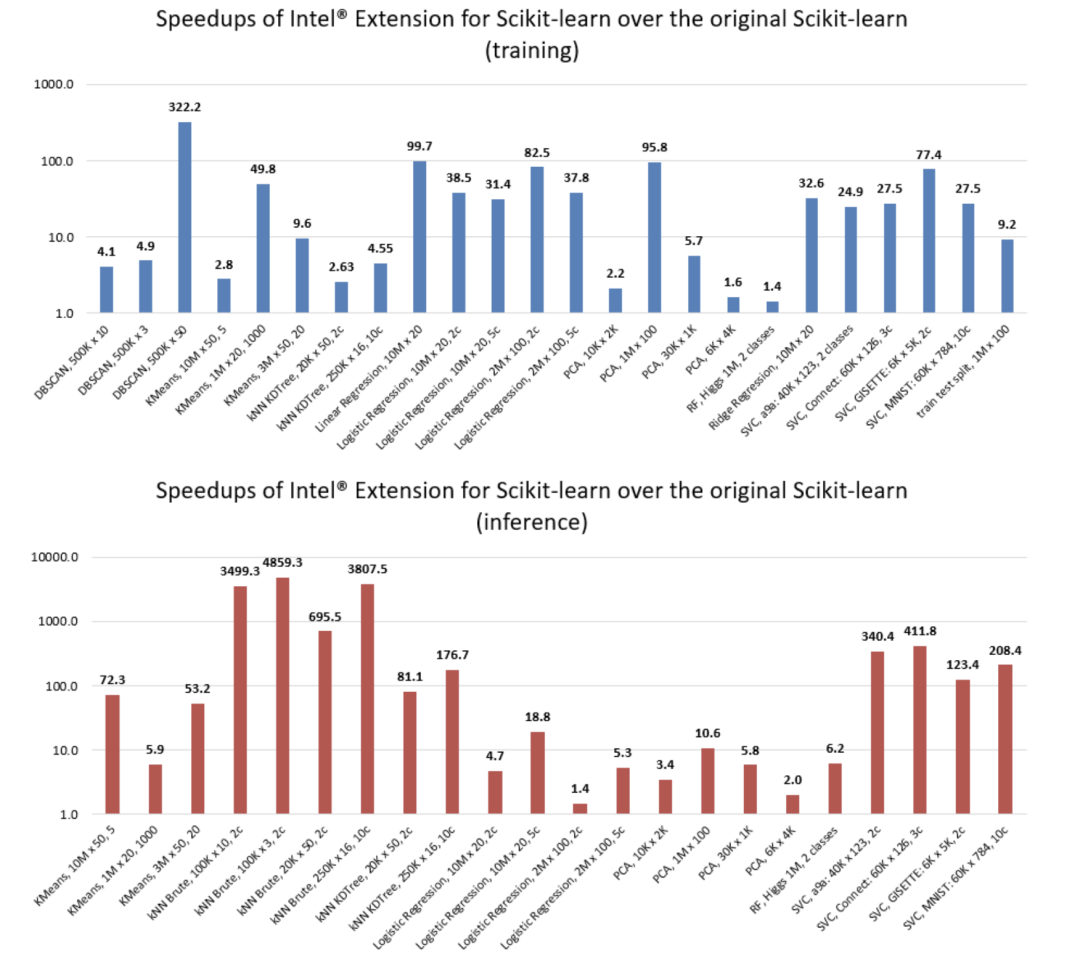
文章目录
- 一、问题背景
- 二、复杂并发场景释义
- 2.1 简单并发场景
- 2.2 复杂并发场景
- 三、分组并发调度模型演进
- 3.1 简单异步并发调度
- 3.2 分组并发调度
- 四、自驱动并发调度模型演进
- 4.1 一个优化耗时的小目标及其实现
- 4.2 下一步的疑惑
- 4.3 对问题的重新思考以及自驱动并发调度模型的诞生
- 4.3.1 重新思考
- 4.3.2 自驱动并发调度模型
- 五、结语
一、问题背景
设想,打开一个 APP,我们会看到什么?答案是:内容信息。
