FRNet做了大量的消融实验,这里仔细来分析一下。
1:ResNet backbone:
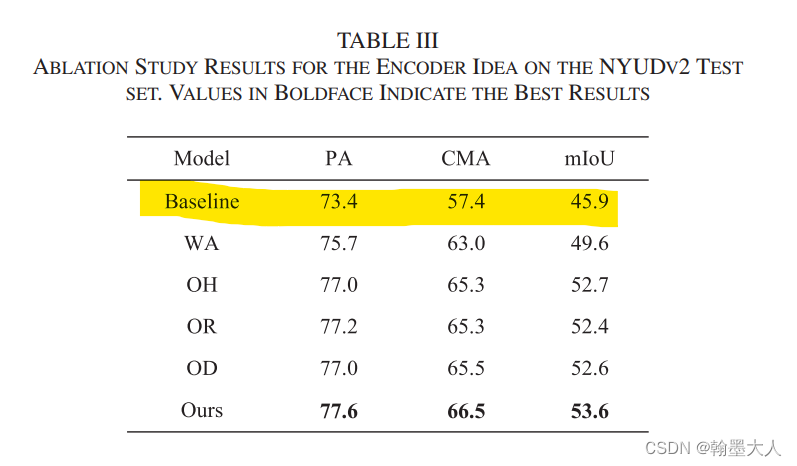
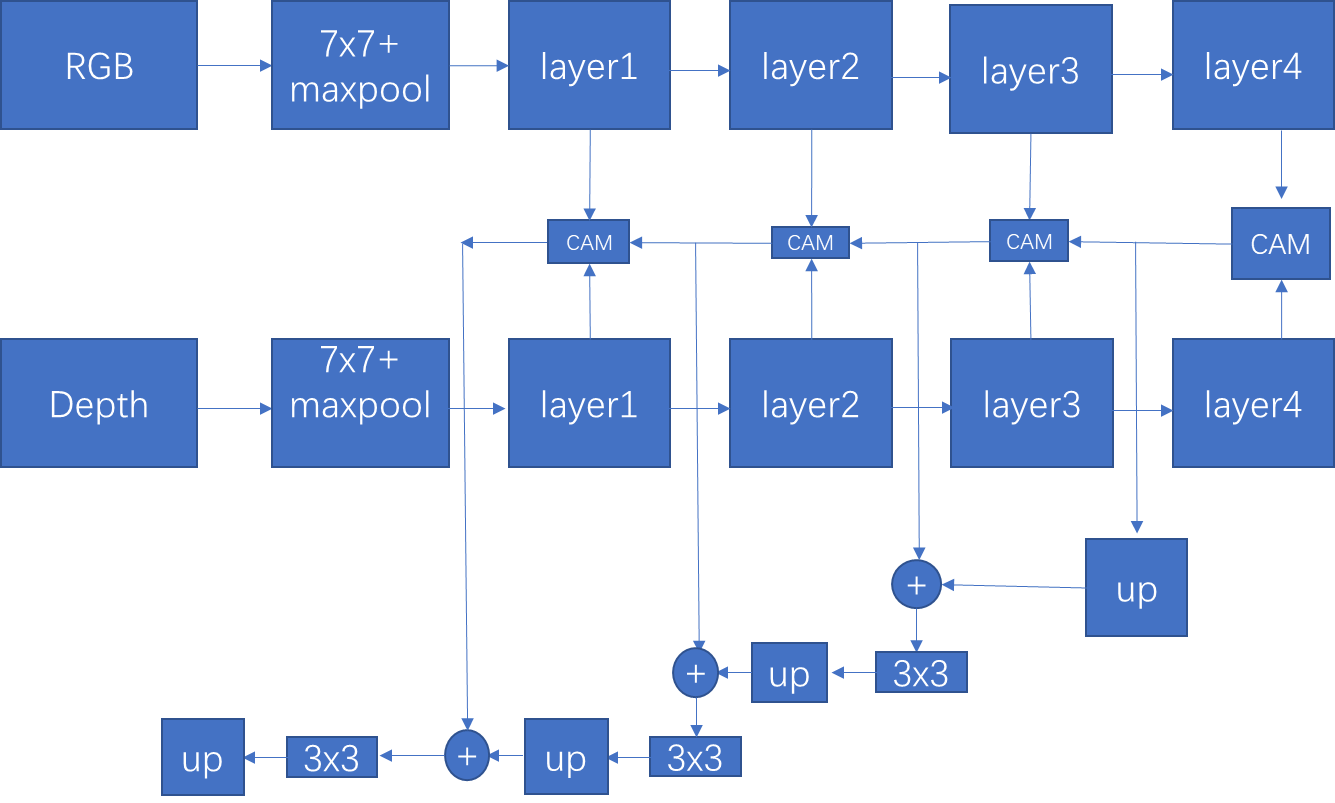
作者消融实验使用了ResNet34作为backbone来提取特征,将最后一层的输出简单相加起来,然后通过不断的上采样获得最终的输出。并且只在最后一层进行监督。最终在NYU取得了45.9%的成绩。我自己也跑过,说实话有些偏高。
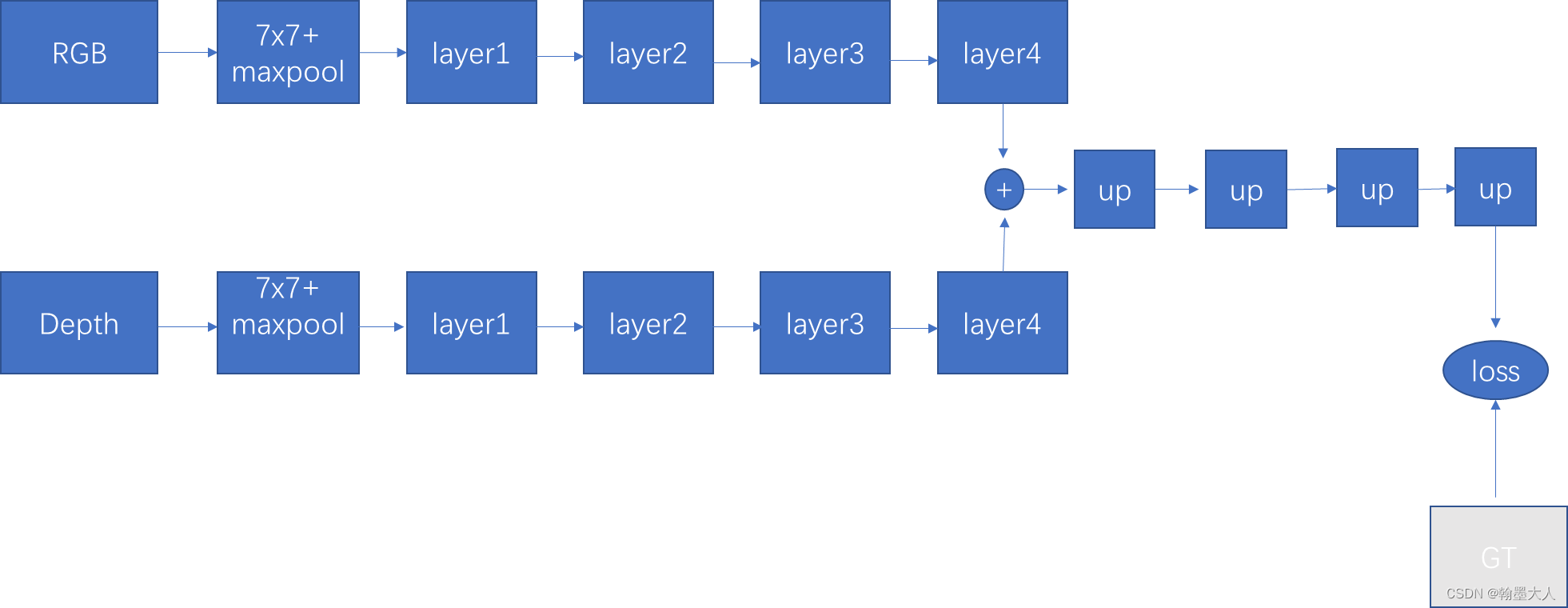
可视化:

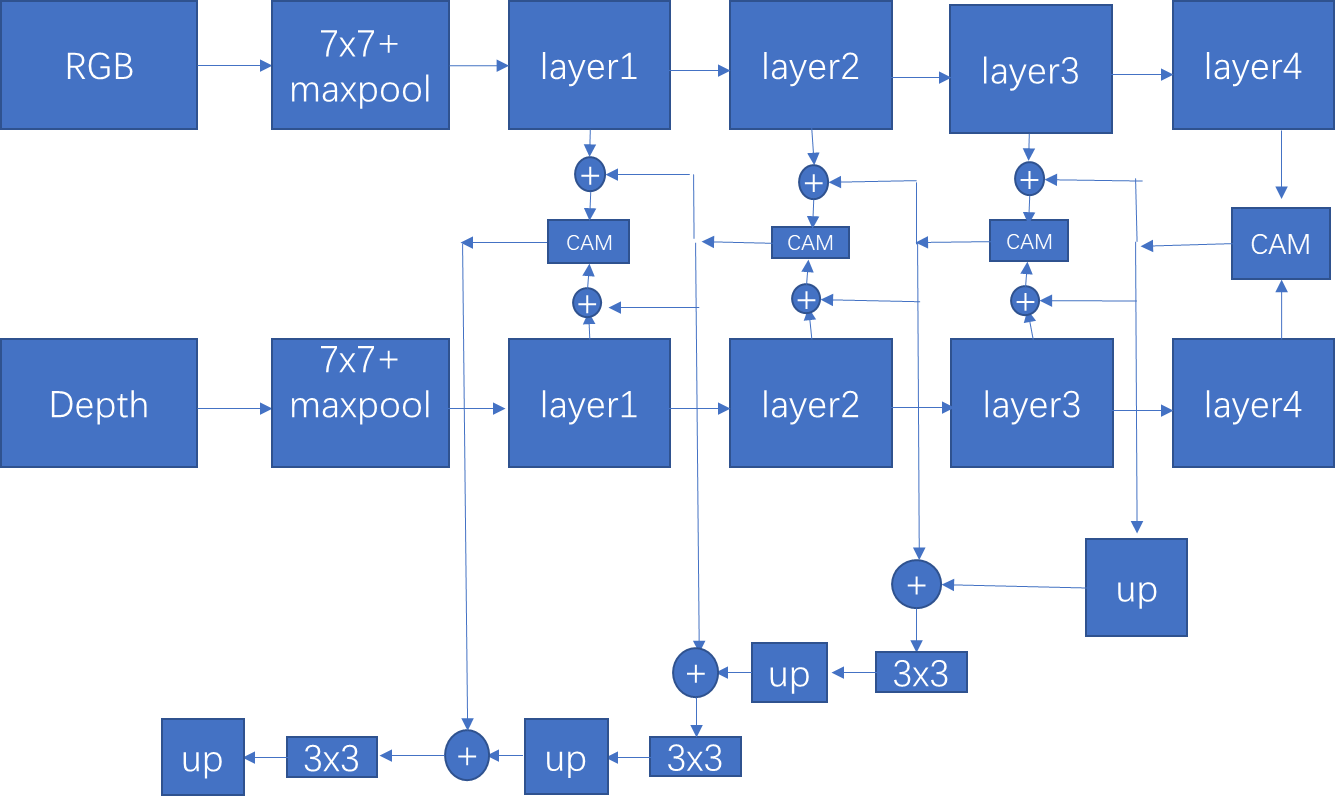
作者提到FRNet为什么可以获得比较好的结果其原因是因为考虑到了跨模态的信息,多层信息,上下文信息,多尺度监督。
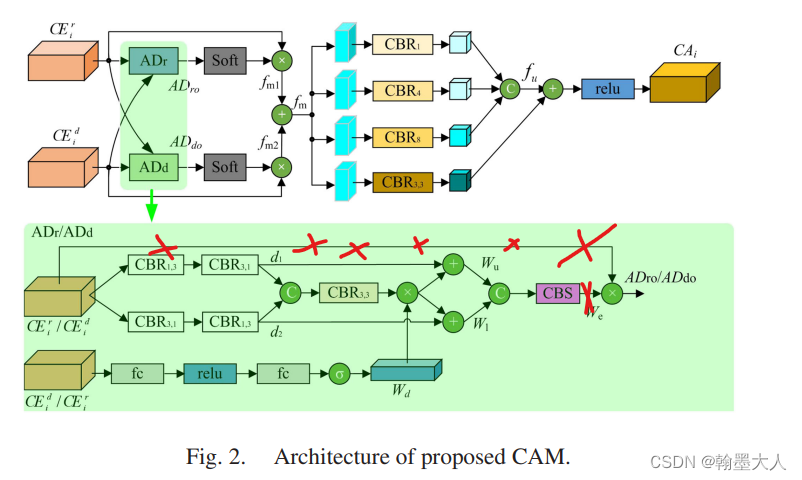
接着作者对FCE的四个变量进行验证:
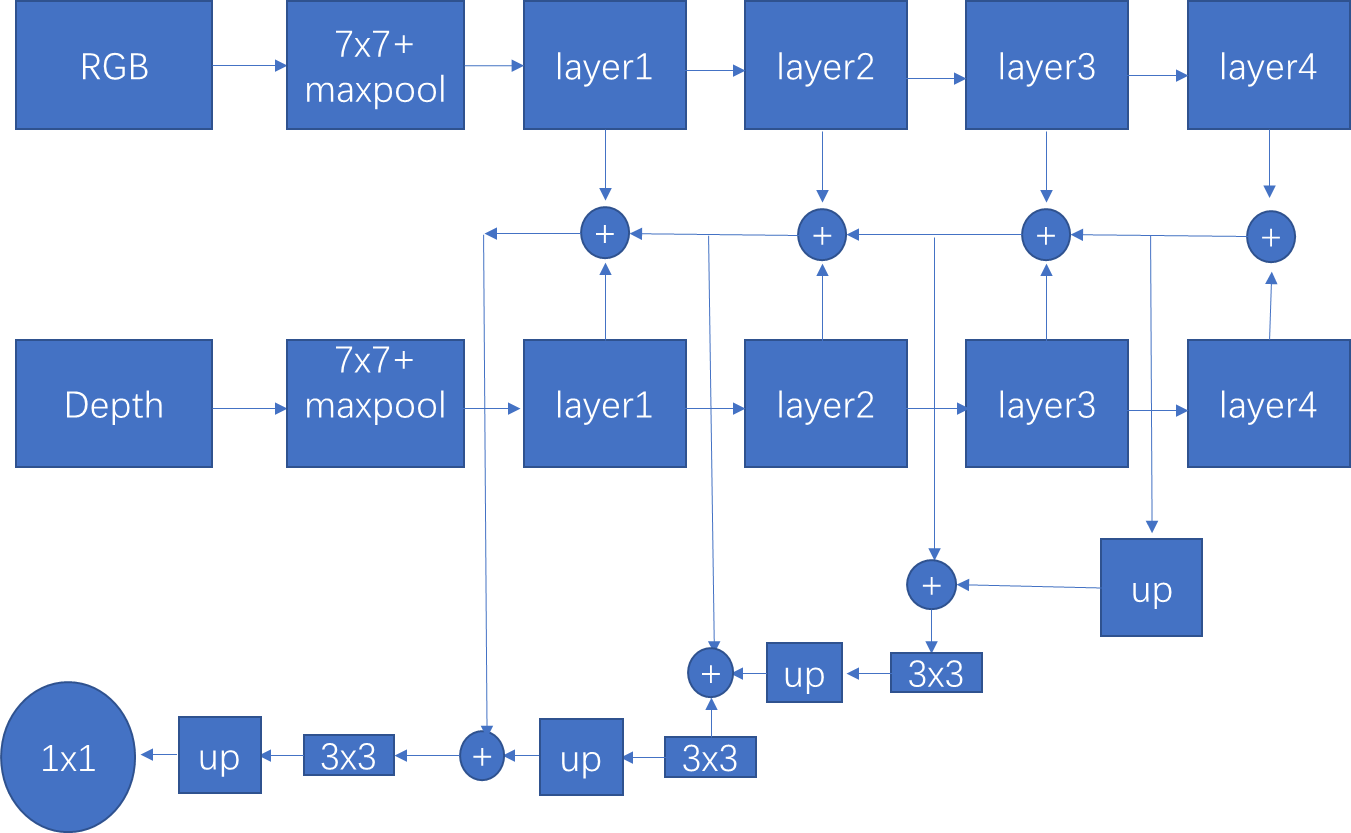
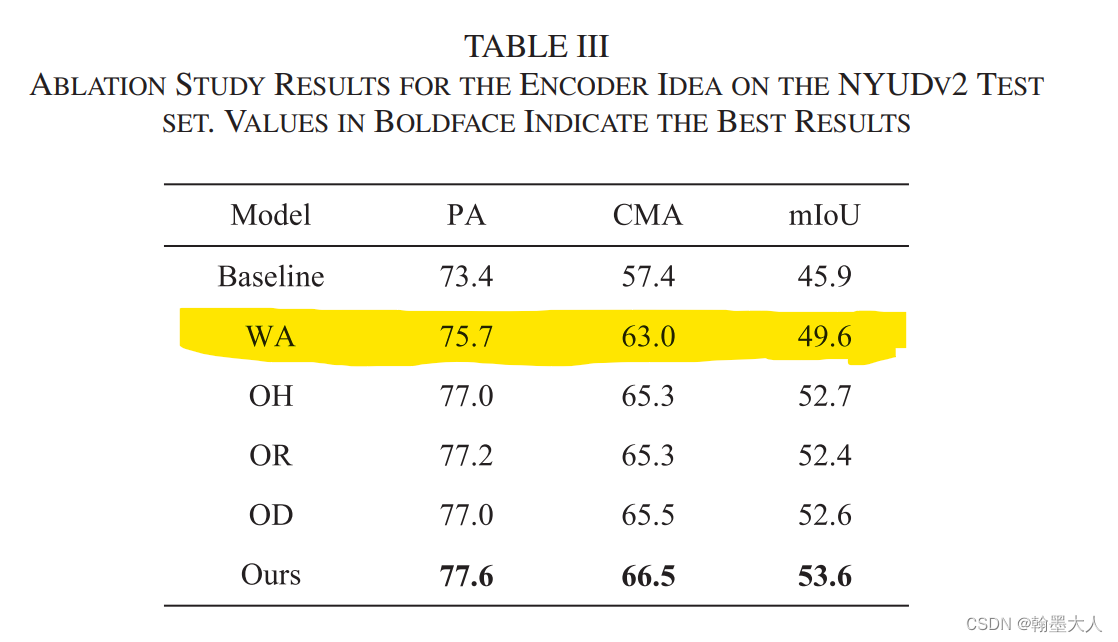
WA表示移除掉所有的重建操作,即CEM,而多层特征表示直接又相加替换掉。效果可以达到49.6。相比基础模型多了个信息的回流和融合上采样。等我下去试试这种top-down的结构的表现再回来。
