文章目录
- pandas-profiling
- ydata-profiling
- ydata-profiling实际应用iris鸢尾花数据集分析
pandas-profiling
pandas_profiling 官网(https://pypi.org/project/pandas-profiling/)大概在23年4月前发出如下公告:
Deprecated 'pandas-profiling' package, use 'ydata-profiling' instead
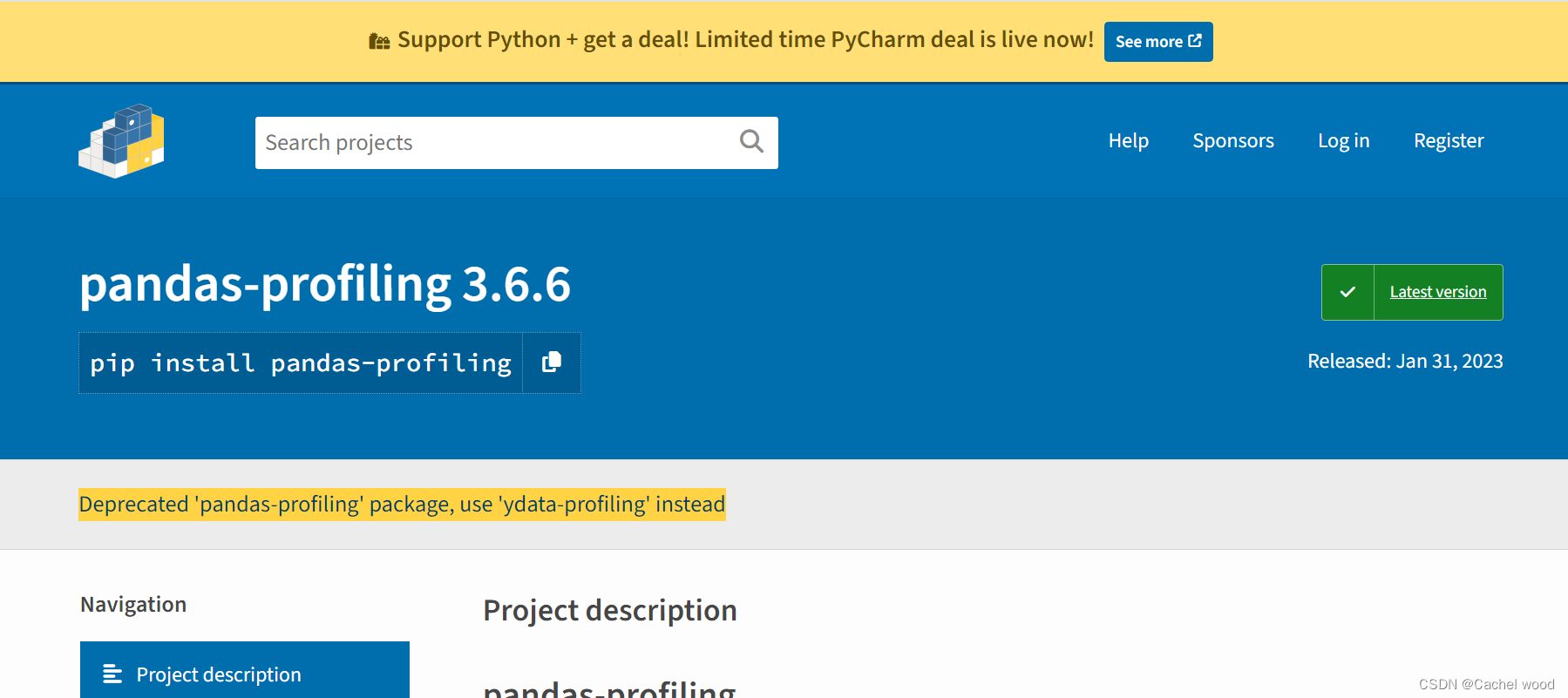
意味着pandas-profiling不能再用啦,要改用ydata-profiling。
所以不用再找更改pandas-profiling版本等相关的教程,直接拥抱新版本的 ydata-profiling即可,功能比原来的更强大。
ydata-profiling
ydata-profiling的主要目标是提供一种简洁而快速的探索性数据分析(EDA)体验。就像pandas中的df.describe()函数一样,ydata-profiling可以对DataFrame进行扩展分析,并允许将数据分析导出为不同格式,例如html和json。
该软件包输出了一个简单而易于理解的数据集分析结果,包括时间序列和文本数据。
- 安装
pip install ydata-profiling
- 使用方式
import numpy as np
import pandas as pd
from ydata_profiling import ProfileReport
df = pd.DataFrame(np.random.rand(100, 5), columns=['a','b','c','d','e'])
profile = ProfileReport(df, title="Profiling Report")
- 输出结果
一些关键属性:
类型推断 (Type inference):自动检测列的数据类型(分类、数值、日期等)
警告 (Warning):对数据中可能需要处理的问题/挑战的概要(缺失数据、不准确性、偏斜等)
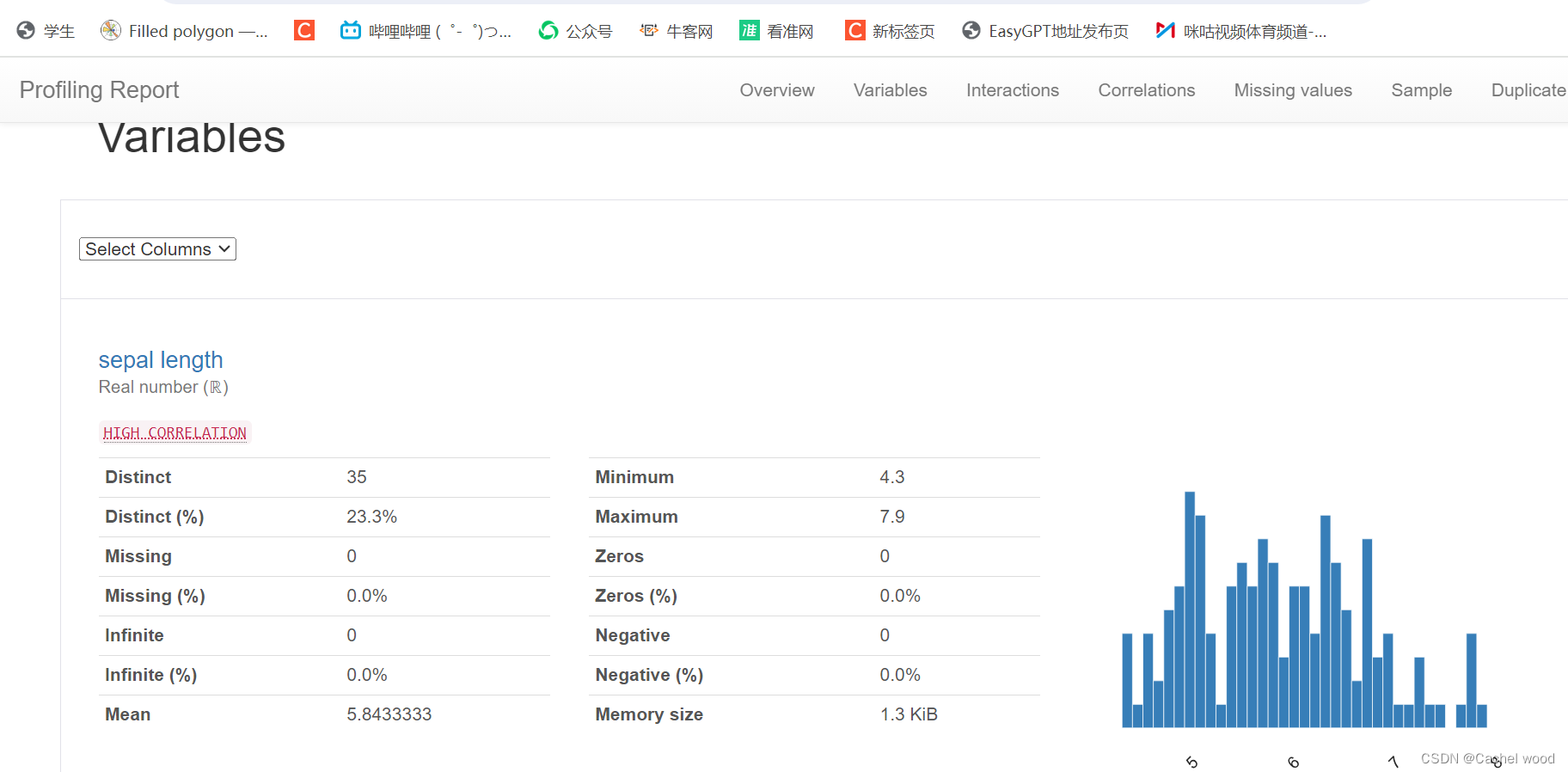
