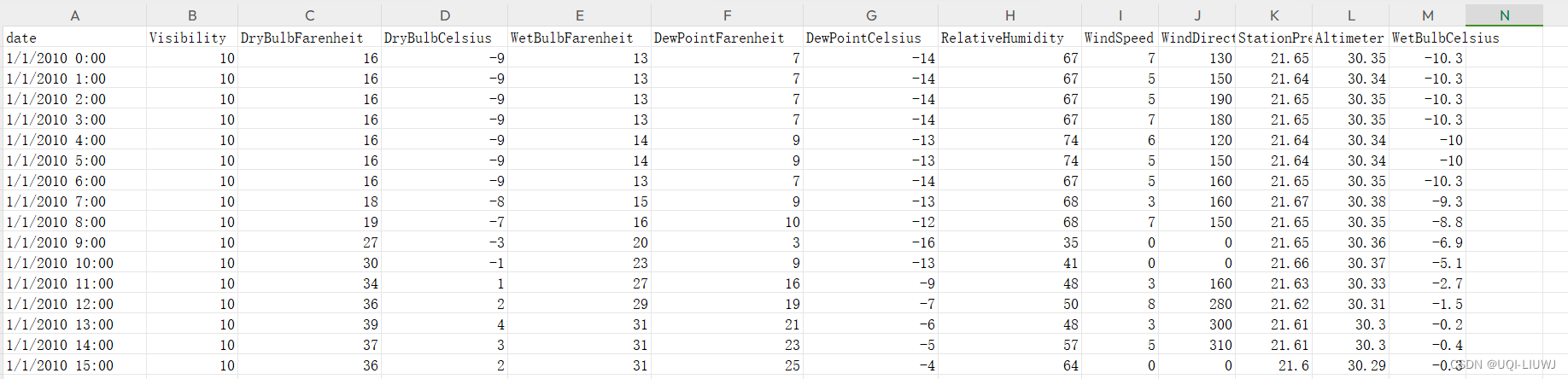
以WTH为例
import os
import numpy as np
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader
# from sklearn.preprocessing import StandardScaler
from utils.tools import StandardScaler
from utils.timefeatures import time_features
import warnings
warnings.filterwarnings('ignore')1 WTH
1.1 数据
1.2 Dataset_Custom
1.2.1 __init__
class Dataset_Custom(Dataset):
def __init__(self, root_path, flag='train', size=None,
features='S', data_path='ETTh1.csv',
target='OT', scale=True, inverse=False, timeenc=0, freq='h', cols=None):
# size [seq_len, label_len, pred_len]
# info
if size == None:
self.seq_len = 24*4*4
self.label_len = 24*4
self.pred_len = 24*4
else:
self.seq_len = size[0]
self.label_len = size[1]
self.pred_len = size[2]
#设置seq_len,label_len和pred_len
# init
assert flag in ['train', 'test', 'val']
type_map = {'train':0, 'val':1, 'test':2}
self.set_type = type_map[flag]
self.features = features
self.target = target
self.scale = scale
self.inverse = inverse
self.timeenc = timeenc
self.freq = freq
self.cols=cols
self.root_path = root_path
self.data_path = data_path
self.__read_data__()
1.2.2 __read_data__
def __read_data__(self):
self.scaler = StandardScaler()
df_raw = pd.read_csv(os.path.join(self.root_path,
self.data_path))
if self.cols:
cols=self.cols.copy()
cols.remove(self.target)
else:
cols = list(df_raw.columns); cols.remove(self.target); cols.remove('date')
df_raw = df_raw[['date']+cols+[self.target]]
#数据被重新组织,使得日期列在前,然后是其他特征列,最后是目标特征列。
#对于Weather,只有target=WetBulbCelsius和date,没有cols
num_train = int(len(df_raw)*0.7)
num_test = int(len(df_raw)*0.2)
num_vali = len(df_raw) - num_train - num_test
#数据集被划分为70%训练集、20%测试集和剩余的作为验证集。
border1s = [0, num_train-self.seq_len, len(df_raw)-num_test-self.seq_len]
border2s = [num_train, num_train+num_vali, len(df_raw)]
border1 = border1s[self.set_type]
border2 = border2s[self.set_type]
#根据是train还是test还是vali,计算这些集合的边界,即数据中的索引位置。
if self.features=='M' or self.features=='MS':
cols_data = df_raw.columns[1:]
df_data = df_raw[cols_data]
elif self.features=='S':
df_data = df_raw[[self.target]]
'''
根据self.features的值选择特征。
如果是'M'或'MS',选择除日期外的所有特征; [多变量预测多变量,多变量预测单变量]
如果是'S',只选择目标特征。 [S:单变量预测单变量]
'''
if self.scale:
train_data = df_data[border1s[0]:border2s[0]]
self.scaler.fit(train_data.values)
data = self.scaler.transform(df_data.values)
else:
data = df_data.values
df_stamp = df_raw[['date']][border1:border2]
df_stamp['date'] = pd.to_datetime(df_stamp.date)
data_stamp = time_features(df_stamp, timeenc=self.timeenc, freq=self.freq)
'''
从数据中提取时间戳,并转换成pandas的datetime对象。
使用time_features函数来提取时间相关的特征。
'''
self.data_x = data[border1:border2]
if self.inverse:
self.data_y = df_data.values[border1:border2]
else:
self.data_y = data[border1:border2]
self.data_stamp = data_stamp
'''
self.data_x: 用于模型训练的特征数据。
self.data_y: 目标数据,如果self.inverse为真,则使用原始数据,否则使用标准化后的数据。(和data_x一样)
self.data_stamp: 时间特征数据。
'''1.2.3 其他
'''
获取数据集的一个样本,其中index是样本的索引
seq_x,seq_y:特征序列,目标序列
seq_x_mark,seq_y_mark:相对应的时间特征序列
'''
def __getitem__(self, index):
s_begin = index
s_end = s_begin + self.seq_len
r_begin = s_end - self.label_len
r_end = r_begin + self.label_len + self.pred_len
seq_x = self.data_x[s_begin:s_end]
if self.inverse:
seq_y = np.concatenate([self.data_x[r_begin:r_begin+self.label_len], self.data_y[r_begin+self.label_len:r_end]], 0)
else:
seq_y = self.data_y[r_begin:r_end]
seq_x_mark = self.data_stamp[s_begin:s_end]
seq_y_mark = self.data_stamp[r_begin:r_end]
return seq_x, seq_y, seq_x_mark, seq_y_mark
'''
返回数据集中样本的总数
'''
def __len__(self):
return len(self.data_x) - self.seq_len- self.pred_len + 1
def inverse_transform(self, data):
return self.scaler.inverse_transform(data)