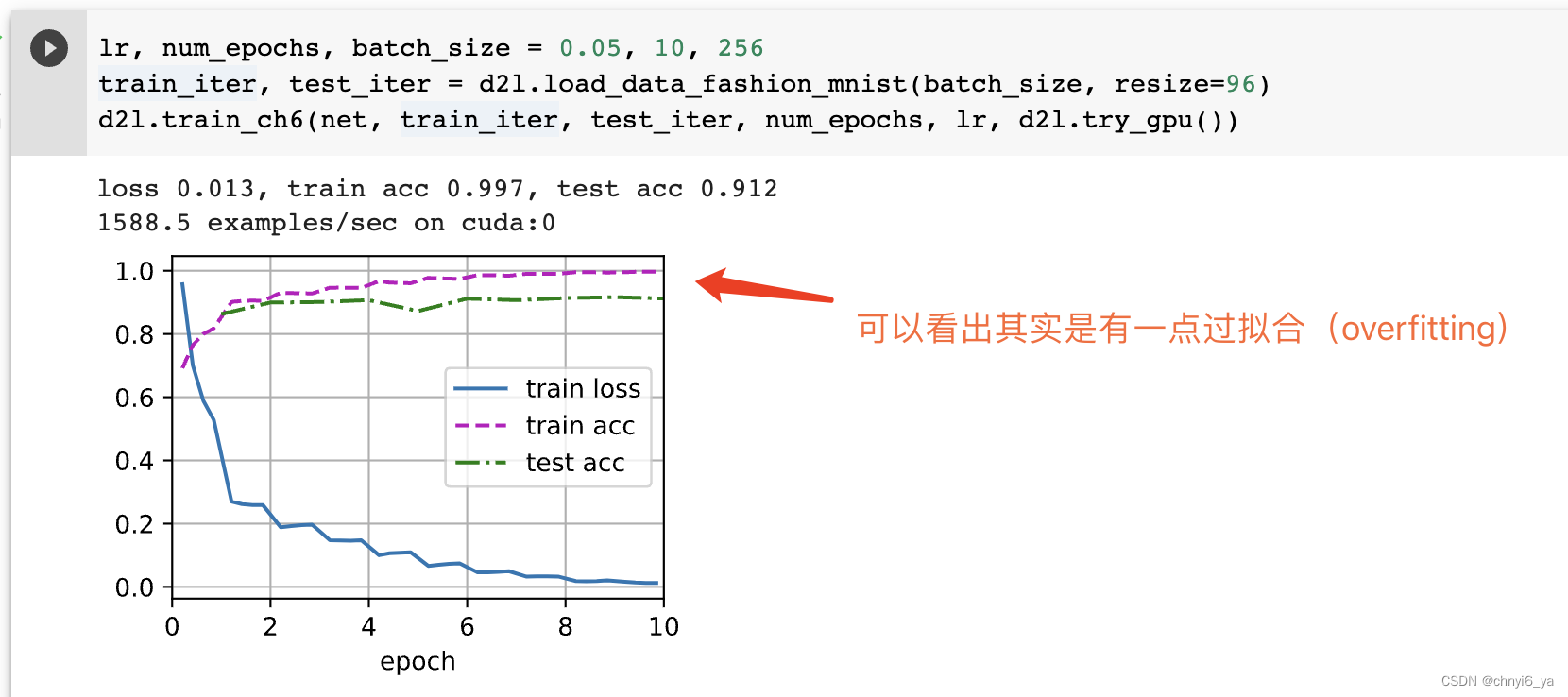
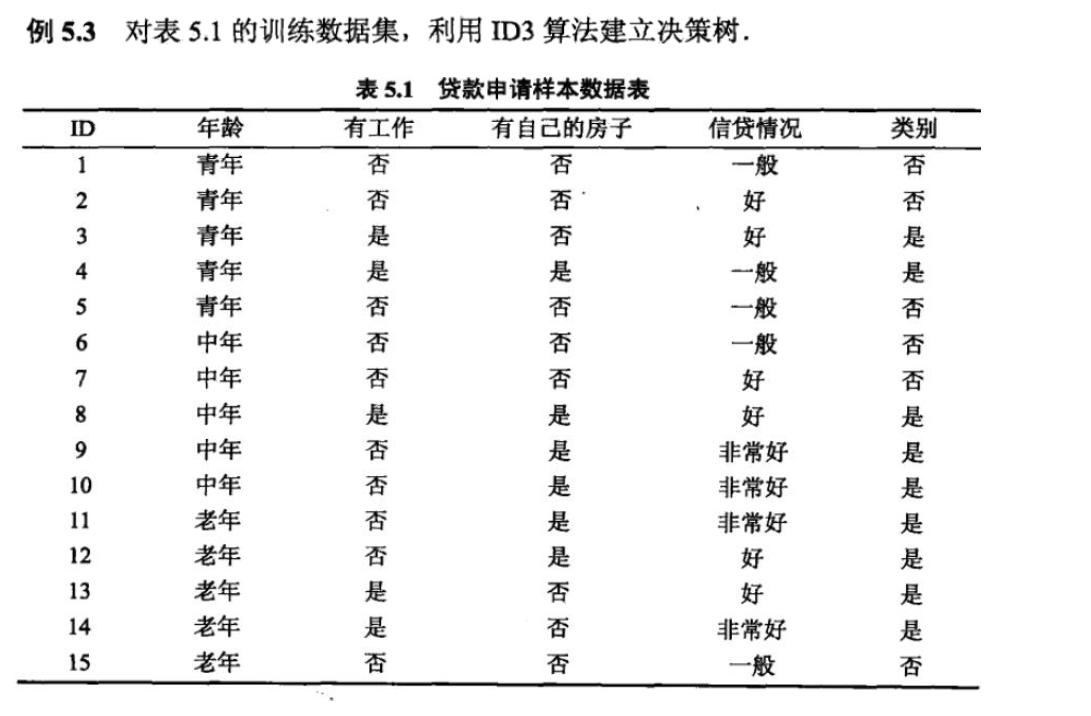
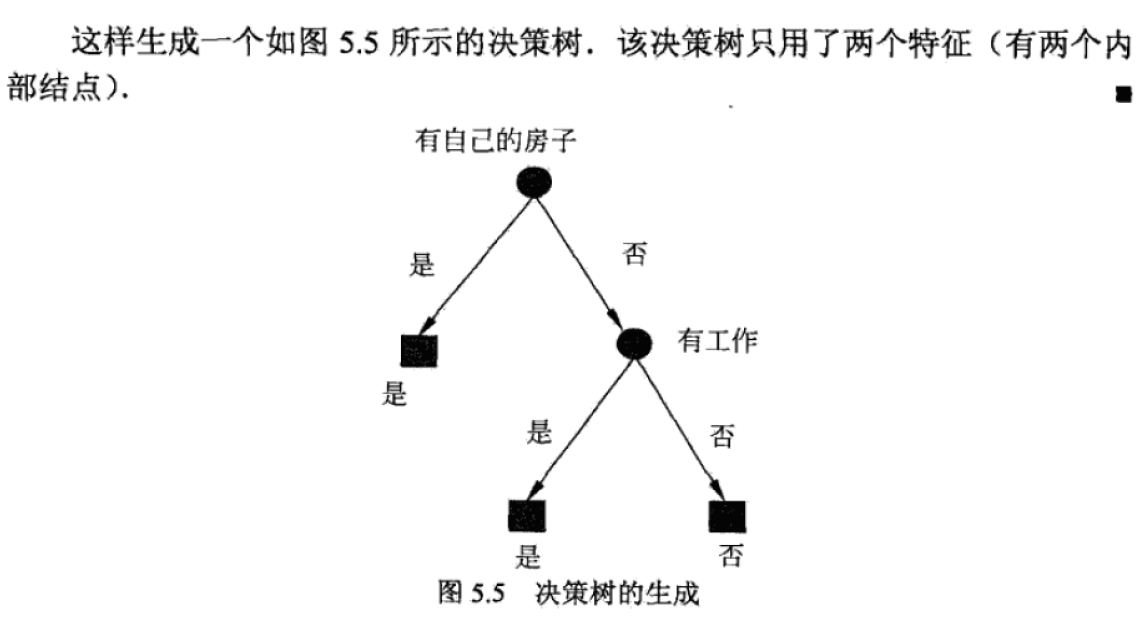
1、ID3(Iterative Dichotomizer)
- ID3是Quinlan于1986年提出的, 它的提出开创了决策树算 法的先河, 而且是国际上最早的决策树方法, 在该算法中, 引入了信息论中熵的概念, 利用分割前后的熵来计算信息 增益, 作为判别能力的度量。
- ID3 算法的核心是在决策树各个结点上应用信息增益准则选择特征, 递归地 构建决策树. 具体方法是: 从根结点 (root node) 开始, 对结点计算所有可能的 特征的信息增益, 选择信息增益最大的特征作为结点的特征, 由该特征的不同取 值建立子结点; 再对子结点递归地调用以上方法, 构建决策树; 直到所有特征的 信息增益均很小或没有特征可以选择为止. 最后得到一个决策树. ID3 相当于用 极大似然法进行概率模型的选择.
ID3算法
输入: 训练数据集
D
D
D, 特征集
A
A
A, 阈值
ε
\varepsilon
ε;
输出: 决策树
T
T
T.
(1) 若
D
D
D 中所有实例属于同一类
C
k
C_k
Ck, 则
T
T
T 为单结点树, 并将类
C
k
C_k
Ck 作为该结 点的类标记, 返回
T
T
T;
(2) 若
A
=
∅
A=\varnothing
A=∅, 则
T
T
T 为单结点树, 并将
D
D
D 中实例数最大的类
C
k
C_k
Ck 作为该结点的 类标记, 返回
T
T
T;
(3)否则, 计算
A
A
A 中各特征对
D
D
D 的信息增益, 选择信息增益最大 的特征
A
g
A_g
Ag;
(4) 如果
A
g
A_g
Ag 的信息增益小于阈值
ε
\varepsilon
ε, 则置
T
T
T 为单结点树, 并将
D
D
D 中实例数最 大的类
C
k
C_k
Ck 作为该结点的类标记, 返回
T
T
T;
(5) 否则, 对
A
g
A_g
Ag 的每一可能值
a
i
a_i
ai, 依
A
g
=
a
i
A_g=a_i
Ag=ai 将
D
D
D 分割为若干非空子集
D
i
D_i
Di, 将
D
i
D_i
Di 中实例数最大的类作为标记, 构建子结点, 由结点及其子结点构成树
T
T
T, 返回
T
T
T;
(6) 对第
i
i
i 个子结点, 以
D
i
D_i
Di 为训练集, 以
A
−
{
A
g
}
A-\left\{A_g\right\}
A−{Ag} 为特征集, 递归地调用 步 (1) ~步 (5), 得到子树
T
i
T_i
Ti, 返回
T
i
T_i
Ti.

2、C4.5
- ID3算法使用信息增益( Info Gain) Info ( D ) = − ∑ i = 1 m p i log 2 ( p i ) Info A ( D ) = ∑ j = 1 v ∣ D j ∣ ∣ D ∣ × Info ( D j ) Gain ( A ) = Info ( D ) − Info A ( D ) \begin{gathered} \operatorname{Info}(D)=-\sum_{i=1}^m p_i \log _2\left(p_i\right) \quad \operatorname{Info}_A(D)=\sum_{j=1}^v \frac{\left|D_j\right|}{|D|} \times \operatorname{Info}\left(D_j\right) \\ \operatorname{Gain}(A)=\operatorname{Info}(D)-\operatorname{Info}_A(D) \end{gathered} Info(D)=−i=1∑mpilog2(pi)InfoA(D)=j=1∑v∣D∣∣Dj∣×Info(Dj)Gain(A)=Info(D)−InfoA(D)
- 偏向于具有大量值的属性。在训练集中, 某个属性所取的不同值的个数越多, 那么越有可能拿它来作为分裂属性。
- C4.5中使用信息增益率( Gain ratio) SplitInfo A ( D ) = − ∑ j = 1 v ∣ D j ∣ ∣ D ∣ × log 2 ( ∣ D j ∣ ∣ D ∣ ) GainRatio ( A ) = Gain ( A ) SplitInfo ( A ) \begin{gathered} \text { SplitInfo }_A(D)=-\sum_{j=1}^v \frac{\left|D_j\right|}{|D|} \times \log _2\left(\frac{\left|D_j\right|}{|D|}\right) \\ \operatorname{GainRatio}(A)=\frac{\operatorname{Gain}(A)}{\operatorname{SplitInfo}(A)} \end{gathered} SplitInfo A(D)=−j=1∑v∣D∣∣Dj∣×log2(∣D∣∣Dj∣)GainRatio(A)=SplitInfo(A)Gain(A)
- Info-Gain在面对类别较少的离散数据时效果较好, 之前的 outlook, temperature等数据都是离散数据, 而且每个类别都 有一定数量的样本, 这种情况下使用ID3与C4.5的区别并不大。
- 但如果面对连续的数据(如体重、身高、年龄、距离等), 或者每列数据没有明显的类别之分 (最极端的例子的该列所有数据都独一无一), 在这种情况下, ID3算法倾向于把每个数据分成一类(将每一个样本都分到一个节点当中去), 程序会倾向于选择这种划分, 这样划分效果极差。
- 为了解决这个问题, 引入了信息增益率 (Gain-ratio) 的概念, 减轻了划分行为本身的影响。
- 对于取值多的属性, 尤其一些 连续型数值 , 比如两条地理数据的距离 属性, 这个单独的属性就可以划分所有的样本, 使得所有分支下的样本集合都是 “纯的” (最极端的情况是每个叶子节点只有一个样本)
- 对于ID (就比如是姓名), 用信息增益划分, 每一个名字都是一个类
- 所以如果是取值更多的属性, 更容易使得数据更“纯”(尤其是连续型数值), 其信息增益更大, 决策树会首先挑选这个属性作为树的顶点,结果训练出来的形状是一棵庞大且深度很浅的树, 这样的划分是极为不合理的。
- C4. 5使用了信息增益率, 在信息增益的基础上除了一项 split information, 来惩罚值更多的属性
- 信息增益率引入了分裂信息, 取值数目多的属性分裂信息也会变大, 将增益除以分裂信息, 再加上一些额外操作, 可以有效控制信息增益过大的问题。
3、CART(Classification and Regression Trees)
- 分类与回归树 (classification and regression tree, CART) 模型由 Breiman 等人在 1984 年提出, 是应用广泛的决策树学习方法. CART 同样由特征选择、树的生成及剪枝组成, 既可以用于分类也可以用于回归. 以下将用于分类与回归的 树统称为决策树
- CART 假设决策树是二叉树, 内部结点特征的取值为 “是” 和 “否”, 左分支是取值为 “是” 的分支, 右分支是取值为 “否” 的分支
(1) 决策树生成: 基于训练数据集生成决策树, 生成的决策树要尽量大
(2) 决策树剪枝: 用验证数据集对已生成的树进行剪枝并选择最优子树, 这时用损失函数最小作为剪枝的标准
♣
\clubsuit
♣ 最小二乘回归树生成算法
输入: 训练数据集
D
D
D
输出: 回归树
f
(
x
)
f(x)
f(x).
