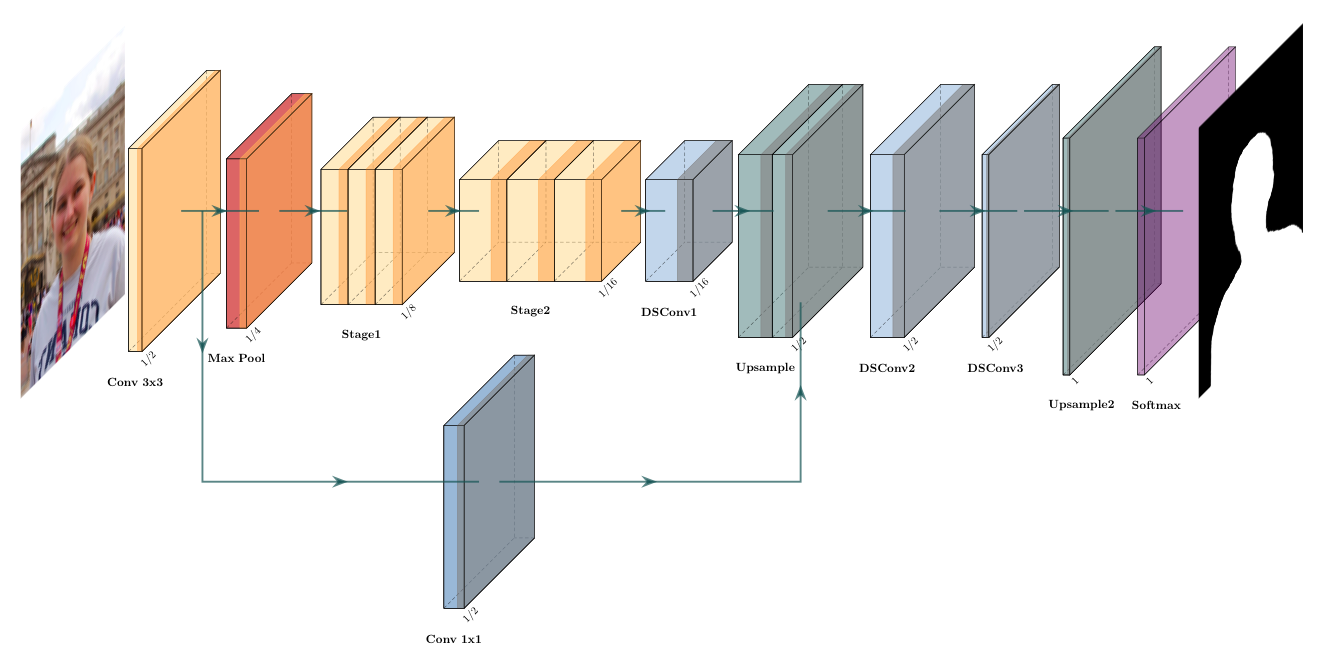
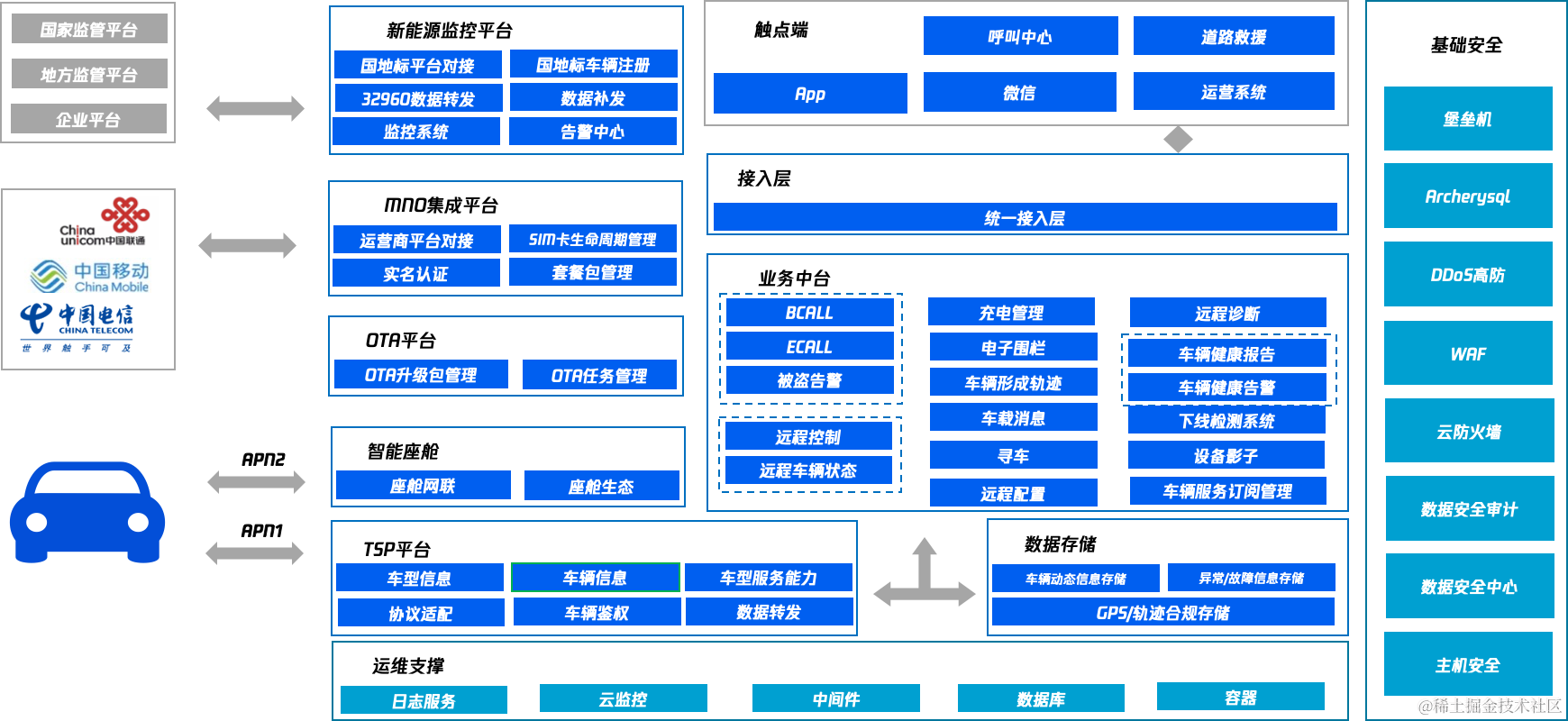
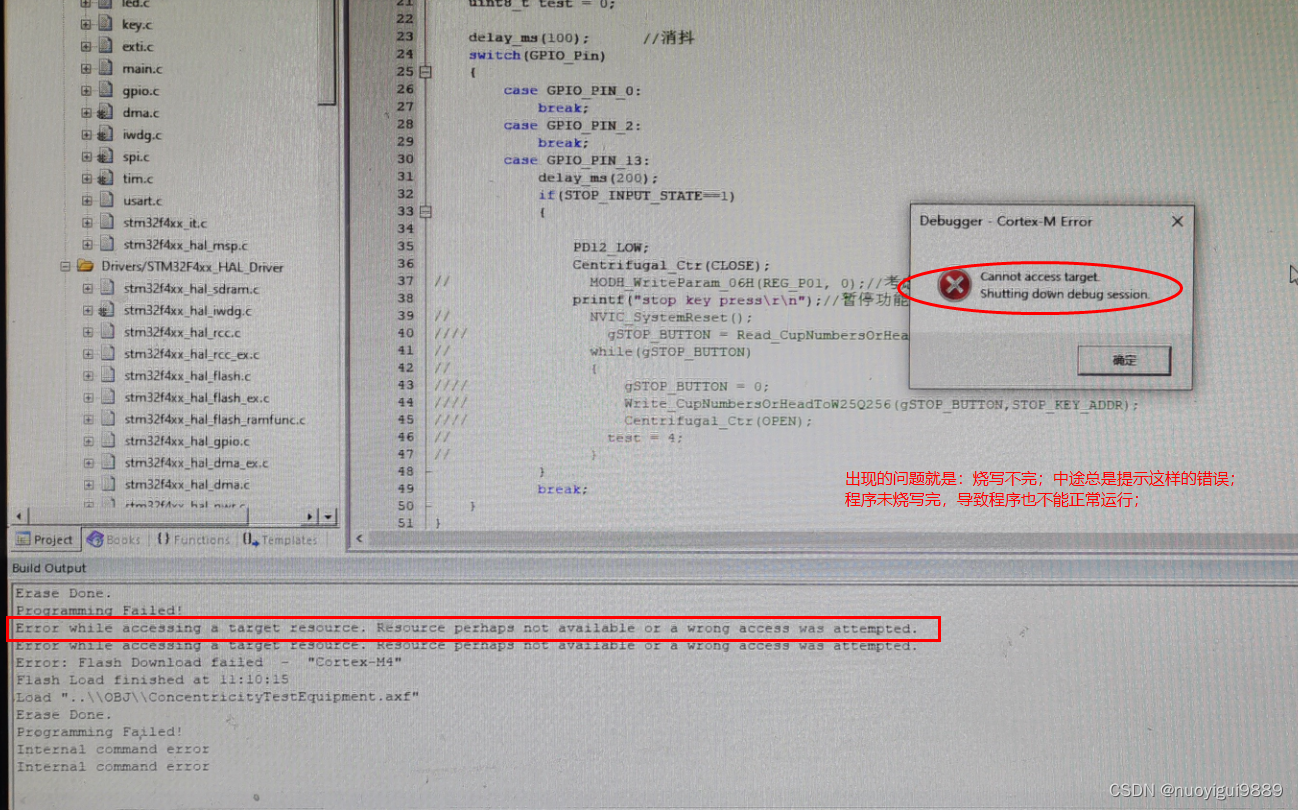
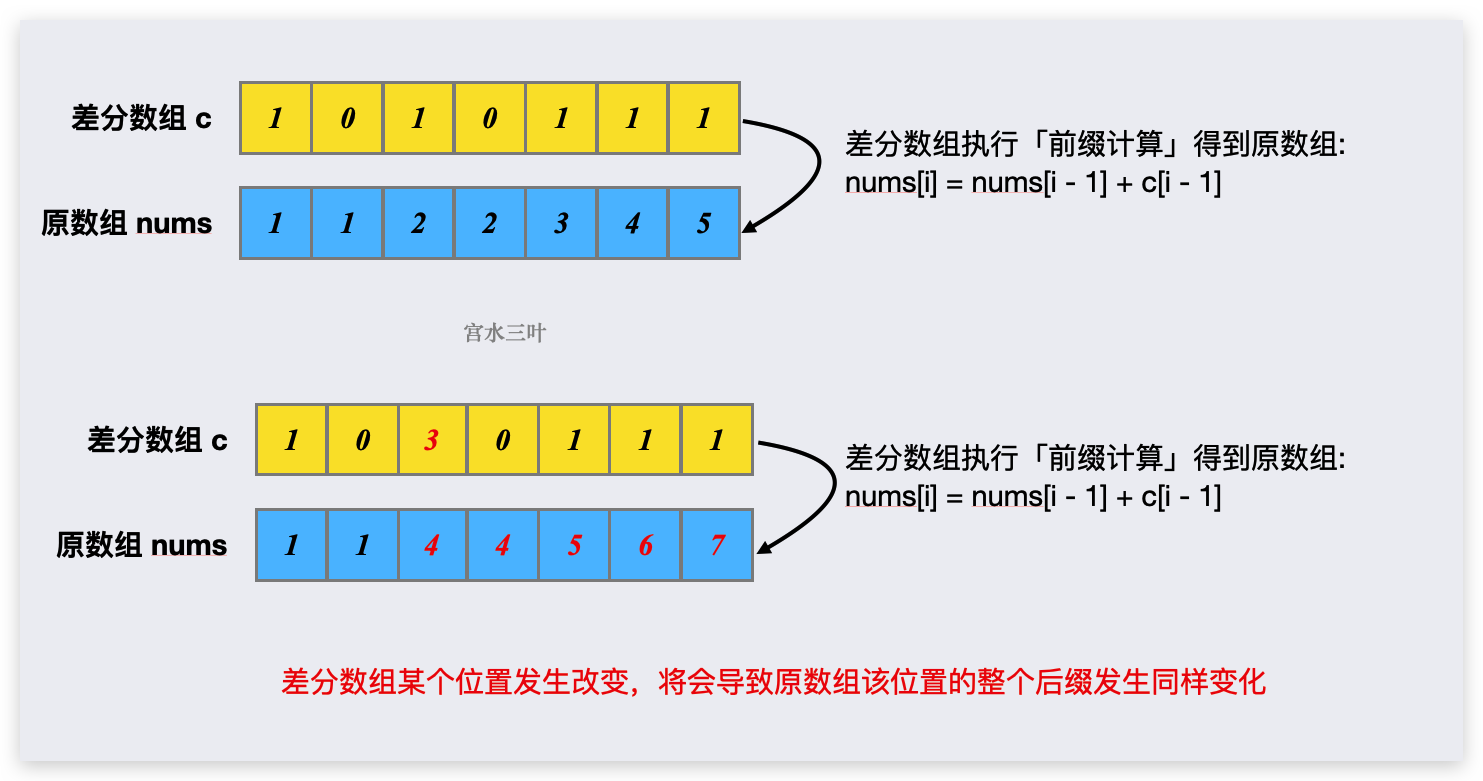
两种方式:
验证码识别技术 (很难达到100%)
添加Cookie (*****五星推荐)
方式一:验证码识别技术
逻辑方式:
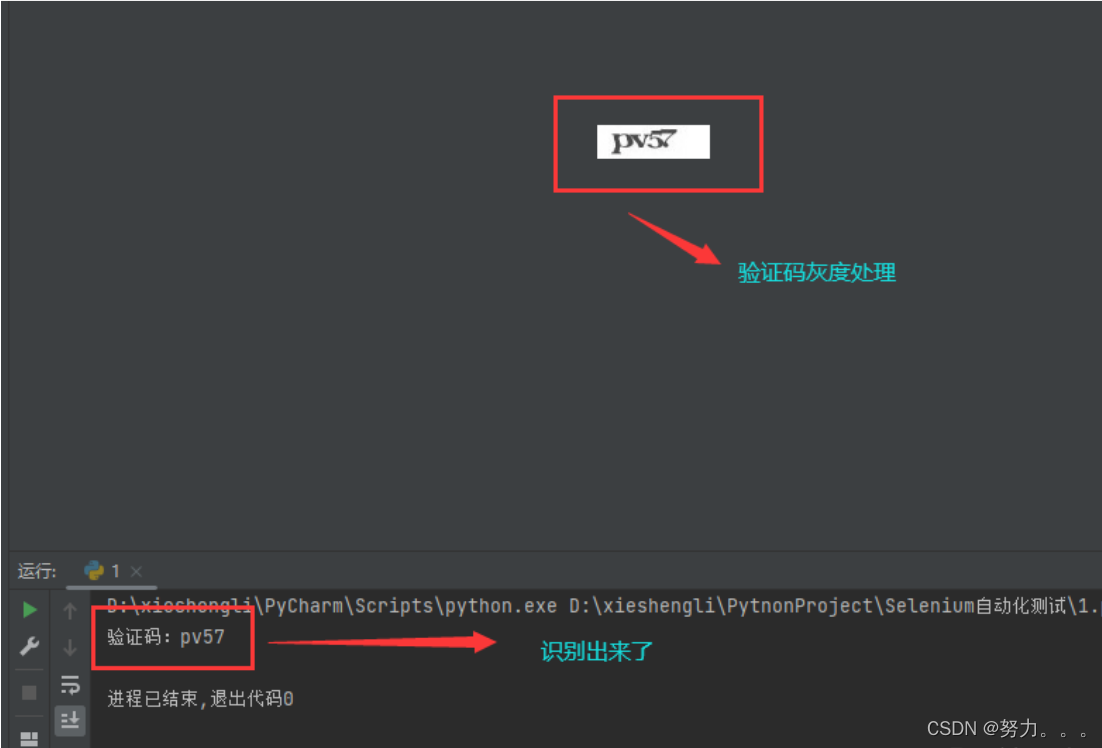
1:打开验证码所在页面,截图。获取验证码元素坐标,剪切出验证码图片,识别
