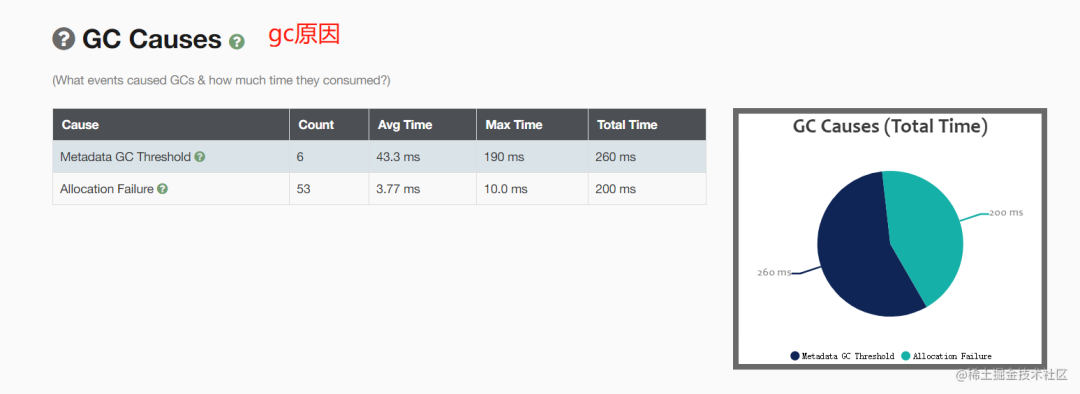
在人机交互的过程中,语音是重要的信息载体,而语音交互技术离不开语音识别与语音合成技术。飞桨语音模型库PaddleSpeech为开发者们使用这些技术提供了便捷的环境。本次PaddleSpeech迎来重大更新——1.3版本正式发布。让我们一起看看,这次PaddleSpeech为大家带来了哪些新内容吧!
-
提速300%,提供U2模型和U2++模型高性能C++部署方案;
-
无监督预训练大模型wav2vec2正式上线,支持全流程微调;
-
通用语音识别大模型Whisper上线PaddleSpeech CLI;
-
语音合成支持Android全流程部署;
-
新增SSML标签实现发音控制;
-
语音合成支持韵律预测与韵律合成控制。
-
更多内容可以参考
https://github.com/PaddlePaddle/PaddleSpeech/releases/tag/r1.3.0

亮点速览
 提速300%,提供U2模型和U2++模型高性能C++部署方案
提速300%,提供U2模型和U2++模型高性能C++部署方案
U2模型是由企业出门问问联合西北工业大学推出的端到端语音识别模型,实现了流式识别与非流式识别统一的解决方案。U2++则是在U2的基础上添加了Left to Right和Right to Left两个Attention Decoder,进一步降低识别的CER(Char Error Rate,字错误率)。
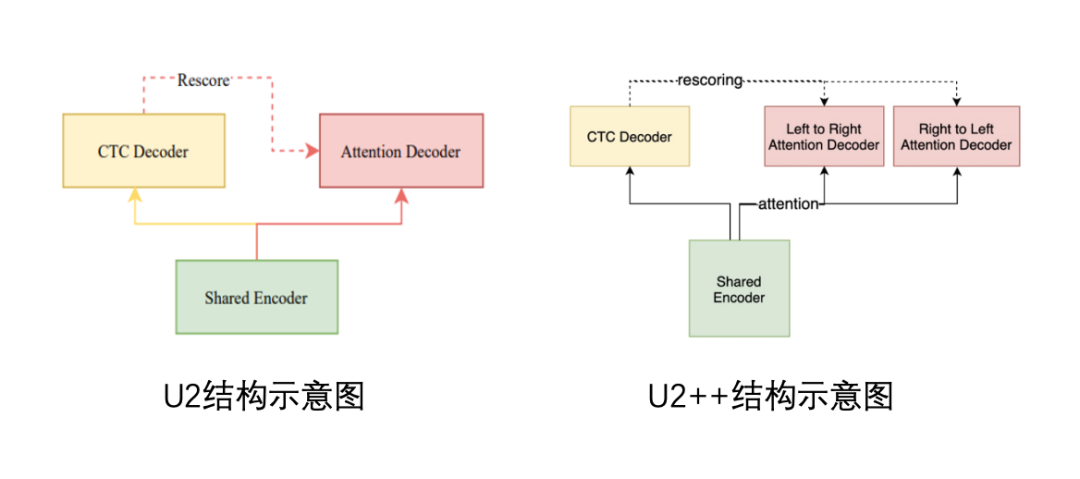
U2模型与U2++结构示意图
这次PaddleSpeech 1.3版本发布,带来了U2模型和U2++模型高性能C++部署方案,通过推理加速与量化压缩技术,相较于基于Python的动态图推理,模型推理速度提升300%。
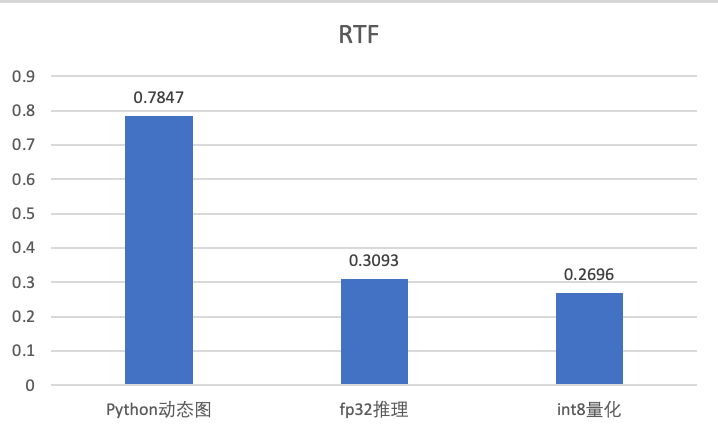
U2++模型推理测试RTF结果
注:测试机器为CPU:Intel(R) Xeon(R) Gold 6271C CPU@2.60GHz,RTF=处理语音总时长/语音总时长,RTF数值越小,速度越快。
通过下面的链接可以快速体验推理加速方案带来的极致性能提升!
-
体验传送门
