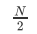文章目录
- 搜索树概念
- 1. 查找操作
- 2. 插入操作
- 3. 删除操作
- 4. 以上三种操作的测试
- 5. 性能分析
搜索树概念
二叉搜索树 又称 二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的 左 子树 不为空,则 左 子树上所有节点的值都 小于 根节点的值
- 若它的 右 子树 不为空,则 右 子树上所有节点的值都 大于 根节点的值
- 它的左右子树也分别为二叉搜索树
如果现在有一个数组:
int[] array = {5, 3, 4, 1, 7, 8, 2, 6, 0, 9};
将这个数组变为 二叉搜索树 如下。

可以看到 左子树 上的所有节点都比根节点的值 小,
而 右子树 上的所有节点都比根节点的值 大。
1. 查找操作
查找思路
将下面一组数据变成二叉搜索树,再查找其中某个节点是否存在。
int[] array = {8, 5, 7, 2, 12, 25, 11};
变为二叉搜索树为以下图片

如果要查找 11 这个值,则根据二叉搜索树的特点,这个值一定是在根节点的右边。
1、定义一个 cur 指向根节点。

2、要找的 11 是在根节点的右边,所以 cur 会往右边走。

3、这是要找的值比此时的 cur 的值小,cur 往左边走。

此时的 cur 的值等于要查找的值,即找到了,返回 cur 即可。
我们会发现,每一次的查找都会直接去掉一半的节点,二叉搜索树 类似于二分查找的思路。(一次去掉一半的数据)
如果这不是一个 二叉搜索树 ,则需要遍历每一个结点才有可能找到目标值。
这时候效率明显就慢了不少。
查找的不同结果
在这一棵 二叉搜索树 中,有可能遍历结束后也不会出现要查找的值,即是搜索树没有要查找的值。

如果要在上面的 搜索树 中查找 18 这个值,一开始会因为 18 大于 根节点,
所以 cur 会往右边走。
此时的 cur 的值 还是小于 18 ,cur 还是会往右边走,cur 此时来到 25 的位置。
由于此时 cur 的值 大于 18,cur 会往左走,但此时 cur 的值为空并且没有找等于18的结点,
此时就是找不到的情况了,返回 null 即可。
关于代码的分析
因此就可以采取下面的代码实现多次的查找
while (cur != null) {}
可以通过比较 cur 与 val (查找的目标值)的值,来决定 cur 往哪边移动。
if (cur.val > val) {
cur = cur.right; // cur 往右边走
} else if (cur.val < val) { // cur 往左边走
cur = cur.left;
} else {
// 此时即使找到目标中
return cur;
}
如果循环结束了就说明搜索树当中不存在目标值,返回 null 即可。
return null;
完整代码的展示
// 查找操作
public ThreeNode search(int val) {
// 定义 cur 指向根节点
ThreeNode cur = root;
while (cur != null) {
// 此时 cur 往右边走
if (cur.val > val) {
cur = cur.right;
} else if (cur.val < val) { // cur 往左边走
cur = cur.left;
} else {
// 此时即使找到目标中
return cur;
}
}
// 若循环结束号未找到即为找不到了 - 返回 null
return null;
}
最好与最坏的情况
最好的情况就是 完全二叉树,一次查找会省去一般的效率。
上面所讲的就是一个 完全二叉树 的情况。
最坏的情况 是一个 左单支 或者 右单支。


这个时候不论是查找哪个值,都不能去掉一半的节点。
此时一定是每一个结点都要遍历才有可能找到 val 的值。
2. 插入操作
空与非空的插入情况
如果搜索树是空的,则直接将结点插入即可,新插入的结点就是 根节点 root。
如果不为空则按照 左边比根节点小右边比根节点大 的规则找到合适的位置,
然后将节点插入进去。
插入思路
下面还是以 5, 3, 4, 1, 7, 8, 2, 6, 0, 9 这组序列来演示。
如果树是空的,新插入的结点就是根节点。

