说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。
1.项目背景
萤火虫算法(Fire-fly algorithm,FA)由剑桥大学Yang于2009年提出 , 作为最新的群智能优化算法之一,该算法具有更好的收敛速度和收敛精度,且易于工程实现等优点。
本项目通过FA萤火虫优化算法寻找最优的参数值来优化支持向量机分类模型。
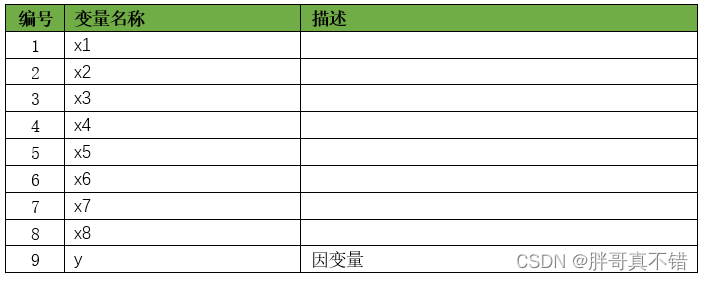
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
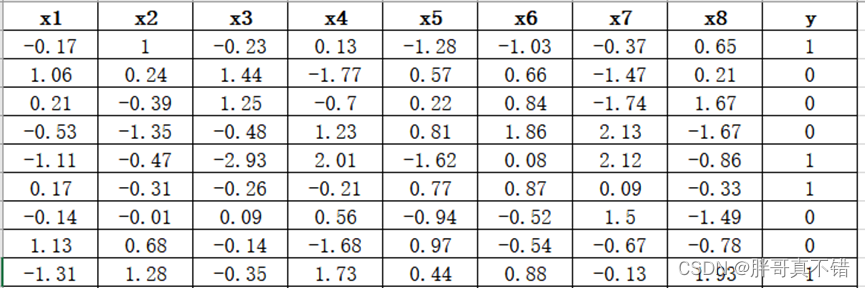
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
从上图可以看到,总共有9个变量,数据中无缺失值,共1000条数据。
关键代码:

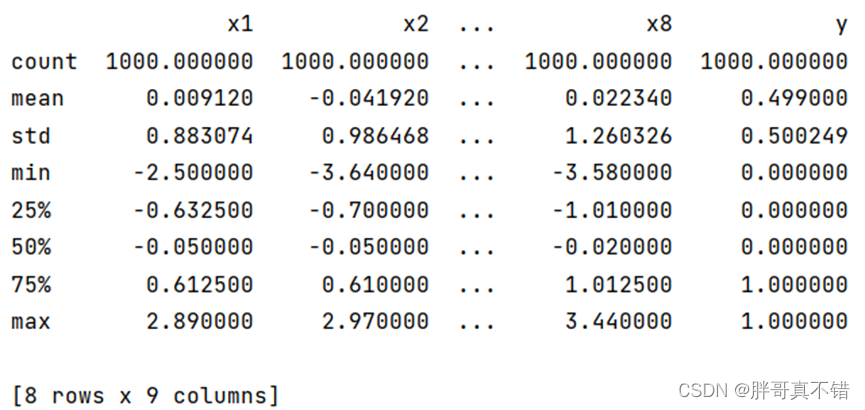
3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:

4.探索性数据分析
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.3 相关性分析
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:
5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:
6.构建FA萤火虫优化算法优化支持向量机分类模型
主要使用FA萤火虫优化算法优化SVC算法,用于目标分类。
6.1 算法介绍
说明:FA算法介绍来源于网络,供参考,需要更多算法原理,请自行查找资料。
(1)算法原理:
在FA中,萤火虫发出光亮的主要目的是作为一个信号系统,以吸引其他的萤火虫个体,其假设为:
1) 萤火虫不分性别,它将会被吸引到所有其他比它更亮的萤火虫那去;
2) 萤火虫的吸引力和亮度成正比,对于任何两只萤火虫,其中一只会向着比它更亮的另一只移动,然而,亮度是随着距离的增加而减少的;
3) 如果没有找到一个比给定的萤火虫更亮,它会随机移动 。
如上所述,萤火虫算法包含两个要素,即亮度和吸引度。亮度体现了萤火虫所处位置的优劣并决定其移动方向,吸引度决定了萤火虫移动的距离,通过亮度和吸引度的不断更新,从而实现目标优化。从数学角度对萤火虫算法的主要参数进行如下描述 :
(1)萤火虫的相对荧光亮度为:
其中,I0 为萤火虫的最大萤光亮度,与目标函数值相关,目标函数值越优自身亮度越高;γ为光强吸收系数,荧光会随着距离的增加和传播媒介的吸收逐渐减弱; ri,j 为萤火虫i与j之间的空间距离 。
(2)萤火虫的吸引度为:
其中,β0 为最大吸引度; γ为光强吸收系数; ri,j 为萤火虫i与j之间的空间距离。
(3)萤火虫i被吸引向萤火虫j移动的位置更新公式如式(3)所示:
其中,xi ,xj 为萤火虫i和j所处的空间位置;α∈[0,1] 为步长因子;rand为[0,1]上服从均匀分布的随机数。
算法步骤如下:
(1)初始化萤火虫算法参数。
(2)计算各萤火虫的亮度并排序得到亮度最大的萤火虫位置。
(3)判断迭代是否结束:判断是否达到最大迭代次数 T ,达到则转(4),否则转(5)。
(4)输出亮度最大的萤火虫位置及其亮度。
(5)更新萤火虫位置:根据式(3)更新萤火虫的位置,对处在最佳位置的萤火虫进行随机扰动,搜索次数增加1 ,转(2),进行下一次搜索。
6.2 FA萤火虫优化算法寻找最优参数值
关键代码:
迭代过程数据(部分截图):
最优参数:
6.3 最优参数值构建模型
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
从上表可以看出,F1分值为0.8826,说明模型效果良好。
关键代码如下:
7.2 查看是否过拟合
从上图可以看出,训练集和测试集分值相当,无过拟合现象。
7.3 分类报告
从上图可以看出,分类为0的F1分值为0.87;分类为1的F1分值为0.88。
7.4 混淆矩阵
从上图可以看出,实际为0预测不为0的 有8个样本;实际为1预测不为1的 有17个样本,整体预测准确率良好。
8.结论与展望
综上所述,本项目采用了FA萤火虫优化算法寻找支持向量机SVC算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。











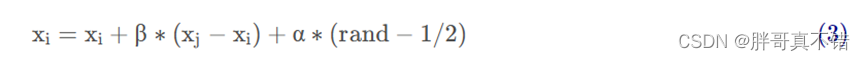








本次机器学习项目实战所需的资料,项目资源如下:
项目说明:
链接:https://pan.baidu.com/s/1c6mQ_1YaDINFEttQymp2UQ
提取码:thgk