以途牛为例 代码:
from PIL import Image # 用户打开图片和对图片处理
from selenium import webdriver
from selenium.webdriver.common.by import By
import ddddocr
driver = webdriver.Chrome()
# 打开登录页面
driver.get("https://passport.tuniu.com/login?origin=https://www.tuniu.com/ssoConnect")
driver.implicitly_wait(30) # 隐式等待30s
driver.save_screenshot("./image/页面截图.png") # 全屏截图
page_snap_obj = Image.open("./image/页面截图.png") # 打开图片
# 获取验证码元素
img = driver.find_element(By.XPATH, '//*[@id="line_3"]/td/div/div[3]/a[1]/img')
location = img.location # location属性可以返回该图片对象(既这张图片)在浏览器中的位置,以字典的形式返回
size = img.size # 获取图验证码的宽x高
left = location['x'] # 此处的x和y是图片验证码左上角的点再浏览器中的x轴y轴对应的值
top = location['y']
right = left + size['width']
bottom = top + size['height']
# 按照提供的图片验证码的左上右下的坐标值对图片验证码进行裁剪
image_obj = page_snap_obj.crop((left, top, right, bottom))
# 把图片强制转成RGB
img = image_obj.convert("RGB")
img = img.convert("L")
# 保存处理过后的验证码图片
img.save("./image/code_image.png")
# 进行验证码识别
ocr = ddddocr.DdddOcr()
with open('./image/code_image.png', 'rb') as f:
img_bytes = f.read()
# 识别后的验证码
res = ocr.classification(img_bytes)
print("验证码:" + res)
# 获取验证码输入框,输入验证码
# driver.find_element(By.XPATH, '//*[@id="identify"]').send_keys(res)
# time.sleep(5)
driver.quit()
