浅谈 C++ 字符串:std::string 与它的替身们
文章目录
- 浅谈 C++ 字符串:std::string 与它的替身们
- 零、前言
- 一、前辈:C 风格的字符串
- 1.1 什么是 C 风格的字符串
- 1.2 C 风格的字符串有什么缺陷
- 1.2.1 以 '\0' 作为结尾,没有直接指明长度
- 1.2.2 相关 API 设计糟糕
- 1.2.3 缺乏内存管理
- 1.2.4 线程安全问题
- 1.3 如何改进 C 风格的字符串或避免危险
- 二、标准库:std::string
- 2.1 什么是 std::string
- 2.2 std::string 的实现方式
- 2.2.1 eager copy 无特殊处理
- 2.2.2 COW 写时复制
- 2.2.3 SSO 短字符串优化
- 2.3 std::string 的优点
- 2.4 std::string 有什么缺陷
- 三、替身们
- 3.1 FBstring
- 3.1.1 什么是 FBstring
- 3.2.2 FBstring 有什么优势
- 3.2 StringPiece 与 std::string_view
- 3.2.1 什么是 StringPiece
- 3.2.2 StringPiece 有什么优势
- 四、总结
- 五、参考资料
零、前言
本文浅谈了 C++ 字符串的相关概念,侧重讨论了其实现机制、优缺点等方面,对于如何使用 C++ string,建议读者通过阅读其他文章学习了解。
期间参阅了很多优秀博客,具体参考文章在末尾和相应部分均有列出,强烈推荐看看
一、前辈:C 风格的字符串
该部分参阅了这两篇博客:
C的字符串有哪些问题
C风格字符串缺陷及改进
函数式编程 (用 PPT 例子介绍了停机问题)
1.1 什么是 C 风格的字符串
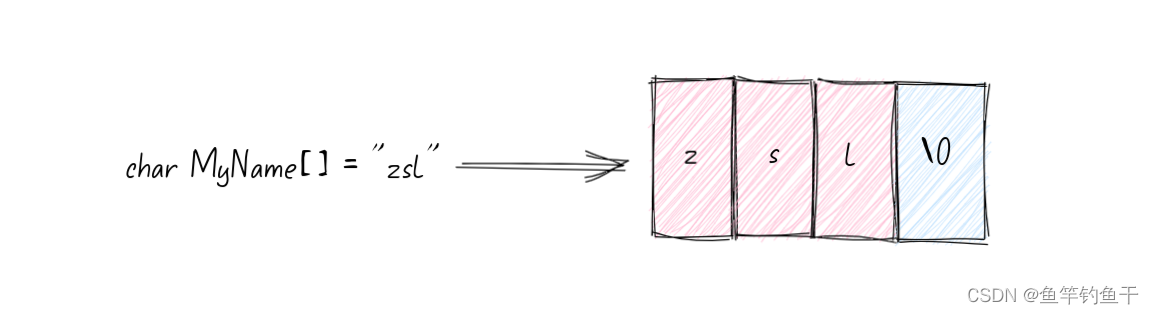
C 语言实际并不存在所谓的字符串类型,而是把以’\0’ 结尾的字符数组当作字符串
char notstring[8] = {'n','o','t',' ','s','t','r','i','n','g'}; // 不是字符串
char istring[8] = {'i','s',' ','s','t','r','i','n','g','\0'}; // 是字符串
char MyID[11] = "FishingRod"; // 结尾自动包含\0
char MyName[] = "zsl"; // 让编译器自动计数
1.2 C 风格的字符串有什么缺陷
C 风格的字符串缺陷主要有以下几点
- 以 ‘\0’ 作为结尾,没有直接指明长度
- 相关 API 设计糟糕
- 缺乏内存管理
- 线程安全问题
1.2.1 以 ‘\0’ 作为结尾,没有直接指明长度
难以校验字符串正确性
校验 C 风格字符串正确性近乎可以等价于解决停机问题。下面简单介绍以下停机问题,便能认识到其中相似之处。
停机问题:给定任意一个程序及其输入,判断该程序是否能够在有限次计算以内结束。
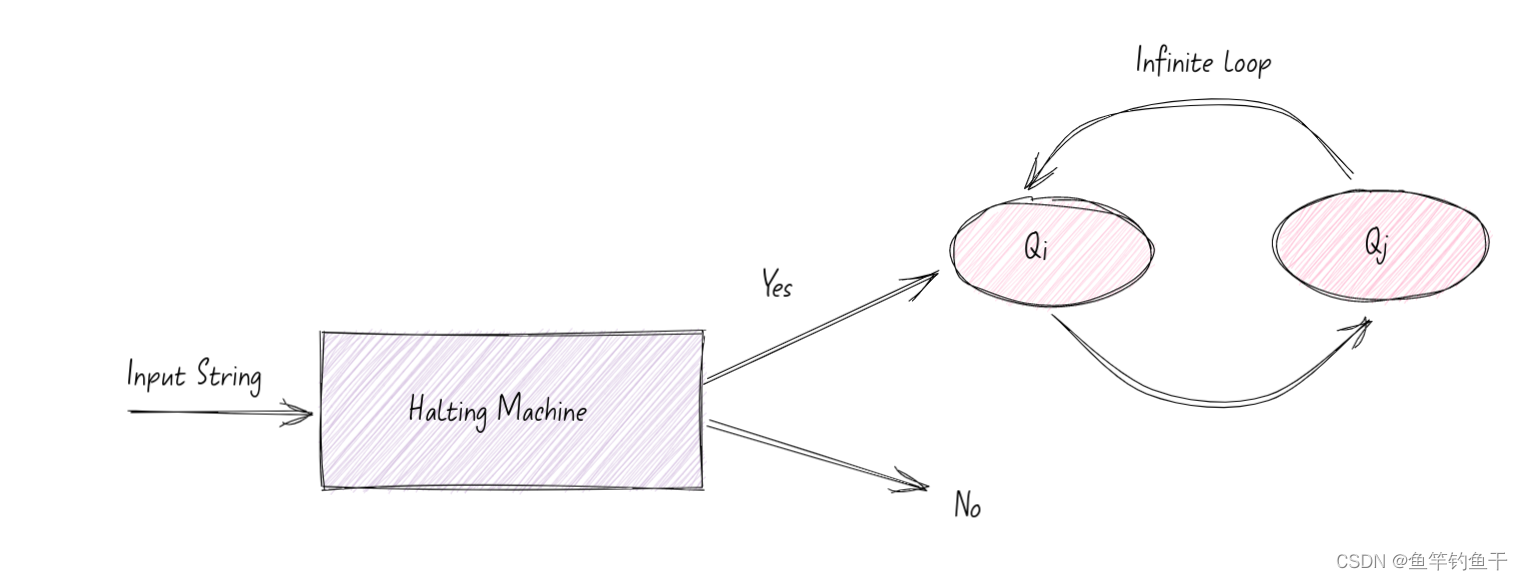
假设停机问题有解,那么我们就可以发明一个自动检查程序里面有没有死循环的工具了!我们给它任意一个函数和这个函数的输入,就能告诉你这个函数会不会运行结束。
我们用下列伪代码描述
function halting(func, input) {
return if_func_will_halt_on_input;
}
接下来充分利用停机判定,构造另一函数
function myfunc(func) {
if(halting(func, func)) {
for(;;) // 死循环
}
}
接下来调用
myfunc(myfunc)
函数 myfunc 以 myfunc 为输入时,停机还是不停机呢?出现悖论了!