可视化:

我们通过图片可以看到,如果不对RGB和Depth进行重建和融合,图片的边缘会比较模糊,且有大面积的涂抹感。
OH操作表示重建操作只在第四层有,且反向不再执行。
结果:相比于WA提升很明显有3.1%的提升。
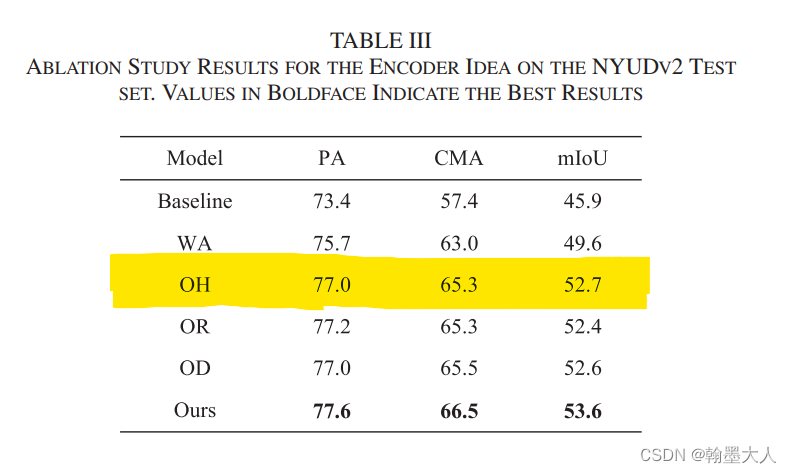
OR表示我们只重建RGB分支,OH表示我们只重建Depth分支。我们只画rgb,depth同理。效果有所降低,说明只对RGB或Depth分值进行重建不如同时进行重建。
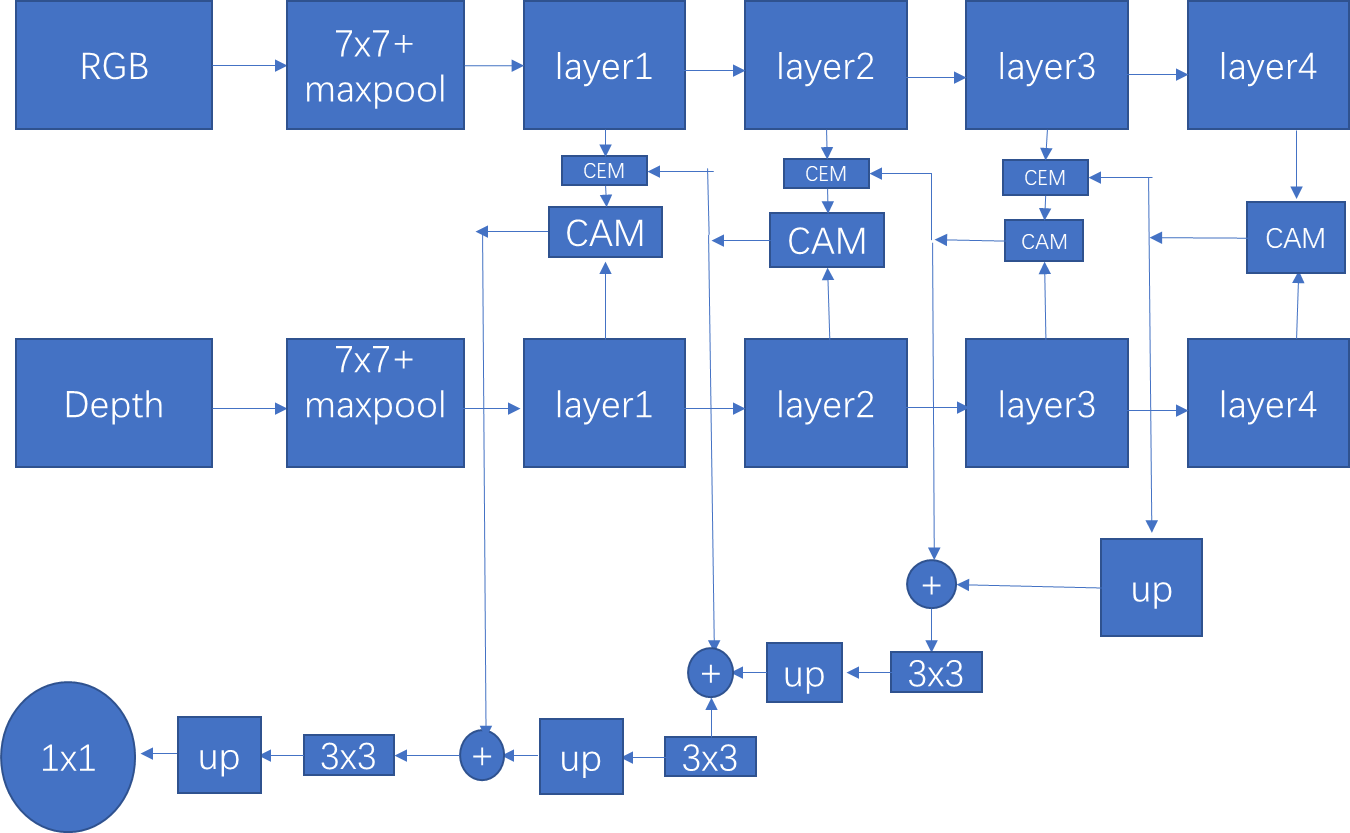