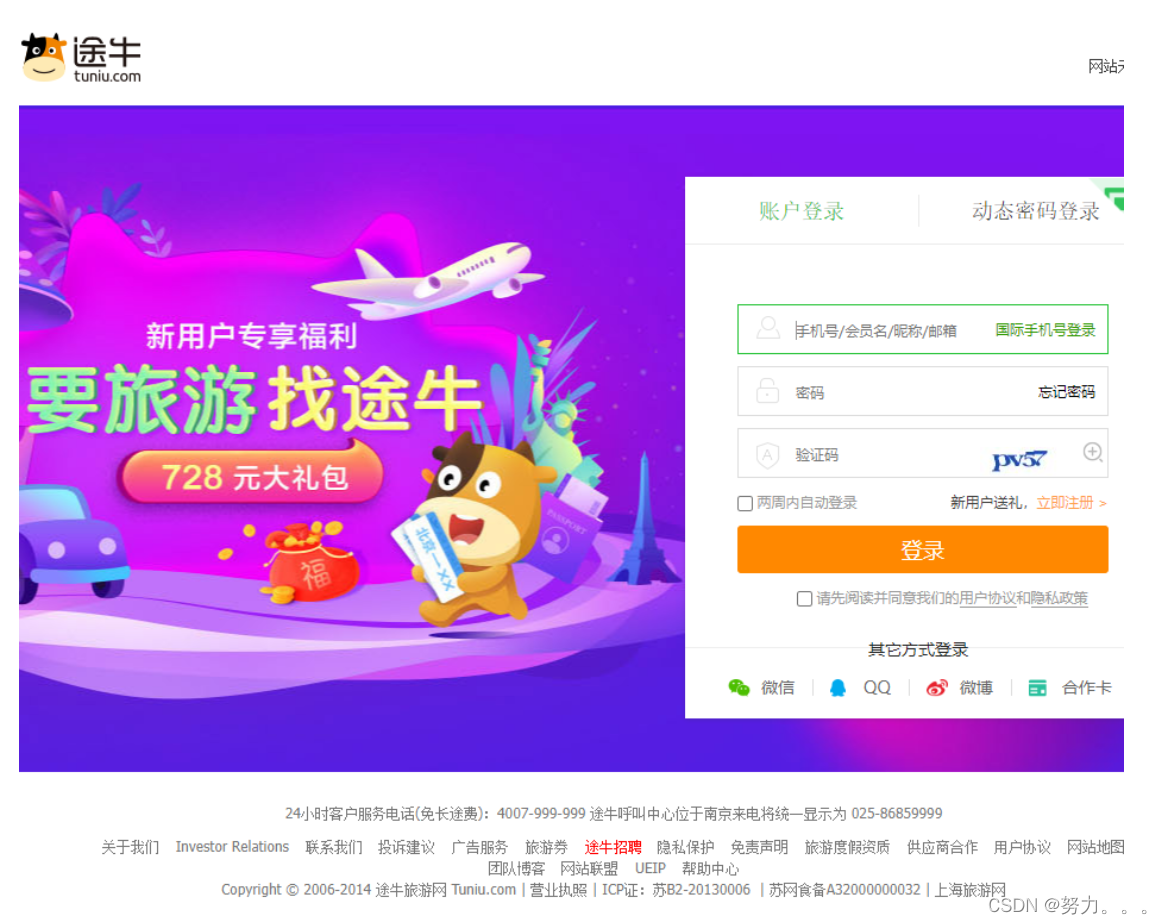
方式二:添加Cookie 以百度为例:
步骤:
1:获取指定cookie: get_cookie(cookie名)
2:获取本网站所有本地cookies: get_cookies()
3:添加cookie:add_cookie({字典对象})
百度cookie获取:
先F12打开网络工作台,再登录抓包
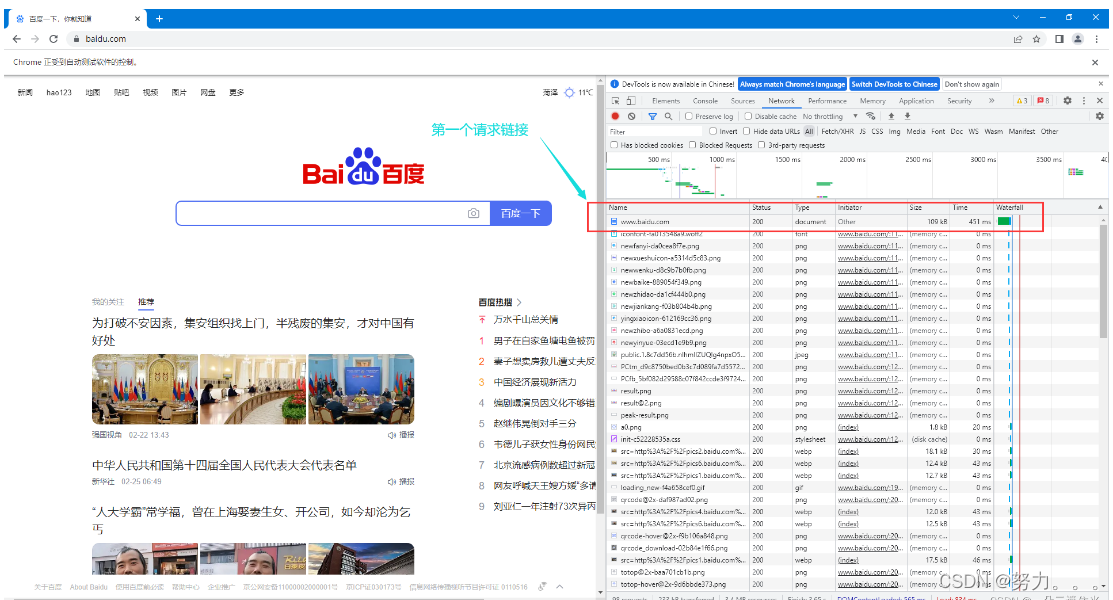
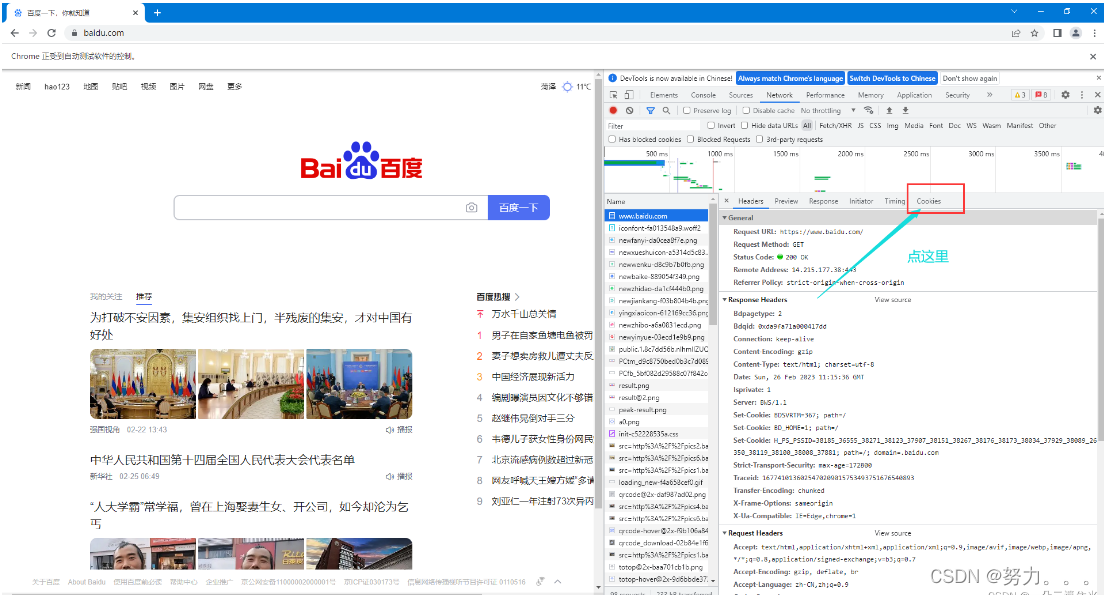
