深度学习入门(六十六)循环神经网络——束搜索)
- 前言
- 循环神经网络——束搜索
- 课件
- 贪心搜索
- 穷举搜索
- 束搜索
- 总结
- 教材
- 1 贪心搜索
- 2 穷举搜索
- 3 束搜索
- 4 小结
前言
核心内容来自博客链接1博客连接2希望大家多多支持作者
本文记录用,防止遗忘
循环神经网络——束搜索
课件
贪心搜索
在seq2seq中我们使用了贪心搜索来预测序列
- 将当前时刻预测概率最大的词输出
但贪心很可能不是最优的:
穷举搜索
最优算法:对所有可能的序列,计算它的概率,然后选取最好的那个
如果输出字典大小为n,序列最长为T,那么我们需要考察nT个序列
- n = 10000,T= 10: n T = 1 0 40 n^T = 10^{40} nT=1040
- 计算上不可行
束搜索
保存最好的k个候选
在每个时刻,对每个候选新加一项(n种可能),在kn个选项中选出最好的k个
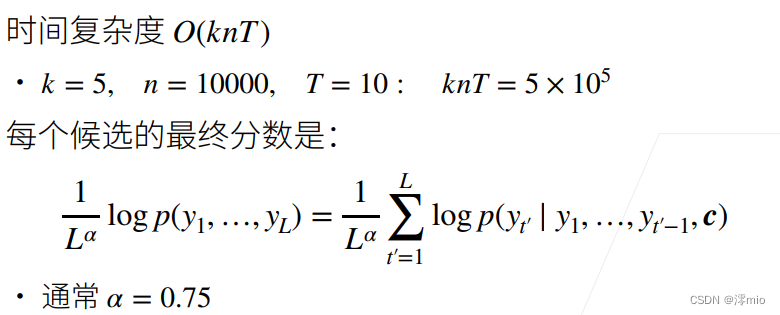
总结
束搜索在每次搜索时保存k个最好的候选
- k =1时是贪心搜索
- k = n时是穷举搜索
教材
在上一节中,我们逐个预测输出序列, 直到预测序列中出现特定的序列结束词元“<eos>”。 本节将首先介绍贪心搜索(greedy search)策略, 并探讨其存在的问题,然后对比其他替代策略: 穷举搜索(exhaustive search)和束搜索(beam search)。
在正式介绍贪心搜索之前,我们使用与上一节中 相同的数学符号定义搜索问题。 在任意时间步
t
′
t'
t′,解码器输出
y
t
′
y_{t'}
yt′的概率取决于 时间步
t
′
t'
t′之前的输出子序列
y
1
,
…
,
y
t
′
−
1
y_1, \ldots, y_{t'-1}
y1,…,yt′−1 和对输入序列的信息进行编码得到的上下文变量
c
\mathbf{c}
c。 为了量化计算代价,用
Y
\mathcal{Y}
Y表示输出词表, 其中包含“<eos>”, 所以这个词汇集合的基数
∣
Y
∣
\left|\mathcal{Y}\right|
∣Y∣就是词表的大小。 我们还将输出序列的最大词元数指定为
T
′
T'
T′。 因此,我们的目标是从所有
O
(
∣
Y
∣
T
′
)
\mathcal{O}(\left|\mathcal{Y}\right|^{T'})
O(∣Y∣T′)个 可能的输出序列中寻找理想的输出。 当然,对于所有输出序列,在“<eos>”之后的部分(非本句) 将在实际输出中丢弃。
1 贪心搜索
首先,让我们看看一个简单的策略:贪心搜索, 该策略已用于上一节的序列预测。 对于输出序列的每一时间步, 我们都将基于贪心搜索从中找到具有最高条件概率的词元,即:
y
t
′
=
argmax
y
∈
Y
P
(
y
∣
y
1
,
…
,
y
t
′
−
1
,
c
)
y_{t'} = \operatorname*{argmax}_{y \in \mathcal{Y}} P(y \mid y_1, \ldots, y_{t'-1}, \mathbf{c})
yt′=y∈YargmaxP(y∣y1,…,yt′−1,c)
一旦输出序列包含了“<eos>”或者达到其最大长度
T
′
T'
T′,则输出完成。