例如当我们打开转转 APP 时,目光所及的首页、商品列表页、商品详情页…以上我们简称为信息聚合场景。在电商 APP 中,此类信息聚合场景往往需要聚合多种数据源才能完成最终渲染,这也意味着在微服务架构中,服务端响应一次用户请求需要聚合 N 个内部 RPC 请求响应的数据才能完成最终响应。
而为了尽快响应用户请求,往往需要通过某些方式异步发起多个 RPC 请求来获取结果数据,我们把这样的过程称为并发场景。
二、复杂并发场景释义
2.1 简单并发场景
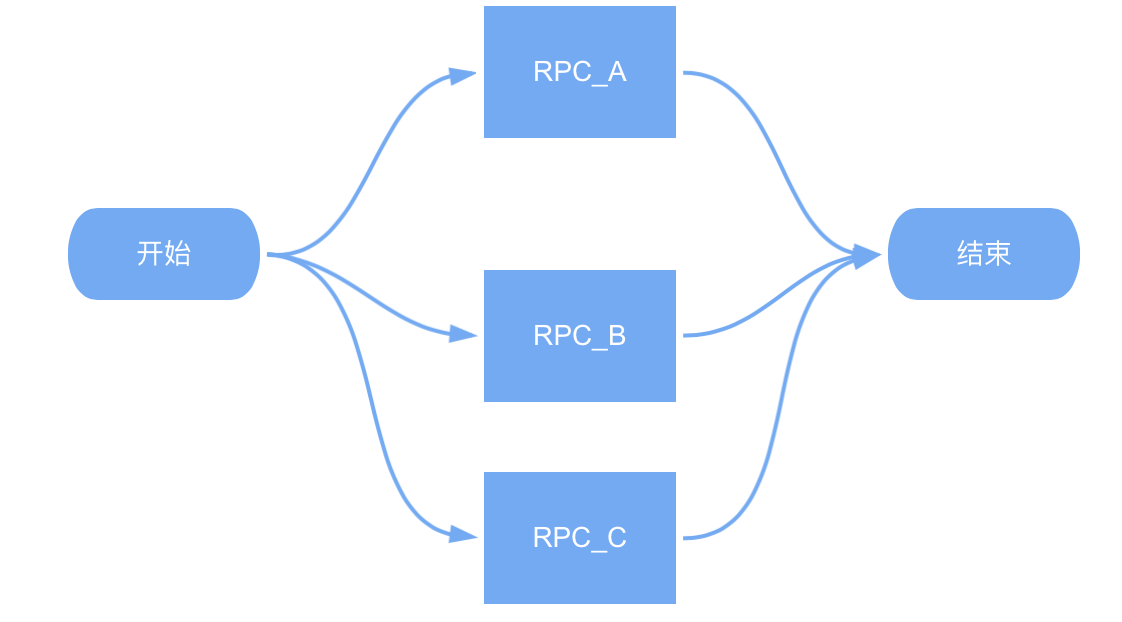
较为简单的信息聚合场景,一次信息聚合过程只需要 N 个相互独立的 RPC 结果即可。如下图所示:
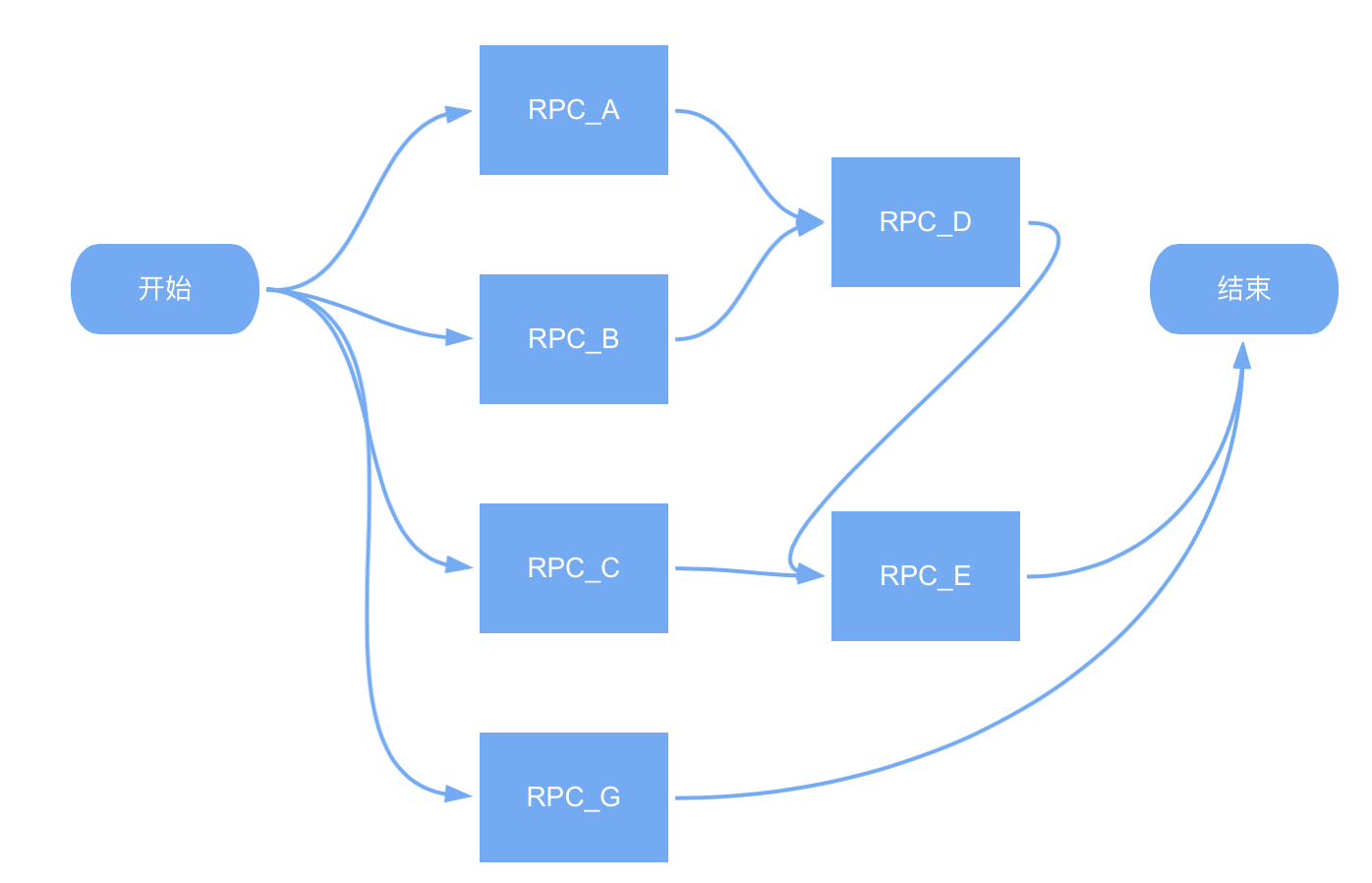
2.2 复杂并发场景
较为复杂,但却常见的重要信息聚合场景。通常意味着响应一次用户请求的过程:1,需要聚合多个 RPC 响应结果;2,内部多个 RPC 请求之间存在相互依赖关系,如下图所示:D 的 request 依赖 A、B 的 response;E 的 request 依赖 C、D 的 response;…
三、分组并发调度模型演进
3.1 简单异步并发调度
为了尽量提升服务端的请求响应速度,我们可以有一些简单的方式,如:
基于 Future 等基础能力,在一次用户请求的处理过程中,异步执行没有前后依赖关系的 RPC 过程。
这种方式通常更适用于简单并发场景,而复杂并发场景下怎么办呢?