如果树不是空的则会按照下面的思路插入。
1、如何插入 3

把结点的值与根节点的值比较一下,如果大于就插到右边,小于就插到左边。
2、如何插入4

还是拿结点的值与根节点的值比较,发现要把结点插入到左边。
但是此时左边还有一个结点,要再次与这个结点的值(3)比较,
再根据规则插入到右边或者左边。
其他的节点都是按照这种思路来实现的,
只要找到需要插入到的位置即可。
有一点要注意的是,当前插入的数据 一直是在叶子结点上的。
比如,当前插入的数据 3 的操作 ,这个 3 就是在当前的最后一个结点上的值。
插入数据 4 的操作,就是把 5 放在了当前的最后一个结点上。
结论:
只有第一次插入的结点是根节点,其他的每次插入都是在叶子结点的位置。
插入位置如何确定

假如要在上面搜索树中插入数据 0。
1、先定义一个 cur 指向根节点

2、将插入数据的值与 cur 的值比较,小的往左大的往右,cur 最终会到下面位置

当前的 cur 的值为空,就说明找到了插入的位置。
但也正是由于 cur 的值为空,无法通过 cur 来插入数据 0。
解决办法就是 重新定义一个变量记录 cur 的位置,让这个变量替 cur 移动
1、先定义一个指向空的 P 变量
2、在 cur 移动之前让 P 指向 cur 的位置

3、cur 移动了一次位置后,P 就指向 cur 移动前位置



当 cur 的值为空的时候,此时的 P 就是要插入的位置。
关于代码的分析
1、可以通过下面的代码判断树是不是空的。
if (root == null) {
// 此时插入到根节点的位置
root = new ThreeNode(key);
return true;
}
2、创建 cur 和 parent
ThreeNode cur = root;
ThreeNode parent = null;
3、cur 不为空说明还没有找到插入的位置
while (cur != null) {}
4、判断 cur 往哪边移动
if (cur.val > key) {}
else if (cur.val < key) {}
5、新建一个结点以便可以插入一个数据
ThreeNode node = new ThreeNode(key);
6、判断结点数据是插在左边还是右边
if (key < parent.val) {}
else {}
完整代码展示
// 插入一个元素 key
public boolean insert(int key) {
// 为空的情况
if (root == null) {
// 此时插入到根节点的位置
root = new ThreeNode(key);
return true;
}
// 不为空的情况
ThreeNode cur = root;
ThreeNode parent = null; // 用来记录 cur 的位置
// cur 不为空说明还未找到插入的位置
while (cur != null) {
// cur 的值大于 key 的值
if (cur.val > key) {
// parent 先指向 cur 的位置
parent = cur;
// cur 再向左边移动
cur = cur.left;
} else if (cur.val < key) {
parent = cur;
// cur 向右移动
cur = cur.right;
} else {
// 插入的数据是相同的
return false;
}
}
// 此时 cur 的值为空,说明找到了插入的位置
// 先创建一个结点
ThreeNode node = new ThreeNode(key);
//判断此时的 key 的值是在左边还是在右边
if (key < parent.val) {
// 插左边
parent.left = node;
} else {
// 否则插右边
parent.right = node;
}
// 插入完成后返回true
return true;
}
3. 删除操作

如果要删除 12 ,就要把 25 移动到删除前12的位置。
但此时有一个疑问,是应该把 8 或者 20 哪一个作为 25 的左边?
因此可以看出删除操作还是很有难度的。
搜索树删除操作分三种情况
1、cur.left == null 的情况
cur 是 root,则 root = cur.right

删除后

cur 指向的是要删除的结点,如果此时 cur 指向的是 root。
则只需要 root = cur.right,即可完成删除并且此时仍然是一个搜索树。
直接使用这个操作的前提是 cur 的左树为空。
cur 不是 root,cur 是 parent.left,则 parent.left = cur.right

此时 cur 指向的结点是要删除的结点并且要删除的结点不是根节点。
此时 p 左边的结点如果变成 p 右边的结点,即可完成删除,
而且此时仍然是搜索树。
删除后

cur 不是 root,cur 是 parent.right,则 parent.right = cur.right

此时 cur 指向的结点是要删除的结点并且要删除的结点不是根节点。
此时 p 右边的结点如果变成 cur 右边的结点,即可完成删除,
而且此时仍然是搜索树。
删除后