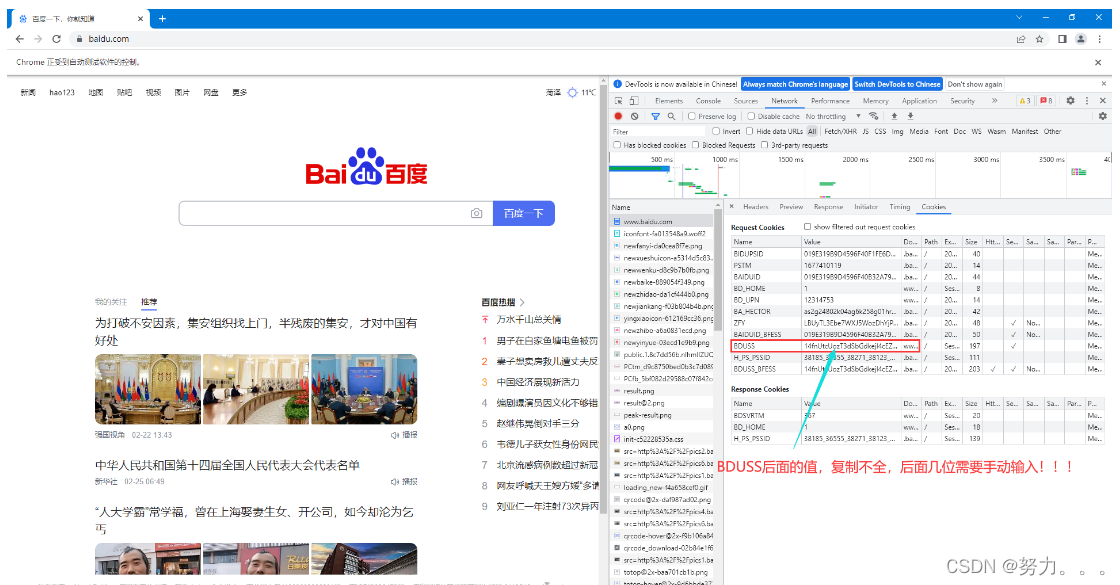
这一步就拿到百度cookie了,代码:
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(30)
driver.get("https://www.baidu.com")
sleep(3)
driver.add_cookie({"name": "BDUSS", "value": "你的BUDSS的值"}) # 登录百度时,抓包获取
print(driver.get_cookie("BDUSS"))
driver.refresh()
sleep(5)
driver.quit()