查阅了很多博客和资料,这篇文章以思路为准,详细代码不细说,都是非常简单的方法,一看就明白。具体实现稍微百度一下就能出来。仅供参考。
如题:单表数据已经达到4千万条数据,通过mybatis的分页查询效率非常低下。
当然,前提是索引什么的优化已经都存在并且命中的情况下。所以就不分析索引的问题了。
原因:mybatis分页查询会执行两次sql
第一次:select count(1) from table where ??
这一步非常慢,如果结果是万级别的数据,估计会4-5s以上,数据越多,时间逐渐增加
第二次:select * from table where ?? limit ?,? 这一步很快,就算是结果集总数达到二十多万,速度也可以保持在毫秒级别
分析结果:
第一:count()有优化空间的直接优化
第二:count()没办法优化的,只能从业务入手
总结:
第一:针对count()有优化空间的如下
(1):重写count()覆盖自带count()
如果是连表查询的速度慢,可以重写mybatis Page的count方法,具体操作就是在xml文件里面定义一个count查询方法,大概类似如下:
为什么说这个方法对于连表查询有用呢,是因为连表查询,sql比较复杂,通过自带的count肯定查询条件一致,但是自定义的话就只查询主表数量就足够了,不需要连表进行count
但是这个局限性比较大,如果条件里面有table2的条件就没办法了。
【代码里面】
page.setCountId("selectAll_COUNT");
【xml里面】
<select id="selectAll" resultType="xxxxxx">
select * from table1 left table2 on table1.userId = table2.id where ....
</select>
<select id="selectAll_COUNT" resultType="java.lang.Long">select count(1) from table1 where ....
</select>(2):缓存获取count()
这个需要看业务需求,如果业务上面对于总数实时性要求不高,或者总数变化不快的情况下可以使用。具体实现方法就是
通过设置setSearchCount=false,关闭mybatis自动查询总数的开关。
carFlowInfoPageDTOPage.setSearchCount(false);然后自定义一个查询count的方法,在接口上面添加上@cacheable注解(具体实现自行百度),如果下一次查询的条件和上次的条件一致,则直接返回结果,就不需要跟数据库进行交互。
缺点:不同的查询条件第一次查询或者缓存时间到期后再次查询肯定还是慢,而且实时性较差。但是根据系统情况来看,如果对于实时性要求不高的,可以选择使用。无伤大雅
(3):不推荐
看了很多帖子,要么就是数据库记录数据、或者来一条数据更新一下总数、或者多线程一个查询列表一个程序总数等等,这些方法都不适用于正常的待条件分页查询,可以忽略。
第二:count()没办法优化的,只能从业务入手
(1):前后端一起优化--推荐
可以跟公司的产品进行沟通,如果可以去掉总数显示,分页上面只显示上一页下一页的话,就可以用下面这个方法。比较推荐。
效果就是前后端一起优化:
首先后端设置:
carFlowInfoPageDTOPage.setSearchCount(false);
结果就是返回的page结果里面没有totalcount。
前端可以根据条件修改分页插件,一直可以点击下一页,如果当前页返回的数量<pageSize,则表示当前是最后一页。或者如果当前页查询数据为空,则把页数调整至上一页但不能<1的情况下再请求一次即可。
如下图,参考一下即可。
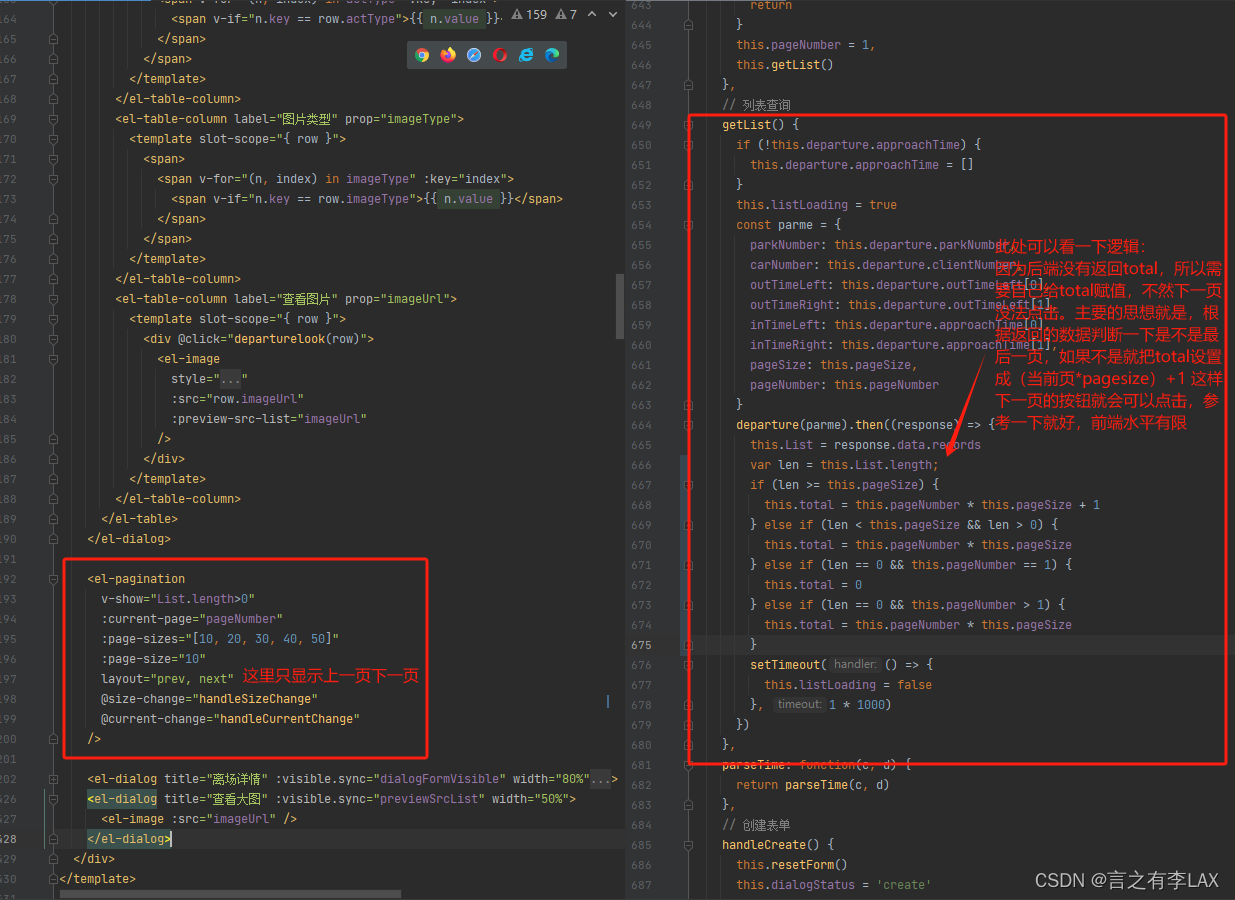
(2):异步查询加载
还是carFlowInfoPageDTOPage.setSearchCount(false); 返回结果没有totalcount
但是后端增加一个查询count的接口
也就是点击一次请求查询两个接口。list接口肯定很快返回,可以直接进行列展示,供用户操作查看等;
count接口返回较慢,分页插件下面展示loading(提示正在加载)
当然上面的方法都做了一定的妥协,彻底解决:
引入ES或其他数据库,直接彻底解决