所以停机问题不可判定。类似的,如果你要去判断 C 风格的字符串是否正确,唯一的方法即使遍历它并判断循环是否终止。任何处理无效 C 风格字符串的循环都是死循环(或导致缓冲区溢出)。
取得字符串长度的操作时间复杂度为 O ( N ) O(N) O(N),它本可以是 O ( 1 ) O(1) O(1)。
由于以 ‘\0’ 作为结束标志,所以想要获取字符串长度就要遍历整个字符串,这导致 strlen() 函数的时间复杂度为
O
(
N
)
O(N)
O(N) 而不是
O
(
1
)
O(1)
O(1) ,在下面的代码例子中是刚学 C 语言的时候容易犯下的错误,在循环中使用 strlen() 作为判定条件,导致时间复杂度由预期的
O
(
N
)
O(N)
O(N) 变为
O
(
N
2
)
O(N^2)
O(N2)
#include <string.h>
#include <stdio.h>
int main() {
char str[] = "abcde";
int len = strlen(str); // O(N)
for(int i = 0; i < strlen(str); ++i) { // O(N^2)
printf("%c", str[i]);
}
for(int i = 0; i < len; ++i) { // O(N)
printf("%c", str[i]);
}
}
1.2.2 相关 API 设计糟糕
可以发现 C 风格字符串的相关操作 API 并不是那么优雅,存在着缺少错误检查、缓冲区溢出、没考虑传入 NULL 等等问题。其中很大一部分原因是因为这些函数并非标准化下共同努力的结果,而是诸多程序员各自贡献积累起来的。等到 C 标准化开始的时候,“修整”他们已经太晚了,太多的程序对函数的行为已经有了明确的定义。下面作简单列举,具体可以参看这两篇博客中的说明:C的字符串有哪些问题、C风格字符串缺陷及改进
- gets() 的使用会将应用暴露在缓冲区溢出的问题之下。
- strtok() 会修改它解析的字符串,因此,它在要求可重入和多线程的程序中可能不可用。
- fgets 有着“忽视”出现在在换行符 ‘\n’ 出现之前的空字符 ‘\0’ 的奇怪语义。
- 在某些情况下, strncpy() 不会将目标字符串以 ‘\0’ 结尾。
- 将 NULL 传给 C 库中的字符串函数会导致未定义的空指针访问。
- 参数混叠(parameter aliasing) (重叠,或称为自引用)在大多数 C 库函数中都是未定义行为。
- 许多 C 库字符串函数都带有受限范围的整数参数。传递超出这些范围的整数的行为不会被检测到,并会造成未定义行为。
1.2.3 缺乏内存管理
C 风格的字符串缺乏内存管理,对于长度固定或长度范围确定的字符串来说,可以使用固定长度的字节数组来存储。但是如果需要动态改变字符串长度时,就需要手动的申请和释放内存块,增加了心智负担,容易造成缓冲区溢出等内存管理问题。
1.2.4 线程安全问题
由于 C 语言出生的时候还没有多线程这些东西,所以对字符串进行修改的相关函数大多不具备线程安全性。
1.3 如何改进 C 风格的字符串或避免危险
- 给字符串加上长度
- 添加简单的内存管理功能
- 仔细阅读参考手册
- 弃用危险的 API
- 使用更加安全的字符串函数库
当然,如果没有硬性规定只能使用纯 C 语言编程,你也可以考虑使用 C++ 提供的 std::string。
二、标准库:std::string
2.1 什么是 std::string
C++ 内置了 std::string 类,这大大增强了对字符串的支持,处理起字符串来更加方便了。std::string 一定程度上可以替代 C 风格的字符串。
#include <string>
#include <iostream>
int main() {
std::string s1 = "std::string";
std::string s2 = "not C string";
std::cout << s1 << " " << s2 << std::endl;
std::cout << "s1 size = " << s1.size() << std::endl;
std::cout << "s1 length = " << s1.length() << std::endl;
std::cout << "s1 + s2 = " << s1 + s2 << std::endl;
for(int i = 0; i < s1.size(); ++i) {
std::cout << s1[i] << " ";
}
const char* Cstring = s1.c_str();
return 0;
}
2.2 std::string 的实现方式
这一部分参阅了下面几篇博客/书籍
漫谈C++ string(1):std::string实现
C++ folly库解读(一) Fbstring —— 一个完美替代std::string的库
深入剖析 linux GCC 4.4 的 STL string
Linux 多线程服务端编程 陈硕
C++标准库中string的三种底层实现方式
std::string的Copy-on-Write:不如想象中美好
通过查看 gcc 源代码 gcc-12.2.0 <string.h> 可以发现 string 实际上是 basic_string 模板的 char 版本特化。
namespace pmr {
template<typename _Tp> class polymorphic_allocator;
template<typename _CharT, typename _Traits = char_traits<_CharT>>
using basic_string = std::basic_string<_CharT, _Traits,
polymorphic_allocator<_CharT>>;
using string = basic_string<char>; // Here!!!