- 在训练数据集所在的输入空间中, 递归地将每个区域划分为两个子区域并决 定每个子区域上的输出值, 构建二叉决策树:
(1) 选择最优切分变量 j j j 与切分点 s s s
min
j
,
s
[
min
c
1
∑
x
i
∈
R
1
(
j
,
s
)
(
y
i
−
c
1
)
2
+
min
c
2
∑
x
ϵ
∈
R
2
(
j
,
s
)
(
y
i
−
c
2
)
2
]
\min _{j, s}\left[\min _{c_1} \sum_{x_i \in R_1(j, s)}\left(y_i-c_1\right)^2+\min _{c_2} \sum_{x_\epsilon \in R_2(j, s)}\left(y_i-c_2\right)^2\right]
j,smin
c1minxi∈R1(j,s)∑(yi−c1)2+c2minxϵ∈R2(j,s)∑(yi−c2)2
遍历变量
j
j
j, 对固定的切分变量
j
j
j 扫描切分点
s
s
s, 选择使上式达到最小值的对
(
j
,
s
)
(j, s)
(j,s).
(2)用选定的对
(
j
,
s
)
(j, s)
(j,s) 划分区域并决定相应的输出值(该区域样本标签平均值)
R
1
(
j
,
s
)
=
{
x
∣
x
(
j
)
⩽
s
}
,
R
2
(
j
,
s
)
=
{
x
∣
x
(
j
)
>
s
}
c
^
m
=
1
N
m
∑
x
1
∈
R
m
(
j
,
s
)
y
i
,
x
∈
R
m
,
m
=
1
,
2
\begin{gathered} R_1(j, s)=\left\{x \mid x^{(j)} \leqslant s\right\}, \quad R_2(j, s)=\left\{x \mid x^{(j)}>s\right\} \\ \hat{c}_m=\frac{1}{N_m} \sum_{x_1 \in R_m(j, s)} y_i, \quad x \in R_m, \quad m=1,2 \end{gathered}
R1(j,s)={x∣x(j)⩽s},R2(j,s)={x∣x(j)>s}c^m=Nm1x1∈Rm(j,s)∑yi,x∈Rm,m=1,2
(3)继续对两个子区域调用步骤 (1), (2), 直至满足停止条件
(4)将输入空间划分为
M
M
M 个区域
R
1
,
R
2
,
⋯
,
R
M
R_1, R_2, \cdots, R_M
R1,R2,⋯,RM, 生成决策树
f
(
x
)
=
∑
m
=
1
M
c
^
m
I
(
x
∈
R
m
)
f(x)=\sum_{m=1}^M \hat{c}_m I\left(x \in R_m\right)
f(x)=m=1∑Mc^mI(x∈Rm)
- 分类树用基尼指数选择最优特征, 同时决定该特征的最优二值切分点
定义 (基尼指数) :分类问题中, 假设有
K
K
K 个类, 样本点属于第
k
k
k 类的概 率为
p
k
p_k
pk, 则概率分布的基尼指数定义为
Gini
(
p
)
=
∑
k
=
1
K
p