自然而然,我们很容易想到一个方式:分组并发调度。
3.2 分组并发调度
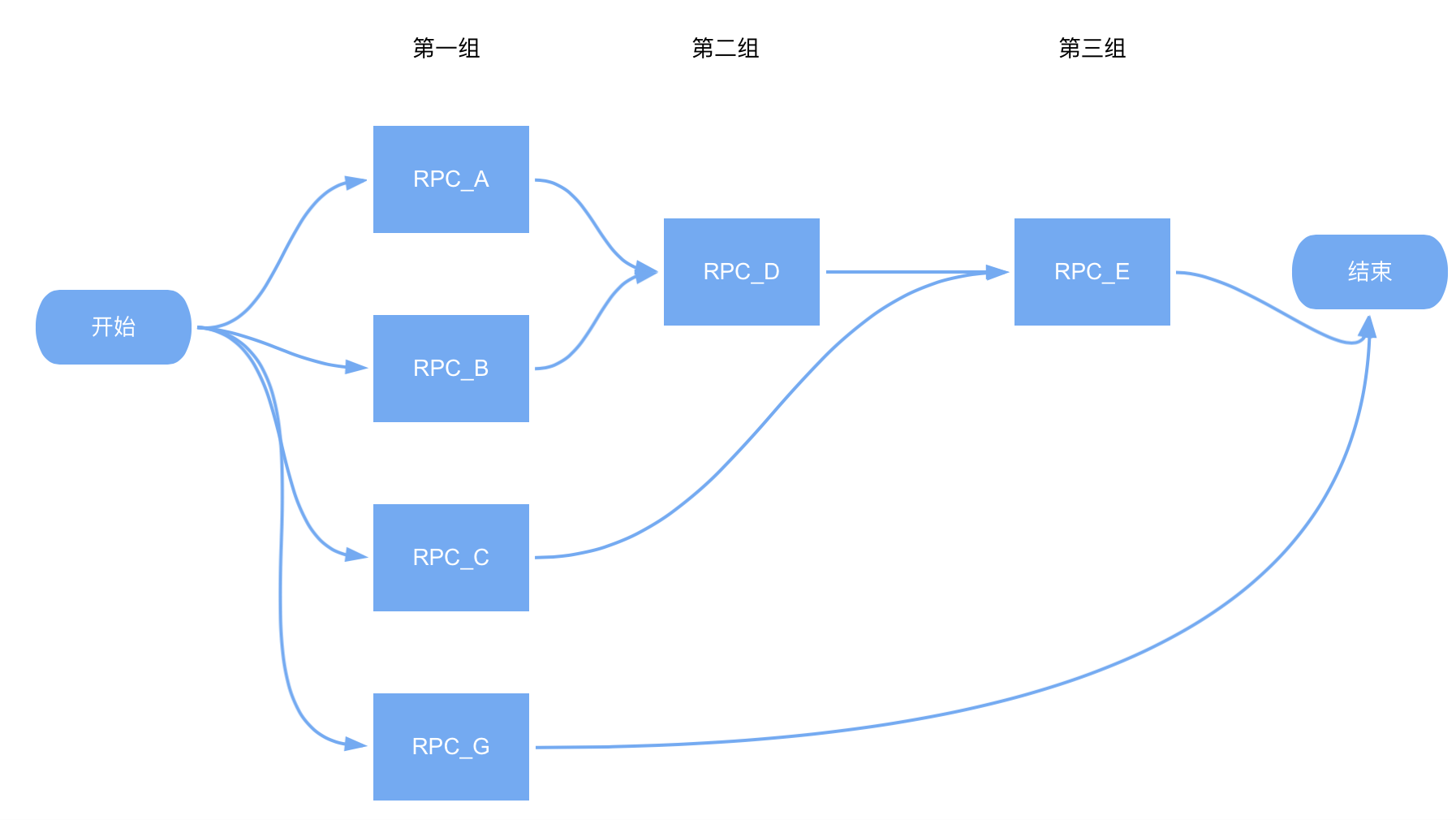
分组并发调度主要适用于一次用户请求处理过程需要聚合多个存在前后依赖关系的 RPC 查询结果的复杂并发场景中,通常我们会使用如下方案:
1,分组:将所有 RPC 查询过程按照依赖关系分组。如:没有前置依赖的 RPC 过程认为是第一组;依赖第一组的 RPC 过程认为是第二组;依此类推…
2,调度:基于 CompleteFuture、Future 等基础能力,依次从第一组开始并发执行组内的 RPC 过程。即:组间同步、组内异步。
为了提升开发效率,我们可以基于 Future 等基础能力重新封装自己的分组并发调度工具,甚至集成并发治理等方面的能力,如:细粒度的超时调控、熔断降级机制,以大幅度降低治理工作成本。
四、自驱动并发调度模型演进
4.1 一个优化耗时的小目标及其实现
在 2020 年 Q2,转转基础生态有这么一个 OKR:实现全平台核心接口平均耗时稳定降低到 90ms 以下。不可忽略的背景是彼时接口耗时在 120ms 上下,且受下游服务方影响,每周呈现 10ms 的上涨趋势。为了完成这个不太可能的目标,我们做了这些事情:
1,分析接口单位贡献值:主要根据接口 QPS,分别分析单接口每降低 10ms 的响应时间对全局响应的贡献值,确定优化方向。
2,理解每一毫秒的耗时:假设从监控平台我们可以看到某个接口耗时为 200ms,但具体耗时在哪是不明确的。为此,我们在每个接口的内部执行逻辑,从代码行的维度监测耗时,尝试去完全理解每一毫秒。
3,并发调度调整:基于上述准备,进行接口耗时优化。期间我们发现严格的分组并发调度模型并不能达到最佳调度,为此我们又破坏了原本的分组模型,将一些没有前后依赖的长耗时 RPC 过程单独提取出来做全局异步调度。
在 Q2 结束,全平台核心接口平均耗时降低到 85ms,超额完成了既定目标。
4.2 下一步的疑惑
随着耗时优化目标的完成,我们产生了一些这样的疑惑:
1,开发维护工作依旧繁琐:复杂并发场景中,随着业务迭代,代码腐化严重。一个小需求的迭代可能需要太多的前置熟悉代码的时间。
2,接口耗时优化工作周而复始:回想过去,每到一定的时间(例如一两周、一两个月),需要花费时间去调整并发模型,优化组织分组逻辑以尽可能消除业务迭代带来的影响。
3,分组并发调度模型的折中:结合上述目标的完成过程,我们为了性能而应用分组并发调度模型后又为了性能破坏既定模型。
信息聚合场景的接口耗时优化,下一步该怎么做?
4.3 对问题的重新思考以及自驱动并发调度模型的诞生
4.3.1 重新思考
回想以往,我们做的是什么?不外乎:编织一幅图。
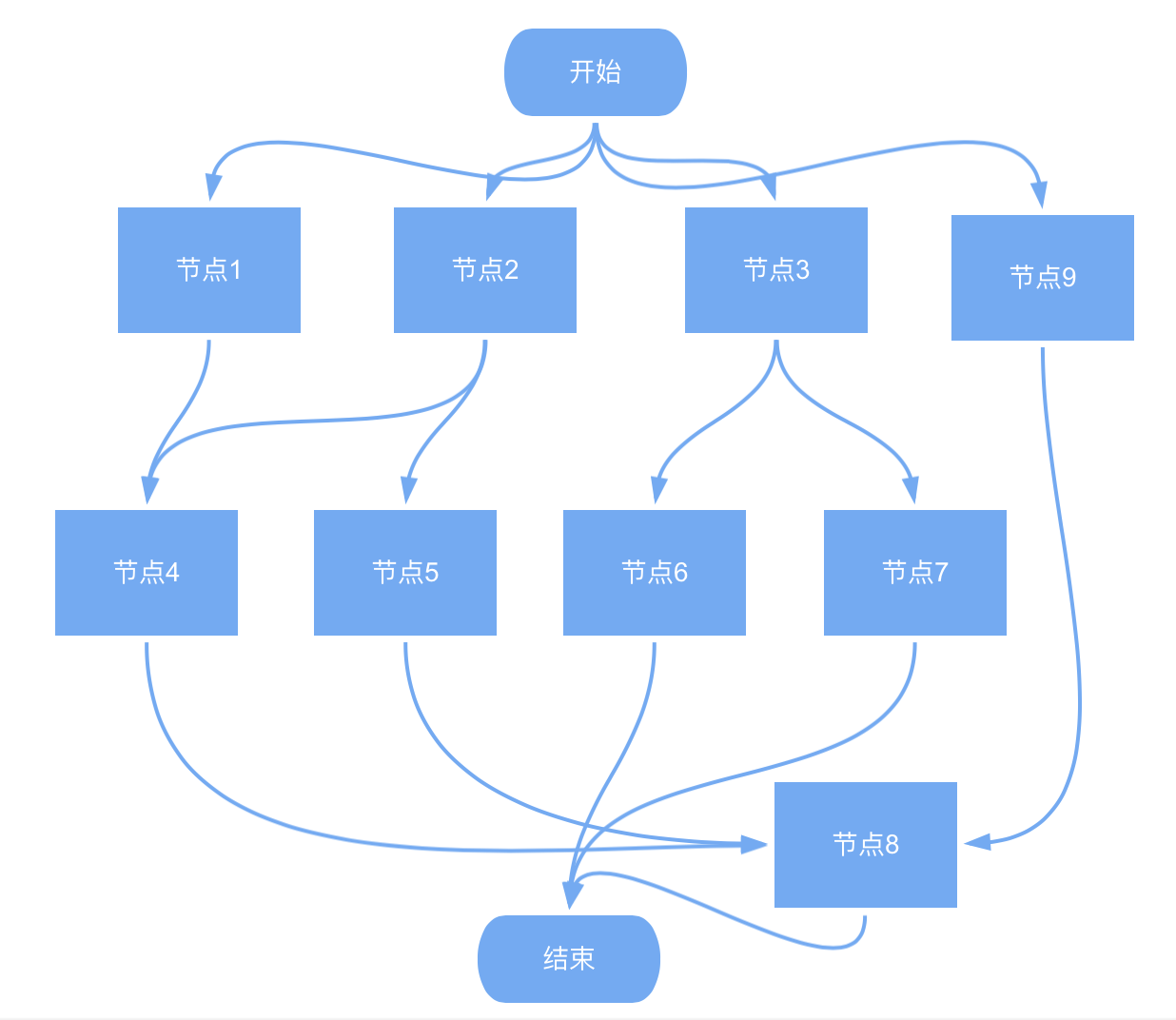
上图示意一次用户请求(如商品列表页搜索)的内部 RPC 聚合过程,一个最简单的聚合节点等同于一次 RPC 请求过程。
回首我们的开发工作,会发现做的事情其实是:
1,画点:例如商列需要展示活动信息,此时就会新增一个查询活动信息的 RPC 聚合节点。
2,连线:我们依据依赖关系将可以同时并发查询的节点放置于同一组。
3,画图:组织各组的并发调度、数据同步、并串行驱动下一组。
整个过程概括起来就是:点动成线,线动成面。可能这正是对复杂并发场景下一系列表面问题背后的不可分割的基本组成的一种描述。
4.3.2 自驱动并发调度模型
基于以上思考,可以发现在业务开发中:
1,业务逻辑强相关的增量逻辑在于*“点”。
2,业务逻辑弱相关的重复工作成本在于“连线”、在于“图的编织”。
那么,有没有一种可能:开发者仅仅关心“点”,由额外的框架能力来处理“线”与“图”?