#ifdef _GLIBCXX_USE_CHAR8_T
using u8string = basic_string<char8_t>;
#endif
using u16string = basic_string<char16_t>;
using u32string = basic_string<char32_t>;
using wstring = basic_string<wchar_t>;
} // namespace pmr
关于basic_string 的具体实现,各版本存在差异,下面介绍 3 种常见的实现方式
- eager copy
- COW
- SSO
2.2.1 eager copy 无特殊处理
eager copy 非常朴素,没有什么特殊处理,采用类似 std::vector 的数据结构。现在很少有实现采用这种方式。
eager copy 采用深拷贝,在每次拷贝时将原 string 对应的内存以及所持有的动态资源完整地复制一份,没有任何特殊处理。这导致在需要对字符串进行频繁复制而又并不改变字符串内容时效率很低
// sgi-stl
class string {
public:
const_pointer data() const { return start; }
iterator begin() { return start; }
iterator end() { return finish; }
size_type size() const { return finish - start; }
size_type capacity() const { return end_of_storage - start; }
private:
char* start;
char* finish;
char* end_of_storage;
}
当然也有其他实现 eager copy 的方式,在此不做详述,感兴趣的读者可以阅读 Linux 多线程服务端编程 陈硕 这本书中 《12.7 再探 std::string》 这一章节。
下面给出这一实现的简单图示
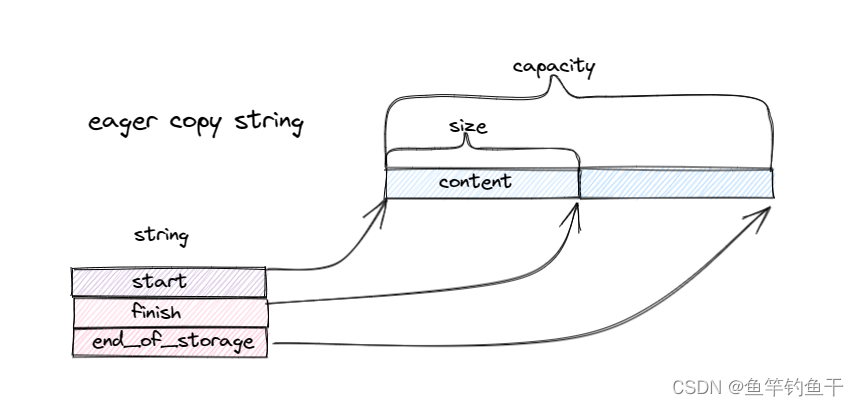
优点:
- 实现简单
- 每个对象互相独立,不用考虑那么多乱七八糟的场景。
缺点:
- 字符串较大时,拷贝浪费空间。
2.2.2 COW 写时复制
只有在某个 string 要对共享对象进行修改时,才会真正执行拷贝。
由于存在共享机制,所以需要一个std::atomic<size_t>,代表被多少对象共享。
class cow_string // libstdc++-v3
{
struct Rep
{
size_t size;
size_t capacity;
size_t refcount; // 引用计数应当是原子的
char* data[1]; // variable length
};
char* start;
}
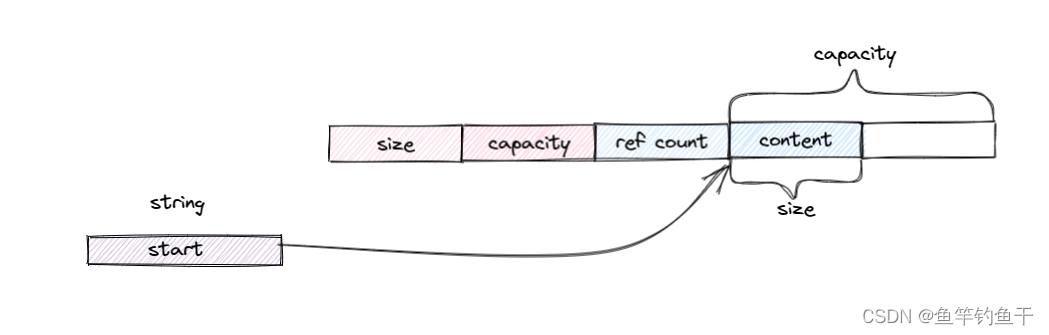
为了方便验证,采用了 Compiler Explorer x86-64 gcc 4.6.4 的编译器,下面通过打印字符串的地址验证 COW 机制
// https://godbolt.org/z/zzaTvjzG9 可以通过这个链接在线查看结果
#include <iostream>
#include <string>
using namespace std;
int main () {
string a = "abcd" ;
string b = a ;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "b.data() =" << (void *)b. data() << endl ;
cout << endl;
string c = a ;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "b.data() =" << (void *)b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
cout << endl;
c[3] = 'e';
cout << "after write:" << endl;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "b.data() =" << (void *)b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
return 0;
}
输出结果为
// gcc 4.6.4
a.data() =0xbe02b8
b.data() =0xbe02b8
a.data() =0xbe02b8
b.data() =0xbe02b8
c.data() =0xbe02b8
after write:
a.data() =0xbe02b8
b.data() =0xbe02b8
c.data() =0xbe12f8
可以发现在 c 修改之前,它的地址与拷贝的 a 的地址是一样的,在修改之后就发生了变化。下面用两幅图简单说明这两个情况。
拷贝但不修改
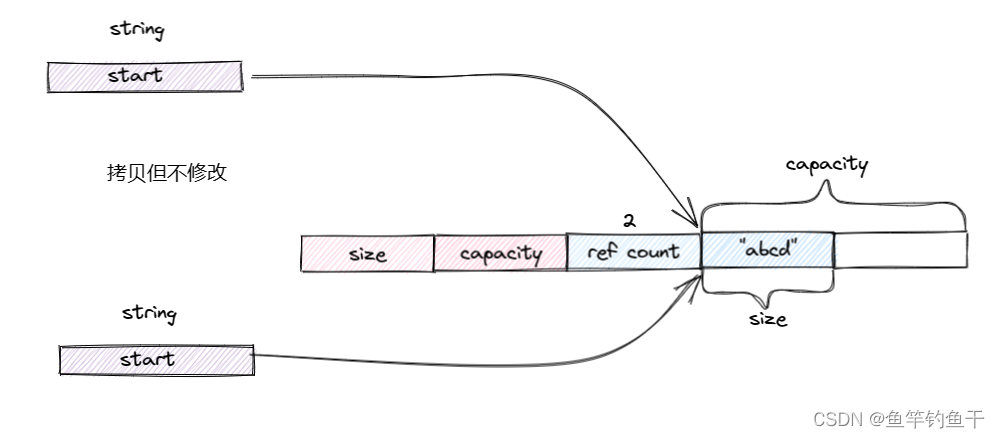
拷贝并且修改
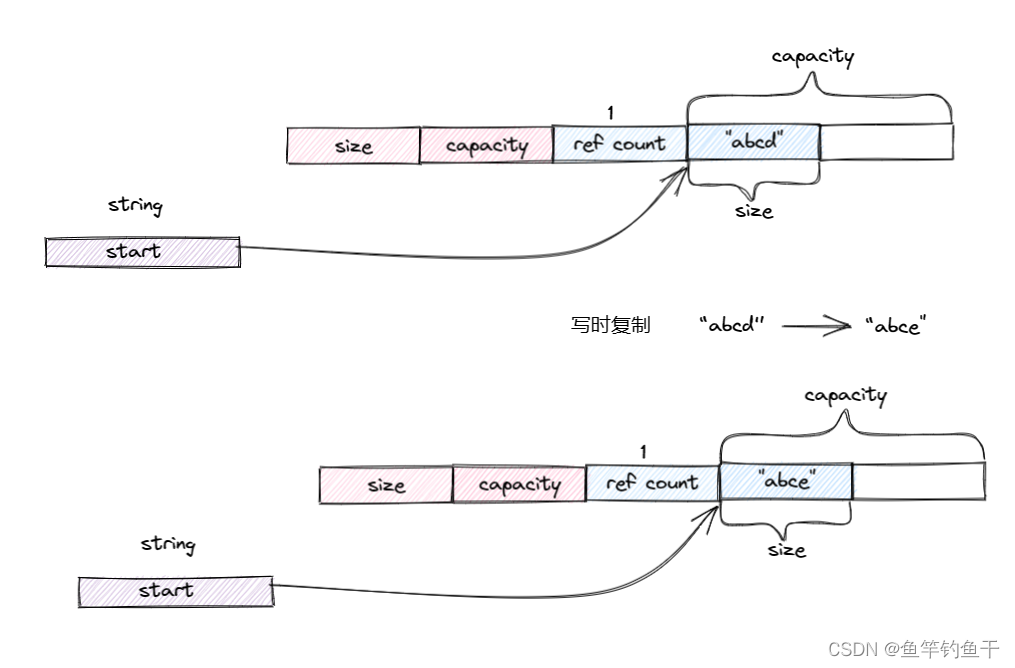
通过查看 gcc 变更文档,可以发现 gcc 在 5.1 版本将 std::string 的实现由 COW 改为下面要讲的 SSO 即短字符串优化。

下面时 gcc 5.1 版本下的编译结果
// https://godbolt.org/z/jGj6GjrdG
// gcc 5.1
a.data() =0x7ffd606a0dc0
b.data() =0x7ffd606a0da0
a.data() =0x7ffd606a0dc0
b.data() =0x7ffd606a0da0
c.data() =0x7ffd606a0d80
after write:
a.data() =0x7ffd606a0dc0
b.data() =0x7ffd606a0da0
c.data() =0x7ffd606a0d80
另外,在文章 深入剖析 linux GCC 4.4 的 STL string 中还通过 gdb debug 来查看引用计数来验证 COW ,并将 strncpy 和 std::string copy 做了简单的性能对比,发现对于单纯的拷贝场景来说,COW 确实达到了预期的效果,并且字符串越大效果越明显。
然而 COW 有一个严重的问题就是没有区分下标运算符的读操作和写操作
// https://godbolt.org/z/oarz1sn14
#include <iostream>
#include <string>
using namespace std;
int main () {
string a = "abcd" ;
string const_b = a ;
string c = a ;
string d = a;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "const_b.data() =" << (void *)const_b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
cout << "d.data() =" << (void *)d. data() << endl ;
cout << endl;
cout << "read const_b[0] = " << const_b[0] << endl;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "const_b.data() =" << (void *)const_b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
cout << "d.data() =" << (void *)d. data() << endl ;
cout << endl;
cout << "read c[0] = " << c[0] << endl;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "const_b.data() =" << (void *)const_b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
cout << "d.data() =" << (void *)d. data() << endl ;
cout << endl;
d[0] = '1';
cout << "write d[0] = '1'" << endl;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "const_b.data() =" << (void *)const_b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
cout << "d.data() =" << (void *)d. data() << endl ;
return 0;
}
结果如下
a.data() =0x14122b8
const_b.data() =0x14122b8
c.data() =0x14122b8
d.data() =0x14122b8
read const_b[0] = a
a.data() =0x14122b8
const_b.data() =0x14132f8
c.data() =0x14122b8
d.data() =0x14122b8
read c[0] = a
a.data() =0x14122b8
const_b.data() =0x14132f8
c.data() =0x1413328
d.data() =0x14122b8
write d[0] = '1'
a.data() =0x14122b8
const_b.data() =0x14132f8
c.data() =0x1413328
d.data() =0x1413358
可以发现,即使只是通过[]运算符去读取对应位置的值也会引发拷贝,这就可能导致意外开销。
另一方面,COW 对多线程并不友好,虽然 C++ 并没有要求多线程操作同一个字符串时的线程安全,但当多线程操作几个独立的字符串时,应当是安全的。
为了保证这点,COW 通过以下两点来实现
-
只对引用计数进行原子增减
-
需要修改时,先分配和复制,后将引用计数-1(当引用计数为0时负责销毁)
虽然使用原子操作相较直接使用 mutex 的开销要小很多但仍然会带来一定的性能损耗
- 系统通常会lock住比目标地址更大的一片区域,影响逻辑上不相关的地址访问。
- lock指令具有”同步“语义,会阻止CPU本身的乱序执行优化。
- 两个CPU对同一个地址进行原子操作,会导致cache bounce(抖动)
就操作顺序而言,先分配后复制再修改的操作顺序,在某些条件下可能会导致多一次内存分配和复制。
具体可以参考 std::string的Copy-on-Write:不如想象中美好 这篇文章做进一步了解
简单总结一下 COW 的优缺点
优点:
- 适用于频繁拷贝但不修改的场景,减少了动态分配内存的开销和复制字符串的开销,并且字符串越大,效果越好
缺点:
- 对多线程并不友好,引用计数需要原子操作和固定的操作顺序,这些会带来额外的开销
- 没有区分下标运算符的读写操作,即使只是用下标运算符进行读操作也有可能引发 COW 导致意外的开销
2.2.3 SSO 短字符串优化
基于大多数字符串都比较短的特点,利用 string 对象本身的栈空间来存储段短字符串。当字符串长度大于某个临界值时,采用 eager copy 的方式
SSO 的实现类似下面的代码,使用 union 来区分长字符串和短字符串,阈值一般为 15 字节。union 的成员共享一段内存,union 大小至少能包含最大的成员(还要对齐)。
如果短字符串,则直接存储在栈上的 buffer 中;如果超过阈值则存储在 char* start 指向的堆空间上
