大家好,用于训练深度学习模型的GPU功能强大但价格昂贵。为了有效利用GPU,开发者需要一个高效的数据管道,以便在GPU准备好计算下一个训练步骤时尽快将数据传输到GPU,使用Ray可以大大提高数据管道的效率。
1.训练数据管道的结构
首先考虑下面的模型训练伪代码:
for step in range(num_steps):
sample, target = next(dataset) # 步骤1
train_step(sample, target) # 步骤2
在步骤1中,获取下一个小批量的样本和标签。在步骤2中,它们被传递给train_step函数,该函数会将它们复制到GPU上,执行前向传递和反向传递以计算损失和梯度,并更新优化器的权重。
当数据集太大无法放入内存时,步骤1将从磁盘或网络中获取下一个小批量数据。此外步骤1还涉及一定量的预处理,输入数据必须转换为数字张量或张量集合,然后再馈送给模型。在某些情况下,在将它们传递给模型之前,张量上还会应用其他转换,例如归一化、绕轴旋转等。
如果工作流程是严格按顺序执行的,即先执行步骤1,然后再执行步骤2,那么模型将始终需要等待下一批数据的输入、输出和预处理操作。GPU将无法得到有效利用,它将在加载下一个小批量数据时处于空闲状态。
为了解决这个问题,可以将数据管道视为生产者——消费者的问题。数据管道生成小批量数据并写入有界缓冲区。模型/GPU从缓冲区中消费小批量数据,执行前向/反向计算并更新模型权重。如果数据管道能够以模型/GPU消费的速度快速生成小批量数据,那么训练过程将会非常高效。
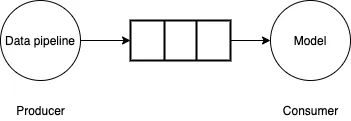
2.Tensorflow tf.data API
Tensorflow tf.data API提供了一组丰富的功能,可用于高效创建数据管道,使用后台线程获取小批量数据,使模型无需等待。仅仅预先获取数据还不够,如果生成小批量数据的速度比GPU消费数据的速度慢,那么就需要使用并行化来加快数据的读取和转换。为此,Tensorflow提供了交错功能以利用多个线程并行读取数据,以及并行映射功能使用多个线程对小批量数据进行转换。
由于这些API基于多线程,因此可能会受到Python全局解释器锁(GIL)的限制。Python GIL限制了Python解释器一次只能运行单个线程的字节码。如果在管道中使用纯TensorFlow代码,通常不会受到这种限制,因为TensorFlow核心执行引擎在GIL的范围之外工作。但是,如果使用的第三方库没有发布GIL或者使用Python进行大量计算,那么依赖多线程来并行化管道就不可行。
3.使用多进程并行化数据管道
考虑以下生成器函数,该函数模拟加载和执行一些计算以生成小批量数据样本和标签。
def data_generator():
for _ in range(10):
# 模拟获取
# 从磁盘/网络
time.sleep(0.5)
# 模拟计算
for _ in range(10000):
pass
yield (
np.random.random((4, 1000000, 3)).astype(np.float32),
np.random.random((4, 1)).astype(np.float32)
)
接下来,在虚拟的训练管道中使用该生成器,并测量生成小批量数据所花费的平均时间。
generator_dataset = tf.data.Dataset.from_generator(
data_generator,
output_types=(tf.float64, tf.float64),
output_shapes=((4, 1000000, 3), (4, 1))
).prefetch(tf.data.experimental.AUTOTUNE)
st = time.perf_counter()
times = []
for _ in generator_dataset:
en = time.perf_counter()
times.append(en - st)
# 模拟训练步骤
time.sleep(0.1)
st = time.perf_counter()
print(np.mean(times))
据观察,平均耗时约为0.57秒(在配备Intel Core i7处理器的Mac笔记本电脑上测量)。如果这是一个真实的训练循环,GPU的利用率将相当低,它只需花费0.1秒进行计算,然后闲置0.57秒等待下一个批次数据。
为了加快数据加载速度,可以使用多进程生成器。
from multiprocessing import Queue, cpu_count, Process
def mp_data_generator():
def producer(q):
for _ in range(10):
# 模拟获取
# 从磁盘/网络
time.sleep(0.5)
# 模拟计算
for _ in range(10000000):
pass
q.put((
np.random.random((4, 1000000, 3)).astype(np.float32),
np.random.random((4, 1)).astype(np.float32)
))
q.put("DONE")
queue = Queue(cpu_count()*2)
num_parallel_processes = cpu_count()
producers = []
for _ in range(num_parallel_processes):
p = Process(target=producer, args=(queue,))
p.start()
producers.append(p)
done_counts = 0
while done_counts < num_parallel_processes:
msg = queue.get()
if msg == "DONE":
done_counts += 1
else:
yield msg
queue.join()
测量等待下一个小批次数据所花费的时间,得到的平均时间为0.08秒,速度提高了近7倍,但理想情况下,希望这个时间接近0。
如果进行分析,可以发现相当多的时间都花在了准备数据的反序列化上。在多进程生成器中,生产者进程会返回大型NumPy数组,这些数组需要进行准备,然后在主进程中进行反序列化。
4.使用Ray并行化数据管道
Ray是一个用于在Python中运行分布式计算的框架,它带有一个共享内存对象存储区,可在不同进程间高效地传输对象。在不进行任何序列化和反序列化的情况下,对象存储区中的Numpy数组可在同一节点上的worker之间共享。Ray还可以轻松实现数据加载在多台机器上的扩展,并使用Apache Arrow高效地序列化和反序列化大型数组。
Ray带有一个实用函数from_iterators,可以创建并行迭代器,开发者可以用它包装data_generator生成器函数。
import ray
def ray_generator():
num_parallel_processes = cpu_count()
return ray.util.iter.from_iterators(
[data_generator]*num_parallel_processes
).gather_async()
使用ray_generator,测量等待下一个小批量数据所花费的时间为0.02秒,比使用多进程处理的速度提高了4倍。






![[密码学]DES](https://img-blog.csdnimg.cn/direct/35cb8bb4644e4840a37ff4d27f13b99f.png)