近期,中国最大的出行平台之一——滴滴,经历了一次长达12小时的系统崩溃,造成了重大的经济损失。这一事件引起了广泛关注,并凸显出一些关键信息。本文将深入探讨此次事件中凸显的关键信息和可能的技术原因。

首先,滴滴作为中国最大的出行平台之一,拥有庞大的用户群体和复杂的业务体系。这次系统崩溃持续了长达12小时,给用户出行带来了极大的不便,也给滴滴带来了巨大的经济损失。这表明滴滴在系统的稳定性和可靠性方面存在一定的问题,需要加强技术投入和风险防范措施。
其次,此次事件中凸显了滴滴在应对突发情况时的应急响应能力不足。系统崩溃后,滴滴的客服电话无法接通,用户无法通过正常渠道联系到滴滴客服,这给用户带来了很大的困扰。这也表明滴滴在应急响应方面存在一些问题,需要加强应急预案的制定和实施。
最后,可能的技术原因也是此次事件中需要关注的问题。滴滴作为一家技术驱动型的公司,其系统崩溃可能涉及到技术层面的原因。据报道,此次系统崩溃可能与网络攻击有关,这也提醒了滴滴需要加强网络安全防护措施。此外,滴滴的业务体系复杂,涉及到的技术环节众多,也需要加强技术管理和风险控制措施。
事件回顾
11月27日,全国多地滴滴用户反映,滴滴出行App“崩了”,出现不显示定位、地图无法加载、扣费异常、无法打车等情况。
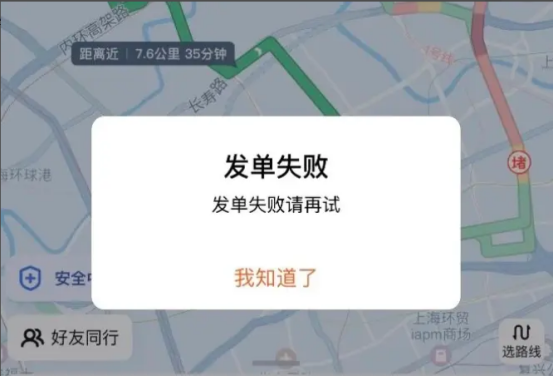
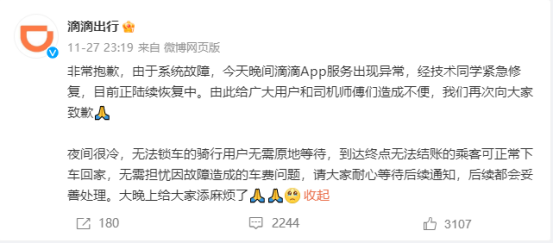
27日深夜,滴滴出行对此作出回应:“非常抱歉,由于系统故障,今天晚间滴滴App服务出现异常,经技术同学紧急修复,目前正陆续恢复中。”
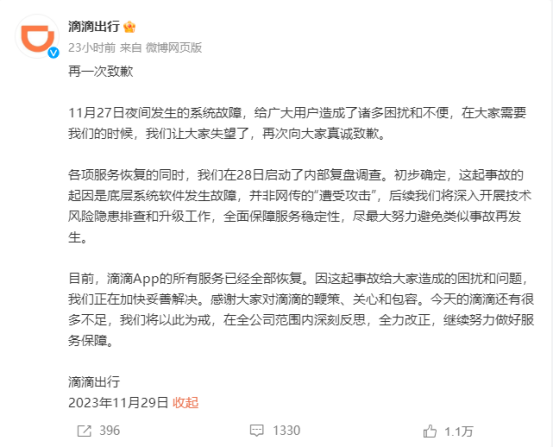
28日早上7点30分,滴滴出行发表了正式的道歉声明,并宣布其网约车服务已经恢复。经过技术团队的连夜奋战,已经解决了出现的问题。用户可以重新下载滴滴App,并使用其打车服务。
同时,滴滴也表示,其共享单车等服务还在陆续修复中。在此期间,所有可开锁或未关锁的青桔车辆均可免费骑行。

尽管滴滴出行已发布公告,然而,至今仍有众多用户反映滴滴App存在诸多问题。至本文发布之际,滴滴出行的最后一次发文是在11月29日。
经济损失
此次事件,根据众多司机的反馈,滴滴平台在接单、定位、计费等环节上均存在问题。有网约车司机表示,在App崩溃时开始接单,从11月27日晚上10点20分起无法进行任何操作,客服电话也无法接通。目前部分功能已恢复,但仍无法正常使用,出现了许多错单乱单,以及多位司机接同一单的情况。经过一夜维修,滴滴司机表示目前仍未恢复。目前无法使用,导致司机在接单时无法正常显示订单信息,到达乘客位置也找不到乘客,接到乘客后又无法结束订单等众多问题。
甚至在11月28号早上,尝试打车时也遇到了类似情况,虽然不再崩溃,但仍然存在问题。司机成功接单后,仅能短暂查看车牌号,随后系统便异常重试,好在凭借记忆成功上车;询问司机后得知,其端口仅恢复了接单界面,其他功能仍未恢复。好在能接单并能进行导航。截至28日12点前,滴滴的系统仍然混乱。甚至有司机反馈称,相关的小桔充电桩目前也无法充电。
用户体验
滴滴系统崩溃导致用户无法叫车、支付和使用其他平台功能,这种情况给用户带来了巨大的困扰。用户可能因此被迫寻找替代解决方案,增加了他们的出行成本和不便。此外,这种情况还可能损害用户对平台可靠性和服务稳定性的信任,降低了用户对平台的忠诚度和满意度。因此,对于一个平台来说,提供稳定可靠的服务是非常重要的,这不仅可以增强用户的信任和忠诚度,还可以提高平台的口碑和竞争力。

技术原因
此次滴滴出行App崩溃的具体技术原因尚未公布,但已经有一些猜测和分析。可能的原因包括系统过载、服务器故障、网络问题或者软件漏洞。这些可能性都需要滴滴进行全面的调查,找出问题的根源,并采取有效的措施,以防止类似事件再次发生。
滴滴出行作为对数据量响应速度要求极高的网络服务,出现故障的频率并不低。在过去的几年里,滴滴出行曾多次出现系统故障,导致用户无法正常使用。这些故障包括2022年9月22日、2021年2月25日、2019年10月、2016年7月和2015年10月等多次系统异常。这些故障的原因可能包括机房网络故障、系统异常等。
值得留意的是,滴滴出行的云服务主要由滴滴云进行支持。根据滴滴云官网显示,滴滴出行的云计算服务基于滴滴出行的业务技术和经验积累,采用领先的云计算架构、高规格服务器集群搭建、高性能资源配置机制、精细化运营模式,致力于为开发者提供简单快捷、高效稳定、高性价比、安全可靠的IT基础设施云服务。然而,早在今年3月,滴滴云已经不再对外提供公有云服务。
此外,对于此次滴滴出行App崩溃的原因,业内相关人士指出故障原因很大可能是来自滴滴自身的机房网络问题。这表明滴滴的云服务可能存在一些问题,需要进一步调查和解决。因此,滴滴需要加强对自身云服务的管理和监控,确保类似的问题不再发生。
灾难恢复计划
滴滴在这次系统崩溃后,必须认真评估其灾难恢复计划是否足够有效。这涉及到备份策略、容错机制以及应急响应流程等关键环节。滴滴需要从这次事件中吸取教训,加强平台的可靠性和鲁棒性,确保类似的问题不再发生。
备份策略
滴滴需要对其备份策略进行全面审查和改进。这包括定期备份所有数据,确保备份的完整性和可访问性,以及存储和保护备份数据的方式。此外,滴滴还需要考虑在备份服务器上实施实时监控,以便及时发现任何异常情况。
容错机制
滴滴需要建立健全的容错机制,以确保在系统出现问题时能够快速响应并恢复正常运行。这包括对服务器进行定期维护和检查,以防止硬件故障;同时也要对软件进行定期更新和补丁修复,以防止软件故障。此外,滴滴还需要建立应急响应小组,以便在发生问题时能够迅速采取行动。
应急响应流程
滴滴需要制定完善的应急响应流程,以便在发生灾难性事件时能够迅速响应并最大限度地减少损失。这包括建立24小时不间断的监控系统,以便及时发现任何问题;同时也要制定详细的应急响应计划,以便应急响应小组能够迅速采取行动。此外,滴滴还需要建立有效的沟通机制,以便与相关部门和客户进行及时沟通和信息共享。
通过评估这次事件,滴滴可以吸取教训并加强平台的可靠性和鲁棒性。这不仅可以提高滴滴的服务质量,还可以确保类似的问题不再发生,为客户提供更加稳定、可靠的服务。
结论
滴滴这次长时间的系统崩溃给整个出行平台带来了巨大的经济损失,对用户和司机的出行产生了重大影响,造成了极大的不便。这次事件充分暴露了滴滴平台在系统可靠性和技术鲁棒性方面的严重不足,凸显了出行平台在应对突发情况时的脆弱性。滴滴需要认真反思,汲取这次事件的教训,从中学习并改进他们的技术架构,以确保类似的问题不再发生。
为了更好地应对系统崩溃等突发事件,滴滴需要采取一系列措施。首先,他们应该加强技术团队的建设,提高技术人员的专业水平,以便在遇到问题时能够迅速定位并修复。其次,滴滴应该建立健全的系统监控机制,实时监测系统的运行状态,及时发现并处理异常情况。此外,滴滴还需要加强与合作伙伴的沟通与协作,共同应对突发情况,减轻对用户和司机的影响。

通过这次事件,滴滴需要深刻认识到系统可靠性和技术鲁棒性的重要性。他们应该采取积极措施来提高系统的稳定性和可靠性,避免类似的问题再次发生。同时,滴滴也需要重视用户和司机的需求和反馈,不断优化服务体验,提升用户满意度。只有这样,滴滴才能在竞争激烈的出行市场中保持领先地位,为用户和司机提供更加优质、便捷的服务。

![P1025 [NOIP2001 提高组] 数的划分](https://img-blog.csdnimg.cn/direct/a0d5f18eb6a84e9fa3667dded9da1075.png)








![navigator.clipboard is undefined in JavaScript issue [Fixed]](https://img-blog.csdnimg.cn/direct/ba5792b02780438988eb14aa11d2788d.png)