https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/speechx/examples/u2pp_ol/wenetspeech
 无监督预训练大模型wav2vec2正式上线
无监督预训练大模型wav2vec2正式上线
在语音识别任务中,除了面临技术上的挑战以外,另一个方面的挑战则是来自数据。采用有监督的学习方式训练语音识别模型,需要海量带标签的高质量语音识别标注数据,而标注数据的价格居高不下,需要大量的资金投入。无监督预训练大模型技术,带来了新的解决方案,业务中产生的大量无标注数据都可以被充分运用。
wav2vec2是语音无监督预训练大模型,可以承接包含语音识别在内的多种语音任务,并且在多个任务场景中取得了SOTA的结果。
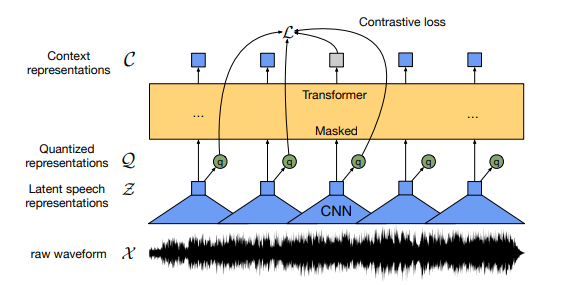
wav2vec2结构示意图
本次PaddleSpeech1.3版本发新,将支持wav2vec2的微调工作(目前只支持英文)。你可以通过在自己的数据集上微调wav2vec2模型,从而在特定业务上达到更好的识别效果。
-
wav2vec2 微调传送门
https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/librispeech/asr3
基于Librispeech数据集的微调模型已集成入CLI当中,通过pip安装或者源码安装的方式安装好1.3版本之后,可以使用Python进行快速体验。你可以使用微调后的模型进行语音识别工作,也可以通过wav2vec模型提取音频特征,承接下游任务。
-
wav2vec2示例代码
import paddle
from paddlespeech.cli.ssl import SSLExecutor
ssl_executor = SSLExecutor()
# to recognize text
text = ssl_executor(
model='wav2vec2ASR_librispeech',
task='asr',
lang='en',
sample_rate=16000,
config=None, # Set `config` and `ckpt_path` to None to use pretrained model.