class sso_string // __gun_ext::__sso_string
{
char* start;
size_t size;
static const int kLocalSize = 15;
union
{
char buffer[kLocalSize + 1];
size_t capacity;
} data;
}
我们可以通过重载全局的 operator new 来观察字符串在栈和堆上分配内存的情况
// 可以通过这个链接在线查看并运行代码 https://godbolt.org/z/3nz7Wc188
#include <iostream>
#include <string>
using namespace std;
auto allocated = 0;
// 重载全局 operator new,统计分配的堆内存
void* operator new(size_t size) {
void* p = std::malloc(size);
allocated += size;
return p;
}
void operator delete(void* p) noexcept {
return std::free(p);
}
int main() {
allocated = 0;
auto s1 = std::string("abcde");
std::cout << "stack space = " << sizeof(s1)
<< ", heap space = " << allocated
<< ", capacity = " << s1.capacity()
<< ", size = " << s1.size() << '\n';
allocated = 0;
auto s2 = std::string("0123456789012345");
std::cout << "stack space = " << sizeof(s2)
<< ", heap space = " << allocated
<< ", capacity = " << s2.capacity()
<< ", size = " << s2.size() << '\n';
// 测试一下 capacity 扩容
s2 += "6";
std::cout << "stack space = " << sizeof(s2)
<< ", heap space = " << allocated
<< ", capacity = " << s2.capacity()
<< ", size = " << s2.size() << '\n';
return 0;
}
结果如下
stack space = 32, heap space = 0, capacity = 15, size = 5
stack space = 32, heap space = 17, capacity = 16, size = 16
stack space = 32, heap space = 50, capacity = 32, size = 17
下面分别给出代码例子中的结构图
短字符串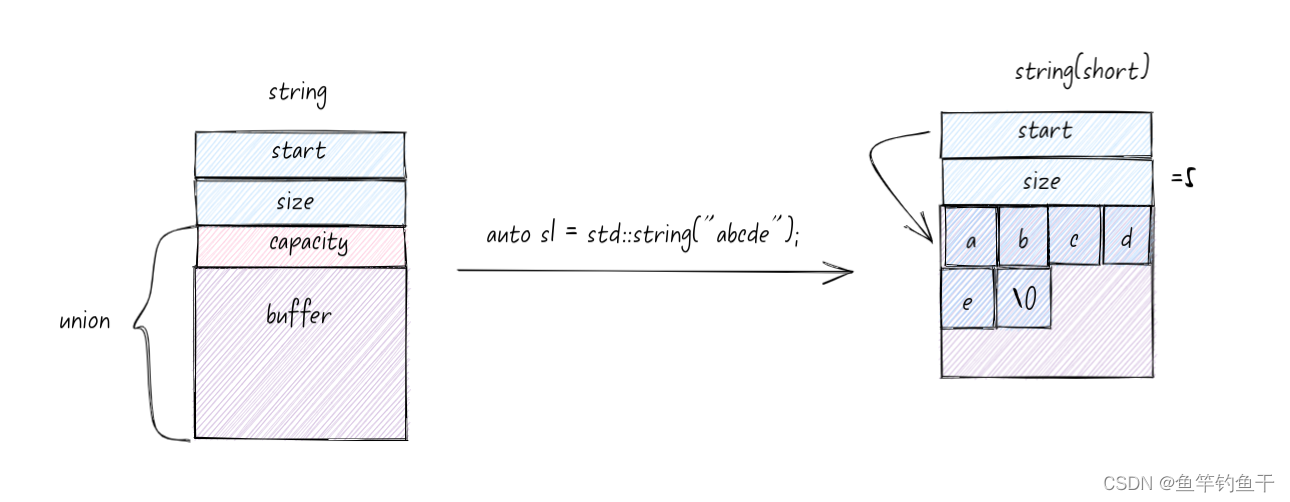
长字符串
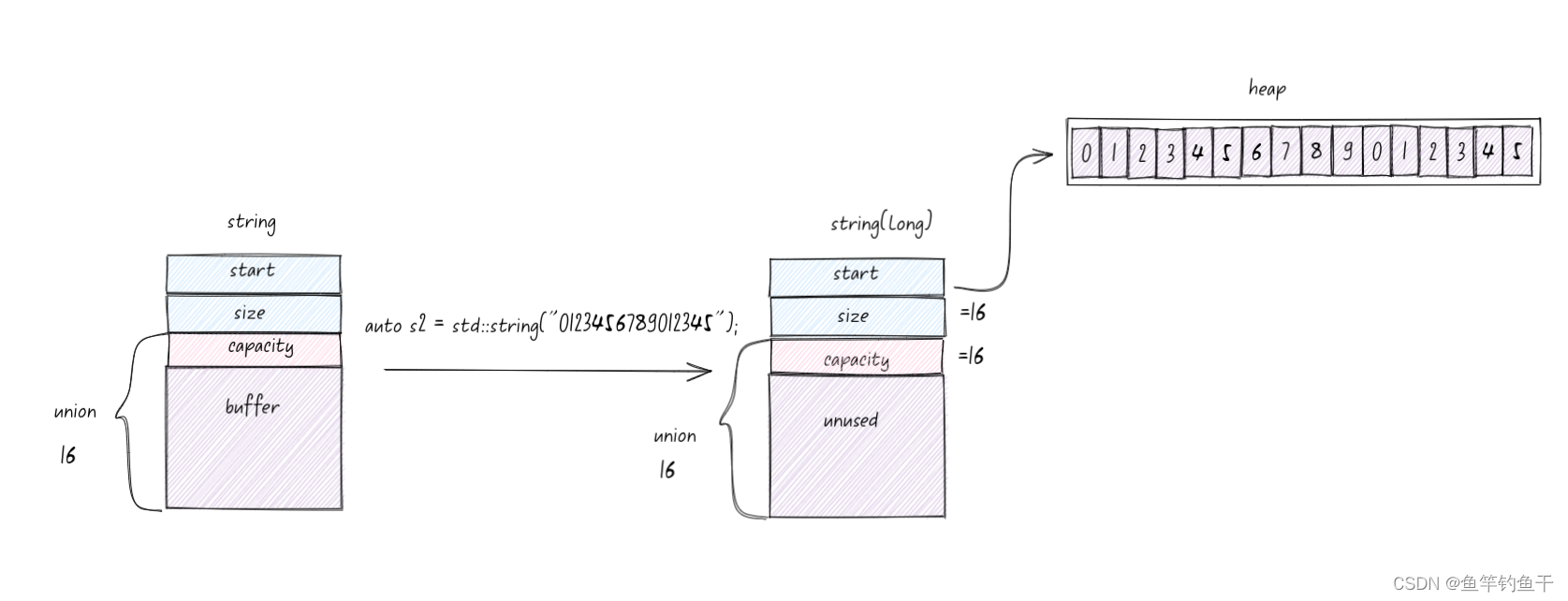
长字符串扩容
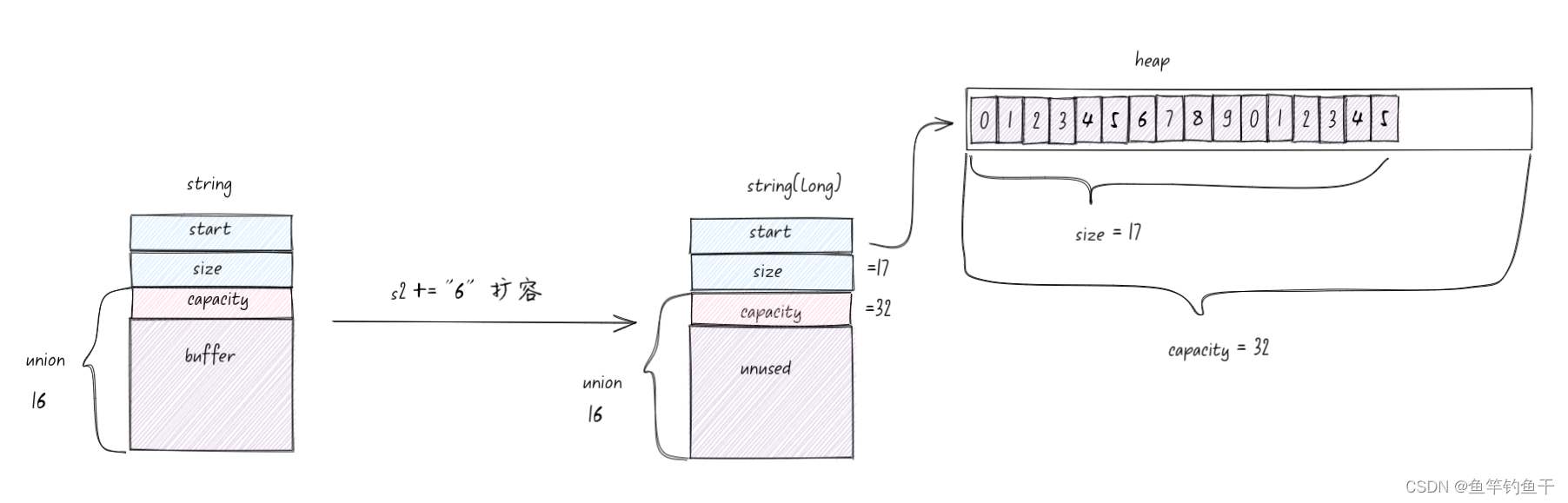
关于 capacity 扩容策略,根据编译器可能有不同的策略。我使用的是 x86_64 gcc 12.2,capactiy 构造的时候要多长就分配多长,后期扩容的时候 2 倍扩容
关于 SSO 的具体实现还有好几种方式,其 string 对象大小、可以本地存储的栈空间大小也各不相同,具体可以去看 Linux 多线程服务端编程 陈硕 这本书中 《12.7 再探 std::string》 这一章节的介绍。
优点:
- 短字符串时,无动态内存分配。
缺点:
- string 对象占用空间比 eager copy 和 cow 要大。(可以根据实现优化空间利用率)
- 实现相对复杂一些
2.3 std::string 的优点
- 自动管理内存的 C 字符串,有着类似 vector 自动扩容机制
- 重载了很多运算符,操作更加方便了
2.4 std::string 有什么缺陷
在知乎上搜了一下下面的两个问题,可以发现回答数差距还是比较大的,看来大家对 std::string 并不是特别满意,下面就梳理一下这些回答中的提及到的缺点。
知乎问题:C++ std::string 有什么优点? 8 个回答
知乎问题:C++ 的 std::string 有什么缺点? 53 个回答

缺少编码信息
std::string 本质其实是一个 basic_string<char> 基本和 vector<char> 是类似的,可以理解为一个字节数组,它并没有包含字符编码信息。
这意味着 std::string 只是一个存储数据的容器,它既可以存储UTF-8 也可以存储UTF-32 。显示的时候乱码往往是因为显示的地方总是假设 std::string 当中存放的是某种编码的数据, 例如用记事本默认 ASCII 打开 存放了 UTF-8 的数据, 那么就会出现乱码。
虽然 C++20 添加了 char8_t 和 std::u8string 等来支持 UTF-8 但似乎很糟糕, 因为缺少输入、输出、格式化设施,如果想要用std::format、std::cin、std::cout、std::fstream 还得在内部复制一遍所有字符串,造成不必要的开销。在这之前至少可以将任何 UFT-8 数据当作 char 然后无性能损失地实现。
缺少完备设施
C++ std::string 相比 C 风格字符串方便了很多,但是相比其他一些语言的字符串在易用性上还是差了不少。标准库并没有直接提供诸如 split、startsWith 之类的函数,往往需要自己封装。
对于字符串格式化而言,C++ 20 以前只支持下面两种
- printf 一族的 C 风格字符串函数
- 带来的 C 风格字符串的种种缺陷,需要手动内存管理
