Hash基础
一、Hash的概念和基本特征
哈希(Hash)也称为散列,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,这个输出值就是散列值。
很多人可能想不明白,这里的映射到底是啥意思,为啥访问的时间复杂度为O(1)?我们只要看存的时候和读的时候分别怎么映射的就知道了。
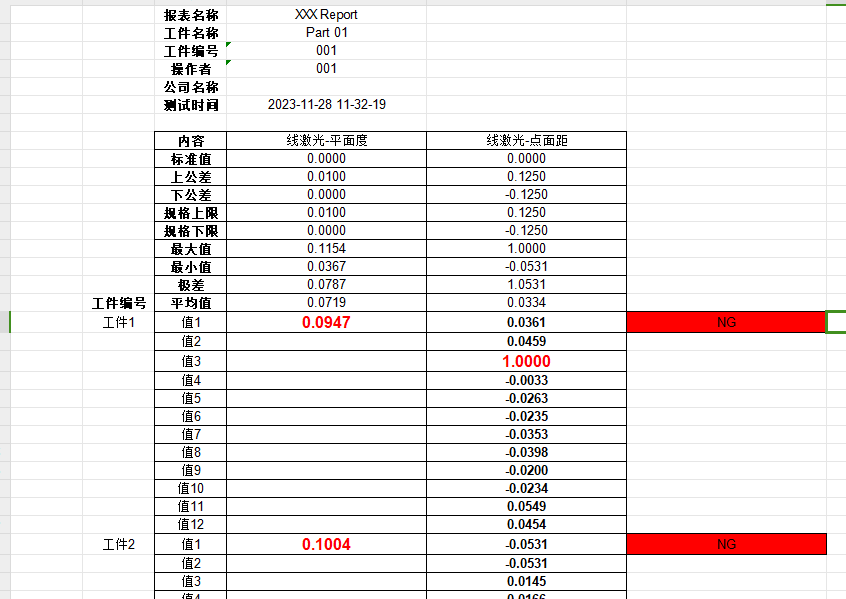
我们现在假设数组array存放的是1到15这些数,现在要存在一个大小是7的Hash表中,该如何存呢?我们存储的位置计算公式是:
index = number % 7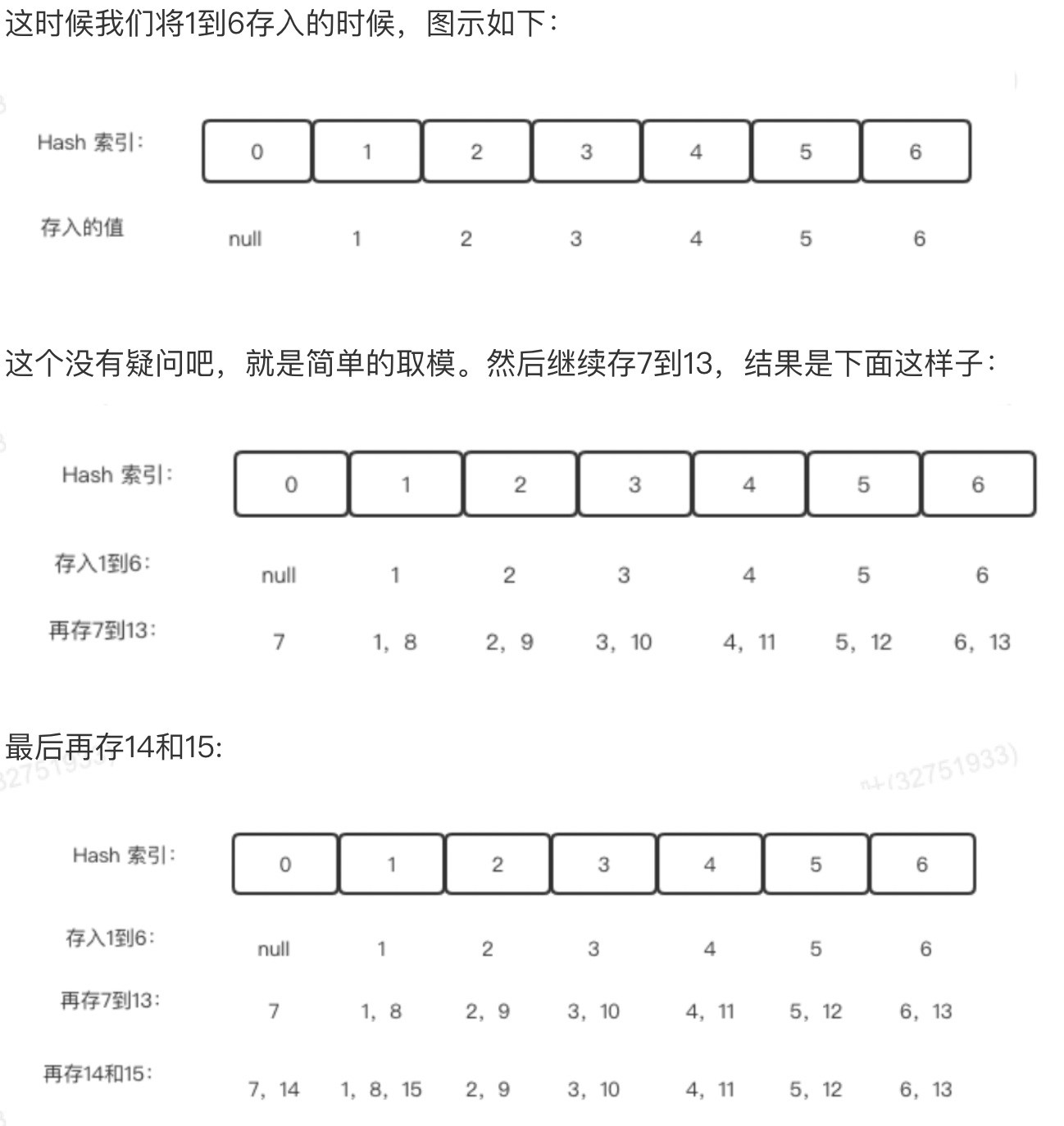
假如我要测试13在不在这里结构里,则同样使用上面的公式来进行,很明显13%7=6,我们直接访问array[6]这个位置,很明显是在的,所以返回true。
