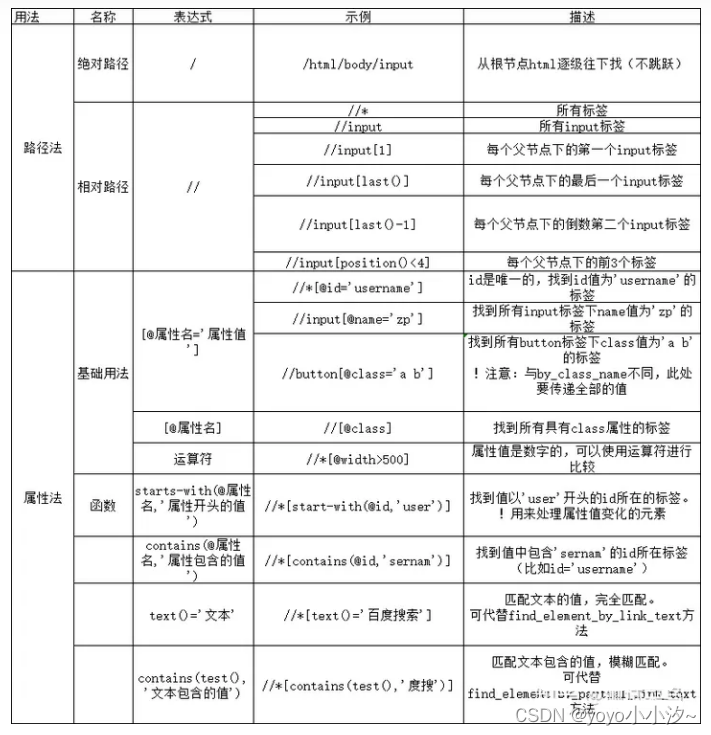
什么是xpath?
- XPath是XML的路径语言,通俗一点讲就是通过元素的路径来查找到这个标签元素
- XPath使用路径表达式在XML文档中进行导航
普通语法
注意!
1.xpath中的值用引号引起来时,在代码中要注意区分,内单外双,内双外单。
2.xapth的class的值要填写全部,注意与find_element_by_class_name的区别。
3.xpath还支持逻辑运算符and/or,多用and来缩小范围,例如//*[@id='username' and @type='text']
4.要注意xpath中//input[1]代表第一个input标签,而不是用0,与python中的下标索引不同。
- xpath轴语法
自动化测试中不常用,爬虫中常用,仅做了解。
学习网址:https://www.w3school.com.cn/xpath/xpath_axes.asp
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:485187702【暗号:csdn11】
selenium中使用xpath
为了练习,我自己想了个需求。
用selenium的xpath定位方式写一个脚本,获取微博热搜内容
步骤
1.打开微博官网https://weibo.com
2.找到热搜榜按钮位置,点击
3.找到热搜标题位置,获得文本
打开微博官网后我们找到热搜榜按钮,然后右键--检查,找到我们要点击的位置
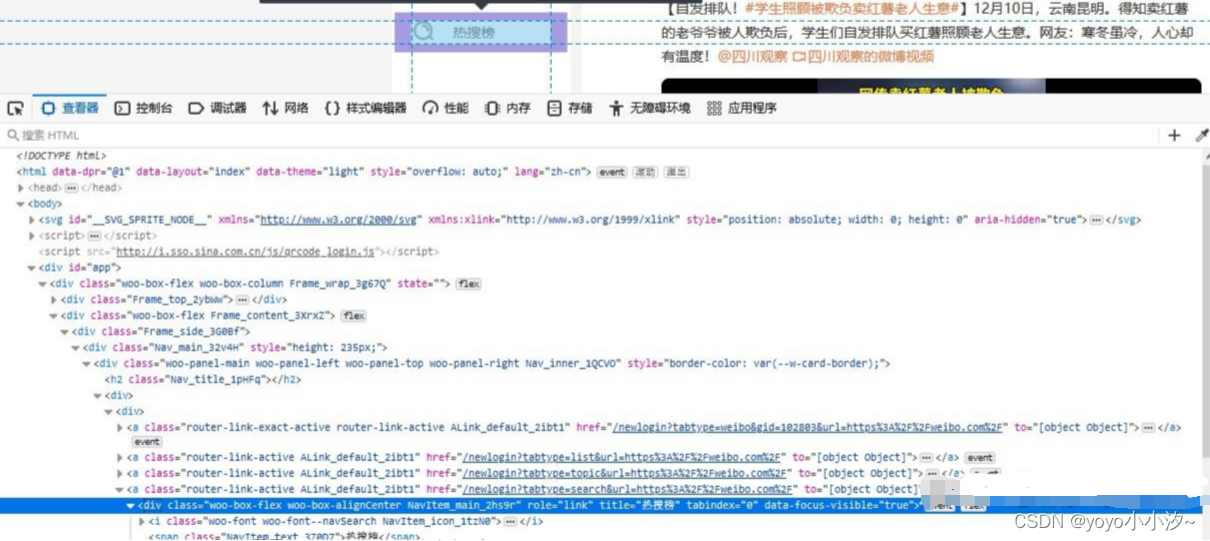
发现这个标签里的属性比较多,所以首先尝试用属性法看能不能找到
![]()
通过role='link'找到4个,不唯一。
换title试试
![]()
咦,如此简单么,找到了
接下来找热搜标题的xpath路径
先手动复制热搜榜前五标题的xpath路径
方法:选中标题位置--右键检查
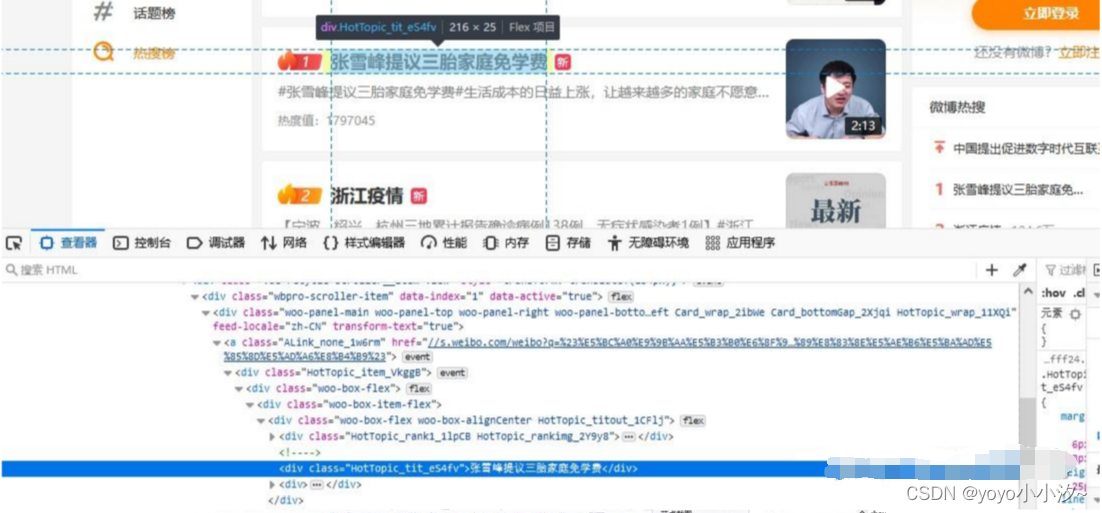
找到对应标签行后,再右键--复制--XPath
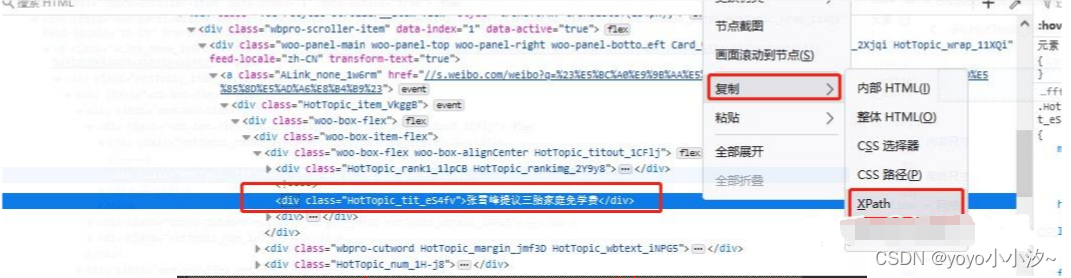
得到前五条热搜名称的xpath路径,并观察规律

然后尝试精简路径。用尽可能短的路径定位到唯一元素(因为我发现路径太长,会概率性出现定位不到元素)
根据找到的规律(变化最明显的点和最有识别度的标签名称)对路径进行简化,经过无数次的调试(我太菜了)
精简后热搜第一名的可用路径为
//main/div//div[2]//*[starts-with(@class,'HotTopic_tit_')]
ok,xpath的路径准备好之后,就可以写代码了
from selenium import webdriver
from time import sleep
driver = webdriver.Firefox()#打开浏览器
url = 'https://weibo.com'
driver.get(url)#打开微博官网
sleep(5)
driver.find_element_by_xpath("//*[@title='热搜榜']").click()#找到热搜榜并点击
for i in range(2,7):
sleep(1)
print(f'此时此刻热搜第{i-1}名为:'+driver.find_element_by_xpath(
f"//main/div//div[{i}]//*[starts-with(@class,'HotTopic_tit_')]").text)
结果如下
此时此刻热搜第1名为:张雪峰提议三胎家庭免学费
此时此刻热搜第2名为:浙江疫情
此时此刻热搜第3名为:读懂中央经济工作会议的深意
此时此刻热搜第4名为:医生建议看手机1小时后休息一下
此时此刻热搜第5名为:雪梨淘宝店铺被封
试了几次,成功率还是挺高的。
有点开心。
再整一下豆瓣的电影排行榜
from selenium import webdriver
from time import sleep
driver = webdriver.Firefox()
url = 'https:/douban.com'
driver.get(url)
driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/ul/li[2]/a').click()
#这用的完整的绝对路径
sleep(5)
driver.find_element_by_xpath("//div/ul/li/a[text()='排行榜']").click()
#找规律精简后的路径
for i in range(1,11):
sleep(2)
print(f'豆瓣排行榜第{i}名:'+driver.find_element_by_xpath(f'//table[{i}]//a[@class=""]').text)
结果如下:
豆瓣排行榜第1名:最后的决斗 / 最后决斗(港)
豆瓣排行榜第2名:毒液2 / 毒魔:血战大屠杀(港) / 猛毒2:血蜘蛛(台)
豆瓣排行榜第3名:倒数时刻 / 滴答,滴答……轰隆隆 / 梦想期限(港)
豆瓣排行榜第4名:芬奇 / 芬奇的旅程 / 生化
豆瓣排行榜第5名:不速来客 / 眼见为虚 / Knock Knock
豆瓣排行榜第6名:斯宾塞 / 斯潘塞 / 黛妃(台)
豆瓣排行榜第7名:Soho区惊魂夜 / 苏豪的最后一夜(港) / 迷离夜苏活(台)
豆瓣排行榜第8名:圣母 / 圣欲(港/台) / 圣母玛利亚
豆瓣排行榜第9名:红色通缉令 / 红色大贱谍
豆瓣排行榜第10名:古驰家族 / GUCCI名门望族(港) / Gucci:豪门谋杀案(台)
ps:这部分刚学的,所以代码中的xpath路径虽然能满足需求,但应该还有很多更优的写法,大家私下可以教教我。
总结:
- webUI的自动化元素定位是分析网页的一个过程
- 绝对路径不稳定,基本不用,前边随便一个爷爷变了,孙子就找不到了。
- 学习时先在浏览器的F12调试界面多试,确定好后再复制到代码里
- 路径法和属性法要结合使用,找到定位元素最准确且精简路径
- 属性值和网址这些东西,能复制尽量不要手敲
- 刚开始学不要过度使用‘复制Xptah’,还是要先会写,再复制。
- 根据基础用法实在定位不到元素,还有轴定位(要能想起来)。
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走! 希望能帮助到你!【100%无套路免费领取】