单变量分析 (Univariate analysis):包括描述性统计量(平均值、中位数、众数等)和信息可视化,如分布直方图
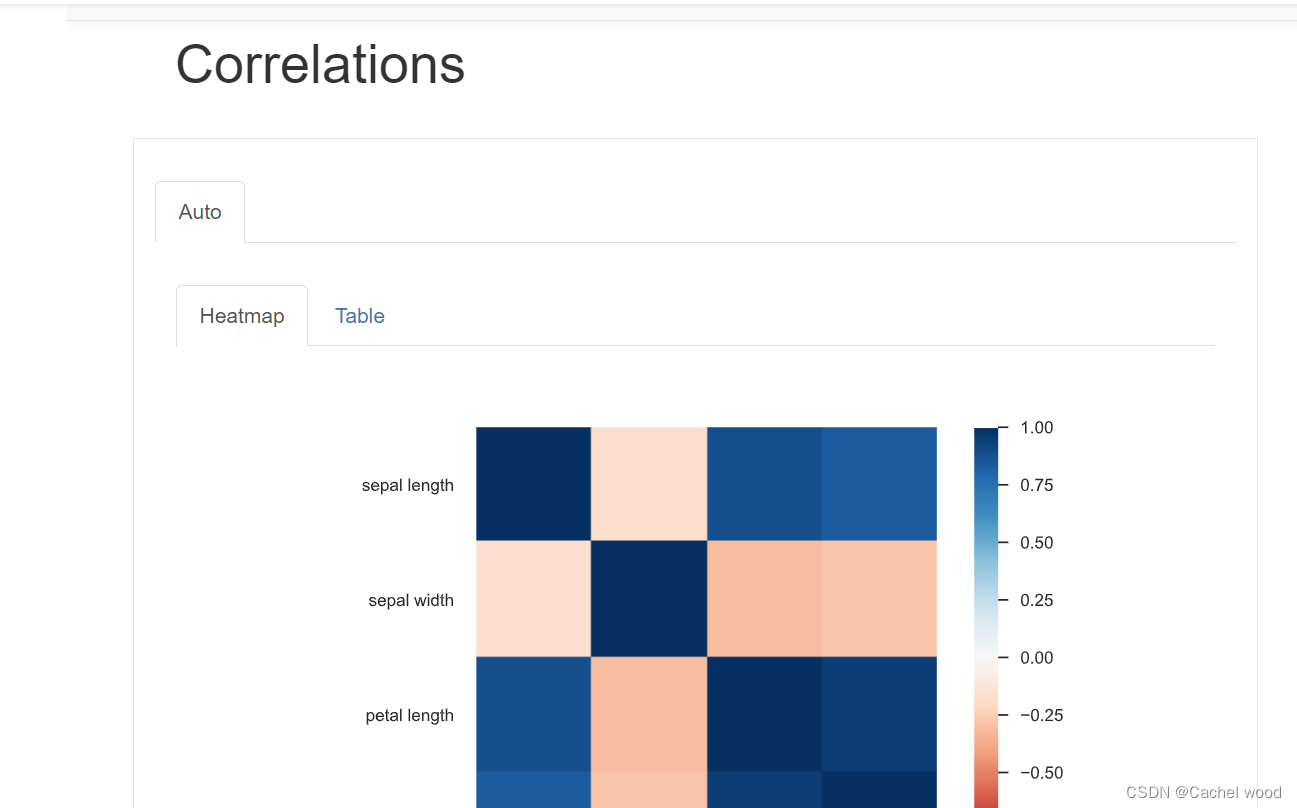
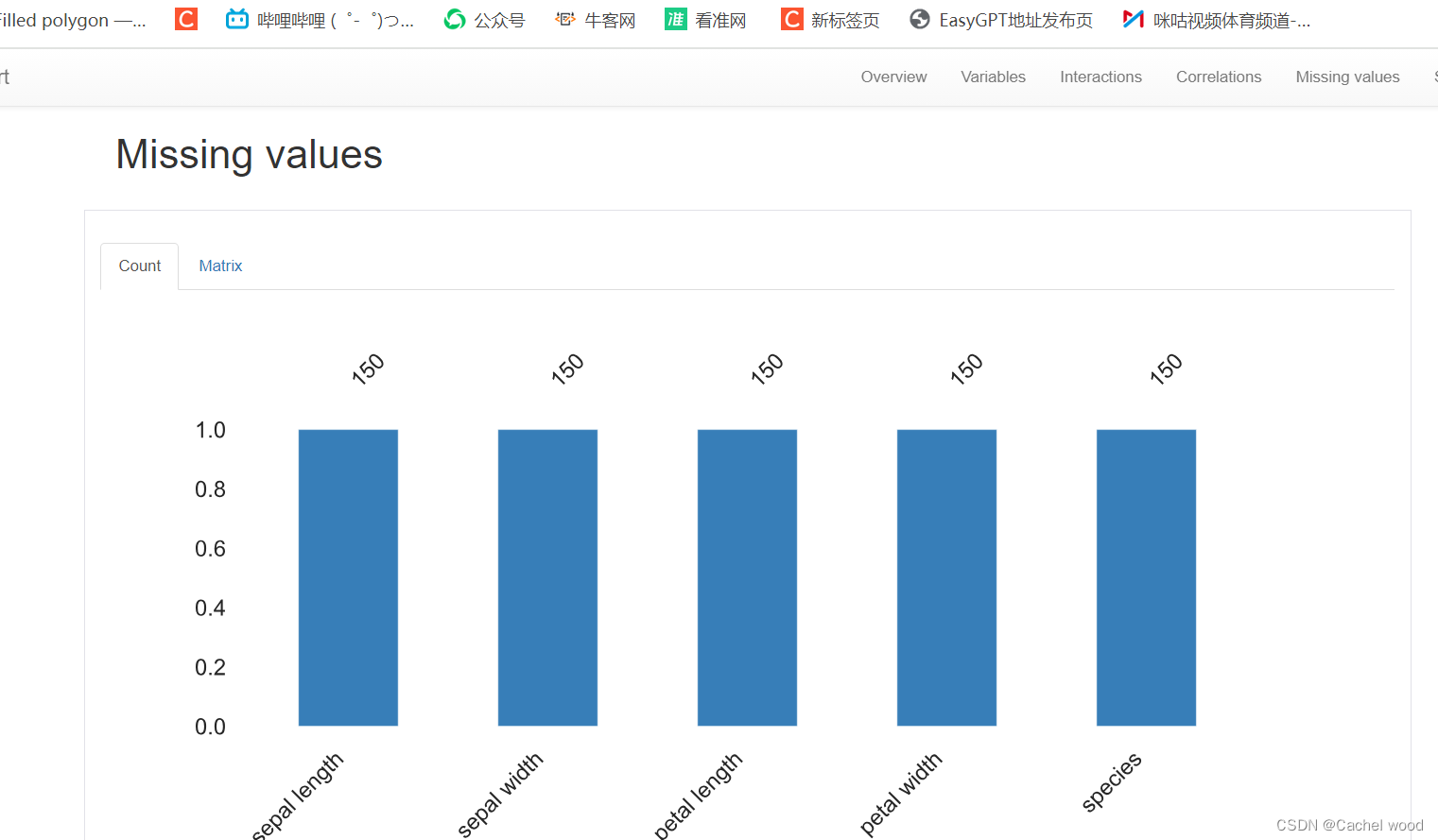
多变量分析 (Multivariate analysis):包括相关性分析、详细分析缺失数据、重复行,并为变量之间的交互提供视觉支持
时间序列 (Time-Series):包括与时间相关的不同统计信息,例如自相关和季节性,以及ACF和PACF图。
文本分析 (Text analysis):最常见的类别(大写、小写、分隔符)、脚本(拉丁文、西里尔文)和区块(ASCII、西里尔文)
文件和图像分析 (File and Image analysis):文件大小、创建日期、指示截断图像和存在EXIF元数据的指示
比较数据集 (Compare datasets):一行命令,快速生成完整的数据集比较报告
灵活的输出格式 (Flexible output formats):所有分析结果可以导出为HTML报告,便于与各方共享,也可作为JSON用于轻松集成到自动化系统中,还可以作为Jupyter Notebook中的小部件使用
报告还包含三个额外的部分:
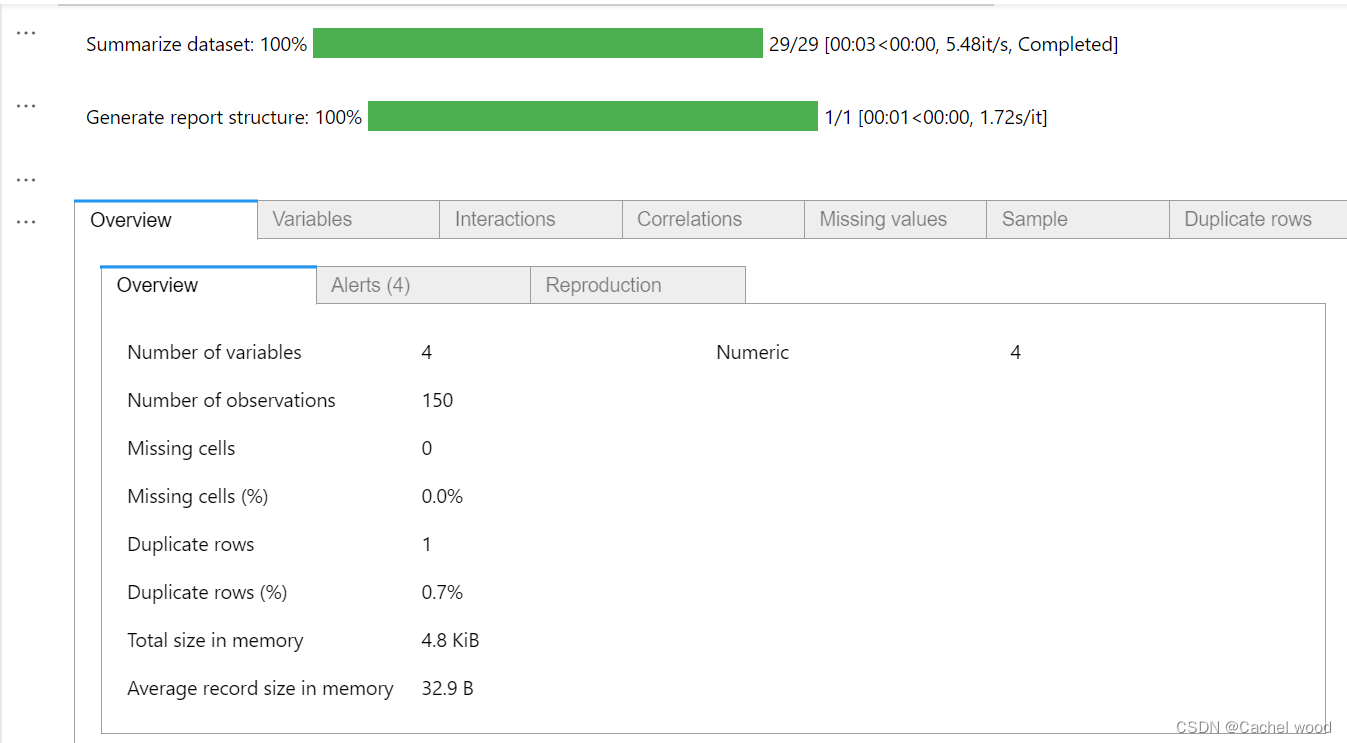
概述 (Overview):主要提供有关数据集的全局详细信息(记录数、变量数、整体缺失值和重复值、内存占用情况)
警告 (Alerts):一个全面且自动的潜在数据质量问题列表(高相关性、偏斜、一致性、零值、缺失值、常数值等)
重现 (Reporduction):分析的技术细节(时间、版本和配置)
ydata-profiling实际应用iris鸢尾花数据集分析
from sklearn.datasets import load_iris
iris = load_iris()
iris
import pandas as pd
df = pd.DataFrame(data=iris.data,
columns=[name.strip(' (cm)') for name in iris.feature_names])
# DISPLAY FIRST 5 RECORDS OF THE
# DATAFRAME
df['species'] = iris.target
df
import ydata_profiling as yp
profile = yp.ProfileReport(df.iloc[:,:4], title="Profiling Report")
# 通过小部件使用
profile.to_widgets()
# 生成嵌入式HTML报告
profile.to_notebook_iframe()
ydata_profiling 可以在jupyter notebook中内嵌HTML报告,也可以使用to_file生产HTML或者json格式文件。
profile.to_file('report.html')






![P1025 [NOIP2001 提高组] 数的划分](https://img-blog.csdnimg.cn/direct/a0d5f18eb6a84e9fa3667dded9da1075.png)