2、cur.right == null 的情况
cur 是 root,则 root = cur.left

cur 指向的是要删除的结点,如果此时 cur 指向的是 root。
则只需要 root = cur.left,即可完成删除并且此时仍然是一个搜索树。
删除后

cur 不是 root,cur 是 parent.right,则 parent.right = cur.left

此时 cur 指向的结点是要删除的结点并且要删除的结点不是根节点。
此时 p 右边的结点如果变成 cur 左边的结点,即可完成删除,
而且此时仍然是搜索树。
删除后

cur 不是 root,cur 是 parent.left,则 parent.left = cur.left

此时 cur 指向的结点是要删除的结点并且要删除的结点不是根节点。
此时 p 左边的结点如果变成 cur 左边的结点,即可完成删除,
而且此时仍然是搜索树。
删除后

3、cur 左右都不为空的情况

此时 cur 是要删除的结点,cur 的左右都不为空。
当删除了cur结点后,8 和 25 哪一个结点应该左为 p 的右边呢?
这是一个疑问。
可以采用 替罪羊 的方法来实现删除操作。

可以使用 9 来代替 12 ,这要搜索树的结构就不会乱了。

也可以使用 13 代替 12 ,这样也不会是搜索树的结构乱了。
那么如何才能找到 9 和 13 呢?
在当前要删除的 cur 结点的左边的最右边 找到 9 。
在当前要删除的 cur 结点的右边的最左边 找到 13 。
9 在 cur 左边的最右边,说明 9 是左边的最大值。
13 在 cur 右边的最左边,说明 13 是右边的最小值。
最后为问题就转变为如何删 9 或 13,而且 9 作为左边的最大值,它的右边一定为空;
13 作为右边的最小值,它的左边一定为空。

如果找到的是 13 ,就定义一个 t 来指向 13 ,定义一个 tp 指向它的父节点。
此时 t 的 左边一定为空,但是右边可能不是空的。
如果要删除 13 ,直接让 tp.left = t.right 即可。

如果找到但是 9 , t 来指向 13 , tp 指向它的父节点。
此时 t 的 右边一定为空,但是左边可能不是空的。
如果要删除 9 ,直接让 tp.right = t.left 即可。
\
关于删除代码的分析
1、要有 cur 结点 和 parent 结点
ThreeNode cur = root;
ThreeNode parent = null; // 用来记录 cur 的位置
2、如果树是空的就肯定不存在要删除的结点。
while (cur != null) {}
3、首先要找到需要删除的结点
if (cur.val == key) {
} else if (cur.val < key) {
// 往右边找
parent = cur;
cur = cur.right;
} else {
// 往左边找
parent = cur;
cur = cur.left;
}
4、删除操作的实现
这里可以写一个方法,需要删除的时候直接调用。
// 这个方法中来判断当前的删除属于哪一种情况
private void removeNode(ThreeNode parent, ThreeNode cur) {}
下面是针对第一种情况(cur.left == null)的删除操作
if (cur.left == null) {
// 如果要删除的结点是root结点
if (cur == root) {
root = cur.right;
} else if (cur == parent.left) { // 要删除的cur结点在 p 的左边
parent.left = cur.right;
} else { // 要删除的cur结点在 p 的右边
parent.right = cur.right;
}
}
这是针对于第二种情况(cur.right == null)的删除操作。
else if (cur.right == null) { // 情况2
// 如果要删除的结点是 root结点
if (cur == root) {
root = cur.left;
} else if (cur == parent.left) { // 要删除的 cur 结点在 p 的左边
parent.left = cur.left;
} else { // 要删除的cur结点在 p 的右边
parent.right = cur.left;
}
下面是针对第三种情况(cur 的左右都不为空)的删除操作。
假设是找 13 结点。
1、先要找到 13 这个结点,可以先定义 target 为目标
ThreeNode target = cur.right;
此时 target 指向了 cur 结点的右边,13 就在 target 的最左边。

2、这个时候要定义 tp 指向 cur 的位置。
ThreeNode targetParent = cur;