假如我要测试20在不在这里结构里,则同样使用上面的公式来进行,很明显20模7=6,我们直接访问array[6]这个位置,但是只有6和13,所以返回false。
理解这个例子我们就理解了Hash是如何进行最基本的映射的,还有就是为什么访问的时间复杂度为O(1)。
二、碰撞处理方法(2种)
在上面的例子中,我们发现有些在Hsh中很多位置可能要存两个甚至多个元素,很明显单纯的数组是不行的,这种两个不同的输入值,根据同一散列函数计算出的散列值相同的现象叫做碰撞。
那该怎么解决呢?常见的方法有:开放定址法(Java里的Threadlocal)、链地址法(Java里的ConcurrentHashMap)、再哈希法(布隆过滤器)、建立公共溢出区。后两种用的比较少,重点看前两个。
1.开放定址法
开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。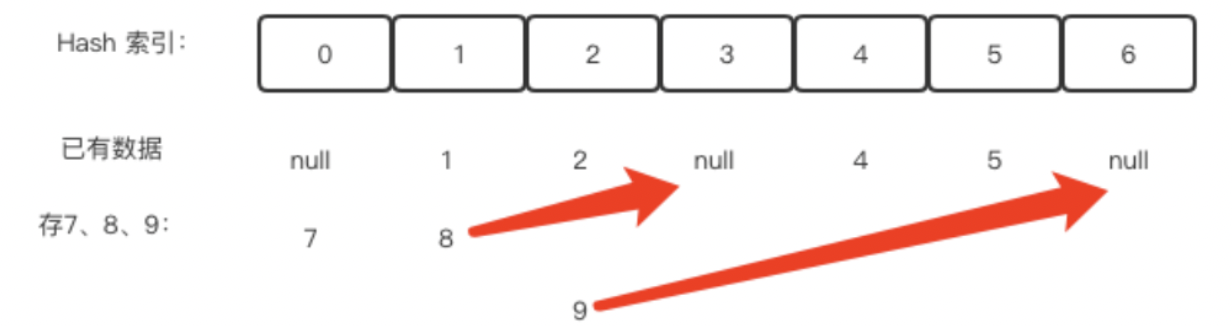
