前面我们已经针对LinkedList和ArrayList的底层原理进行了具体研究讨论,大家可以跳链接阅读哦~
再探Java集合系列—ArrayList-CSDN博客
再探Java集合系列—LinkedList-CSDN博客
HashMap有哪些特征呢?
- value可以重复,key不能重复,允许null键和null值(如果新添加key-value的Map中已经存在重复的key,那么新添加的value就会覆盖该key原来对应的value)
- 不能保证key-value对的顺序
- 如果添加相同的key,则会覆盖原来的key-val,等同于修改
- 没有实现同步,因此线程不安全,方法没有做同步互斥操作,
如何使用HashMap呢?
Map<k,v> map =new HashMap<k,v>();
Map是一种键-值对(key-value)集合,Map中每一个元素都包含一个键对象和一个值对象。
元素:键-值对整体
因为Map中的key和value是不允许使用基本类型的,那为什么呢?
Java中的基本类型和包装类型之间存在自动装箱(autoboxing)和拆箱(unboxing)的过程。当我们将基本类型的值放入Map中时,Java会自动将其转换为对应的包装类型;当我们从Map中取出包装类型的值时,Java会自动将其转换为对应的基本类型。这个过程会带来一些性能上的损耗,特别是在大量数据操作时
Map有哪些方法?
- put(key,value):添加数据
- get(key,value):根据key取值
- containsKey(key):判断当前的map集合是否包含指定的key
- containsValue(value):判断当前的map集合是否包含指定的value
- clear:清空集合
- keySet():获取map集合的key的集合
- values():获取集合的所有value的值
- for(String key:keys):遍历map集合
实战演练
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class HashMapTest {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<String,Integer>();
//添加数据
map.put("b",1);
map.put("c",2);
map.put("e",2);
System.out.println(map); //输出结果:{b=1, c=2, e=2}
//根据key取值
System.out.println(map.get("b")); //输出结果:1
//根据key移除键值对
map.remove("c");
System.out.println(map); //输出结果:{b=1, e=2}
//map集合的长度
System.out.println(map.size()); //输出结果:2
//判断当前的map集合是否包含指定的key
System.out.println(map.containsKey("b")); //输出结果:true
//判断当前的map集合是否包含指定的Value(书写敏感,加双引号和不加双引号的区别)
System.out.println(map.containsValue(1)); //输出结果:true
System.out.println(map.containsValue("1")); //输出结果:false
//清空集合
//map.clear();
//获取map集合的key的集合
map.keySet();
//获取集合的所有value值
map.values();
//获取map集合的key的集合
Set<String> keys = map.keySet();
//遍历map集合
// 第一种方式:for循环
for(String key:keys){
System.out.println("key:"+key+",value:"+map.get(key));
}
//第二种方式:通过map.entrySet();遍历map集合
Set<Map.Entry<String,Integer>> entrys = map.entrySet();
for (Map.Entry<String,Integer> en:entrys){
System.out.println("key:"+en.getKey()+",value:"+en.getValue());
}
}
}数据结构
jdk1.8前:数组+链表 无序,头插
jdk1.8 :数组+链表+红黑树 无序,尾插

底层原理
实例化HashMap
在创建HashMap对象的时候知识初始化一些参数

为什么默认初始容量为16?
匹配硬件设计
大量数据测试,确定基本参数配置
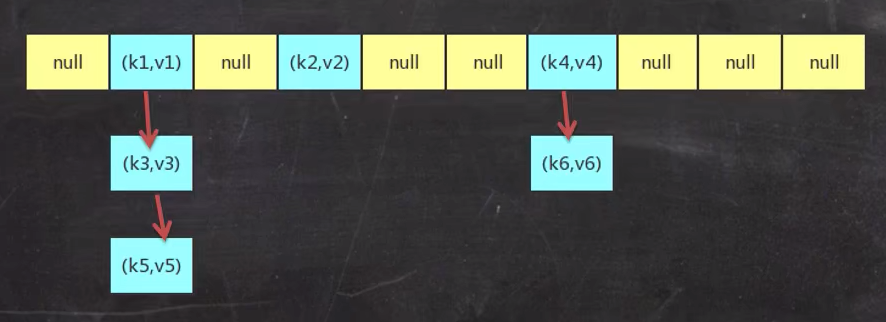
增加元素—put

(图片来源于网上)
当我们在put添加元素的时候,当多个元素映射到了同一个位置,hashmap中采用单链表的形式链接每一个元素,在jdk7使用头插法,jdk8开始使用尾插法,同一个位置会将要插入的新元素放在链表的头部。并且总是会判断当前table的容量是否满足可使用范围

