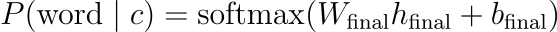基础组件——Tokenizer


(1)模型加载
from transformers import AutoTokenizer
sen = "弱小的我也有大梦想!"
# 从HuggingFace加载,输入模型名称,即可加载对于的分词器
tokenizer = AutoTokenizer.from_pretrained("model/robert-base-chinese-extractive-qa")
tokenizer
BertTokenizerFast(name_or_path='model/robert-base-chinese-extractive-qa', vocab_size=21128, model_max_length=512, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
保存到本地
# tokenizer 保存到本地
tokenizer.save_pretrained("./roberta_tokenizer")
('./roberta_tokenizer/tokenizer_config.json',
'./roberta_tokenizer/special_tokens_map.json',
'./roberta_tokenizer/vocab.txt',
'./roberta_tokenizer/added_tokens.json',
'./roberta_tokenizer/tokenizer.json')
加载本地中保存的tokenizer
# 从本地加载tokenizer
tokenizer = AutoTokenizer.from_pretrained("./roberta_tokenizer/")
tokenizer
BertTokenizerFast(name_or_path='./roberta_tokenizer/', vocab_size=21128, model_max_length=512, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
(2)句子分词
# 会将之前输入的文本,拆分成字典中对应的字词
tokens = tokenizer.tokenize(sen) # 将sen输入给tokenizer
tokens # 如果词表中没有对应的词,就会变成[UNK]
['弱', '小', '的', '我', '也', '有', '大', '梦', '想', '!']
(3)查看字典
tokenizer.vocab
{'##曄': 16334,
'##絡': 18238,
'##啼': 14639,
'瞬': 4746,
'##推': 16029,
'##蔥': 18977,
'沂': 3752,
'嘘': 1656,
'苜': 5730,
'##即': 14372,
'徉': 2524,
'carlo': 12628,
'##歙': 16686,
'飛': 7606,
'##ᵘ': 13495,
'##蜊': 19106,
'##85': 9169,
'##页': 20609,
'##ved': 11667,
'lonzo': 12688,
'旋': 3181,
'##count': 12369,
'狼': 4331,
'次': 3613,
'话': 6413,
...
'1936': 9481,
'小': 2207,
'宜': 2139,
'##獄': 17409,
...}
查看词表大小
# 查看词表大小
tokenizer.vocab_size
21128
(4)索引转换
# 将词序列转换为id序列
ids = tokenizer.convert_tokens_to_ids(tokens)
ids
[2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106]
转换成token
# 将id序列转换为token序列
tokens = tokenizer.convert_ids_to_tokens(ids)
tokens
转换为string
# 将token序列转换为string
str_sen = tokenizer.convert_tokens_to_string(tokens)
str_sen
简洁的一步实现方式:
# 将字符串转换为id序列,又称之为编码
ids = tokenizer.encode(sen, add_special_tokens=True) # add_special_tokens=False时候,不显示加入标签后的id
ids # 这个id和之前的id前后分别多了一个101和102,是因为BERT在句子前后加了标志标签
[101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102]
解码
# 将id序列转换为字符串,又称之为解码
str_sen = tokenizer.decode(ids, skip_special_tokens=False)
str_sen
'[CLS] 弱 小 的 我 也 有 大 梦 想! [SEP]'
(5)填充与截断
# 填充
ids = tokenizer.encode(sen, padding="max_length", max_length=15) # 填充到最大长度15
ids
[101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0]
# 截断
ids = tokenizer.encode(sen, max_length=5, truncation=True)
ids # 保留了头尾标签和从前到后的三个词
[101, 2483, 2207, 4638, 102]
(6)其他输入部分
# 先重新进行填充
ids = tokenizer.encode(sen, padding="max_length", max_length=15)
ids
[101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0]
# attention_mask:标记哪些部分是真实输入,哪些部分是填充
attention_mask = [1 if idx != 0 else 0 for idx in ids] # tokenizer中不为0时候,将其记录为1,标记为真实填充
# token_type_ids:用来区别哪个部分是第一个句子,哪个部分是第二个句子
token_type_ids = [0] * len(ids)
ids, attention_mask, token_type_ids
([101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
* 使用函数,直接快速调用
inputs = tokenizer.encode_plus(sen, padding="max_length", max_length=15) # 直接调用库实现上面功能
inputs
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]}
inputs = tokenizer(sen, padding="max_length", max_length=15) # 直接调用tokenizer结果也一样
inputs
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]}
(7)处理batch数据
sens = ["弱小的我也有大梦想",
"有梦想谁都了不起",
"追逐梦想的心,比梦想本身,更可贵"]
res = tokenizer(sens)
res
{'input_ids': [[101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 102], [101, 3300, 3457, 2682, 6443, 6963, 749, 679, 6629, 102], [101, 6841, 6852, 3457, 2682, 4638, 2552, 8024, 3683, 3457, 2682, 3315, 6716, 8024, 3291, 1377, 6586, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
测试循环耗时
%%time
# 该指令可计算cell的处理时间
# 单条循环处理
for i in range(1000):
tokenizer(sen)
CPU times: user 117 ms, sys: 0 ns, total: 117 ms
Wall time: 258 ms
测试矩阵运算耗时
%%time
# 处理batch数据
res = tokenizer([sen] * 1000) # 数据只需要进行tokenizer的时候,以batch方式去处理,速度最快
CPU times: user 90 ms, sys: 20.3 ms, total: 110 ms
Wall time: 30.2 ms
可以发现采用矩阵运算花费事件远小于循环事件
tokenizer
BertTokenizerFast(name_or_path='./roberta_tokenizer/', vocab_size=21128, model_max_length=512, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
* Fast/slow Tokenizer组件

默认加载
sen = "弱小的我也有大Dreaming!"
# 默认方式创建下,为fast,即use_fast=True
fast_tokenizer = AutoTokenizer.from_pretrained("/u01/zhanggaoke/project/transformers-code-master/model/roberta-base-finetuned-dianping-chinese")
fast_tokenizer
DistilBertTokenizerFast(name_or_path='/u01/zhanggaoke/project/transformers-code-master/model/roberta-base-finetuned-dianping-chinese', vocab_size=30522, model_max_length=512, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
加载use_fast=False
slow_tokenizer = AutoTokenizer.from_pretrained("/u01/zhanggaoke/project/transformers-code-master/model/roberta-base-finetuned-dianping-chinese", use_fast=False)
slow_tokenizer
DistilBertTokenizer(name_or_path='/u01/zhanggaoke/project/transformers-code-master/model/roberta-base-finetuned-dianping-chinese', vocab_size=30522, model_max_length=512, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
处理时间对比
%%time
# 单条循环处理
for i in range(10000):
fast_tokenizer(sen)
CPU times: user 729 ms, sys: 11 ms, total: 740 ms
Wall time: 774 ms
%%time
# 单条循环处理
for i in range(10000):
slow_tokenizer(sen)
# 可以发现slow的方法比fast慢的多
CPU times: user 1.74 s, sys: 0 ns, total: 1.74 s
Wall time: 1.75 s
批处理测试
%%time
# 处理batch数据
res = fast_tokenizer([sen] * 10000)
CPU times: user 1.91 s, sys: 195 ms, total: 2.11 s
Wall time: 319 ms
%%time
# 处理batch数据
res = slow_tokenizer([sen] * 10000)
CPU times: user 1.44 s, sys: 15.6 ms, total: 1.46 s
Wall time: 1.45 s
fast_tokenizer中专用的分词方式
# fast中offset_mapping,其中(0, 0)为首尾标记
inputs = fast_tokenizer(sen, return_offsets_mapping=True)
inputs
{'input_ids': [101, 100, 1829, 1916, 1855, 1750, 1873, 1810, 12802, 999, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'offset_mapping': [(0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 15), (15, 16), (0, 0)]}
# 将词token去id化,其中None为首尾标记
inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 8, None]
* 远程加载
from transformers import AutoTokenizer
# 当我们想要加载chatglm-6b远程代码库里的分词器时候,需要设置trust_remote_code=True
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
tokenizer.save_pretrained("chatglm_tokenizer")
tokenizer = AutoTokenizer.from_pretrained("chatglm_tokenizer", trust_remote_code=True)
tokenizer.decode(tokenizer.encode(sen))
'弱小的我也有大Dreaming!'