即是“点动成线,线动成面”中“动”的工作由框架能力自动化支持*。
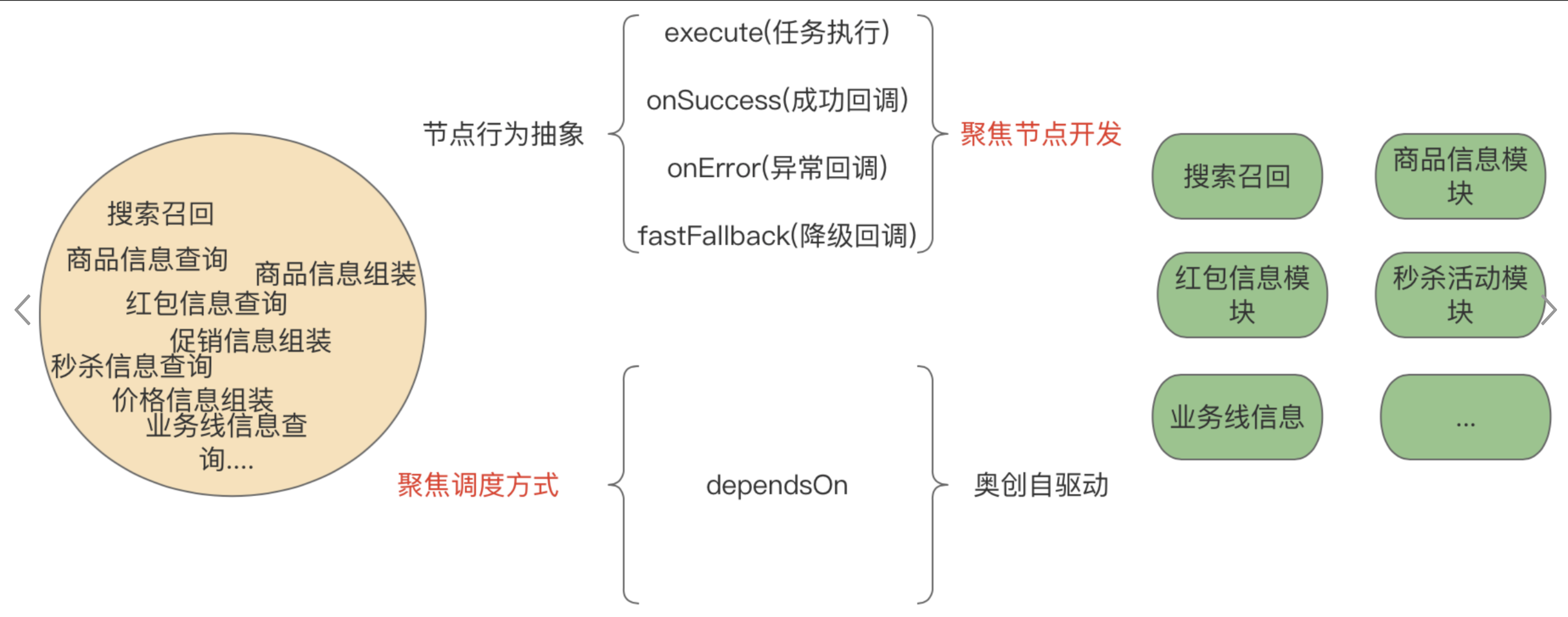
于是,自驱动并发调度模型基于此愿景而诞生,整体设计方向如下:
1,开发模式的聚焦:实现面向节点行为的开发方式
2,框架能力的聚焦:框架聚焦于任意两点之间的连线能力,从而实现全图的自动编织。
五、结语
本文的讲述侧重于并发调度模型演进的思考过程,讲述了基于对问题的理解再理解的探索过程去寻找当前最佳解决方案的思路,也是转转公司复仇者联盟技术生态系列之奥创组件的由来。
关于作者
陈奇恩,转转 B2C 业务供应链后端负责人。
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。
关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~