编译工具:PyCharm
有些编译工具不用写print可以直接将数据打印出来,pycharm需要写print才会打印出来。
概念
1.特征类型
特征的类型:“离散型”和“连续型”
机器学习算法对特征的类型是有要求的,不是任意类型的特征都可以随意放入任何算法中。
通过特征变换后,数据的可解释性得到提高。
连续型特征就是具体的数值,如温度、长度
离散型分为分类型、二值型、顺序型特征
分类型
用于表示类别,每个值表示一种单独的类别,并且不同值之间没有顺序和大小之分,如"在职"、“离职”,可以用"0","1"来表示。
在数据挖掘领域中,分类型特征被称为“标称属性”。
二值型
特征值只有两种状态,如0,1;显然是分类型的,二值型特征也称为“二元型特征”或“布尔型特征”
顺序型
可以是数字也可以是对连续型特征离散化而得到如将学生的成绩划分等级A(90-100)、B(75-90)、C(60-75)
数值型
整数/浮点数
2.特征数值化练习1
将一些算法不理解的特征值转化为数值型,实现数值化
# 将一些算法不理解的特征值转化为数值型,实现数值化
import pandas as pd
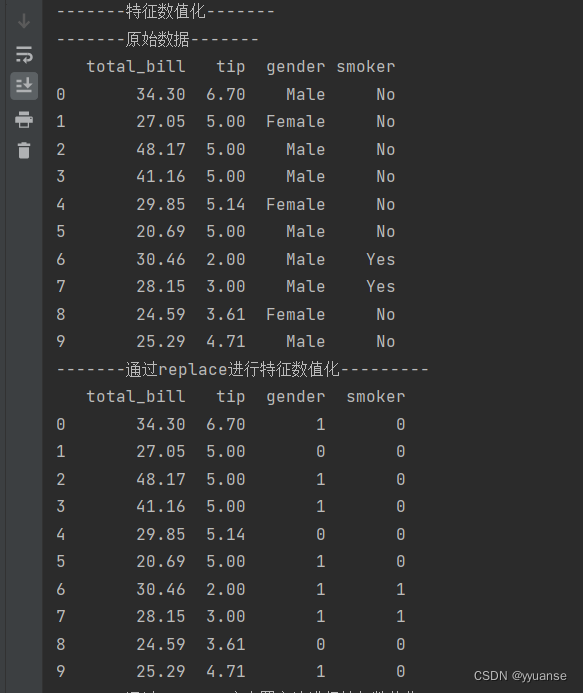
print("-------特征数值化-------")
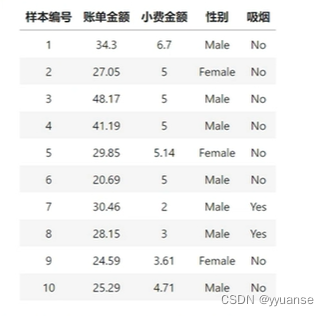
df = pd.DataFrame({
"total_bill":[34.3,27.05,48.17,41.16,29.85,20.69,30.46,28.15,24.59,25.29],
"tip":[6.7,5,5,5,5.14,5,2,3,3.61,4.71],
"gender":["Male","Female","Male","Male","Female","Male","Male","Male","Female","Male"],
"smoker":["No","No","No","No","No","No","Yes","Yes","No","No"]
})
print("-------原始数据-------")
print(df)
print("-------通过replace进行特征数值化---------")
print(df.replace({"Male": 1, "Female": 0, "Yes": 1, "No": 0}))
# 没有sklearn库的先安装,scikit-learn
print("-------通过sklearn库内置方法进行特征数值化---------")
from sklearn.preprocessing import LabelEncoder
day = ["Thur","Thur","Fri","Thur","Sun","Thur","Sun","Sat","Sun","Sun","Thur","Thur","Fri","Sun"]
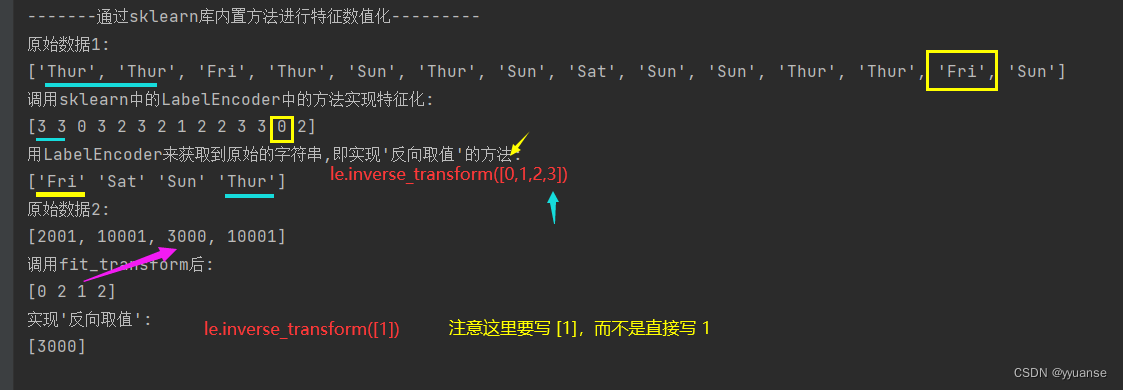
print("原始数据1: ")
print(day)
le = LabelEncoder()
print("调用sklearn中的LabelEncoder中的方法实现特征化: ")
print(le.fit_transform(day))
print("用LabelEncoder来获取到原始的字符串,即实现'反向取值'的方法: ")
day_new = le.inverse_transform([0,1,2,3]) # 这里的le已经被训练好了,所以可以取到特征化之前的数值
print(day_new)
print("原始数据2: ")
nums = [2001,10001,3000,10001]
print(nums)
print("调用fit_transform后: ")
print(le.fit_transform(nums))
print("实现'反向取值':")
print(le.inverse_transform([1])) # 写的时候不能直接写1,要写[1]
运行结果:
使用sklearn库中的内置方法
3.特征数值化练习2
某办公室电子设备数据如下
data=[‘笔记本’,‘台式本’,‘手机’,‘台式机’,‘平板电脑’]
需要用这些数据创建特征数值化模型,然后用该模型对下面的数据集进行特征变换。
data_test=[‘平板电脑’,‘手机’,‘台式机’,‘台式机’]
