05、基于梯度下降的协同过滤算法理论与实践Python
开始学习机器学习啦,已经把吴恩达的课全部刷完了,现在开始熟悉一下复现代码。对这个手写数字实部比较感兴趣,作为入门的素材非常合适。
协同过滤算法是一种常用的推荐算法,基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐。它的主要实现方式包括:
- 根据和你有共同喜好的人给你推荐。
- 根据你喜欢的物品给你推荐相似物品。
因此,常用的协同过滤算法分为两种,基于用户的协同过滤算法(user-based collaborative filtering),以及基于物品的协同过滤算法(item-based collaborative filtering)。
这种算法的特点可以概括为“人以类聚,物以群分”,并据此进行预测和推荐。例如,基于物品的协同过滤算法会给用户推荐与他之前喜欢的物品相似的物品;而基于用户的协同过滤算法会给用户推荐与他兴趣相似的用户喜欢的物品。
1、基于用户的协同过滤算法案例与直观解释
协同过滤算法算是上到今天的课中比较弯弯绕绕的东西了,在此以下面的电影打分案例为例:

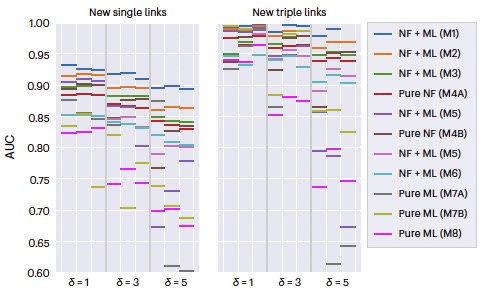
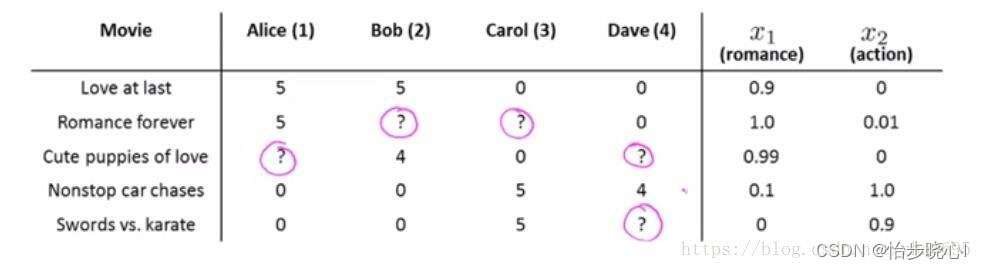
竖过来那一栏是电影的名称,横着的四个是打分的人的名字,最后两个x是电影的特征。问号表示该用户没有对电影进行过评分,与此同时,电影的特征x是完全未知的。
从电影推荐的角度来讲,对正在浏览的用户,若其对某个电影潜在的评分越高,则越有可能将此电影推荐给这个用户。而这个潜在的评分正是算法所需要得到的。
这个算法是如何运作的呢?其底层的直觉是基于用户的相似性。比如,小张是个爱猫人士,喜欢看有猫猫的电影,他看过许多猫猫电影并给这类电影打了高分;然后,小王来了,小王初来乍到也给几部猫猫片打了高分,平台此时认为小王和小张相似,从而把小张打高分的电影推荐给小王。
但是,平台并不知道小张和小王的相似之处在于喜欢看猫猫片(并不了解事物的特征的具体情况),其只知道这两个人爱好类似而已。
这种基于相似度的机制在很多文章中有介绍。如:推荐算法之协同过滤算法详解(原理,流程,步骤,适用场景)。但是,在吴恩达的课程里面,所介绍的基于梯度下降的协同过滤算法好像并没有专门涉及这一相似的矩阵计算概念?在此对这种基于机器学习的协同过滤算法简单介绍。
2、基于梯度下降的协同过滤算法实现原理
这边主要是介绍吴恩达视频里面的实现思路。用户给电影打高分,是因为用户喜欢电影的某项特征,以下面为例(用户Alice和Bob给Love at last打高分其实是两个条件,其一是电影具备浪漫特征,其二是用户喜欢浪漫的东西):
简单来说可以简化为以下的公式(w就是用户自己的喜好特征,x是电影本身的特质,最终得到的是电影的打分):
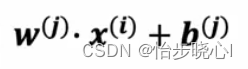
但是对于基于用户的协同过滤算法案例的数据,也就是第一张图,用户自己的喜好特征和电影本身的特质都是未知的(只有部分用户的打分已知),那么该如何进行打分呢?答案是随机初始化(或者合理猜测)然后使用梯度下降得到最优的w、x、b,然后就能计算打分数据y进而进行推荐了。
这个梯度下降实际包含两个过程,首先是从电影的特征和实际打分训练得到用户的特征w、b,其次是从用户的特征w、b和实际打分训练得到电影的特征,这两个过程的成本函数可以相加合一,毕竟实际的未知量是w、b、x:

3、基于梯度下降的协同过滤算法实现步骤
step1:加载数据
其中R是bool类型的矩阵,第i行第j列代表第j个用户是否对第i个电影打分
Y是打分的矩阵,第i行第j列代表第j个用户对第i个电影的打分的分数
def load_ratings_small():
file = open('./Collaborative_Filtering_data/small_movies_Y.csv', 'rb')
