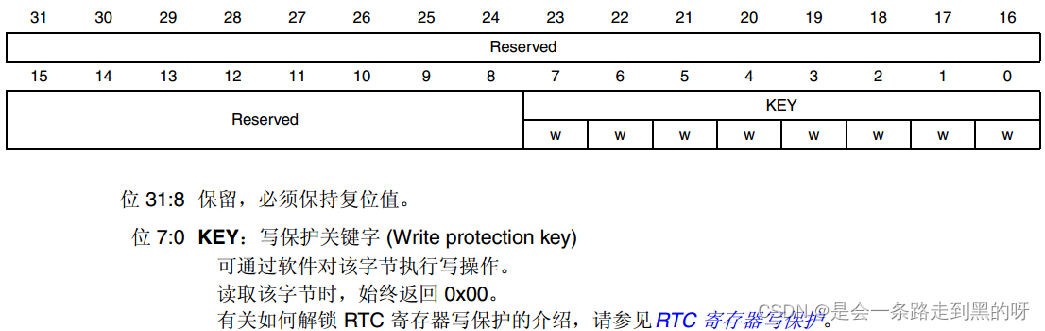
- nvidia-NeMo包含TTS的模型,开源数据
uroma转写工具介绍
-
uroman转写工具
-
N-to-M mapping 转写的规范,包含一些中文-拼音,拉丁文-读法的规则转换。字符串匹配规则下的查字典;
-
将字母对应到发音单元
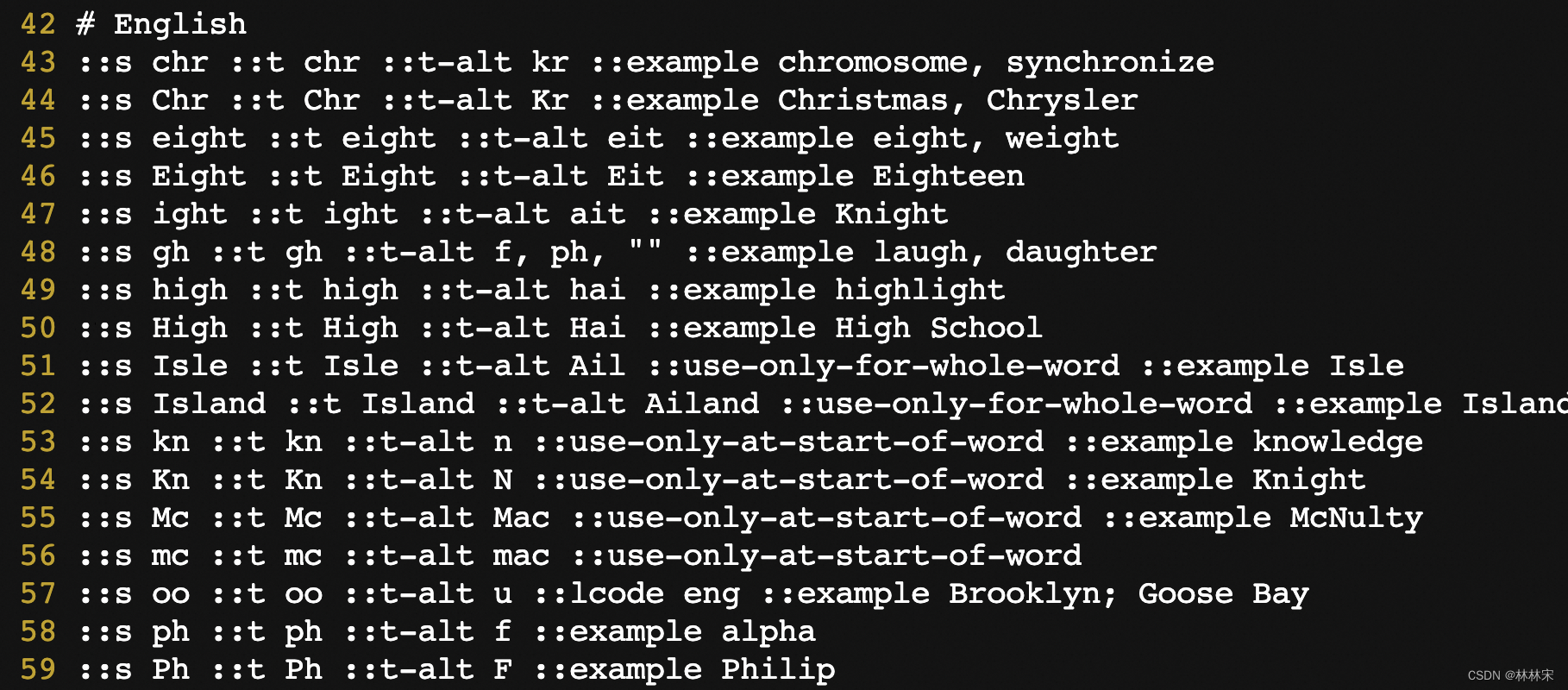
-
转写规范
- 转写过程尽量做到可逆映射;
- 忽略变音符号,比如 o u ‘ ou` ou‘ 和 o u ou ou,转写结果是一样的;
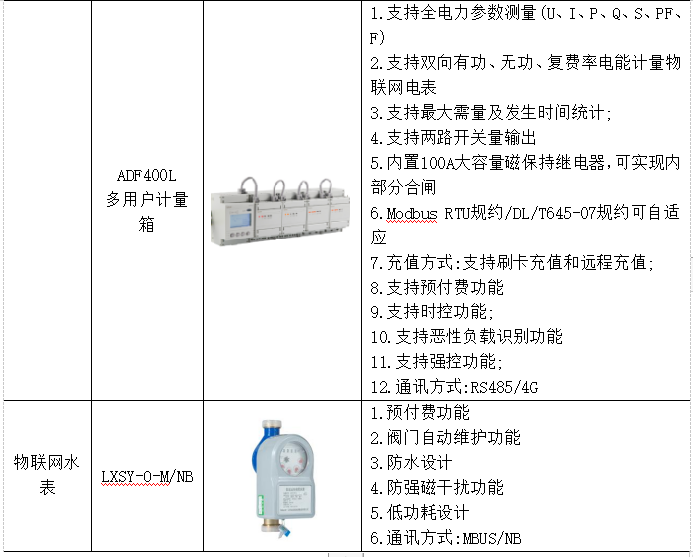
- 不会对缺乏原音的文本进行元音化
- 数字,除了0-9一一进行阿拉伯数字的对应,还会对不同语言书写格式转写到阿拉伯计数上;
- 一些基于拉丁文字的语言中的单词的拼写和发音差异很大,如果非拉丁文字中单词的相应拼写基于发音,则字符串相似性匹配会变得复杂。因此,给出替代结果