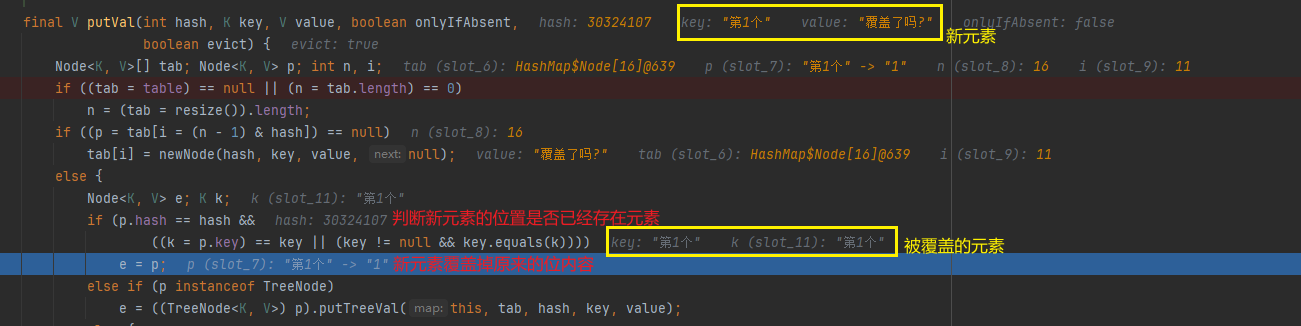
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; //n为table容量,i为下标
if ((tab = table) == null || (n = tab.length) == 0) //如果table为null 或者 table长度==0
n = (tab = resize()).length; //进行第一次扩容,n为第一次扩容后的table长度
if ((p = tab[i = (n - 1) & hash]) == null) //计算节点要插入的位置,如果p为null表示这个位置为空,则创建一个新节点插入
tab[i] = newNode(hash, key, value, null); //在table表的置顶索引位置处插入新节点
else { //否则,说明要映射的索引位置已经存在了元素
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//判断要插入的节点是否已存在,如果存在则直接覆盖原来的key-value
e = p;
else if (p instanceof TreeNode) //判断该链是不是红黑树
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { //否则,不是红黑树
for (int binCount = 0; ; ++binCount) { //遍历该链表表
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //判断该链表长度是大于8则转换为红黑树进行处理
treeifyBin(tab, hash);
break;
}
//如果key已经存在则直接覆盖value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//直接覆盖
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//超过最大容量则扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}如何确定key的位置的?(哈希函数)
先计算出key对应的hashcode(32位的int类型数),将hashcode的高16位和低16位进行异或运算(相同为0,不同为1)
Key值相同会覆盖
对于HashMap来说key必须是唯一的,插入的时候如果已经存在相同的key则会把原来的值覆盖。如下面的例子

无序插入
前面说到了HashMap可以插入key为null的键值对,我们模拟一下看看:我在put的时候最后一个元素的时候key和value都为null,但输出结果来看key为null的键值对是在集合的第一个,因此我们可以总结出HashMap插入顺序是无序的

HashMap如何解决哈希冲突的?
将相同哈希值的键值对通过链表(拉链法)+红黑树的形式存放起来
扩容机制——resize()
思想:扩容数组容量+重新计算hash值
什么时候需要扩容?
table容量>=容量*加载因子(0.75)
第一次扩容:16*0.75=12,当临界值为12的时候
![]()
,第一次扩容之后的table容量为 32,临界值为24
第二次开始及之后:容量为原来容量的2倍,临界值为原来的2倍,第二次扩容后table容量为64,临界值为48,依次类推

为什么加载因子是0.75?

必须是2的几次幂,当加载因子选择了0.75就可以保证它与容量的乘积为证书
什么时候会由链表变成红黑树?(树化思想)
容量先扩容到64,并且链表长度超过 8 的时候,会将链表转化为红黑树来提高查询效率
扩容的流程?
通过 resize 方法来实现的
- 将临界值修改为原来临界值的2倍
- 将table容量变为原来的table容量的2倍
- 创建新数组
- 遍历旧数组,将旧数组中的元素复制到新数组中
-
- 确定在新数组中的位置:hashcode / table容量
- 如果新位置已经有元素:当前元素添加到链表的末尾
- 如果链表长度>8,转成红黑树
注意:在jdk8中扩容的时候会保持链表原来的顺序
存在什么问题?
①、线程安全问题
- 多线程下扩容会死循环
- 多线程下 put 会导致元素丢失
- put 和 get 并发时会导致 get 到 null
解决方案:使用ConcurrentHashMap
整个集合是这一个(table数组)
对node节点的共享变量使用volatile修饰保证可见性

ConcurrentHashMmap在第一次进行put操作的时候才会对进行初始化,在初始化node节点的过程中会调用initTable 方法,判断到如果有其他的线程正在进行初始化则调用yield()让出cpu,并且修改状态为正在初始化状态

CAS(自旋)
②、无序插入
hashmap插入的元素是无序的,如果想要顺序可以使用LinkedhashMap,并且LinkedHashMap继承了HashMap