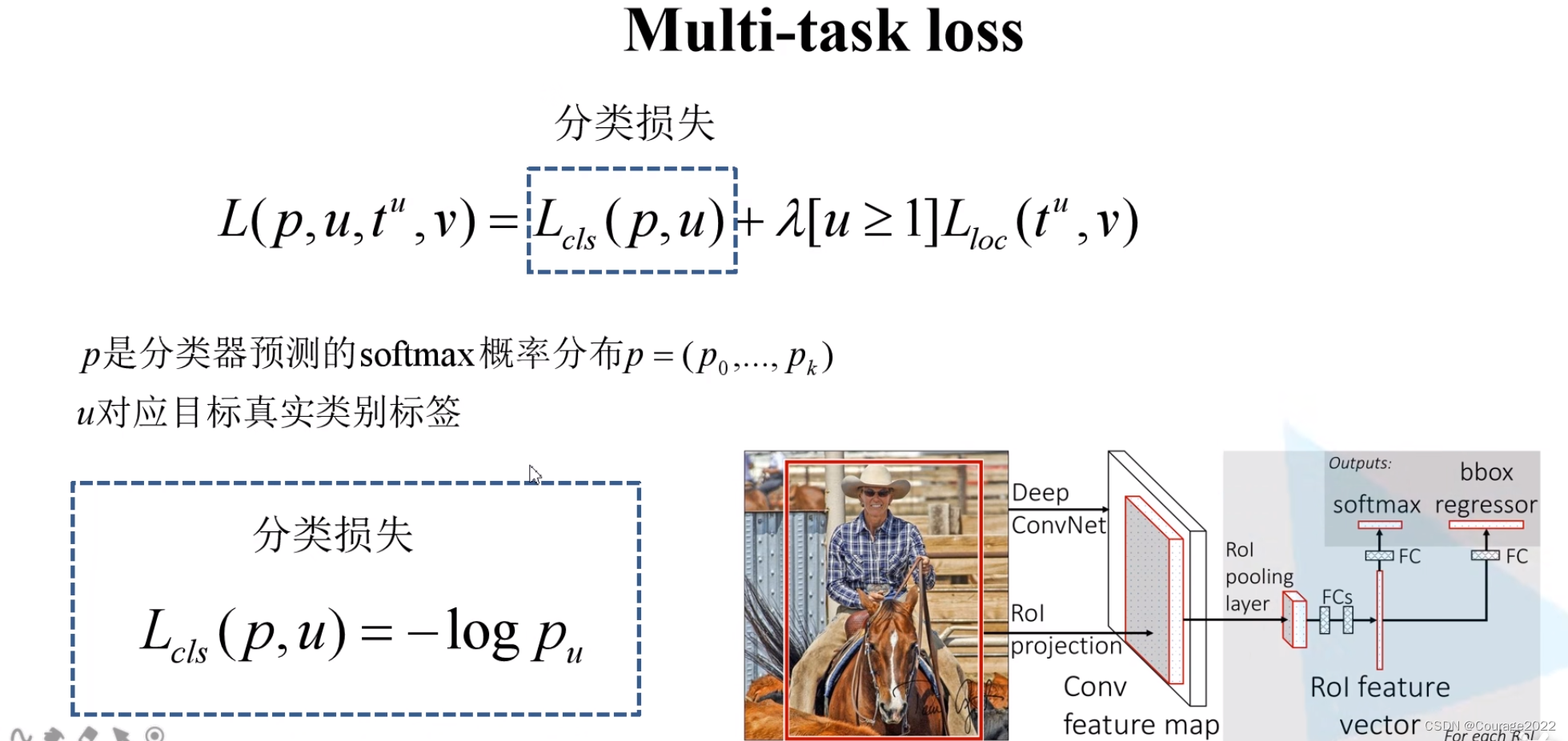
最后我们说一下FastRCNN的损失吧:分类损失 + 边界框回归损失
是目标总类数量。
分类损失采用softmax交叉熵损失:
代表的是真实标签值,
为预测值。
假设真实标签的one-hot编码是:[0,0,...,1,...,0]
预测的softmax概率为:[0.1,0.3,...,0.4,...,0.1]
那么。
边界框回归损失用
计算:
也就是说我们的边界框回归损失由四部分组成:回归参数
的
的
的
的
是平衡系数,用于平衡我们的分类损失和边界框回归损失,
是艾弗森括号,即
时它为1,反之为0。
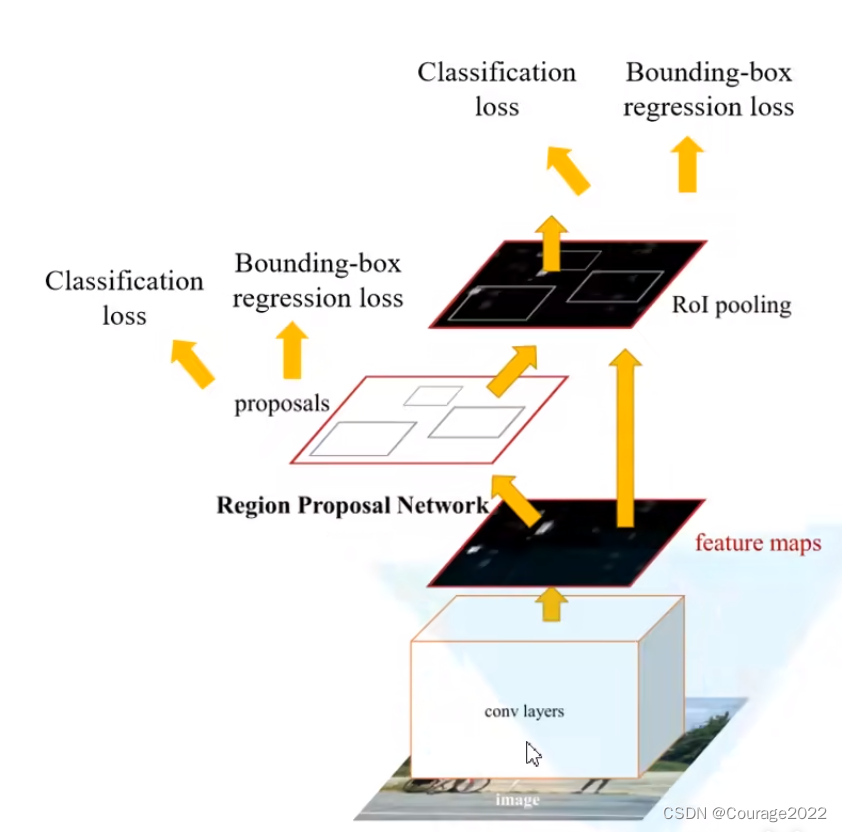
Fast RCNN可以分为两部分进行处理:
相比于RCNN的三部分,是不是更清晰了:
但Fast RCNN还是需要比较长的时间的,因为我们SS算法在CPU上运行,占程序运行的大部分时间,针对此,我们引入了Faster RCNN算法。











二、Faster R-CNN论文解读
Faster R-CNN是作者Ross Girshick继Fast R-CNN后的又一力作。同样使用VGG16作为网络的backbone,推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升。在2015年的ILSVRC以及coco竞赛中获得多个项目的第一名。
我们回顾Fast RCNN算法流程可分为3个步骤
①一张图像生成1K~2K个候选区域(使用Selective Search方法)。②将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵。
③将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果。我们来先大概了解下Faster RCNN的算法步骤,我总结为三个步骤:
①将图像输入网络得到相应的特征图。
②使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵。
③将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图接着将特征图展平通过一系列全连接层得到预测结果。
这里先是将我们的图像输入到CNN网络(特征提取网络)backbone中得到特征图(feature map),使用RPN结构生成候选框,接着将RPN生成的候选框投影在特征图上得到一个个相应的特征矩阵,将特征矩阵通过ROI Pooling层缩放到统一的大小(7*7),进行展平处理接着通过一系列的全连接层得到我们的预测概率以及边界框回归参数。
其实Faster RCNN可以看作是RPN + Fast RCNN。我们这里主要讲解RPN。
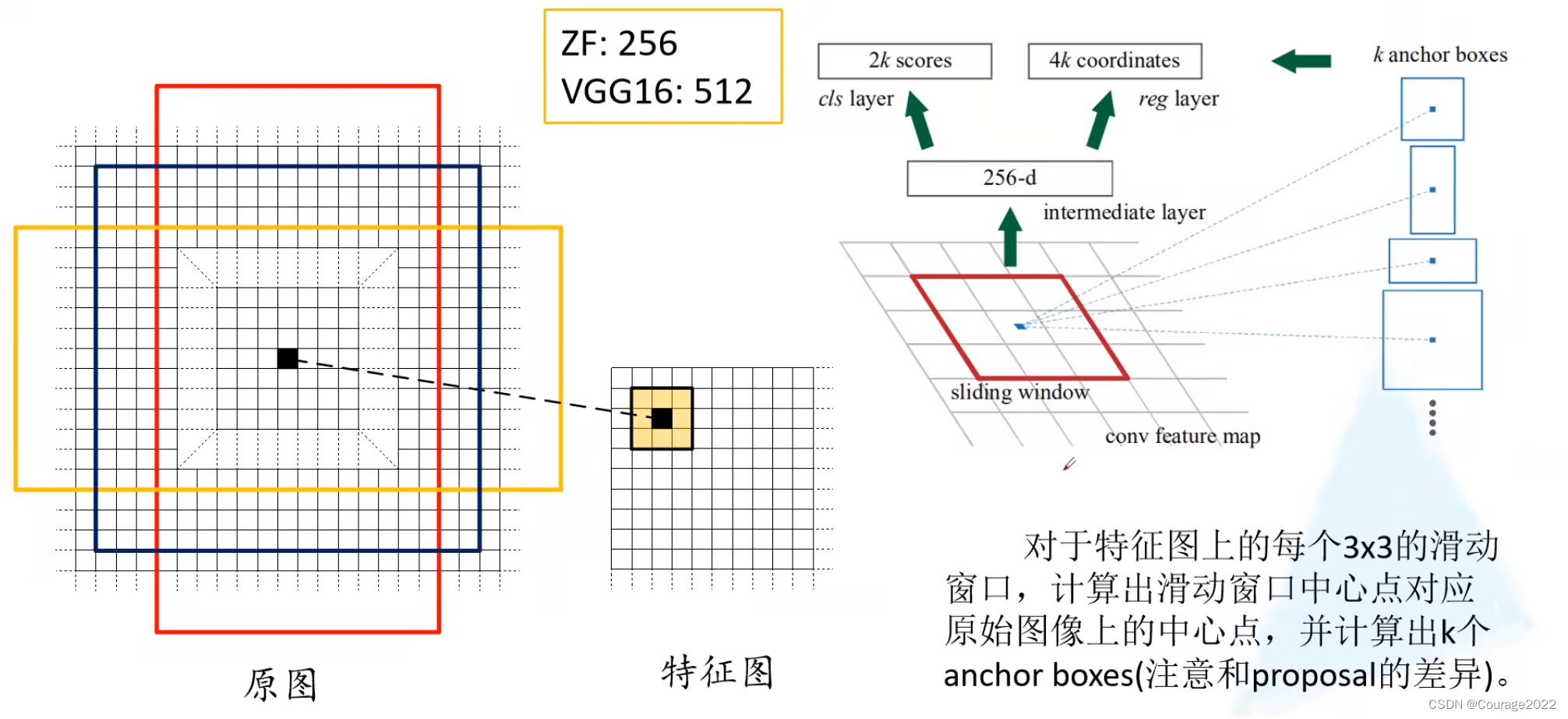
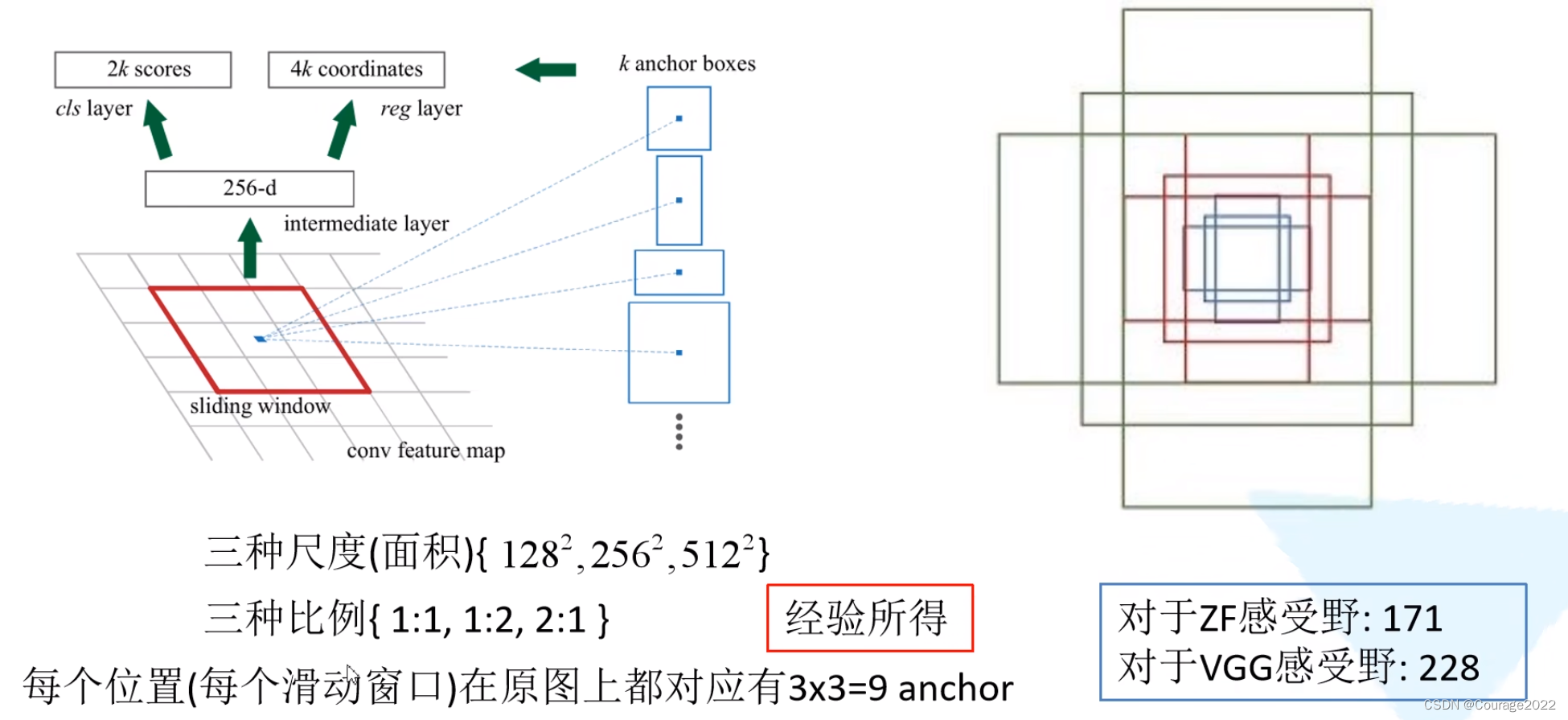
右图中底部为特征图(feature map)是通过backbone生成的,我们在特征图上面使用一个滑动窗口在特征图中进行滑动,每滑动一次我们生成一个一维的向量,在这个向量的基础上通过两个全连接层输出我们的目标概率以及边界框回归参数。