例如上面要继续存7,8,9的时候,7没问题,可以直接存到索引为0位置。8本来应该存到索引为1的位置,但是已经满了,所以继续向后找,索引3的位置是空的,所以8存到3位置。同理9存到索引6位置。
这里是否有一个疑惑:这样鸠占鹊巢的方法会不会引起混乱?比如再存3和6的话,本来自己的位置好好的,但是被外来户占领了,该如何处理呢?这个问题直到我在学习Java里的ThreadLocal才解开。具体过程可以学习一下相关内容,我们这里只说一下基本思想。ThreadLocal?有一个专门存储元素的TheadLocalMap,每次在get和set元素的时候,会先将目标位置前后的空间搜索一下,将标记为nul的位置回收掉,这样大部分不用的位置就收回来了。这就像假期后你到公司,每个人都将自己的位子附近打扫干净,结果整个工作区就很干净了。当然Hsh处理该问题的整个过程非常复杂,涉及弱引用等等,这些都是Java技术面试里的高频考点。
2.链地址法
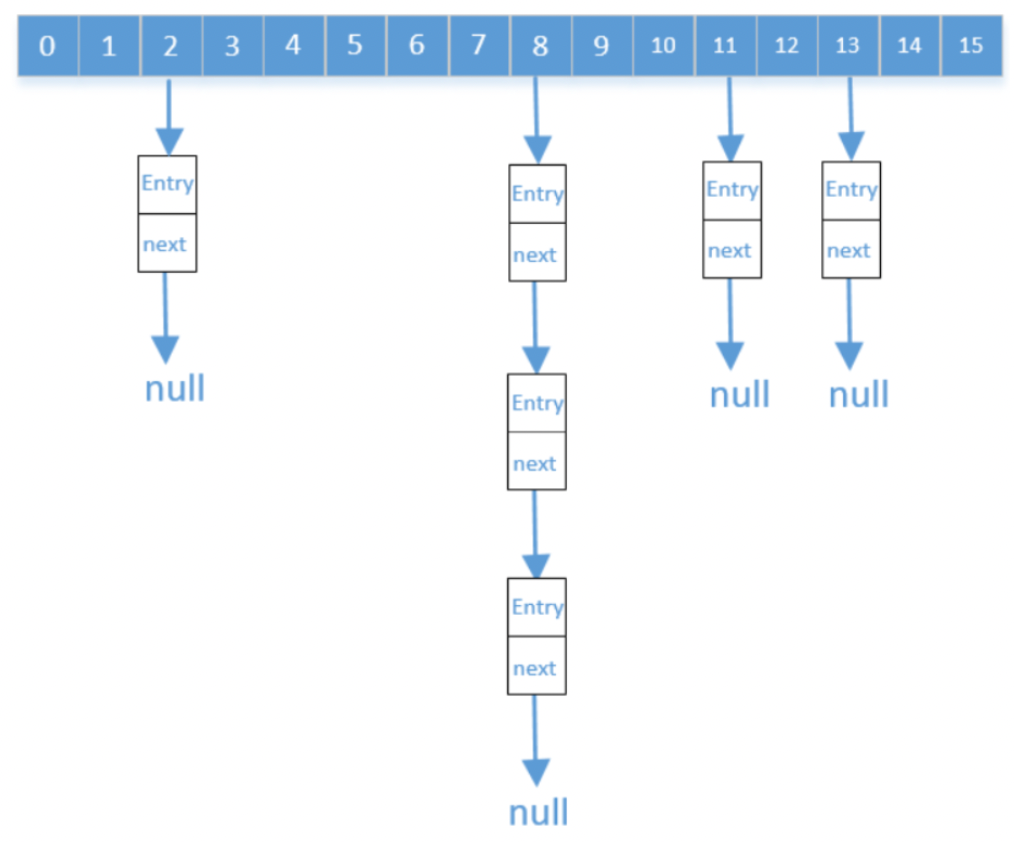
将哈希表的每个单元作为链表的头结点,所有哈希地址为的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。例如: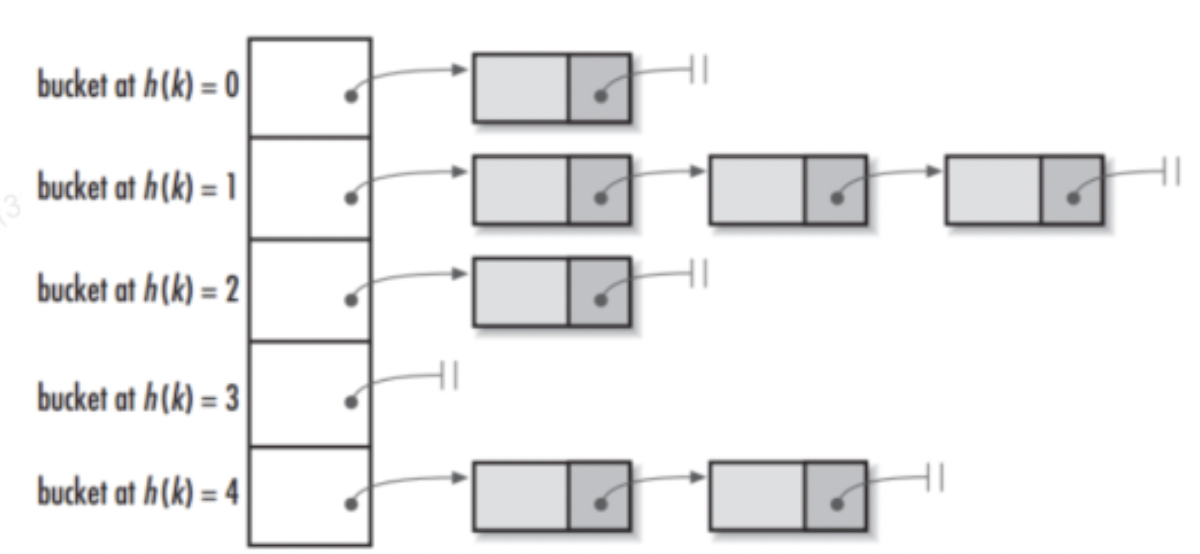
这种处理方法的问题是处理起来代价还是比较高的,要落地还要进行很多优化,例如在Java里的ConcurrentHashMap中就使用了这种方式,其中涉及元素尽量均匀、访问和操作速度要快、线程安全、扩容等很多问题。
我们来看一下下面这个Hash结构,下面的图有两处非常明显的错误,请你先想想是啥。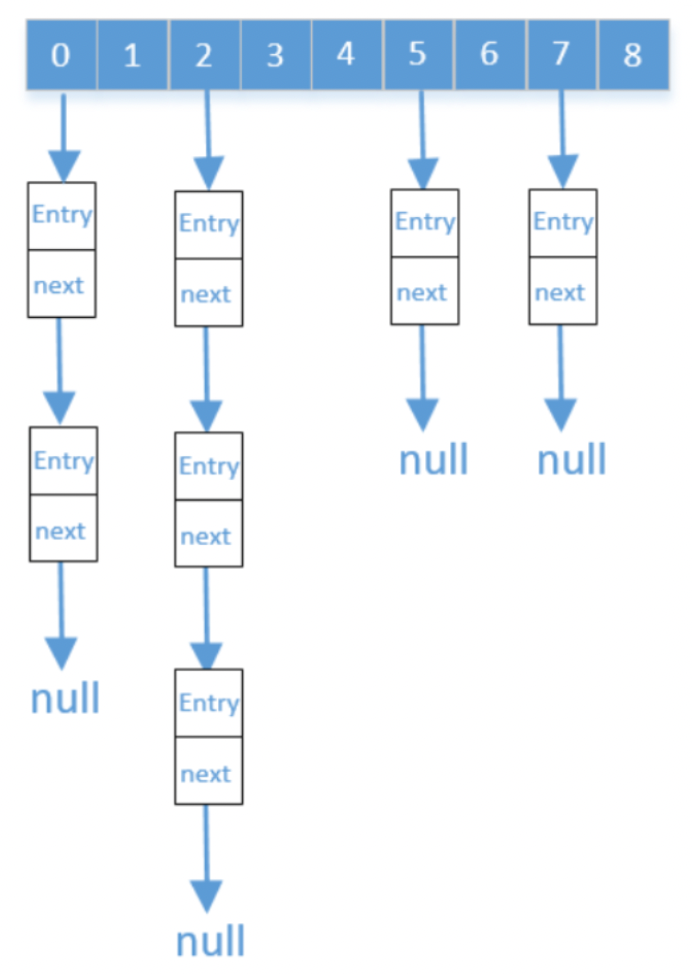
首先是数组的长度必须是2的n次幂,这里长度是9,明显有错,然后是enty的个数不能大于数组长度的75%,如果大于就会触发扩容机制进行扩容,这里明显是大于75%,正确的图应该是这样的: