经典策略梯度算法
DDPG算法
DDPG 算法被提出的初衷其实是 DQN 算法的一个连续动作空间版本扩展。深度确定性策略梯度算法( deep deterministic policy gradient,DDPG),是一种确定性的策略梯度算法。
由于DQN算法中动作是通过贪心策略或者argmax的方式从Q函数间接得到。要想适配连续动作空间,考虑将选择动作的过程编程一个直接从状态映射到具体动作的函数 μ θ ( s ) \mu_\theta (s) μθ(s),也就是actor网络中求解Q函数以及贪心选择动作这两个过程合并为一个函数。Actor 的任务就是寻找这条曲线的最高点,并返回对应的横坐标,即最大 Q 值对应的动作。
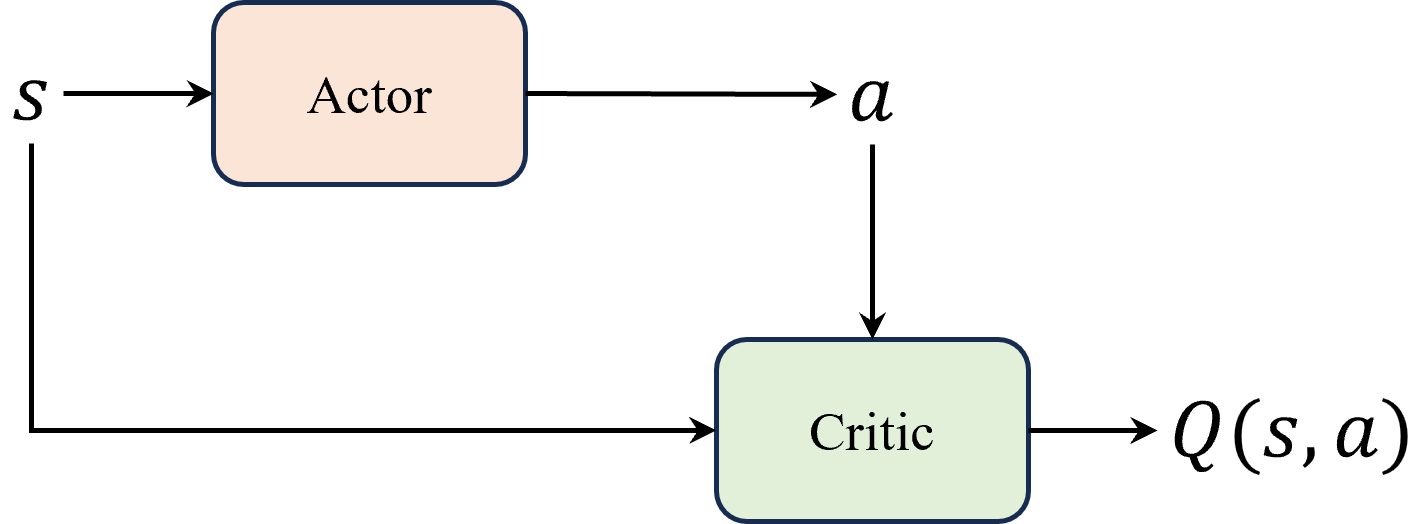
这里相当于是把 DQN 算法中 ε − greedy \varepsilon-\text{greedy} ε−greedy策略函数部分换成了 Actor 。注意 Actor 网络 μ θ ( s ) \mu_\theta (s) μθ(s) 与输出概率分布的随机性策略( stochastic policy )不同,输出的是一个值,因此也叫做确定性策略( deterministic policy )。
在强化学习基础算法的研究改进当中,基本无外乎几个亘古不变的主题:首先是如何提高对值函数的估计,保证其准确性,即尽量无偏且低方差,例如最开始的用深度神经网络替代简单的Q表、结合蒙特卡洛和时序差分的 TD(λ) 、引入目标网络以及广义优势估计等等;其次是如何提高探索以及平衡探索-利用的问题,尤其在探索性比较差的确定性策略中,例如 DQN 和 DDPG 算法都会利用各种技巧来提高探索,例如经验回放、 ε − greedy \varepsilon-\text{greedy} ε−greedy 策略、噪声网络等等。这两个问题是强化学习算法的基础核心问题,希望能够给读者在学习和研究的过程中带来一定的启发。
DDPG算法优缺点:
DDPG 算法的优点主要有:
- 适用于连续动作空间:DDPG 算法采用了确定性策略来选择动作,这使得它能够直接处理连续动作空间的问题。相比于传统的随机策略,确定性策略更容易优化和学习,因为它不需要进行动作采样,缓解了在连续动作空间中的高方差问题。
- 高效的梯度优化:DDPG 算法使用策略梯度方法进行优化,其梯度更新相对高效,并且能够处理高维度的状态空间和动作空间。同时,通过 Actor-Critic 结构,算法可以利用值函数来辅助策略的优化,提高算法的收敛速度和稳定性。
- 经验回放和目标网络:这是老生常谈的内容了,经验回放机制可以减少样本之间的相关性,提高样本的有效利用率,并且增加训练的稳定性。目标网络可以稳定训练过程,避免值函数估计和目标值之间的相关性问题,从而提高算法的稳定性和收敛性。
DDPG缺点:
- 只适用于连续动作空间:这既是优点,也是缺点。
- 高度依赖超参数:DDPG 算法中有许多超参数需要进行调整,除了一些 DQN的算法参数例如学习率、批量大小、目标网络的更新频率等,还需要调整一些 OU 噪声的参数 调整这些超参数并找到最优的取值通常是一个挑战性的任务,可能需要大量的实验和经验。
- 高度敏感的初始条件:DDPG 算法对初始条件非常敏感。初始策略和值函数的参数设置可能会影响算法的收敛性和性能,需要仔细选择和调整。
- 容易陷入局部最优:由于采用了确定性策略,可能会导致算法陷入局部最优,难以找到全局最优策略。为了增加探索性,需要采取一些措施,如加入噪声策略或使用其他的探索方法。
TD3算法是在DDPG的基础上进行改进,主要是以下三点改进:一是 双 Q 网络,体现在名字中的 twin,二是 延迟更新,三是 噪声正则( noise regularisation )
双Q网络的思想:在 DDPG 算法中的 Critic 网络上再加一层,这样就形成了两个 Critic 网络,计算 TD 误差的时候,就可以取两个Q值中较小的那个。
延迟更新:在训练中 Actor 的更新频率要低于 Critic 的更新频率。在学习过程中,Critic 是不断更新的,可以想象一下,假设在某个时刻 Actor 好不容易达到一个最高点,这个时候 Critic 又更新了,那么 Actor 的最高点就被打破了,这样一来 Actor 就会不断地追逐 Critic,这样就会造成误差的过分累积,进而导致 Actor 的训练不稳定,甚至可能会发散。可以在训练中让 Actor 的更新频率低于 Critic 的更新频率,这样一来 Actor 的更新就会比较稳定,不会受到 Critic 的影响,从而提高算法的稳定性和收敛性。
噪声正则:目标策略平滑正则化,可以给 Critic 引入一个噪声提高其抗干扰性,这样一来就可以在一定程度上提高 Critic 的稳定性,从而进一步提高算法的稳定性和收敛性。
练习题
- DDPG 算法是 off-policy 算法吗?为什么?
DDPG 算法是一个 off-policy 的算法,原因是因为它使用了一个确定性的策略,而不是一个随机的策略。DDPG 通过 off-policy 的方式来训练一个确定性策略,这样可以增强探索能力,同时也可以利用经验回放和目标网络的技巧来提高稳定性和收敛速度。
- 软更新相比于硬更新的好处是什么?为什么不是所有的算法都用软更新?
软更新可以使目标网络的参数变化更平滑,避免了目标标签的剧烈波动,从而提高了算法的稳定性和收敛性。
可以使目标网络更接近当前网络,从而减少了目标网络和当前网络之间的偏差,提高了算法的性能。
软更新需要在每次迭代中更新目标网络,这会增加计算的开销,而硬更新只需要在固定的间隔中更新一次目标网络,更节省资源。可能不适用于一些基于离散动作空间的算法,如DQN,因为这些算法需要一个稳定的目标网络来提供一个清晰的目标,而软更新会导致目标网络不断变化
- 相比于DDPG 算法,TD3 算法做了哪些改进?请简要归纳。
一是 双 Q 网络,体现在名字中的 twin,二是 延迟更新,三是 噪声正则
- TD3 算法中 Critic 的更新频率一般要比 Actor 是更快还是更慢?为什么?
TD3 算法中 Critic 的更新频率一般要比 Actor 是更快的.Critic 的更新可以使目标网络的参数变化更平滑,避免了目标标签的剧烈波动,从而提高了算法的稳定性和收敛性。
PPO算法
不同于 DDPG 算法,PPO 算法是一类典型的 Actor-Critic 算法,既适用于连续动作空间,也适用于离散动作空间。PPO 算法的主要思想是通过在策略梯度的优化过程中引入一个重要性权重来限制策略更新的幅度,从而提高算法的稳定性和收敛性。
重要性采样
是一种估计随机变量的期望或者概率分布的统计方法。它的原理也很简单,假设有一个函数 f ( x ) f(x) f(x),需要从分布 p ( x ) p(x) p(x) 中采样来计算其期望值,但是在某些情况下我们可能很难从 p ( x ) p(x) p(x) 中采样,这个时候我们可以从另一个比较容易采样的分布 q ( x ) q(x) q(x) 中采样,来间接地达到从 p ( x ) p(x) p(x) 中采样的效果。
E p ( x ) [ f ( x ) ] = ∫ a b f ( x ) p ( x ) q ( x ) q ( x ) d x = E q ( x ) [ f ( x ) p ( x ) q ( x ) ] (12.1) \tag{12.1} E_{p(x)}[f(x)]=\int_{a}^{b} f(x) \frac{p(x)}{q(x)} q(x) d x=E_{q(x)}\left[f(x) \frac{p(x)}{q(x)}\right] Ep(x)[f(x)]=∫abf(x)q(x)p(x)q(x)dx=Eq(x)[f(x)q(x)p(x)](12.1)
这样一来原问题就变成了只需要从 q ( x ) q(x) q(x) 中采样,然后计算两个分布之间的比例 中采样,然后计算两个分布之间的比例 中采样,然后计算两个分布之间的比例\frac{p(x)}{q(x)}$即可,这个比例称之为重要性权重。
不难看出,当 q ( x ) q(x) q(x)越接近 p ( x ) p(x) p(x) 的时候,方差就越小,也就是说重要性权重越接近于 1 的时候,反之越大。
而策略梯度算法的高方差主要来源于 Actor 的策略梯度采样估计,PPO 算法的核心思想就是通过重要性采样来优化原来的策略梯度估计。
本质上 PPO 算法就是在 Actor-Critic 算法的基础上增加了重要性采样的约束而已,从而确保每次的策略梯度估计都不会过分偏离当前的策略,也就是减少了策略梯度估计的方差,从而提高算法的稳定性和收敛性。
PPO 算法究竟是 o n − p o l i c y on-policy on−policy 还是 o f f − p o l i c y off-policy off−policy 的呢?有读者可能会因为 PPO 算法在更新时重要性采样的部分中利用了旧的 Actor 采样的样本,就觉得 PPO 算法会是 o f f − p o l i c y off-policy off−policy 的。实际上虽然这批样本是从旧的策略中采样得到的,但我们并没有直接使用这些样本去更新我们的策略,而是使用重要性采样先将数据分布不同导致的误差进行了修正,即是两者样本分布之间的差异尽可能地缩小。换句话说,就可以理解为重要性采样之后的样本虽然是由旧策略采样得到的,但可以近似为从更新后的策略中得到的,即我们要优化的 Actor 和采样的 Actor 是同一个,因此 PPO 算法是 on-policy 的。
练习题
- 为什么 DQN 和 DDPG 算法不使用重要性采样技巧呢?
DQN 和 DDPG 算法虽然都是 off-policy 的,但是它们的目标策略都是确定性的,即给定状态,动作是唯一确定的。这样的话,重要性采样的比例不是 0,就是 1/p,其中 p 是采样策略的概率。这样的重要性采样没有意义,也没有必要。
- PPO 算法原理上是 on-policy 的,但它可以是 off-policy 的吗,或者说可以用经验回放来提高训练速度吗?为什么?(提示:是可以的,但条件比较严格)
可以的。但条件比较严格
数据的采样策略和目标策略之间的差异不能太大,否则会导致重要性采样的比例过大或过小,影响梯度的估计。
数据的采样策略和目标策略之间的 KL 散度不能超过一个阈值,否则会导致目标函数的近似失效,影响优化的效果。
数据的采样策略和目标策略之间的相似度不能太低,否则会导致策略的收敛速度变慢,影响学习的效率。
- PPO 算法更新过程中在将轨迹样本切分个多个小批量的时候,可以将这些样本顺序打乱吗?为什么?
可以将这些样本顺序打乱。
将样本顺序打乱可以增加数据的多样性,避免因为样本之间的相关性而影响学习的效果。也可以减少因为样本顺序不同而导致的策略更新的不一致性,提高学习的稳定性。
- 为什么说重要性采样是一种特殊的蒙特卡洛采样?
允许在复杂问题中利用已知的简单分布进行采样,从而避免了直接采样困难分布的问题,同时通过适当的权重调整,可以使得蒙特卡洛估计更接近真实结果。
SAC算法
SAC 算法是一种基于最大熵强化学习的策略梯度算法,它的目标是最大化策略的熵,从而使得策略更加鲁棒。SAC 算法的核心思想是,通过最大化策略的熵,使得策略更加鲁棒。
确定性策略是指在给定相同状态下,总是选择相同的动作,随机性策略则是在给定状态下可以选择多种可能的动作。
而确定性与随机性优缺点:
确定性策略:
- 优势:稳定性且可重复性。由于策略是确定的,因此可控性也比较好,在一些简单的环境下,会更容易达到最优解,因为不会产生随机性带来的不确定性,实验也比较容易复现。
- 劣势:缺乏探索性。由于策略是确定的,因此在一些复杂的环境下,可能会陷入局部最优解,无法探索到全局最优解,所以读者会发现目前所有的确定性策略算法例如 DQN 、DDPG 等等,都会增加一些随机性来提高探索。此外,面对不确定性和噪音的环境时,确定性策略可能显得过于刻板,无法灵活地适应环境变化。
随机性策略:
- 优势:更加灵活。由于策略是随机的,这样能够在一定程度上探索未知的状态和动作,有助于避免陷入局部最优解,提高全局搜索的能力。在具有不确定性的环境中,随机性策略可以更好地应对噪音和不可预测的情况。
境变化。
随机性策略:
- 优势:更加灵活。由于策略是随机的,这样能够在一定程度上探索未知的状态和动作,有助于避免陷入局部最优解,提高全局搜索的能力。在具有不确定性的环境中,随机性策略可以更好地应对噪音和不可预测的情况。
- 劣势:不稳定。正是因为随机,所以会导致策略的可重复性太差。另外,如果随机性太高,可能会导致策略的收敛速度较慢,影响效率和性能。