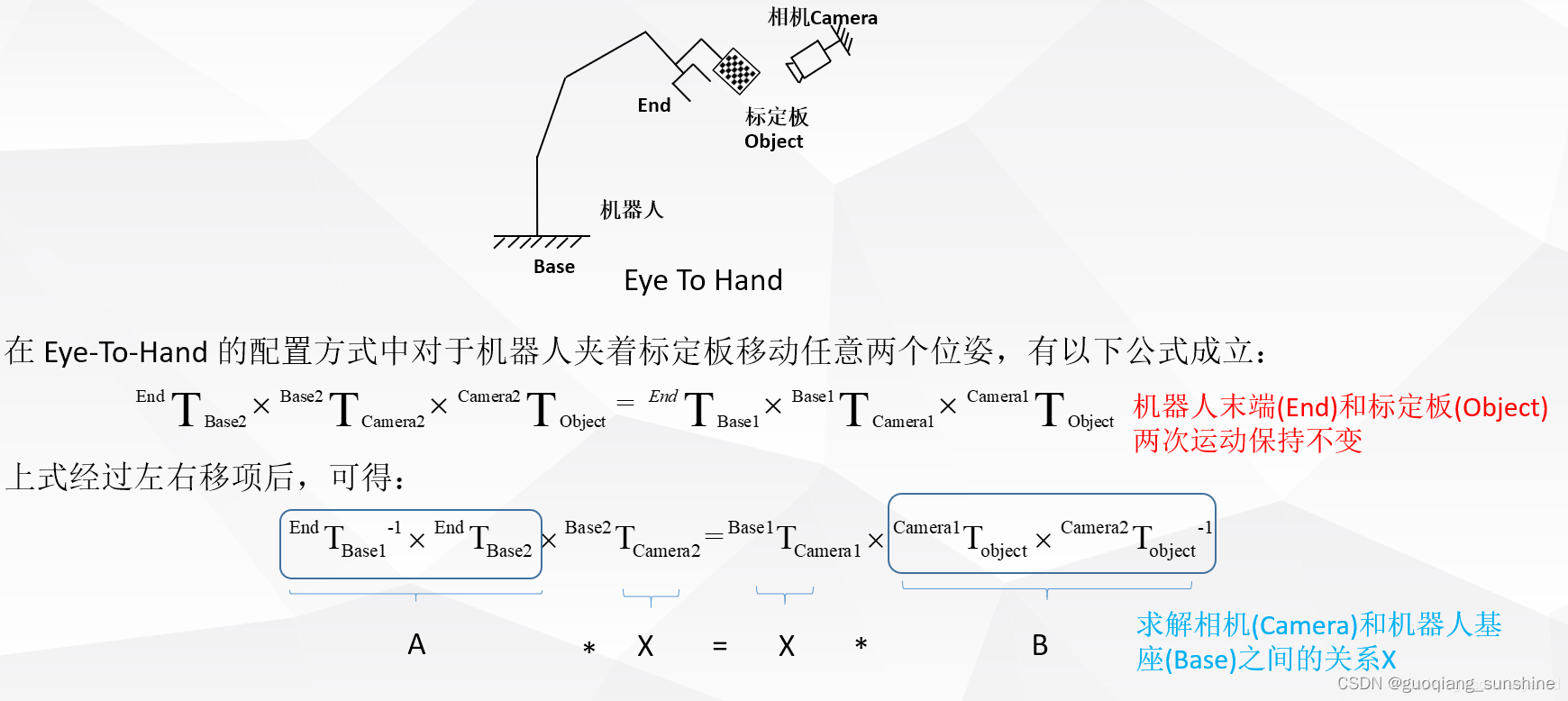
urllib基础
一般做爬虫其实很少有推荐urllib的,但urllib乃是Python标准库成员,在要求比较简单的情况下,采用urllib还是比较方便的。
作为爬虫入门必学包,urllib最常用的函数一定是urllib.request中的urlopen。其返回对象是HTTPResponse,这个类也只能作为urlopen的返回值,而无法通过什么构造函数创建。
import urllib.request as ur
res = ur.urlopen("https://tinycool.blog.csdn.net/")
其成员变量和无参函数如下
| 成员 | 说明 | 值 | 成员 | 说明 | 值 |
|---|---|---|---|---|---|
| version | 版本 | 11 | length | 内容长度 | 50672 |
| status | 状态 | 200 | getcode() url.code | 状态码 | 200 |
| readable() | 是否可读 | True | writable() | 是否可写 | False |
| seekable() | 是否可seek | False | chunked | 是否已编码 | False |
| closed url.isclosed() | 是否已关闭 | False | isatty() | False | |
| fileno | 底层套接字序号 | 700 | msg | 状态信息 | ‘ok’ |
此外,变量res.url链接'https://tinycool.blog.csdn.net/'。
其他像诸如close(),flush(),read(),write与文件操作中的函数类似。例如,read(5)表示读取5个字符,read()表示读取所有内容,readline表示读取一行。
统计CSDN博客阅读量
CSDN非常友好地为创作者提供了诸多统计工具,对近期博客进行数据可视化。然而,似乎并没有对文章的阅读数做实时的记录,所以只能查看每日阅读量,而不能更加细致地查看每小时的阅读量。对于程序员来说,获取这个信息是轻而易举的。
import urllib.request as ur
url = 'https://tinycool.blog.csdn.net/article/list/1'
res = ur.urlopen(url)
text = res.read().decode('utf-8')
即准备爬取的页面如下,想要爬取的内容是文章列表的链接

唯一有点麻烦的就是,在获取网页数据之后,需要对这个数据进行解析。一般来说,适用于爬虫的最佳拍档是BeautifulSoup,但考虑到本文主要介绍标准库中的urllib,不宜引入更多其它的模块,所以接下来用正则表达式来实现对网页的解析。
首先,考虑到我们的目的是获取所有文章的链接,而文章链接基本都是https://tinycool.blog.csdn.net/article/details/128429200这种比较统一的格式,其中最后是9位数字表示博客序号。
import re
article = r'details/[0-9]*'
details = re.findall(article, text)
len(details)
# 结果为101,即找到了101篇博客
但这101篇博客中,有不少是左侧热门文章之类的,但是没关系,最后只需将所有文章号做个单值化就好了。而且经过实测,发现其中有61篇都是不知道哪来的博客。
blogId = []
for i in range(1, 100):
url = f'https://tinycool.blog.csdn.net/article/list/{i}'
res = ur.urlopen(url)
text = res.read().decode('utf-8')
details = re.findall(article, text)
blogId += [int(d.split('/')[-1]) for d in details]
if len(details)==61:
break
blogId = list(set(blogId))
接下来就可以逐一爬取每篇博客了,其中准备爬取的内容包括博客名、发布时间、阅读数,所需爬取的内容包括
TITLE = 'id="articleContentId">.*</h1>'
TIME = '>于 \d*-\d\d-\d\d'
VIEW = '"read-count">\d*'
def parseRes(url):
res = ur.urlopen(url)
text = res.read().decode('utf-8')
title = re.findall(TITLE, text)[0]
title = title.split('>')[1][:-4]
print(title)
t = re.findall(TIME, text)[0]
t = t.split(';')[1]
v = re.findall(VIEW, text)[0]
v = v.split('>')[1]
return [title, t, v]
然后对所有数据进行相同的操作
infos = []
for id in blogId:
url = f'https://tinycool.blog.csdn.net/article/details/{id}'
try: infos.append(parseRes(url))
except: continue
获取所有数据之后,可查看一下阅读量分布
views = [int(i[2]) for i in infos]
import matplotlib.pyplot as plt
plt.hist(views)
得到结果如下,可见大部分博客的阅读量都在1000以内,实在是太凄惨了。






![刷题记录:牛客NC26257小雨坐地铁 [分层图跑最短路]](https://img-blog.csdnimg.cn/7b5cf4f6e8a24286bdbdd702263ba59e.png#pic_center)