数据介绍
- 数据来源:New Testament,1000多种语言,不同的speaker(男性为主)读《新约》的26个章节,55K hours数据的录音格式是标准的;还有另外49k hours 是各种录音文本转写格式,以及同一种语言不同的口音,但是都有audio-text paired 数据;
- 语种识别:不同的口音认为是一种语言;语音合成:同一种语言,只选择一种格式;语音识别:不同的口音认为是不同的语言,标记为srp-script:latin, srp-script:cyrillic.
- 背景音乐:38%的语言有背景音乐,合成任务会remove这些有背景音乐的音频;
数据处理
-
采样率,原始文件22/24/44khz,统一重采样到16k
-
文本规范:NFKC normalization ,unicode的KC 编码;包括标点符号,括号(作者们听一些音频,发现没有读括号,于是删除)等的处理;
-
对齐问题:
a. CTC Alignment:音频是一整个章节,几十分钟,无法用transformer模型直接做对齐;将音频按照15s 长度计算后验概率,然后把后验概率拼成一个大矩阵, O ( L ∗ T ) O(L*T) O(L∗T),其中L是文本长度,T是音频长度;作者优化的算法:viterbi 算法计算最有路线时,只存储forward values for the current and the previous time-step and regularly transfer the computed backtracking matrices to CPU memory. 因此矩阵优化成 O ( L ) O(L) O(L)

b. <*>符号加入:音频开头读者一般会介绍章节内容,这些没有对应的文本;以及数字没有按照标准书写体写,手动转写比较困难,因此在章节文本的开头加入<*>符号,数字用<*>符号替代;最终处理的时候,开头的<*>符号对应,删除;句中数字<*>符号替换回去;选这个字符是因为他和HMM中的sil/OOV token都不重复; -
文本转写:本文使用uroman转写,工具将不同语言的文本转成Latin 编码;也有Unitran的编码转写,将UTF-8 encoded text 转成WorldBet(IPA)或者 X-SAMPA;本文使用uroman是因为它比Unitran更简单,实验取得结果差不多。将uroman转写的所有字母小写,最后只保留a-z以及上撇符号。
-
对齐二次处理:因为音频中,录音人会随机插入一些文本中没有的发挥,所以需要确认;训练单语言ASR,将CER>10%的扔掉;
最终筛选数据

TTS systems
- 每个语言挑选一个speaker recording,训练一个单独的VITS model,
- txt representation:如果语言的词典比较小,letter-based;比较大,使用uroma-based;