Stable Video Diffusion(SVD)安装和测试
官网
- github | https://github.com/Stability-AI/generative-models
- Hugging Face | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
- Paper | https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
准备工作
我的系统环境
- 内存 64G
- 显存3090,24G显存
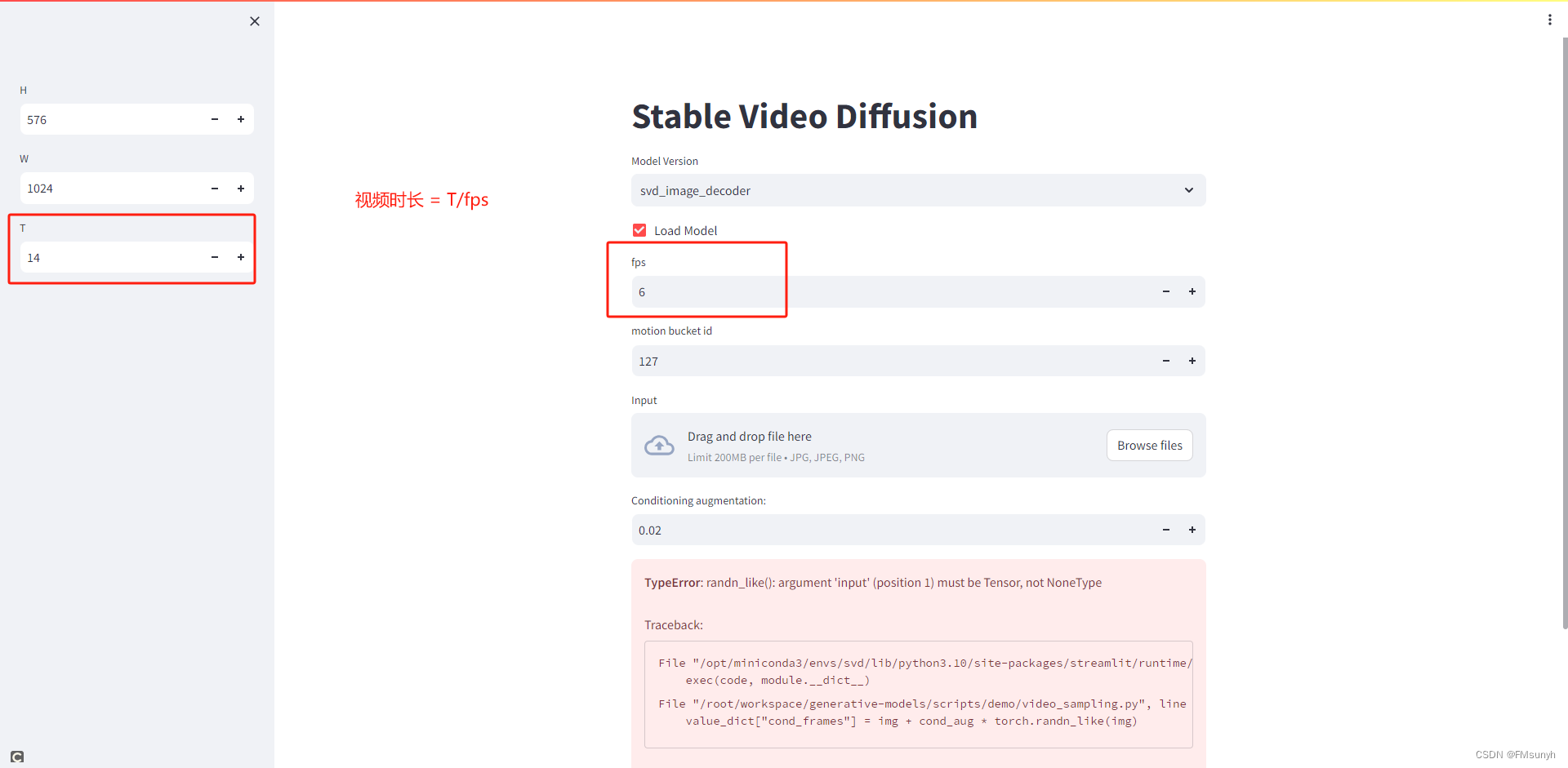
参数
- SVD 模型可以生成14 frames 分辨率576×1024. 也就是输入一张图,可以得到14帧
- SVD XT 模型可以生成25 frames 分辨率576×1024.
FPS
控制视频生成视频的帧数,取值范围【5~30】
比如:SVD 模型出来14帧的数据,然后编码成6帧每秒的视频,那最后输出的视频就是 14/6约2秒这样的视频。
Motion bucket id
控制视频中的动作,数值 越高,动作越多。 取值范围【0~255】
max-cfg-scale
控制生成的帧与第一帧的变化,第一帧默认1,最后一帧是max-cfg-scale,数值越大,变化越大;
也就是数值越大,生成的视频变化也会更大。
Decode t frames at a time (set small if you are low on VRAM)
编码成视频时,一次编码多少帧,设置为1~4。
生成的视频,是多少秒,怎么计算出来
视频时长 = T/fps
AIGC群交流