ckpt_path=None,
audio_file='./en.wav',
device=paddle.get_device())
print('ASR Result: \n{}'.format(text))
# to get acoustic representation
feature = ssl_executor(
model='wav2vec2',
task='vector',
lang='en',
sample_rate=16000,
config=None, # Set `config` and `ckpt_path` to None to use pretrained model.
ckpt_path=None,
audio_file='./en.wav',
device=paddle.get_device())
print('Representation: \n{}'.format(feature)) 通用语音识别大模型Whisper上线PaddleSpeech CLI
通用语音识别大模型Whisper上线PaddleSpeech CLI
Whisper是OpenAI今年9月份开源的通用的语音识别模型,在时长为680,000小时的多语言大数据集上,通过有监督的方式训练得到。Whisper也是一个多任务模型,可以同时支持多语言语音识别以及Any-to-English的语音翻译工作。

Whisper结构示意
目前,Whisper模型已集成到 PaddleSpeech的CLI中,通过命令行或者Python代码即可快速体验语音识别与语音翻译功能。
-
Whisper CLI命令行示例
# 识别文本
paddlespeech whisper --task transcribe --input ./zh.wav
# 将语音翻译成英语
paddlespeech whisper --task translate --input ./zh.wav同样地,你也可以使用Python将其快速集成到自己的项目当中。
-
Whisper Python使用示例
import paddle
from paddlespeech.cli.whisper import WhisperExecutor
whisper_executor = WhisperExecutor()
# 识别文本
text = whisper_executor(
model='whisper-large',
task='transcribe',
sample_rate=16000,
config=None, # Set `config` and `ckpt_path` to None to use pretrained model.
ckpt_path=None,
audio_file='./zh.wav',
device=paddle.get_device())
print('ASR Result: \n{}'.format(text))
# 将语音翻译成英语
test_en = whisper_executor(
model='whisper-large',
task='translate',
sample_rate=16000,