3、tp 要在 t 移动前先记录一下 t 的位置
targetParent = target; // 提前记录 t 的位置
target = target.left; // 找到 13 这个结点

4、此时 cur 结点的值就变成了 t 的值
cur.val = target.val;
5、接下来就可以删除 13 了,也就是删除 t 。
targetParent.left = target.right;
如果 t 的右边为空就直接为空。
6、接下来处理特殊情况

如果 cur 的右边就是 t (要找到结点)
根据上面的演示可以发现分为两种情况。
第一种情况 cur.left == null
第二种情况 cur.right == null
可以先一个 if 语句判断属于哪一种情况。
// t 在 tp 的左边
if (target == targetParent.left) {
targetParent.left = target.right;
} else {
// t 在 tp 的右边
targetParent.right = target.right;
}
删除操作完整代码
// 删除一个结点操作
public void remove(int key) {
ThreeNode cur = root;
ThreeNode parent = null; // 用来记录 cur 的位置
// 删除的第一步是先找到这个结点
while (cur != null) {
// 找到了
if (cur.val == key) {
removeNode(parent, cur);
return;
} else if (cur.val < key) {
// 往右边找
parent = cur;
cur = cur.right;
} else {
// 往左边找
parent = cur;
cur = cur.left;
}
}
}
// 这是删除的具体实现
private void removeNode(ThreeNode parent, ThreeNode cur) {
// 这个方法中来判断当前的删除属于哪一种情况
// 情况1
if (cur.left == null) {
// 如果要删除的结点是root结点
if (cur == root) {
root = cur.right;
} else if (cur == parent.left) { // 要删除的cur结点在 p 的左边
parent.left = cur.right;
} else { // 要删除的cur结点在 p 的右边
parent.right = cur.right;
}
} else if (cur.right == null) { // 情况2
// 如果要删除的结点是 root结点
if (cur == root) {
root = cur.left;
} else if (cur == parent.left) { // 要删除的 cur 结点在 p 的左边
parent.left = cur.left;
} else { // 要删除的cur结点在 p 的右边
parent.right = cur.left;
}
} else { // 情况3
// 左右都不为空
ThreeNode target = cur.right; // 要找到的目标
ThreeNode targetParent = cur;
while (target.left != null) { // 如果t的左边为空就说明这是属于 cur.left == null 的情况
targetParent = target; // 提前记录 t 的位置
target = target.left;
}
cur.val = target.val;
// t 在 tp 的左边
if (target == targetParent.left) {
targetParent.left = target.right;
} else {
// t 在 tp 的右边
targetParent.right = target.right;
}
}
}
4. 以上三种操作的测试
1、首先测试插入操作。
int[] array = {5, 3, 4, 1, 7, 8, 2, 6, 0, 9};
把上面的数组插入到树中。
一个 for 循环实现。
for (int i = 0; i < array.length; i++) {
// 插入数组元素到搜索树中
binarySearchThree.insert(array[i]);
}
可以写一个中序遍历,根据打印出的中序遍历结果来判断插入是否正确。
中序遍历的写法:
public void inorder(ThreeNode root) {
if (root == null) {
return;
}
// 中序遍历 左根右
inorder(root.left);
System.out.print(root.val + " ");
inorder(root.right);
}
最后使用下面代码调用中序遍历打印结果。
binarySearchThree.inorder(binarySearchThree.root);

可以看到结果是正确的。
2、查找操作测试
// 测试查找
System.out.println(binarySearchThree.search(5)); // 可以找到 5 会返回 5 的地址
System.out.println(binarySearchThree.search(11)); // 找不到 11 会返回 null

可以看到结果是正确的。
3、删除操作的测试
删除以后打印删除后的结果,一下以删除 8 结点为演示。
// 测试删除操作
binarySearchThree.remove(8);
// 测试中序遍历
binarySearchThree.inorder(binarySearchThree.root);

可以看到打印的结果没有 8 。
5. 性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,
则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,
可能得到一下两种不同结构的二叉搜索树:


最优情况 下,二叉搜索树为完全二叉树,其平均比较次数为:

最差情况 下,二叉搜索树退化为单支树,其平均比较次数为: