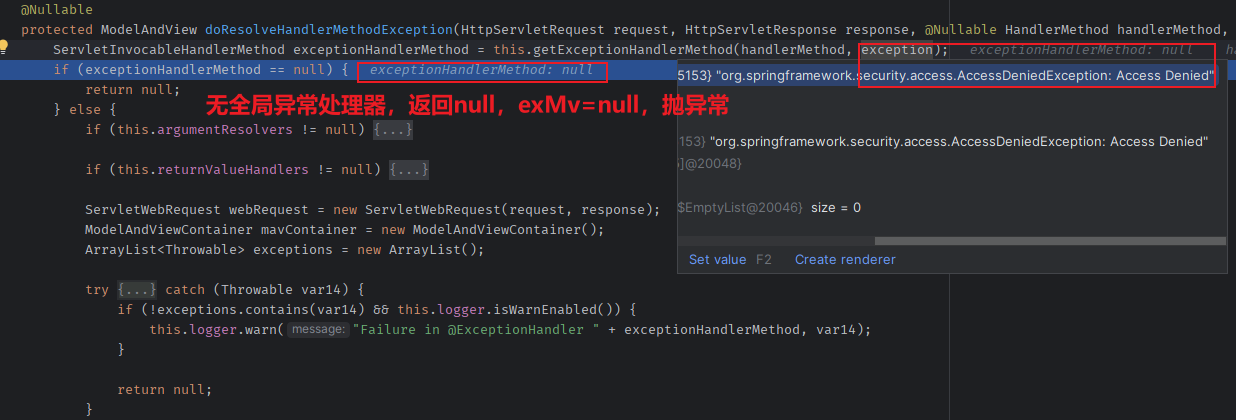
DataFrame.apply()方法主要用于调用每个Series的函数。此函数可以是一个Python的函数,或者是lambda函数。此函数可以接收一个函数作为输入,并应用于DataFrame的每一列。
以下是一些DataFrame.apply()的示例用法:
# @Author : 小红牛
# 微信公众号:wdPython
import pandas as pd
data = {'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
print('0.原始DataFrame数据'.center(40, '-'))
print(df)
print('1.lambda计算平均值'.center(40, '-'))
average = df.apply(lambda x: x.mean())
print(average)
print('2.把每列数据的值*10'.center(40, '-'))
result = df.apply(lambda x: x*10)
print(result)
print('3.sum函数计算总和'.center(40, '-'))
sum_values = df.apply(sum)
print(sum_values)
输出内容:
------------0.原始DataFrame数据-------------
A B
0 1 10
1 2 20
2 3 30
3 4 40
4 5 50
-------------1.lambda计算平均值--------------
A 3.0
B 30.0
dtype: float64
--------------2.把每列数据的值*10--------------
A B
0 10 100
1 20 200
2 30 300
3 40 400
4 50 500
--------------3.sum函数计算总和---------------
A 15
B 150
dtype: int64
2.假设我们有一个包含学生数学和英语成绩的DataFrame,我们想要计算每个学生的总分数。我们可以使用apply方法来实现这个功能。
import pandas as pd
# 创建DataFrame
print('0.原始DataFrame数据'.center(40, '-'))
df = pd.DataFrame({'Math': [90, 90, 80], 'Chinese': [80, 100, 92], 'English': [70, 60, 80]})
print(df)
# 定义计算总分数的函数
def calculate_total_score(row):
return row['Math'] + row['English']
# 使用apply方法应用函数
df['数学+英语分数'] = df.apply(calculate_total_score, axis=1)
print('1.数学+英语的分数'.center(40, '-'))
print(df)
输出内容
D:\Wdpython\environment\Scripts\python.exe D:/Wdpython/Ex/测试3.py
------------0.原始DataFrame数据-------------
Math Chinese English
0 90 80 70
1 90 100 60
2 80 92 80
---------------1.数学+英语的分数---------------
Math Chinese English 数学+英语分数
0 90 80 70 160
1 90 100 60 150
2 80 92 80 160
进程已结束,退出代码0
在上面的示例中,我们首先创建了一个包含学生数学和英语成绩的DataFrame。然后,我们定义了一个计算总分数的函数calculate_total_score,该函数接受一个行作为参数,并返回该行的数学和英语成绩之和。最后,我们使用apply方法将该函数应用于DataFrame的每一行,并将结果存储在一个新的’Total’列中。