config=None, # Set `config` and `ckpt_path` to None to use pretrained model.
ckpt_path=None,
audio_file='./zh.wav',
device=paddle.get_device())
print('Representation: \n{}'.format(test_en)) 语音合成支持Android部署
语音合成支持Android部署
这次PaddleSpeech1.3版本,基于Paddle Lite的端侧部署能力,实现了语音合成声学模型FastSpeech2和声码器Multi-band MelGAN模型在Android上进行部署。推理引擎Paddle Lite除了支持上述模型推理外,也支持SpeedySpeech、Parallel WaveGAN和HiFiGAN等其它语音合成模型。
你可以通过点击下方链接,参考示例代码,在自己的设备上编译应用,也可以下载我们提供的APK安装包快速体验语音合成能力。
手机端语音合成部署示例
-
体验传送门
https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/demos/TTSAndroid
 新增SSML标签实现发音控制
新增SSML标签实现发音控制
SSML(Speech Synthesis Markup Language)是语音合成标记语言。在工业生产中,通过SSML标签可以快速对合成过程进行干预。在本次发新中,PaddleSpeech正式添加了SSML的解析支持,目前支持对中文的文本发音进行指定,可以很好的修复由多音字发音不正确导致的发音错误问题。
-
使用示例
from paddlespeech.cli.tts.infer import TTSExecutor
tts = TTSExecutor()
text = "<speak>人要是行,干一行<say-as pinyin='xing2'>行</say-as>一行,一<say-as pinyin='hang2 xing2 hang2 hang2 xing2'>行行行行行</say-as>。</speak>"
tts(text=text, output="output.wav")-
效果示例:
 语音合成支持韵律预测与韵律合成控制
语音合成支持韵律预测与韵律合成控制
在传统参数法的语音合成过程中,韵律信息会作为特征工程的一部分,通过对语言的韵律结构信息进行建模,从而指导语音合成过程。在技术发展的过程中,韵律层级划分也在不断变化,如标贝科技开源的中文标准女声语音库数据采用四级韵律标记划分,包含韵律词(#1)、韵律短语(#2)、语调短语(#3)和句末(#4)四个层级的标注。
在目前的语音合成产品中,多以四级韵律标记划分为主,部分产品根据业务需要,有的也会采用其它的韵律划分标准,如五级韵律划分与三级韵律划分,这里不做更多讨论,只讨论四级韵律划分标记。
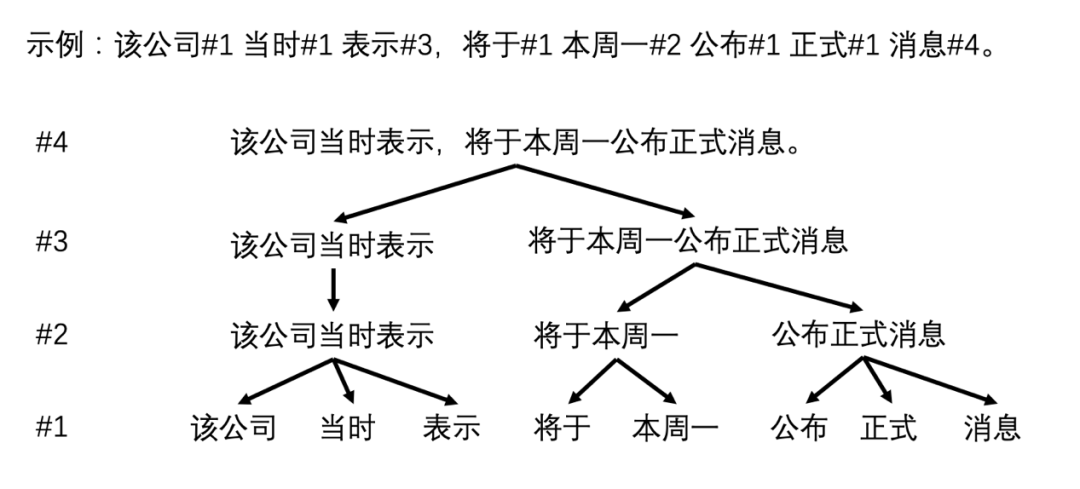
汉语韵律结构四级韵律标记划分示意图