接着作者验证了添加第一层对模型的结构的影响:
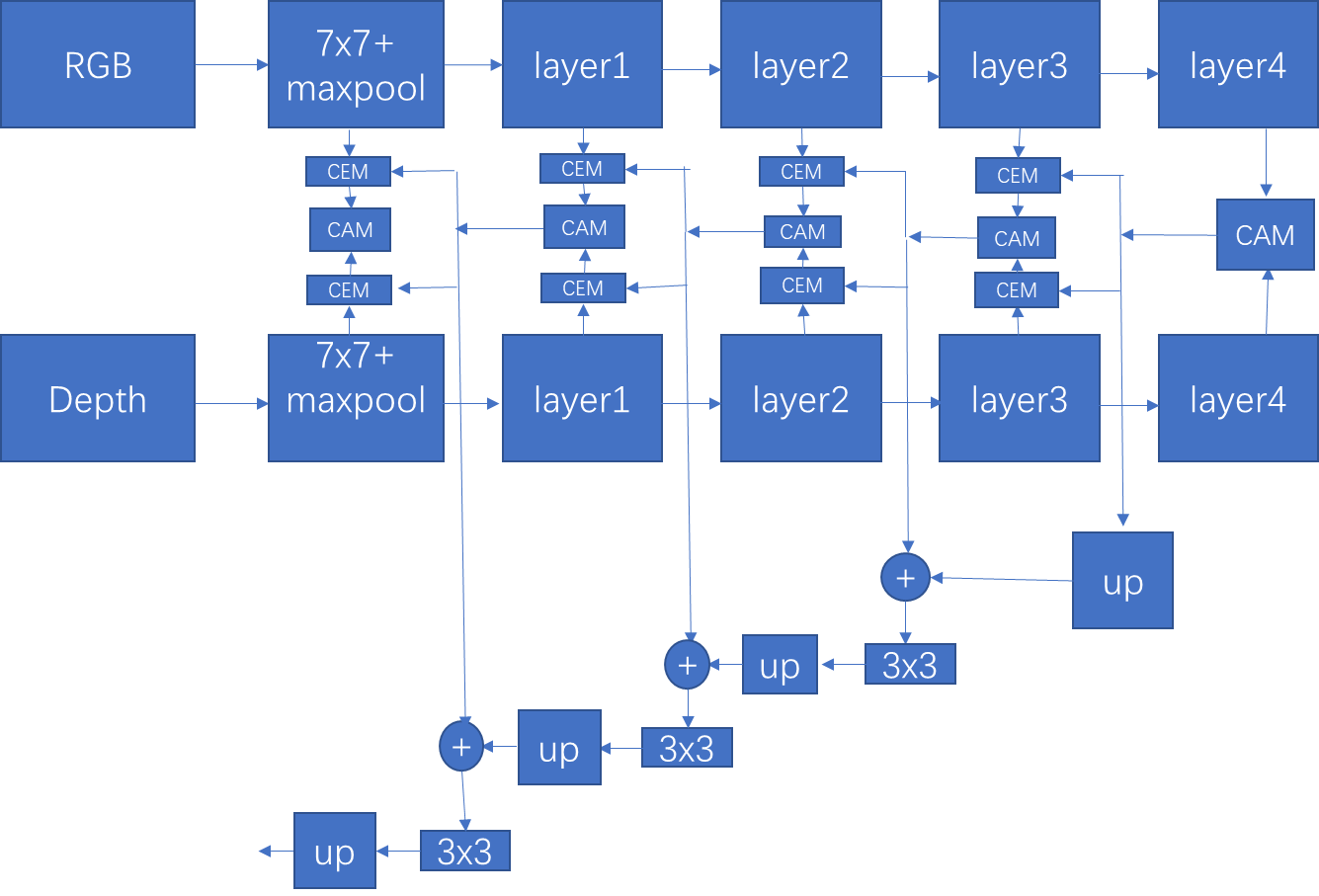
结果:添加了不如不加的好,因为第一层噪声比较多。同时参数量肯定增加了不少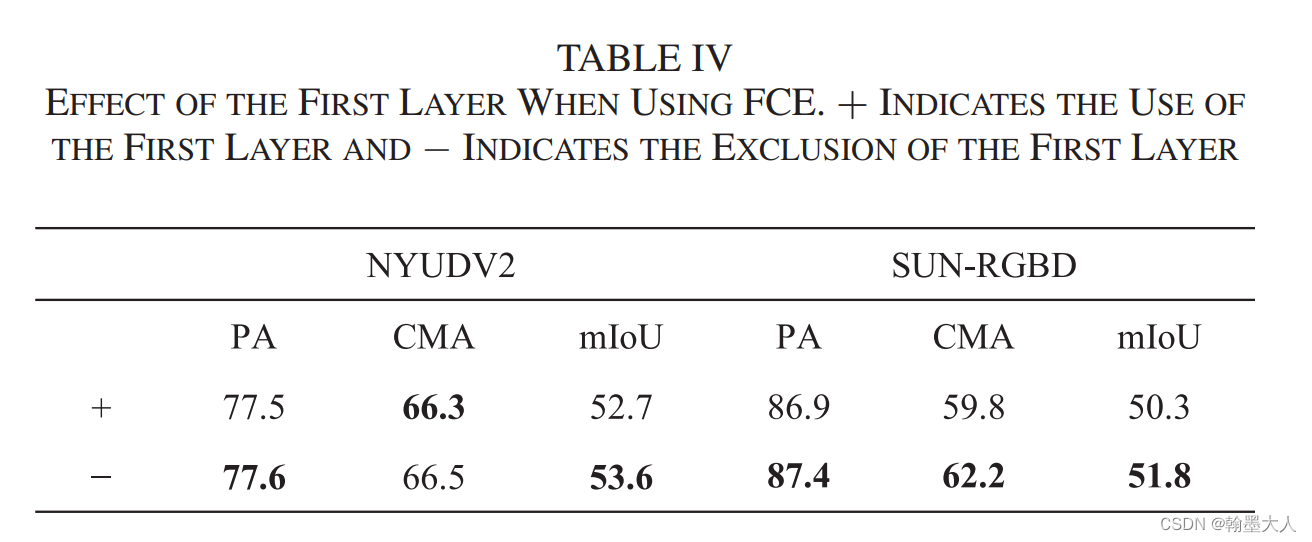
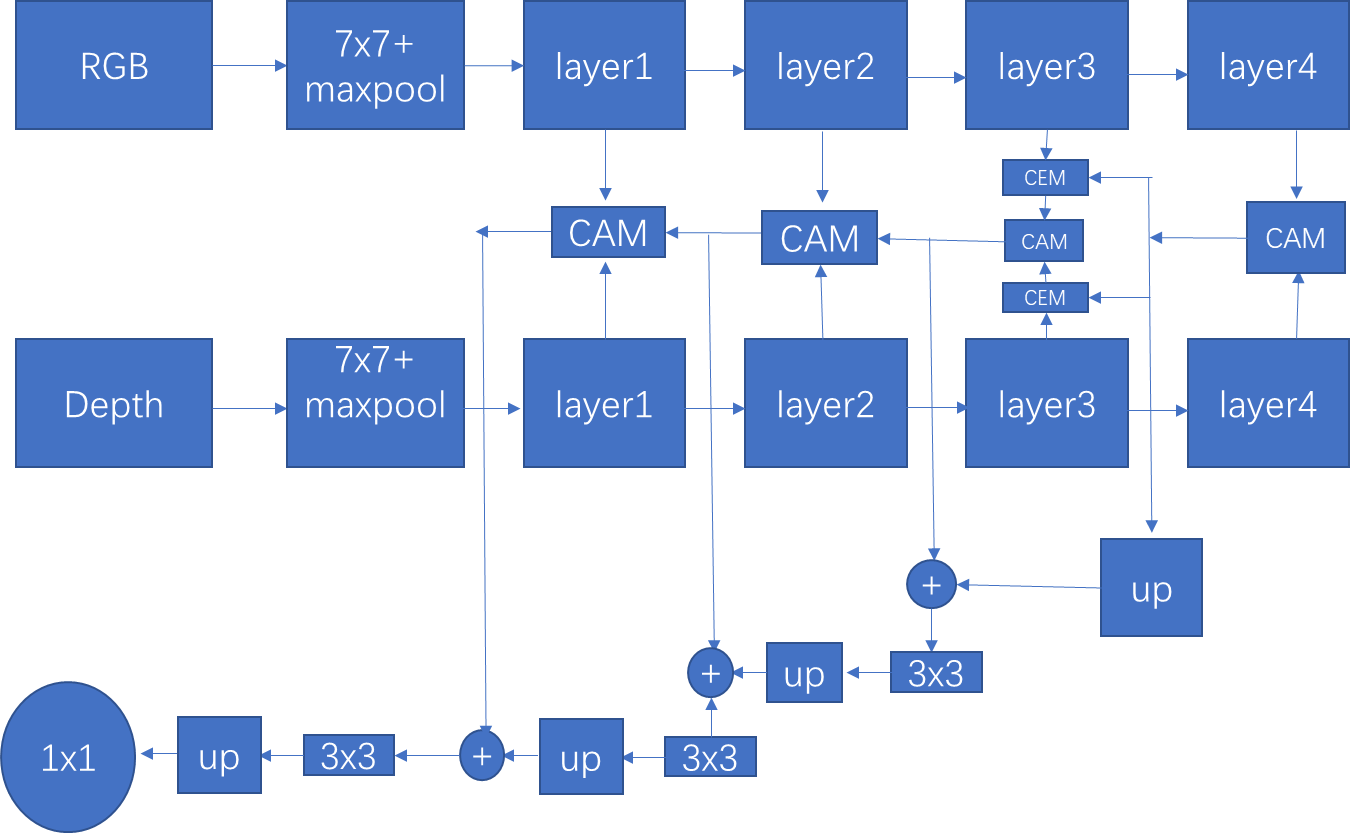
作者验证了CAM的三个变量:
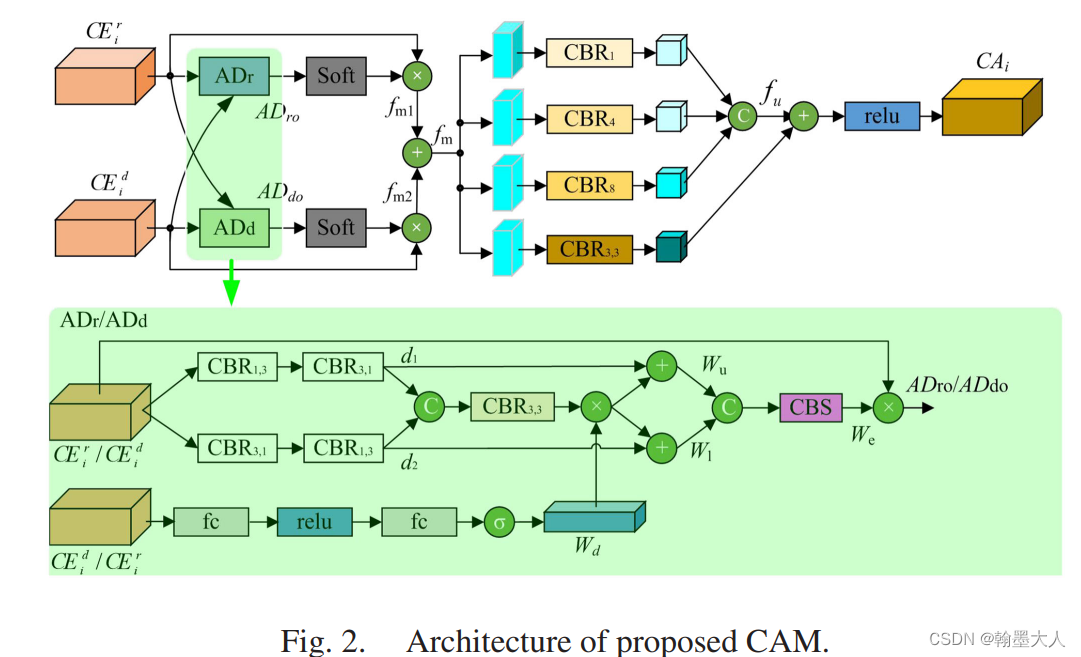
首先W+表示将所有的CAMs替换为逐像素相加。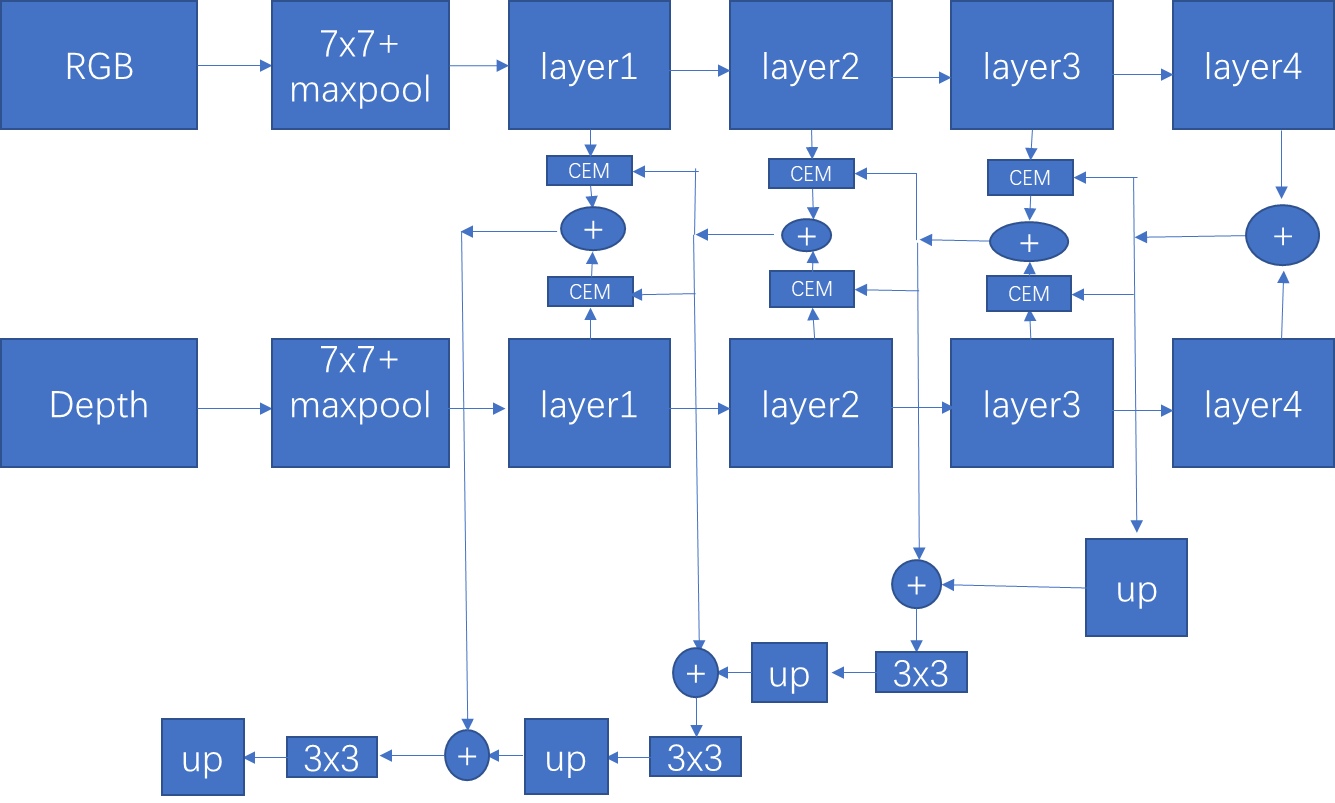
结果:51.3%
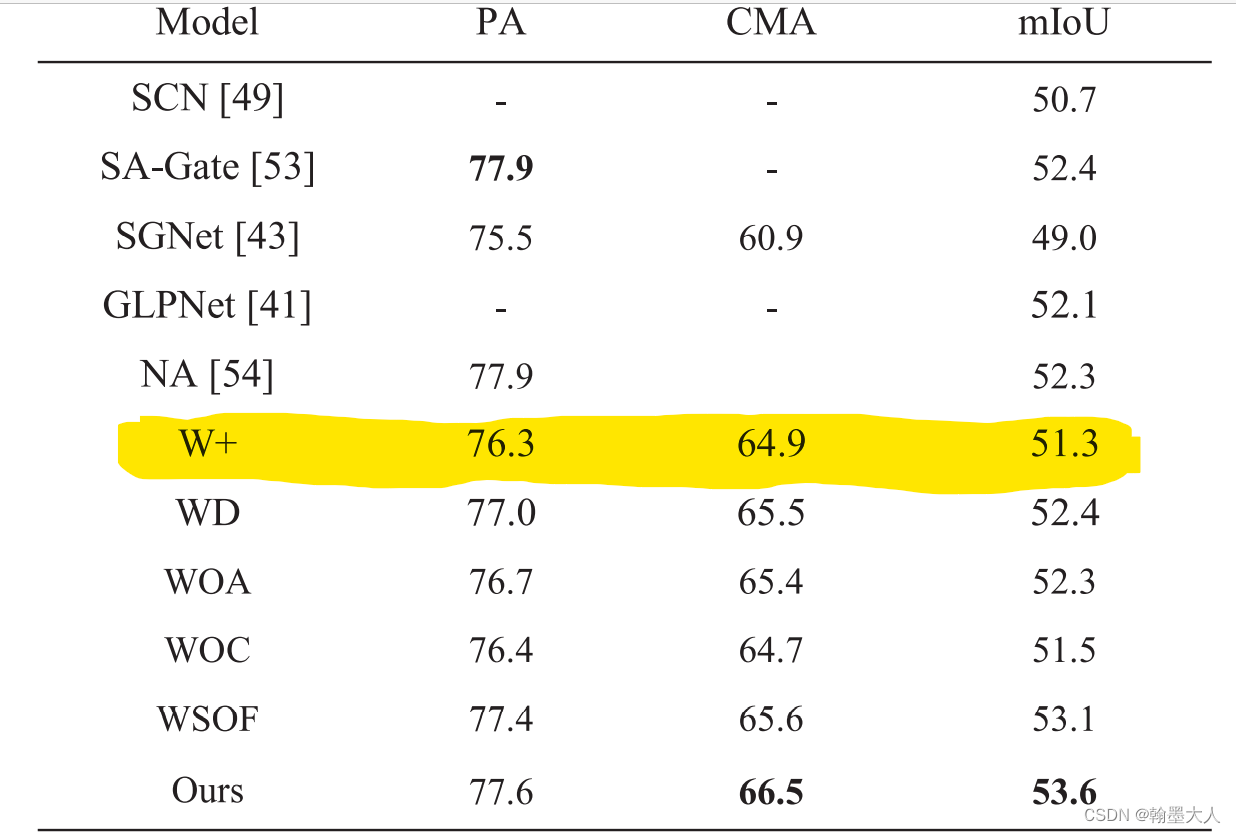
WD表示移除掉权重相乘的Wd操作。
结果:提升到了52.4%相比于逐像素相加,效果提升了1%。
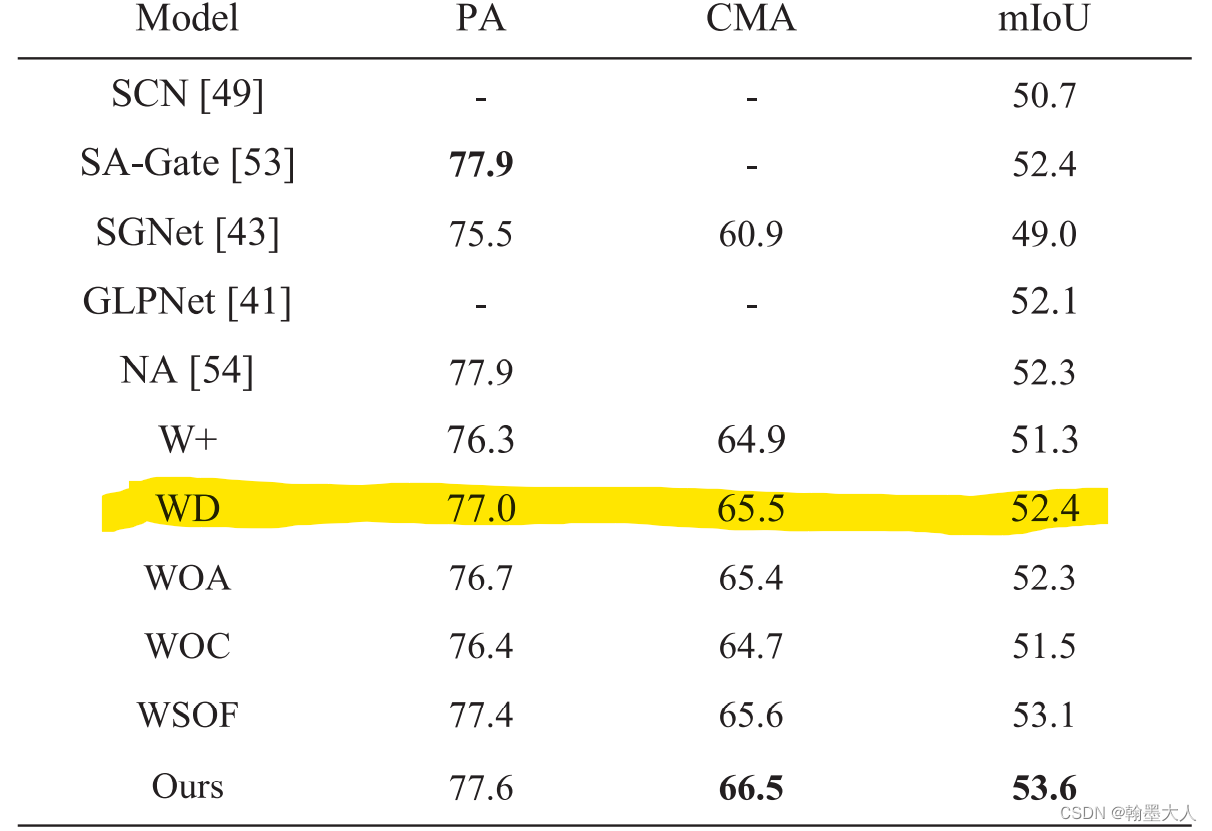
WOA表示用逐像素相加和卷积替代ADr和ADd:
结果:和WD结果差不了多少。
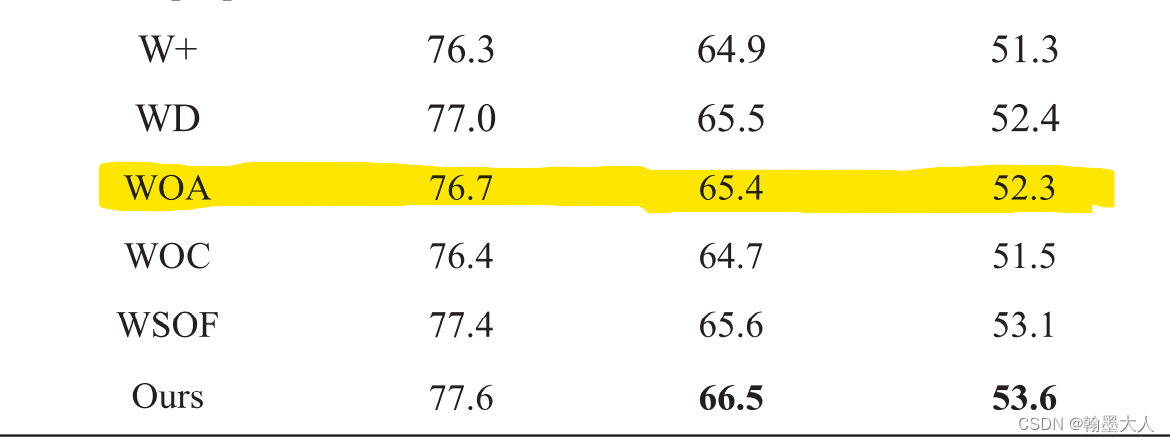
WOC:表示移除多尺度特征提取。
结果:相比于之前的效果降低了一些,可以知道多尺度特征提取是有用的,即ASPP比一般的卷积效果好一点,这个我也经过实验的。