- 只支持几种内置类型
- 缺乏类型安全
- stream 一族的 C++ 流设施
- 语法不直观,代码冗余
C++20 format 用起来和 python 的 formatter 类似,更加简单直观且类型安全
性能可能有差异
前面谈到了 std::string 的三种实现方式,可以发现标准并没有严格规定如何去实现 std::string。有的是 COW、有的是 SSO,其空间、时间效率根据实现又各有不同,无法保证。
三、替身们
这一部分参考了以下这些博客/文章
C++ folly库解读(一) Fbstring —— 一个完美替代std::string的库
漫步Facebook开源C++库folly(1):string类的设计
漫谈C++ string(3):FBString的实现
folly FBString 文档
StringPiece介绍
brpc小课堂:从StringPiece说开来
C++ string_view 字符串视图
这一部分主要介绍 std::string 的两个替代品(补充品),FaceBook folly 库的 FBstring 和 Chrome 的 StringFiece。由于个人使用经验还比较有限,所以不细究其具体实现,以了解应用场景为主。当然还有诸如 QString 之类的优秀实现,在这也不做过多介绍。
3.1 FBstring
3.1.1 什么是 FBstring
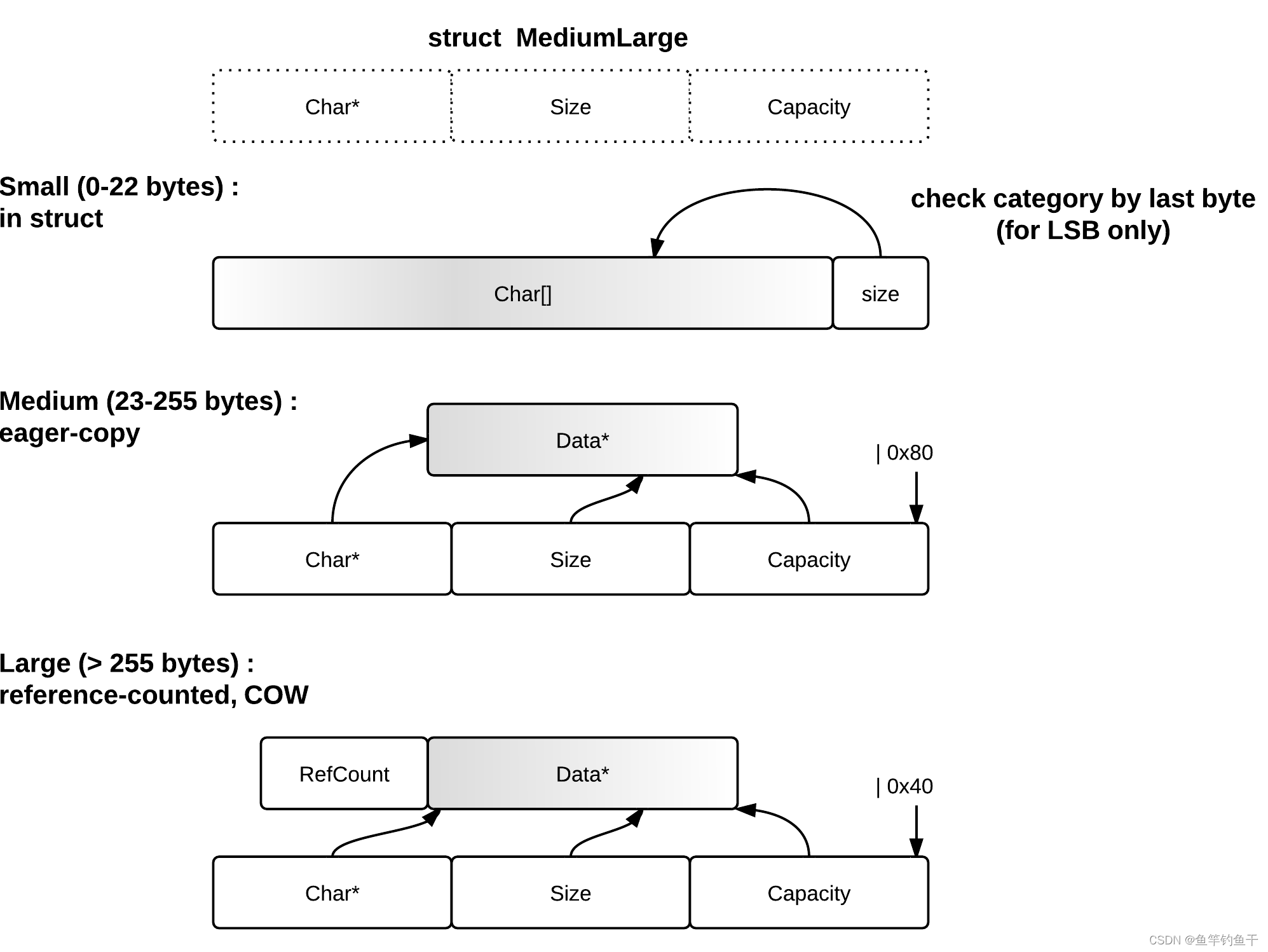
FBstring 是 std::string 的替代品,使用三层存储策略,通过配合内存分配器,特别是 jemalloc,以改善性能和内存使用状况。
支持 32 和 64 位以及大小端架构
存储策略
- Small Strings(<=23 chars),使用 SSO
- Medium Strings(24-255 chars),存储在 malloc 分配的内存中,采用 eager copy 策略
- Large Strings(> 255 chars) 存储在 malloc 分配的内存中,采用懒复制 COW
3.2.2 FBstring 有什么优势
- 100% 兼容
std::string,可以和std::string相互转换 - Large Strings 使用线程安全的引用计数来实现 COW
- 对
Jemalloc友好,如果发现使用了Jemalloc就会使用它的一些非标准扩展接口来提高性能 - 没用 allocator 获取内存,而是直接使用 malloc/free 管理内存。
find()用简化的 Boyer-Moore algorithm 算法实现。相较string::find()在成功的时候有 30 倍的性能提升,在失败的时候有 1.5 倍的性能提升- Fbstring在
std::string的基础上对于不同尺寸的string采用了不同类型的实现方式,对内存的使用控制非常精细。(原本 SSO 只有两个粒度分类)- 短字符串直接存储在栈中从而避免内存分配
- 中型字符串采用了eager copy的实现方式,因为folly鼓励使用jemalloc来替代glibc下默认的ptmalloc,内存使用使用很高效,开辟这样尺寸的内存可以认为是非常高效的
- 长字符串则采用了COW的实现,减少内存拷贝
3.2 StringPiece 与 std::string_view
3.2.1 什么是 StringPiece
StringPiece 是一个很常见的字符串工具类,在很多 C++ 项目中均有实现。例如 chromium(StringPiece), llvm(StringRef), boost(string_ref), folly(StringPiece), pcre(StringPiece) 等;国内项目 brpc, 经典面试项目 muduo 中也有 StringPiece 的身影;在 C++17 之后以 std::string_view 的形式进入标准库。
那么 std::string 和 StringPiece 有何区别?
StringPiece 并没有数据的所有权,存储的是指向字符串的指针,也就是说 StringPiece 以非拥有的方式包装了现有字符串。这说明了以下两点。
StringPiece不会开辟新的空间来存储字符串StringPiece的生命周期和其包装数据的声明周期并不一致
为了方便,我们用 C++17 的 std::string_view 写几个例子来说明这两点,std::string_view 基本原理和 StringPiece 相同,只是 API 可能存在微小差异。
StringPiece 不会开辟新的空间来存储字符串
// https://godbolt.org/z/drrKP6hrc
#include <string>
#include <string_view>
#include <iostream>
auto allocated = 0;
// 重载全局 operator new,统计分配的堆内存
void* operator new(size_t size) {
void* p = std::malloc(size);
allocated += size;
return p;
}
void foo1(std::string str) {
std::cout << "string test = " << str << std::endl;
std::cout << allocated << std::endl;
allocated = 0;
std::cout << std::endl;
}
void foo2(const std::string& str) {
std::cout << "const std::string& test = " << str << std::endl;
std::cout << allocated << std::endl;
allocated = 0;
std::cout << std::endl;
}
void foo3(const char* str) {
std::cout << "const char* str test = " << str << std::endl;
std::cout << allocated << std::endl;
allocated = 0;
std::cout << std::endl;
}
void foo4(std::string_view sv) {
std::cout << "string_view test = " << sv << std::endl;
std::cout << allocated << std::endl;
allocated = 0;
std::cout << std::endl;
}
int main() {
std::string str = "012345678901234567890123456789"; // 要超过 SSO 阈值
allocated = 0;
std::cout << "test 1" << std::endl;
foo1(str);
foo2(str);
// foo3(str); const char* 不能直接传 std::string
foo3(str.c_str());
foo4(str);
std::cout << std::endl;
std::cout << "test 2" << std::endl;
foo1("012345678901234567890123456789");
foo2("012345678901234567890123456789");
foo3("012345678901234567890123456789");
foo4("012345678901234567890123456789");
return 0;
}
测试结果
test 1
string test = 012345678901234567890123456789
31
const std::string& test = 012345678901234567890123456789
0
const char* str test = 012345678901234567890123456789
0
string_view test = 012345678901234567890123456789
0
test 2
string test = 012345678901234567890123456789
31
const std::string& test = 012345678901234567890123456789
31
const char* str test = 012345678901234567890123456789
0
string_view test = 012345678901234567890123456789
0
| 形参 | 实参 | 是否发生内存分配 |
|---|---|---|
| std::string | C 风格字符串 | Y |
| const std::string& | C 风格字符串(会被构造成 std::string) | Y |
| const char* | C 风格字符串 | N |
| std::string_view | C 风格字符串 | N |
| std::string | std::string | Y |
| const std::string& | std::string | N |
| const char* | std::string(必须要转换为 C 风格字符串) | N |
| std::string_view | std::string | N |
可以发现 std::string_view 不仅能在传参的时候避免内存分配,而且同时适用于 C 风格字符串和 std::string 字符串,不必专门转换。
StringPiece 的生命周期和其包装数据的声明周期并不一致
// https://godbolt.org/z/n4Px1M48W
#include <string>
#include <string_view>
#include <iostream>
std::string_view foo() {
std::string str = "abc";
return std::string_view(str); // str 析构了
}
int main() {
std::string_view sv("abcd");
std::cout << sv.data() << std::endl;
std::cout << foo().data() << std::endl; // 高危操作
return 0;
}
输出结果
abcd
A@ // 出现问题了
3.2.2 StringPiece 有什么优势
在 chromium 的 string_piece.h 代码文件中说明了 StringPiece 的主要优点
https://source.chromium.org/chromium/chromium/src/+/main:base/strings/string_piece.h
// Copyright 2012 The Chromium Authors
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
//
// A string-like object that points to a sized piece of memory.
//
// You can use StringPiece as a function or method parameter. A StringPiece
// parameter can receive a double-quoted string literal argument, a “const
// char*” argument, a string argument, or a StringPiece argument with no data
// copying. Systematic use of StringPiece for arguments reduces data
// copies and strlen() calls.