进入端到端合成时代,经典的端到端语音合成方法如Tacotron2、TransformerTTS、FastSpeech1和FastSpeech2都采用直接将输入的音素作为建模单元,让模型通过大量的语音合成数据学习语言中的韵律规律。从试验的结果来看,采用此类方法确实可以让模型学习到韵律的发音规律,但是面对复杂的生产场景,偶尔会遇到发音韵律停顿不对的问题。由于输入阶段缺少韵律控制信息指导,导致推理阶段无法进行韵律调控,业务上错误的韵律停顿bad case无法得到及时的响应。
为了进一步提高端到端语音合成的稳定性和可控性,PaddleSpeech提出了一套基于文本输入的韵律预测模型,并在语音合成的输入阶段,引入韵律结构信息,从而实现合成过程中韵律可控。韵律预测任务可以认为是一个五类别的序列标记任务,即输入的每一个文字后面都存在一个槽位,可以使用无韵律或者#1~#4的四级韵律标记,通过微调文心ERNIELinear模型实现韵律预测标记任务。

-
关于韵律预测的更多细节,可通过链接体验
https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/other/rhy
在声学模型的训练阶段,将韵律标记与音素一起输入到声学模型中进行训练,可以得到韵律可控的声学模型。以FastSpeech2为例,支持韵律标注的模型结构如下。
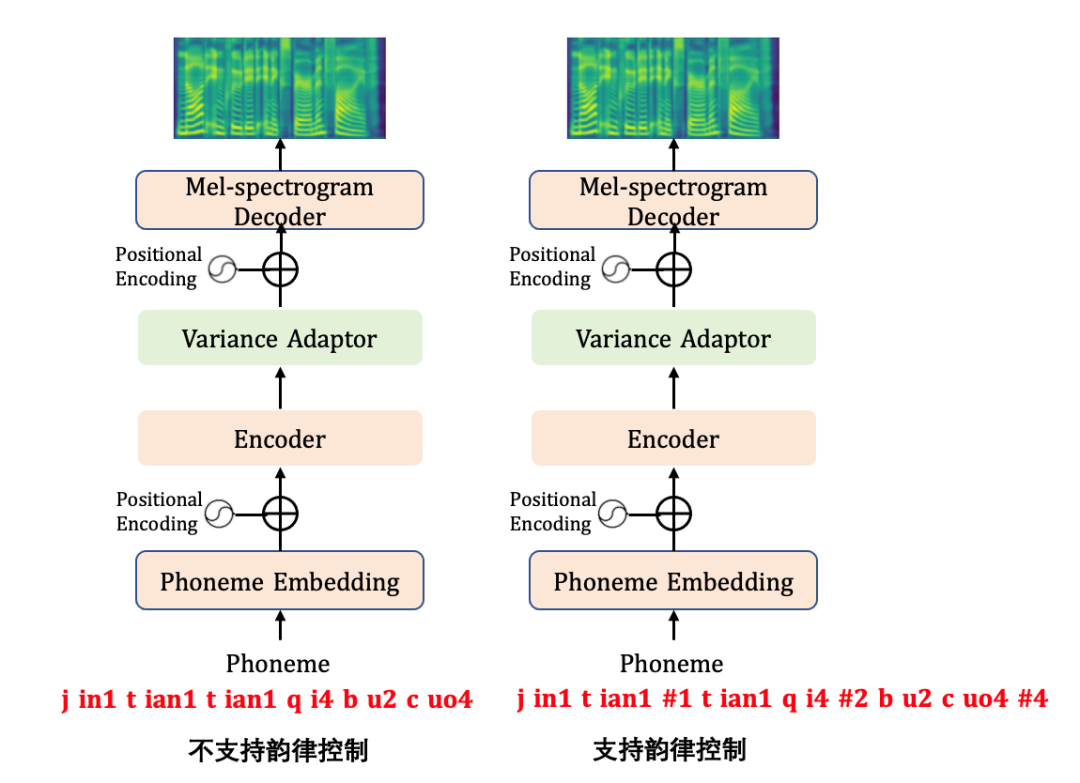
-
带韵律控制信息的FastSpeech2训练体验链接
https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/csmsc/tts3_rhy

飞桨语音技术课程
由PaddleSpeech的核心开发者精心打造的免费公开课《飞桨PaddleSpeech语音技术课程》目前已经在AI Studio中上线。该课程非常适合于零基础的开发者入门智能语音开发工作。课程内容会随着PaddleSpeech的发展建设,持续更新最前沿的技术,同样适合于具有开发经验的语音方向开发者们。让我们一起看看课程中有哪些内容吧!

课程内容持续更新中,欢迎大家前往AI Studio中报名参与。
-
课程传送门
https://aistudio.baidu.com/aistudio/course/introduce/25130

精品项目合集
PaddleSpeech建设过程中,也有很多开发者基于PaddleSpeech开发了许多有趣的项目。比如,基于PaddleGAN与PaddleSpeech的虚拟人项目PaddleBoBo,基于PaddleOCR与PaddleSpeech的电表点读系统,基于PaddleSpeech语音识别能力的语音听写桌面应用等等。这些项目都可以在AI Studio中在线体验,并已收录到PaddleSpeech教程与精品项目合集中,欢迎大家前来体验。

-
精品项目合集传送门
https://aistudio.baidu.com/aistudio/projectdetail/4692119
飞桨PaddlePaddle公众号后台回复关键词:PaddleSpeech,即可获取飞桨语音技术课程资源、精品项目合集等。
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~