2K(背景的概率 + 前景的概率)是针对K个anchorbox,针对每个anchor我们会生成四个边界框回归参数因此是4K个。在使用ZF网络中它所生成的特征图的深度(channel)是等于256的。
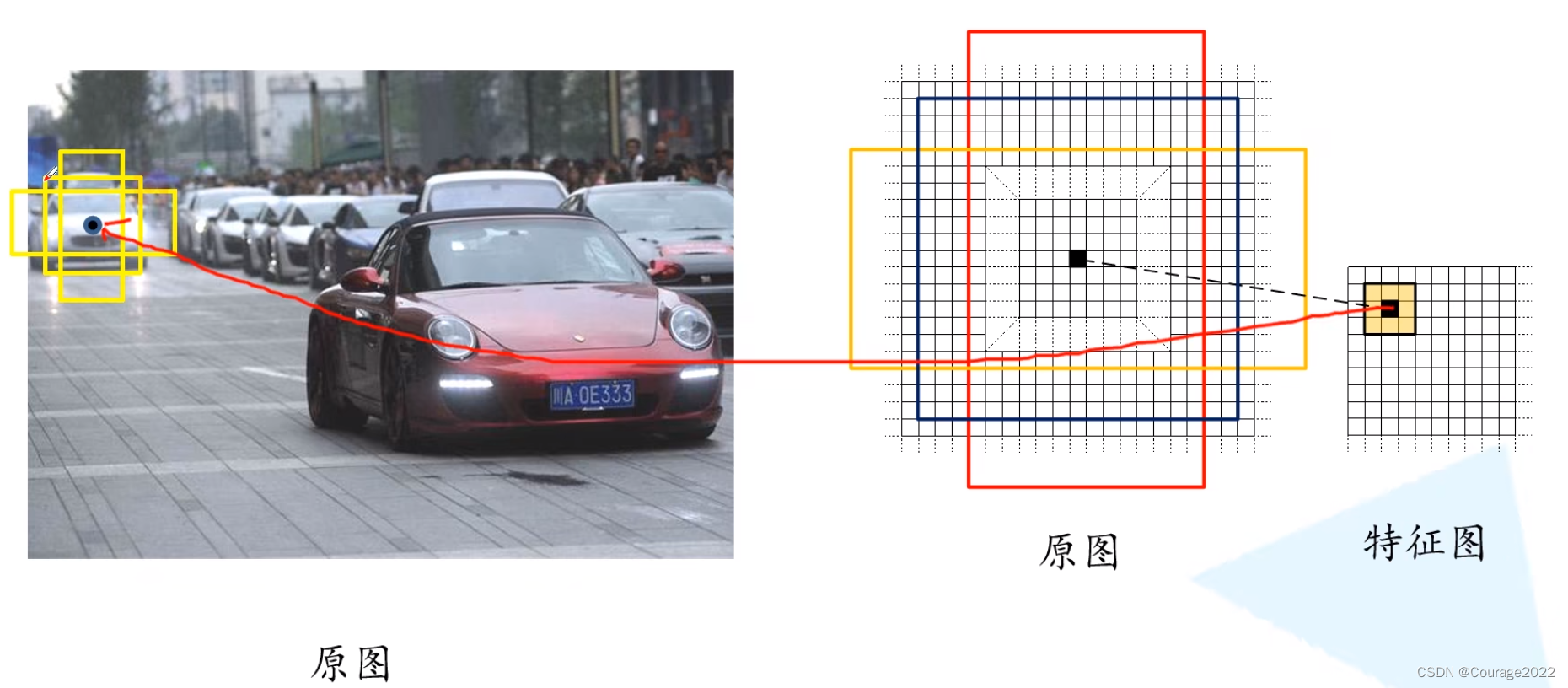
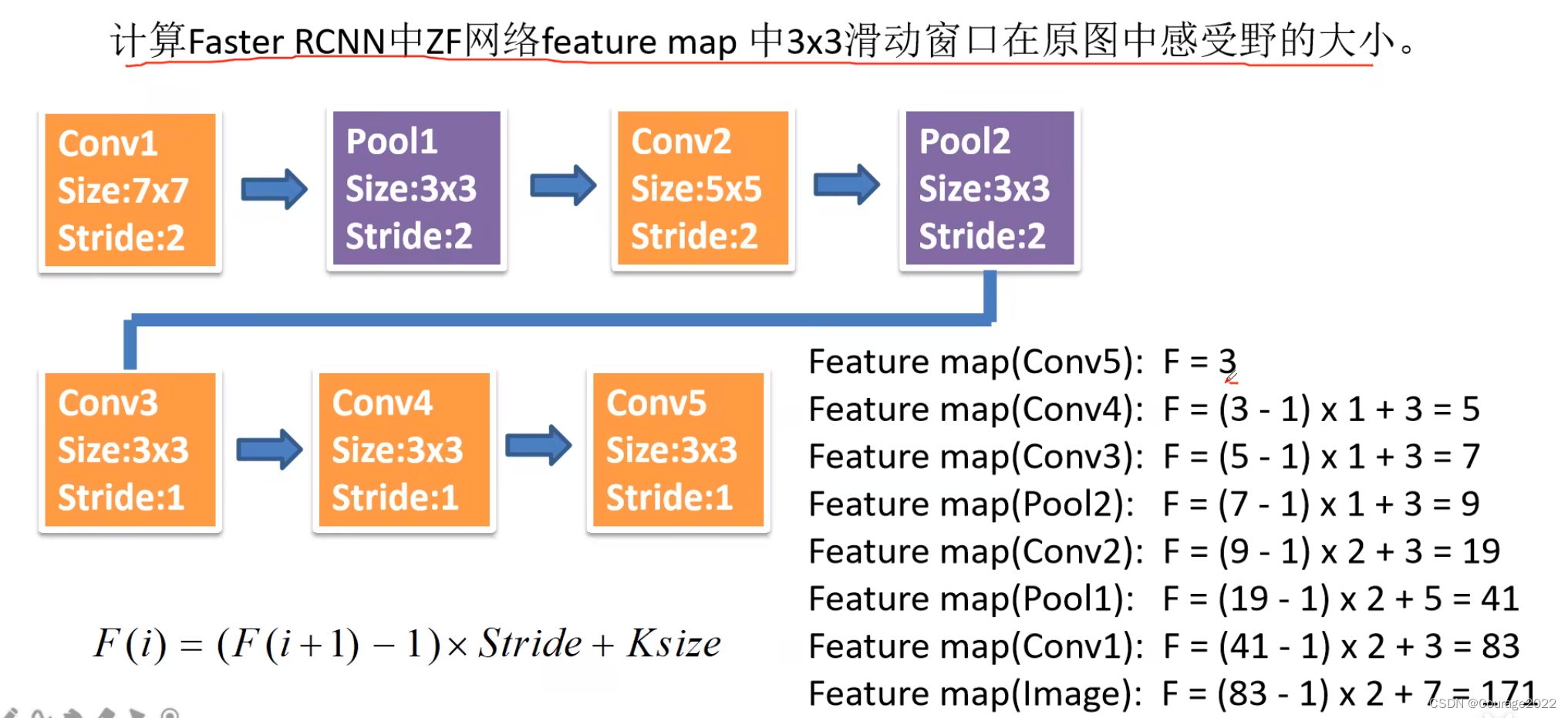
对于特征图上每一个3*3的滑动窗口,计算中心点在原图上所对应的位置(等比例缩放),再以这个点为中心计算每个anchor box,这里都是给定的大小及长宽比例。
用上图做解释,我们找到特征图对应的原图的点,在该点周围生成一系列的anchor box。anchor中可能包含了我们所要检测的目标,也可能没有我们所要检测的目标。