k
(
1
−
p
k
)
=
1
−
∑
k
=
1
K
p
k
2
\operatorname{Gini}(p)=\sum_{k=1}^K p_k\left(1-p_k\right)=1-\sum_{k=1}^K p_k^2
Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
对于给定的样本集合
D
D
D, 其基尼指数为
Gini
(
D
)
=
1
−
∑
k
=
1
K
(
∣
C
k
∣
∣
D
∣
)
2
\operatorname{Gini}(D)=1-\sum_{k=1}^K\left(\frac{\left|C_k\right|}{|D|}\right)^2
Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
这里,
C
k
C_k
Ck 是
D
D
D 中属于第
k
k
k 类的样本子集,
K
K
K 是类的个数
如果样本集合
D
D
D 根据特征
A
A
A 是否取某一可能值
a
a
a 被分割成
D
1
D_1
D1 和
D
2
D_2
D2 两部分, 即
D
1
=
{
(
x
,
y
)
∈
D
∣
A
(
x
)
=
a
}
,
D
2
=
D
−
D
1
D_1=\{(x, y) \in D \mid A(x)=a\}, \quad D_2=D-D_1
D1={(x,y)∈D∣A(x)=a},D2=D−D1
则在特征
A
A
A 的条件下, 集合
D
D
D 的基尼指数定义为
Gini
(
D
,
A
)
=
∣
D
1
∣
∣
D
∣
Gini
(
D
1
)
+
∣
D
2
∣
∣
D
∣
Gini
(
D
2
)
\operatorname{Gini}(D, A)=\frac{\left|D_1\right|}{|D|} \operatorname{Gini}\left(D_1\right)+\frac{\left|D_2\right|}{|D|} \operatorname{Gini}\left(D_2\right)
Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
基尼指数
Gini
(
D
)
\operatorname{Gini}(D)
Gini(D) 表示集合
D
D
D 的不确定性, 基尼指数
Gini
(
D
,
A
)
\operatorname{Gini}(D, A)
Gini(D,A) 表示经
A
=
a
A=a
A=a 分割后集合
D
D
D 的不确定性. 基尼指数值越大, 样本集合的不确定性也就越大, 这一点与熵相似.
- 基尼指数关注的目标变量里面最大的类, 它试图找到一个划分把它和其它类别区分开来。
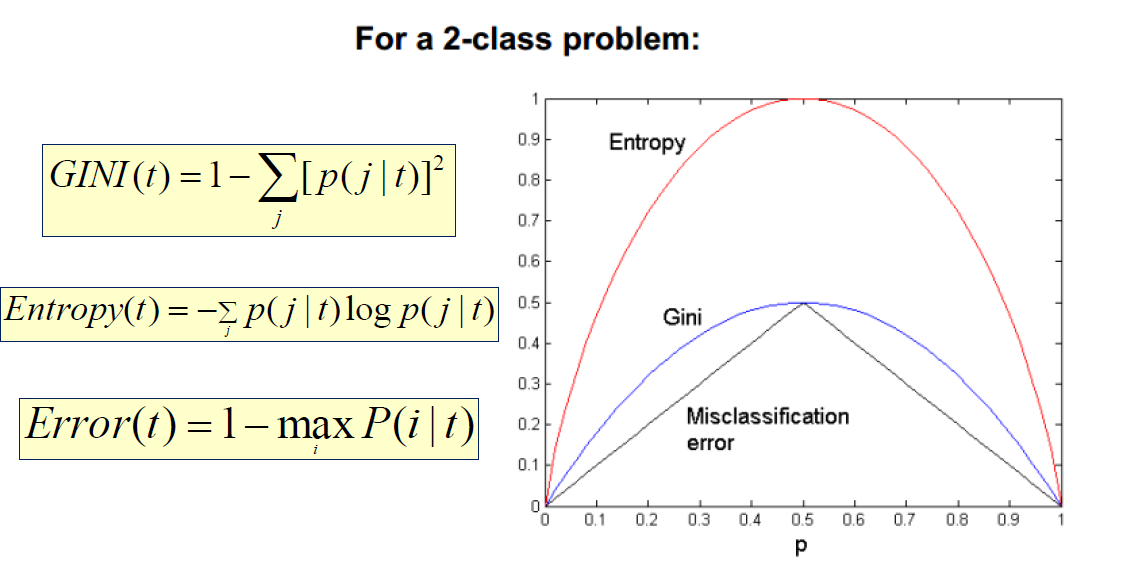
在终止条件被满足, 划分停止之后, 下一步是剪枝:
- 给树剪枝就是剪掉 “弱枝”,弱枝指的是在验证数据上误分类率高的树枝
- 为树剪枝会增加训练数据上的错误分类率, 但精简的树会提高新记录上的预测能力