//
// Prefer passing StringPieces by value:
// void MyFunction(StringPiece arg);
// If circumstances require, you may also pass by const reference:
// void MyFunction(const StringPiece& arg); // not preferred
// Both of these have the same lifetime semantics. Passing by value
// generates slightly smaller code. For more discussion, Googlers can see
// the thread go/stringpiecebyvalue on c-users.
1、统一了参数格式
不需要为const char* ,const std::string&等分别实现功能相同的函数了,参数统一指定为StringPiece 或 std::string_view 即可。
注意到在先前的代码案例中
void foo2(const std::string& str) {
std::cout << "const std::string& test = " << str << std::endl;
std::cout << allocated << std::endl;
allocated = 0;
std::cout << std::endl;
}
void foo3(const char* str) {
std::cout << "const char* str test = " << str << std::endl;
std::cout << allocated << std::endl;
allocated = 0;
std::cout << std::endl;
}
如果给 foo2 传入 C 风格的字符串就会发生内存分配。如果相关 foo3 传递 std::string 就需要先转为 C 风格的字符串。
为了方便用户,我们可以重载这两个函数
#include <string>
#include <string_view>
#include <iostream>
auto allocated = 0;
// 重载全局 operator new,统计分配的堆内存
void* operator new(size_t size) {
void* p = std::malloc(size);
allocated += size;
return p;
}
void foo2(const std::string& str) {
std::cout << "foo2 const std::string& test = " << str << std::endl;
std::cout << allocated << std::endl;
allocated = 0;
std::cout << std::endl;
}
void foo2(const char* str) {
std::cout << "foo2 const char* test = " << str << std::endl;
std::cout << allocated << std::endl;
allocated = 0;
std::cout << std::endl;
}
void foo3(const char* str) {
std::cout << "foo3 const char* str test = " << str << std::endl;
std::cout << allocated << std::endl;
allocated = 0;
std::cout << std::endl;
}
void foo3(const std::string& str) {
std::cout << "foo3 std::string& str test = " << str << std::endl;
std::cout << allocated << std::endl;
allocated = 0;
std::cout << std::endl;
}
int main() {
std::string str = "012345678901234567890123456789"; // 要超过 SSO 阈值
allocated = 0;
std::cout << "test 1" << std::endl;
foo2(str);
foo2("012345678901234567890123456789");
std::cout << std::endl;
std::cout << "test 2" << std::endl;
foo3(str);
foo3("012345678901234567890123456789");
return 0;
}
结果为
test 1
foo2 const std::string& test = 012345678901234567890123456789
0
foo2 const char* test = 012345678901234567890123456789
0
test 2
foo3 std::string& str test = 012345678901234567890123456789
0
foo3 const char* str test = 012345678901234567890123456789
0
避免了内存分配,不过这样每个都要重载一遍也太麻烦了,std::string_view 就解决了这个问题,统一了参数
2、节约了数据拷贝以及strlen的调用
在 《3.2.1 什么是 StringPiece》 当中,第一个代码案例便给出了 StringPiece 能够节约数据拷贝的证明
3、O(1) 的 substr
除了以上两点,获取子串也是 StringPiece 的优点之一
- std::string 的 substr 方法需要 O ( N ) O(N) O(N) 的线性复杂度,复杂度和字符串大小有关。
- std::string_view 的 substr 方法具有 O ( 1 ) O(1) O(1) 的常数复杂度,复杂度和字符串大小无关。
下面是一个简单的性能测试,基于网站 Quick C++ Benchmarks
- GCC 12.2
- O2 优化
- C++ 20 标准
// https://quick-bench.com/q/ACForeT_vkfkdvccL7OQ6dO51tY
static void String10(benchmark::State& state) {
std::string str = "0123456789";
for (auto _ : state) {
str.substr(0, str.size());
}
}
BENCHMARK(String10);
static void String40(benchmark::State& state) {
std::string str = "0123456789012345678901234567890123456789";
for (auto _ : state) {
str.substr(0, str.size());
}
}
BENCHMARK(String40);
static void String80(benchmark::State& state) {
std::string str = "01234567890123456789012345678901234567890123456789012345678901234567890123456789";
for (auto _ : state) {
str.substr(0, str.size());
}
}
BENCHMARK(String80);
static void StringView10(benchmark::State& state) {
std::string_view sv("0123456789");
for (auto _ : state) {
sv.substr(0, sv.size());
}
}
BENCHMARK(StringView10);
static void StringView40(benchmark::State& state) {
std::string_view sv("0123456789012345678901234567890123456789");
for (auto _ : state) {
sv.substr(0, sv.size());
}
}
BENCHMARK(StringView40);
static void StringView80(benchmark::State& state) {
std::string_view sv("01234567890123456789012345678901234567890123456789012345678901234567890123456789");
for (auto _ : state) {
sv.substr(0, sv.size());
}
}
BENCHMARK(StringView80);
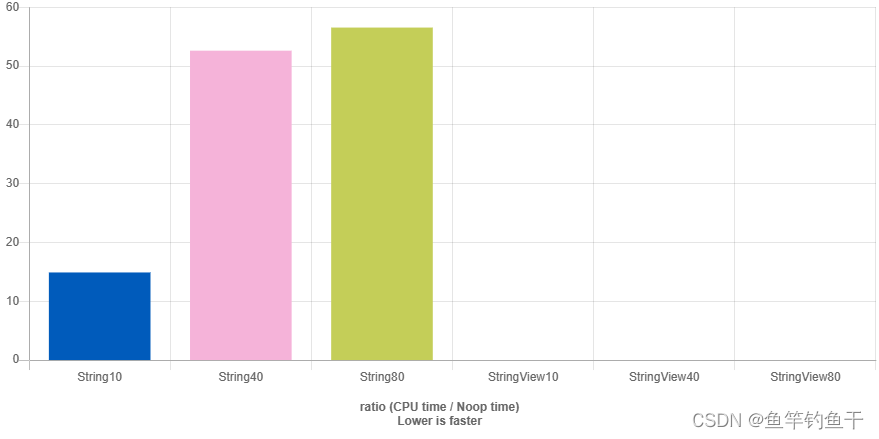
四、总结
五、参考资料
C的字符串有哪些问题
C风格字符串缺陷及改进
函数式编程
深入剖析 linux GCC 4.4 的 STL string
漫谈C++ string(1):std::string实现
C++ folly库解读(一) Fbstring —— 一个完美替代std::string的库
Linux 多线程服务端编程 陈硕
C++标准库中string的三种底层实现方式
std::string的Copy-on-Write:不如想象中美好
知乎问题:C++ std::string 有什么优点?
知乎问题:C++ 的 std::string 有什么缺点?
漫谈C++ string(3):FBString的实现
漫步Facebook开源C++库folly(1):string类的设计
folly FBString 文档
StringPiece介绍
brpc小课堂:从StringPiece说开来
C++ string_view 字符串视图