对于K个anchor,我们会生成2K个cls(背景概率、前景概率--没有进行分类)和4K(anchor中心坐标、宽、高预测的量)个reg。经过边界框回归,我们希望尽可能框选出来我们的目标。
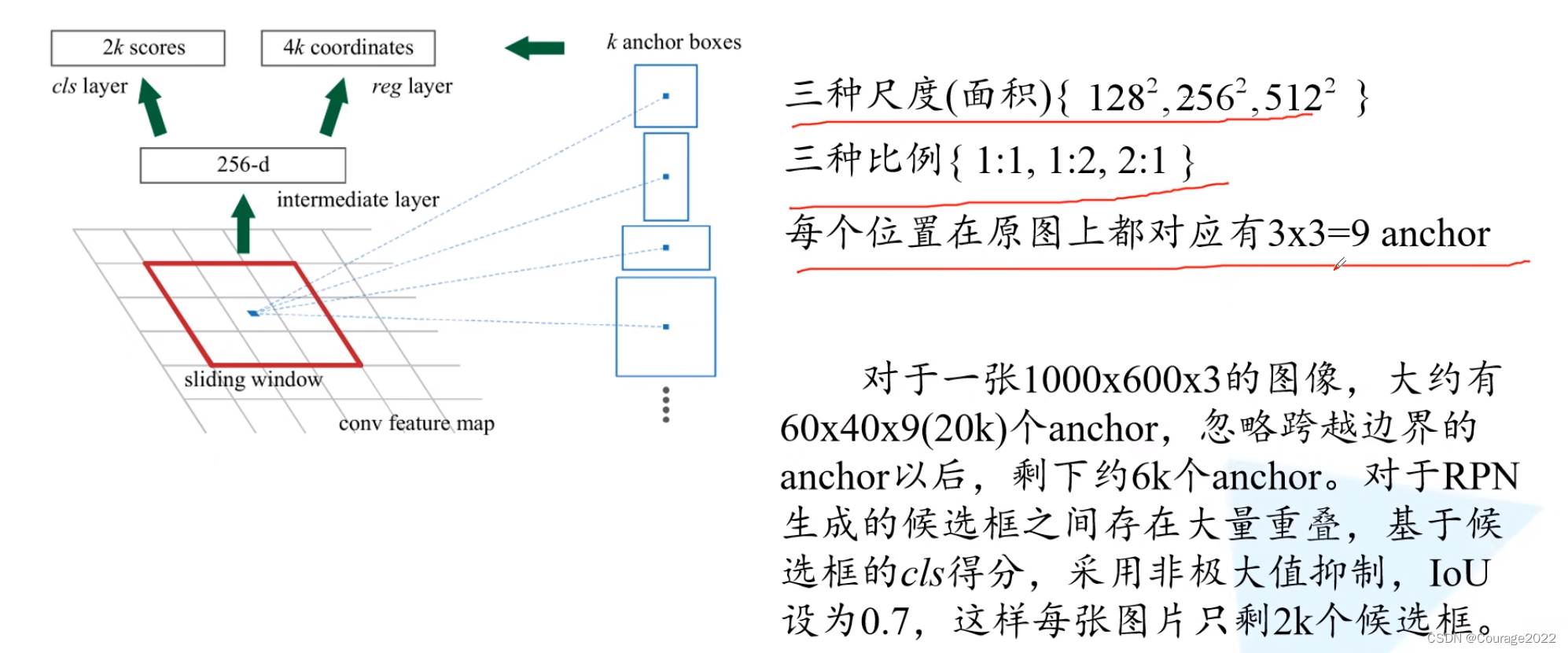
在Faster R-CNN中给了9个anchor。(作者说是经验......)
也就是说会生成2*9=18个预测分数和4*9=36个边界框回归参数。
对于一张1000x600x3的图像,大约有60x40x9(20k)个anchor,忽略跨越边界的anchor以后,剩下约6k个anchor(也就是我们说的proposal)。对于RPN生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,loU设为0.7,这样每张图片只剩2k个候选框。