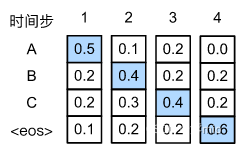
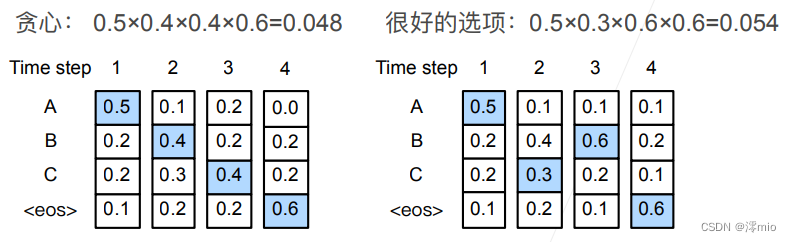
如图中, 假设输出中有四个词元“A”“B”“C”和“<eos>”。 每个时间步下的四个数字分别表示在该时间步 生成“A”“B”“C”和“<eos>”的条件概率。 在每个时间步,贪心搜索选择具有最高条件概率的词元。 因此,将在图中 预测输出序列“A”“B”“C”和“<eos>”。 这个输出序列的条件概率是
0.5
×
0.4
×
0.4
×
0.6
=
0.048
0.5\times0.4\times0.4\times0.6 = 0.048
0.5×0.4×0.4×0.6=0.048。
那么贪心搜索存在的问题是什么呢? 现实中,最优序列(optimal sequence)应该是最大化
∏
t
′
=
1
T
′
P
(
y
t
′
∣
y
1
,
…
,
y
t
′
−
1
,
c
)
\prod_{t'=1}^{T'} P(y_{t'} \mid y_1, \ldots, y_{t'-1}, \mathbf{c})
∏t′=1T′P(yt′∣y1,…,yt′−1,c)值的输出序列,这是基于输入序列生成输出序列的条件概率。 然而,贪心搜索无法保证得到最优序列。
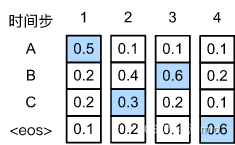
上图中的另一个例子阐述了这个问题。 与前一张图不同,在时间步中, 我们选择图2中的词元“C”, 它具有第二高的条件概率。 由于时间步所基于的时间步和处的输出子序列已从 图1中的“A”和“B”改变为 图9.8.2中的“A”和“C”, 因此时间步处的每个词元的条件概率也在 图2中改变。 假设我们在时间步选择词元“B”, 于是当前的时间步基于前三个时间步的输出子序列“A”“C”和“B”为条件, 这与图1中的“A”“B”和“C”不同。 因此,在 图2中的时间步生成 每个词元的条件概率也不同于 图1中的条件概率。 结果, 图2中的输出序列 “A”“C”“B”和“<eos>”的条件概率为
0.5
×
0.3
×
0.6
×
0.6
=
0.054
0.5\times0.3 \times0.6\times0.6=0.054
0.5×0.3×0.6×0.6=0.054 , 这大于 图1中的贪心搜索的条件概率。 这个例子说明:贪心搜索获得的输出序列 “A”“B”“C”和“<eos>” 不一定是最佳序列。
2 穷举搜索
如果目标是获得最优序列, 我们可以考虑使用穷举搜索(exhaustive search): 穷举地列举所有可能的输出序列及其条件概率, 然后计算输出条件概率最高的一个。
虽然我们可以使用穷举搜索来获得最优序列, 但其计算量 O ( ∣ Y ∣ T ′ ) \mathcal{O}(\left|\mathcal{Y}\right|^{T'}) O(∣Y∣T′)可能高的惊人。 例如,当 ∣ Y ∣ = 10000 |\mathcal{Y}|=10000 ∣Y∣=10000和 T ′ = 10 T'=10 T′=10时, 我们需要评估 1000 0 10 = 1 0 40 10000^{10} = 10^{40} 1000010=1040序列, 这是一个极大的数,现有的计算机几乎不可能计算它。 然而,贪心搜索的计算量 O ( ∣ Y ∣ T ′ ) \mathcal{O}(\left|\mathcal{Y}\right|T') O(∣Y∣T′),它要显著地小于穷举搜索。 例如,当 ∣ Y ∣ = 10000 |\mathcal{Y}|=10000 ∣Y∣=10000和 T ′ = 10 T'=10 T′=10时, 我们只需要评估 10000 × 10 = 1 0 5 10000\times10=10^5 10000×10=105个序列。
3 束搜索
那么该选取哪种序列搜索策略呢? 如果精度最重要,则显然是穷举搜索。 如果计算成本最重要,则显然是贪心搜索。 而束搜索的实际应用则介于这两个极端之间。
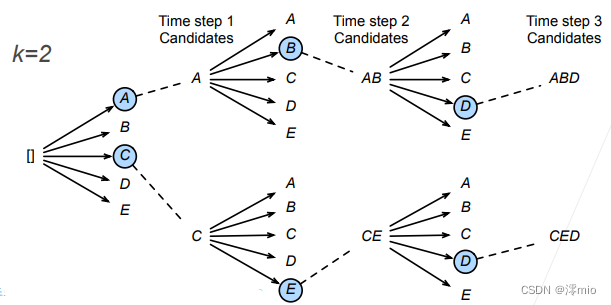
束搜索(beam search)是贪心搜索的一个改进版本。 它有一个超参数,名为束宽(beam size)k。 在时间步1,我们选择具有最高条件概率的k个词元。 这k个词元将分别是k个候选输出序列的第一个词元。 在随后的每个时间步,基于上一时间步的k个候选输出序列, 我们将继续从
k
∣
Y
∣
k\left|\mathcal{Y}\right|
k∣Y∣个可能的选择中 挑出具有最高条件概率的k个候选输出序列。
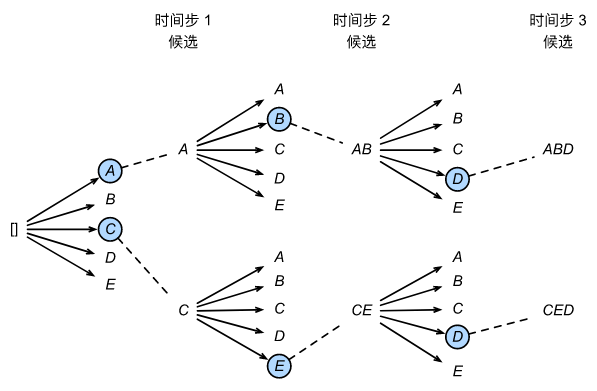
上图演示了束搜索的过程。 假设输出的词表只包含五个元素:
Y
=
{
A
,
B
,
C
,
D
,
E
}
\mathcal{Y} = \{A, B, C, D, E\}
Y={A,B,C,D,E} , 其中有一个是“<eos>”。 设置束宽为2,输出序列的最大长度为3。 在时间步1,假设具有最高条件概率
P
(
y
1
∣
c
)
P(y_1 \mid \mathbf{c})
P(y1∣c)的词元是A和C。 在时间步2,我们计算所有
y
2
∈
Y
y_2 \in \mathcal{Y}
y2∈Y为:
P
(
A
,
y
2
∣
c
)
=
P
(
A
∣
c
)
P
(
y
2
∣
A
,
c
)
,
P
(
C
,
y
2
∣
c
)
=
P
(
C
∣
c
)
P
(
y
2
∣
C
,
c
)
,
\begin{split}\begin{aligned}P(A, y_2 \mid \mathbf{c}) = P(A \mid \mathbf{c})P(y_2 \mid A, \mathbf{c}),\\ P(C, y_2 \mid \mathbf{c}) = P(C \mid \mathbf{c})P(y_2 \mid C, \mathbf{c}),\end{aligned}\end{split}
P(A,y2∣c)=P(A∣c)P(y2∣A,c),P(C,y2∣c)=P(C∣c)P(y2∣C,c),
从这十个值中选择最大的两个, 比如 P ( A , B ∣ c ) P(A, B \mid \mathbf{c}) P(A,B∣c)和 P ( C , E ∣ c ) P(C, E \mid \mathbf{c}) P(C,E∣c)。 然后在时间步3,我们计算所有 y 3 ∈ Y y_3 \in \mathcal{Y} y3∈Y为:
P ( A , B , y 3 ∣ c ) = P ( A , B ∣ c ) P ( y 3 ∣ A , B , c ) , P ( C , E , y 3 ∣ c ) = P ( C , E ∣ c ) P ( y 3 ∣ C , E , c ) , \begin{split}\begin{aligned}P(A, B, y_3 \mid \mathbf{c}) = P(A, B \mid \mathbf{c})P(y_3 \mid A, B, \mathbf{c}),\\P(C, E, y_3 \mid \mathbf{c}) = P(C, E \mid \mathbf{c})P(y_3 \mid C, E, \mathbf{c}),\end{aligned}\end{split} P(A,B,y3∣c)=P(A,B∣c)P(y3∣A,B,c),P(C,E,y3∣c)=P(C,E∣c)P(y3∣C,E,c),
从这十个值中选择最大的两个, 即 P ( A , B , D ∣ c ) P(A, B, D \mid \mathbf{c}) P(A,B,D∣c)和 P ( C , E , D ∣ c ) P(C, E, D \mid \mathbf{c}) P(C,E,D∣c), 我们会得到六个候选输出序列: (1)A;(2)C;(3)A,B;(4)C,E;(5)A,B,D;(6)C,E,D。
最后,基于这六个序列(例如,丢弃包括“<eos>”和之后的部分), 我们获得最终候选输出序列集合。 然后我们选择其中条件概率乘积最高的序列作为输出序列:
1 L α log P ( y 1 , … , y L ∣ c ) = 1 L α ∑ t ′ = 1 L log P ( y t ′ ∣ y 1 , … , y t ′ − 1 , c ) , \frac{1}{L^\alpha} \log P(y_1, \ldots, y_{L}\mid \mathbf{c}) = \frac{1}{L^\alpha} \sum_{t'=1}^L \log P(y_{t'} \mid y_1, \ldots, y_{t'-1}, \mathbf{c}), Lα1logP(y1,…,yL∣c)=Lα1t′=1∑LlogP(yt′∣y1,…,yt′−1,c),
其中 L L L是最终候选序列的长度, α \alpha α通常设置为 0.75 0.75 0.75。 因为一个较长的序列在上式的求和中会有更多的对数项, 因此分母中 L α L^\alpha Lα的用于惩罚长序列。
束搜索的计算量为 O ( k ∣ Y ∣ T ′ ) \mathcal{O}(k\left|\mathcal{Y}\right|T') O(k∣Y∣T′), 这个结果介于贪心搜索和穷举搜索之间。 实际上,贪心搜索可以看作一种束宽为1的特殊类型的束搜索。 通过灵活地选择束宽,束搜索可以在正确率和计算代价之间进行权衡。
4 小结
-
序列搜索策略包括贪心搜索、穷举搜索和束搜索。
-
贪心搜索所选取序列的计算量最小,但精度相对较低。
-
穷举搜索所选取序列的精度最高,但计算量最大。
-
束搜索通过灵活选择束宽,在正确率和计算代价之间进行权衡。



![Spring Boot[概述、功能、快速入门]](https://img-blog.csdnimg.cn/1885a6124f474035adaa8084cd91839e.png)