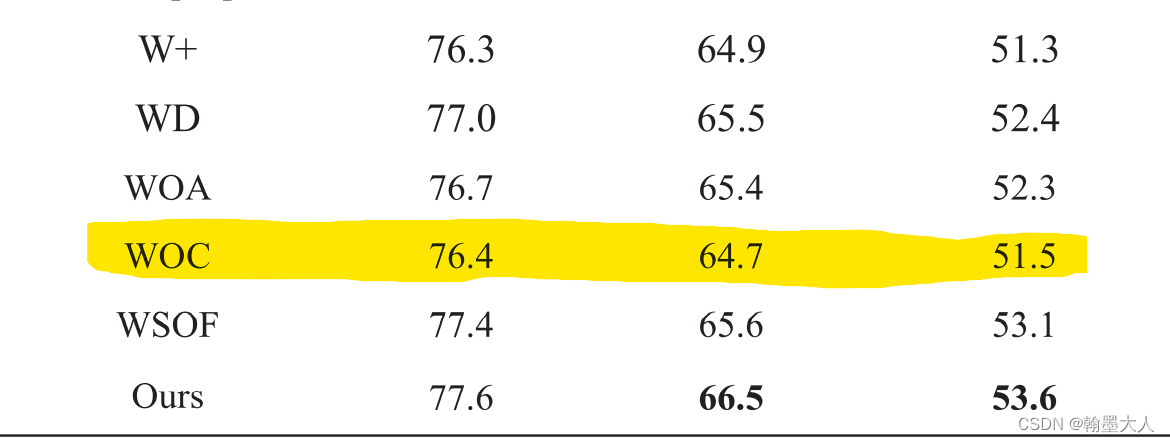
WSOF:
结果:稍微有点降低。

接着是CAM模块的效果可视化:

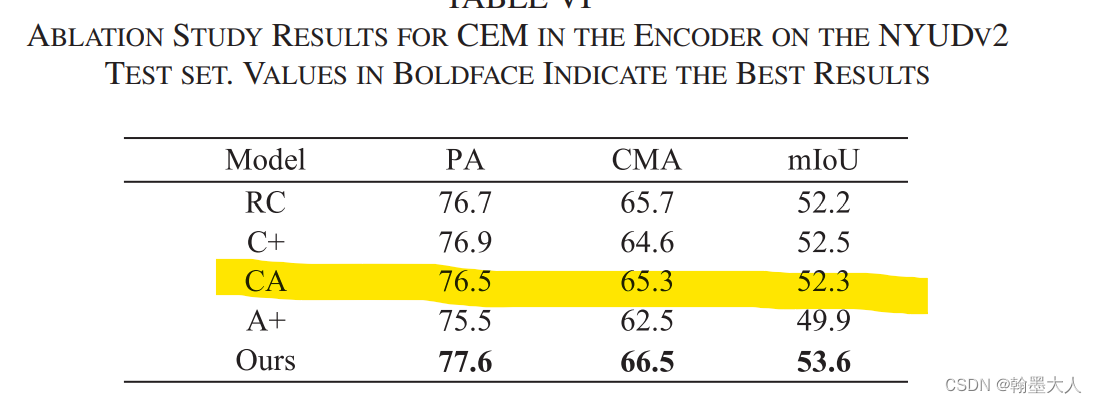
接着是CEM的三个变量:
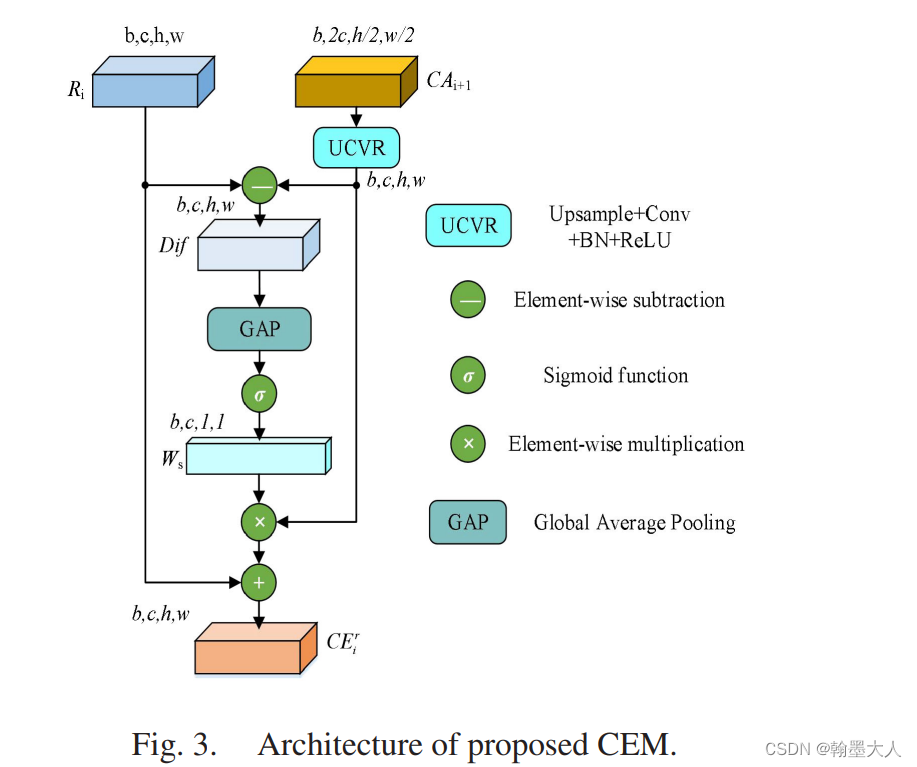
首先是RC,删除掉所有的CEMs,输出值用原始的RGB替换掉,这里的原始RGB到底是输入的RGB还是经过每层卷积后的RGB,这里暂且为经过每层卷积后的RGB。
结果:相比于最好的结果降低了1点多。
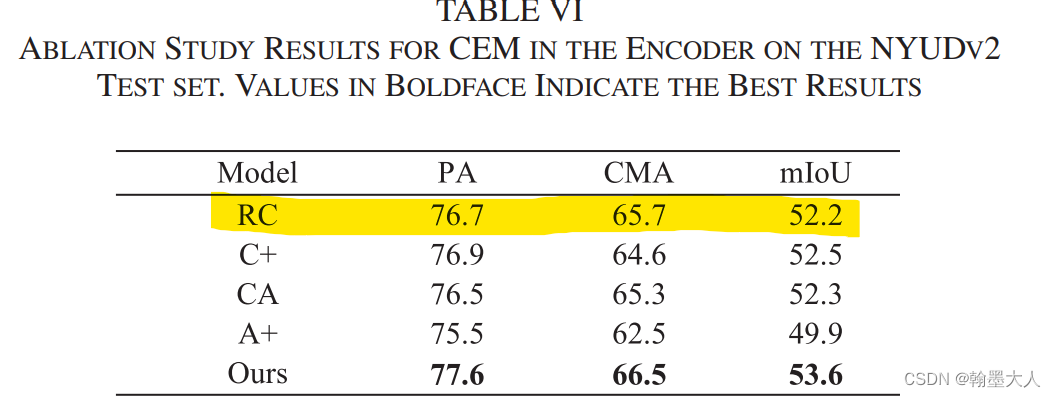
结果可视化:

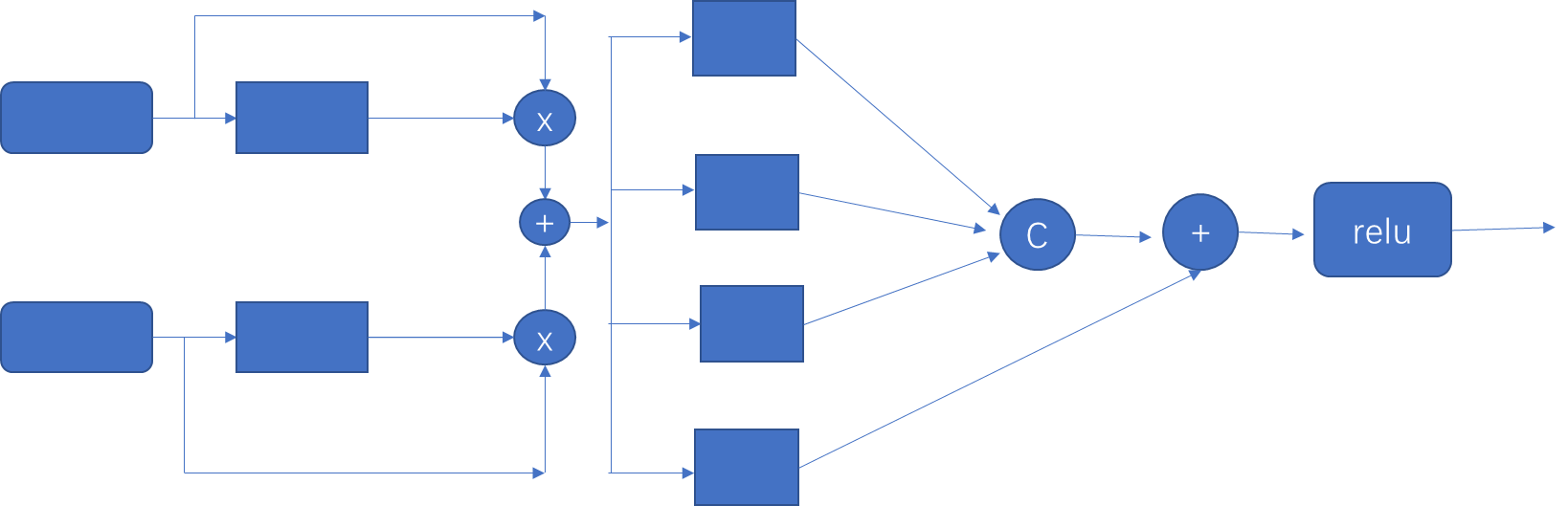
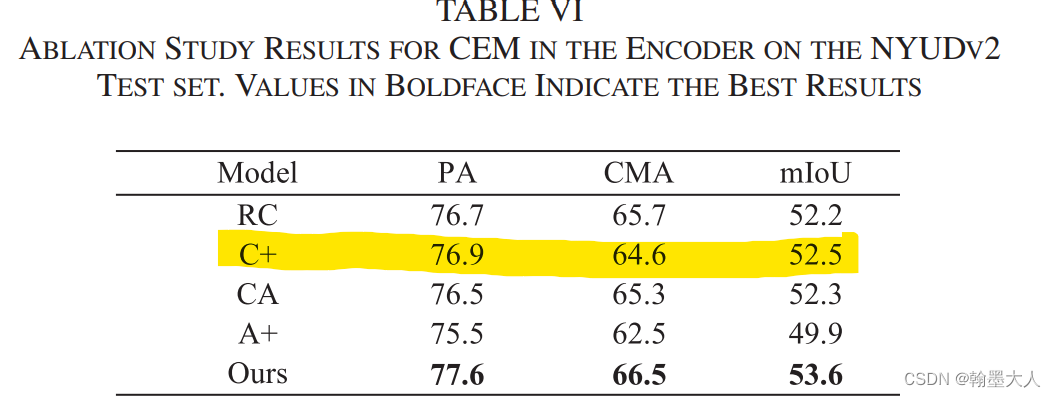
C+:用SUM替代所有的CEMs。
结果:相比于不加高层次的语义信息还是有些许提升。
CA:验证逐像素相减的有效性,将减法替换为加法。
结果:有所下降,相比于逐像素相加,相减可以有效地突出特征的差异。
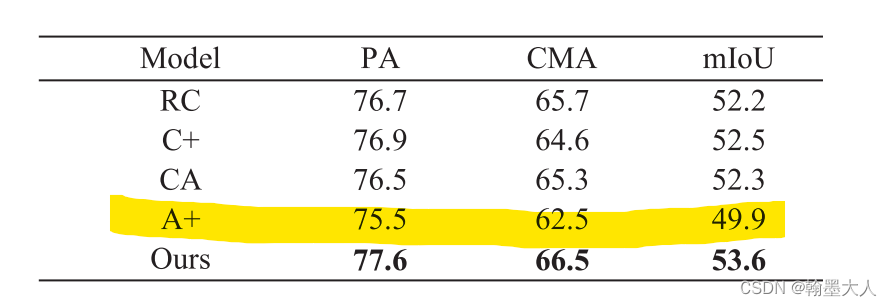
CA:将CEM和CAM替换为sum。
结果下降了4%,证明CAM和CEM的有效性。
总结:
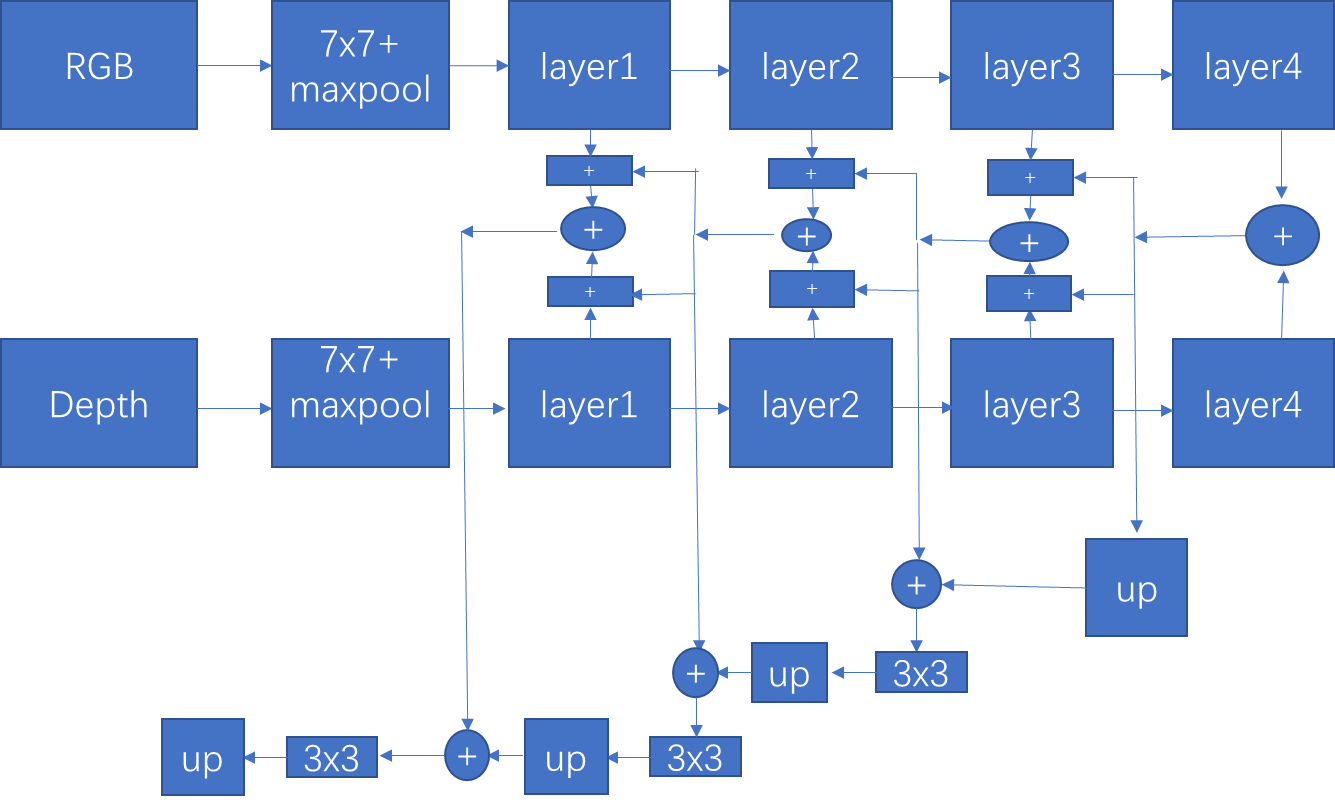
1:类似于TOP-Down结构效果还是挺好的。即高层语义信息向低层的细节特征flow。
2:整个模型总体看来就是一个点即RGB和Depth的融合问题。融合的效果好最后的结果也是很好的,比如SA-Gate,encoder只关注RGB和Depth的融合问题,decoder比较简单。
3:RGB和Depth融合,一般三四个分支就足够的,不用太多,说的就是第一层,即经过池化后融合大可不必和decoder融合,增加计算量,并且第一层特征噪声比较多。
4:跨模态,跨层融合比单一的融合效果更好。同时注意力也是必不可少的。
5:类似于ASPP的结构获得更大的感受野,加在模型中会有一点提升。