我们注意!anchor!=proposal,我们利用RPN生成的边界框回归参数将我们的anchor调节到我们的proposal的。
正向传播过程也是比较简单的,滑动窗口采用3*3的Conv,采用步距为1,padding也为1,这样我们就能得到高度、宽度、深度和我们的feature map一样的特征矩阵,我们在特征矩阵上并联两个1*1的卷积层实现对类别和边界框的预测。
RPN网络中正负样本的选择:
我们在原图上会生成上万个anchor,并不是每个都用来训练我们的RPN网络,根据作者所说,我们从上万个anchor中采样256个anchor(正样本 + 负样本,比例约1:1),如果正样本数目不足则用负样本进行填充。
对于定义正样本:①anchor与标注信息框(ground-truth)iou超过0.7或②anchor与标注信息(ground-truth)具有最大的iou(人工标注的框与很多anchor都相交,我们找到与人工标注有最大的iou值的anchor)
对于负样本定义:与所有的标注信息(ground-truth)的iou值均小于0.3。
丢弃所有不是正样本与负样本的anchor。
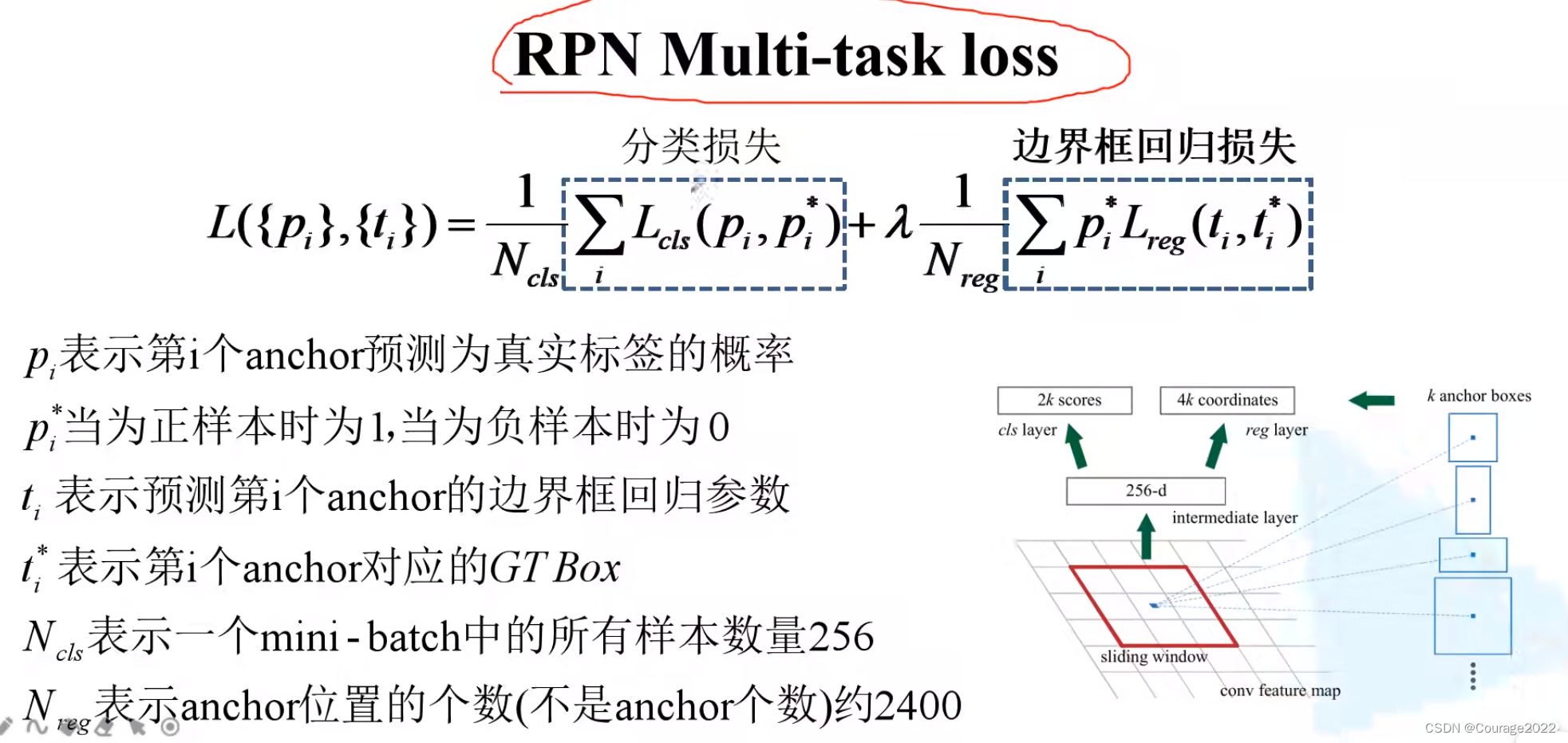
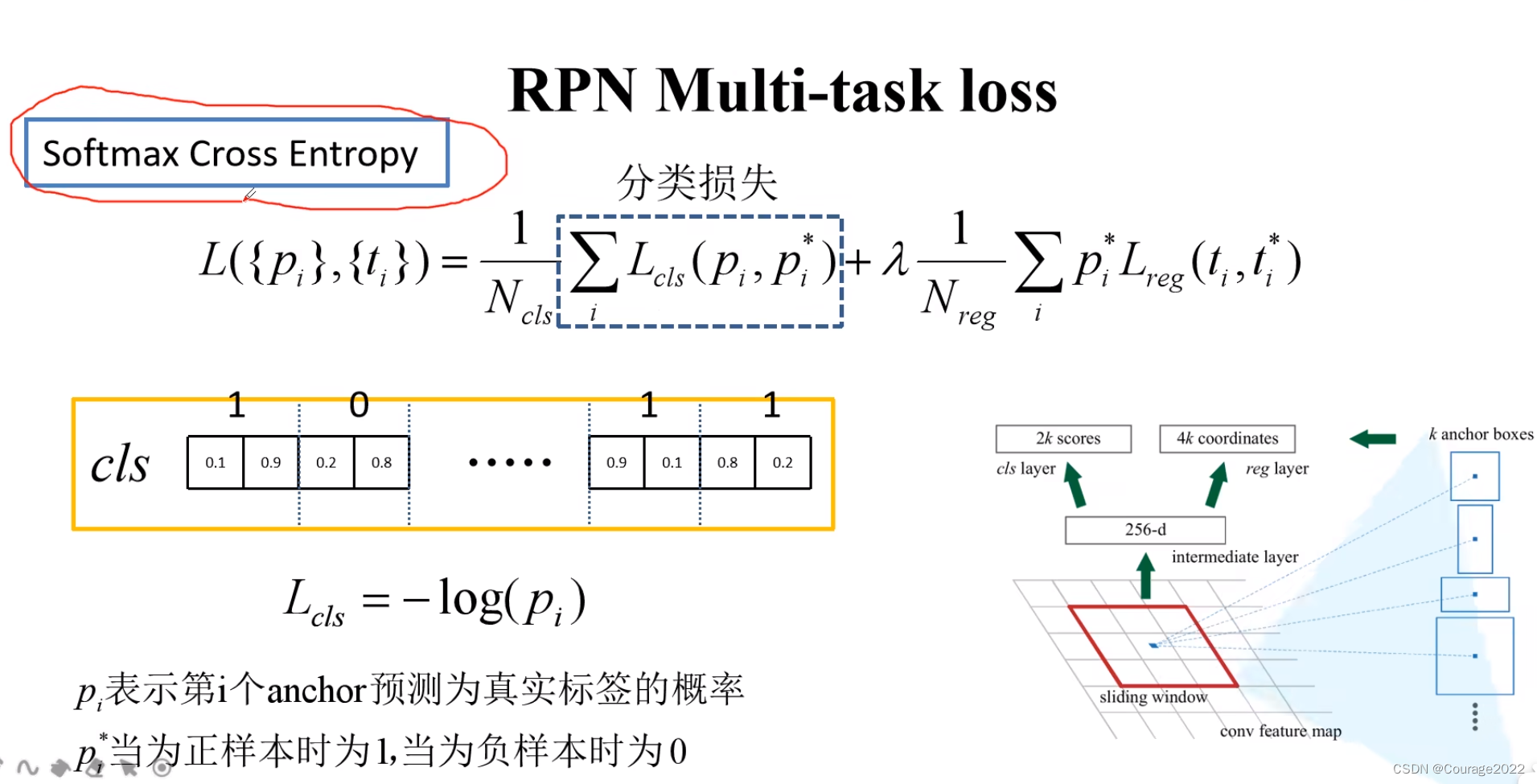
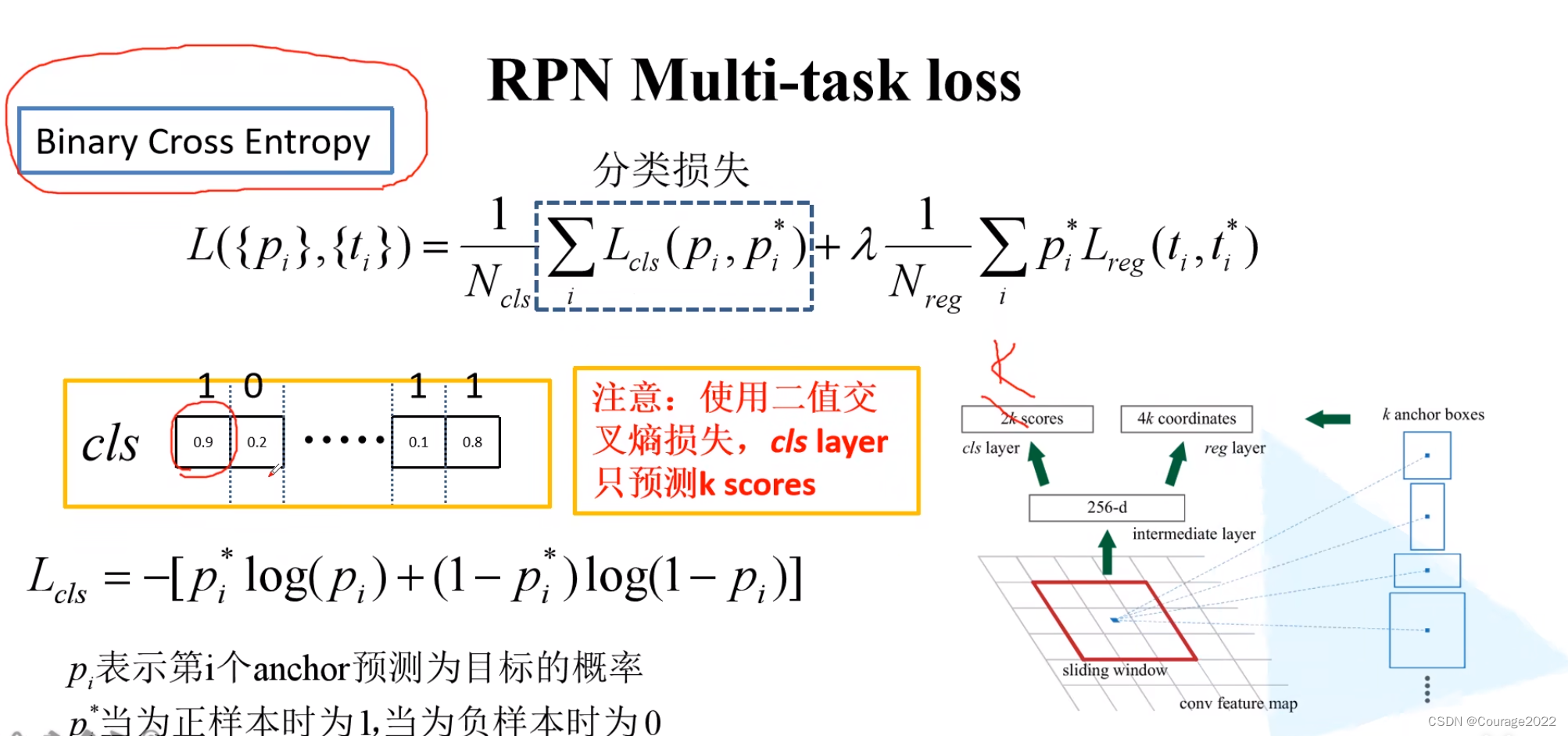
我们看看RPN的损失定义:
分类损失的两种计算方法:
边界框回归损失:
和Fast R-CNN如出一辙。
这里
代表通过回归层预测出来的并不是计算出来的,那些带*的是根据anchor所对应的真实的ground-truth以及anchor的坐标计算出来的。