print()
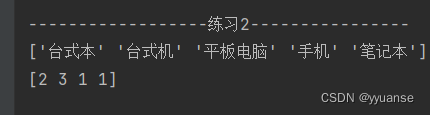
print("------------------练习2----------------")
from sklearn.preprocessing import LabelEncoder
data=['笔记本','台式本','手机','台式机','平板电脑']
data_test=['平板电脑','手机','台式机','台式机']
# 对data特征化,创建特征数值化模型
le = LabelEncoder()
le.fit(data)
# 查看类别信息
print(le.classes_)
# 用训练好的模型对新的数据进行特征化
print(le.transform(data_test))
运行结果:
4.特征二值化
sklearn库提供Binarizer可以实现二值化
from sklearn.preprocessing import Binarizer
print("-----------特征二值化------------")
import numpy as np
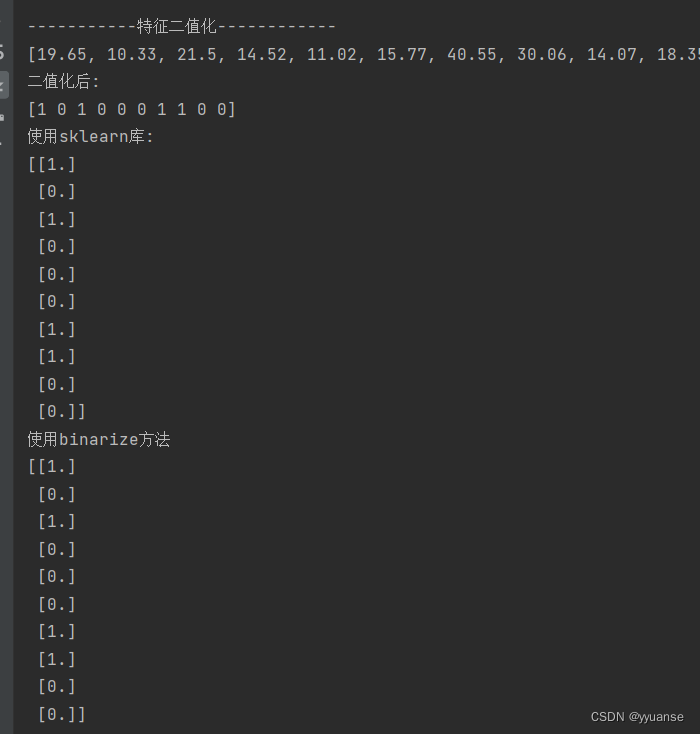
tips = [19.65,10.33,21.50,14.52,11.02,15.77,40.55,30.06,14.07,18.35]
print(tips)
# np.mean(tips)求tips数组的平均值
# np.where中三个参数,判断第一个参数为true则取第二个参数,为false取第三个参数
tips = np.where(tips>np.mean(tips),1,0)
print("二值化后: ")
print(tips)
# sklearn库中二值化模块实现二值化
from sklearn.preprocessing import Binarizer
data2 = {
'tips':[19.65,10.33,21.50,14.52,11.02,15.77,40.55,30.06,14.07,18.35],
'sex':['Male','Male','Male','Female','Male','Male','Male','Male','Male','Male']
}
df2 = pd.DataFrame(data2,columns=['tips','sex'])
print("使用sklearn库: ")
# average = np.mean(data2['tips'])
average = df2['tips'].mean()
# 设置阈值
bn = Binarizer(threshold=average)
# 需要注意的是,不可直接这样子写
# result = bn.fit_transform(df2['tips'])
# df2[['tips']]返回的是一个DataFrame对象,是二位数据
# df2['tips']是一维数据
data_temp = df2[['tips']]
result = bn.fit_transform(data_temp)
print(result)
# 使用binarize方法
print("使用binarize方法")
from sklearn.preprocessing import binarize
fbin = binarize(df2[['tips']],threshold=df2['tips'].mean())
print(fbin)
使用sklearn库自带的Binarizer实现二值化需要注意的点
sklearn需要传入一个二维数据,但是df2[‘tips’]得到的其实是一个一维的数据,可以通过以下方法将一个一维的数据转化为二维的数据使用(一行变为一列 1xm 变为 mx1)。
# 一维数据转变为二维的数据
# df2[['tips']]返回的是一个DataFrame对象,是二位数据
# df2['tips']是一维数据
tra1 = df2['tips']
tra2 = df2[['tips']]
tra3 = df2['tips'].values.reshape((-1,1)).shape
print(tra1)
print(type(tra1))
print(tra2)
print(type(tra2))
print(tra3)
print(type(tra3))