Y = loadtxt(file, delimiter=",")
file = open('./Collaborative_Filtering_data/small_movies_R.csv', 'rb')
R = loadtxt(file, delimiter=",")
return (Y, R)
#加载数据
# Y是所有电影的打分的数据,数据大小是nm*nu
# R的数据大小是nm*nu,格式为bool,表示第j列的用户是否对第i行的用户打分
Y, R = load_ratings_small()
num_movies, num_users = Y.shape
step2:构建成本函数
成本函数的构建参考2、基于梯度下降的协同过滤算法实现原理中的图片里面的公式,当然可以使用循环来实现(X, W, b可以随机初始化):
def cofi_cost_func(X, W, b, Y, R, lambda_):
"""
计算协同过滤的代价函数。
参数:
X -- 电影的特征矩阵
W -- 用户的权重矩阵
b -- 用户的偏置向量
Y -- 用户对电影的评分矩阵
R -- 指示用户是否对电影进行了评分的矩阵
lambda_ -- 正则化参数
返回:
J -- 代价函数的值
"""
nm, nu = Y.shape # 获取评分矩阵Y的形状,nm为电影数量,nu为用户数量
J = 0 # 初始化代价函数值为0
# 遍历每一个用户
for j in range(nu):
# 获取第j个用户的兴趣权重
w = W[j, :]
b_j = b[0, j] # 获取第j个用户的偏置值
# 遍历每一部电影
for i in range(nm):
# 获取第i部电影的特征,和第j个用户对其的打分
x = X[i, :]
y = Y[i, j]
r = R[i, j] # 获取第j个用户对第i部电影的评分指示值(是否进行了评分)
# 计算代价函数中的误差项并累加到J中
J += np.square(r * (np.dot(w, x) + b_j - y))
# 正则化部分,防止过拟合
J += lambda_ * (np.sum(np.square(W)) + np.sum(np.square(X)))
J = J / 2 # 对J进行平均处理
return J # 返回计算得到的代价函数值
更好的方法是使用矩阵运算来实现,这样速度更快:
def cofi_cost_func_v(X, W, b, Y, R, lambda_):
"""
计算基于内容的过滤的代价函数。
为了速度进行了向量化。使用TensorFlow操作以与自定义训练循环兼容。
参数:
X (ndarray (num_movies,num_features)):物品特征矩阵
W (ndarray (num_users,num_features)):用户参数矩阵
b (ndarray (1, num_users)):用户参数向量
Y (ndarray (num_movies,num_users)):用户对电影的评分矩阵
R (ndarray (num_movies,num_users)):矩阵,其中R(i, j) = 1表示第j个用户对第i部电影进行了评分
lambda_ (float):正则化参数
返回:
J (float):代价函数的值
"""
# 使用矩阵乘法和偏置计算预测评分,然后与实际评分相减,并乘以评分指示矩阵R
j = (tf.linalg.matmul(X, tf.transpose(W)) + b - Y) * R
# 计算代价函数的值,包括正则化部分
J = 0.5 * tf.reduce_sum(j**2) + (lambda_ / 2) * (tf.reduce_sum(X**2) + tf.reduce_sum(W**2))
return J
step3:训练数据预处理与随机初始化
def normalizeRatings(Y, R):
"""
规范化用户评分矩阵,使其具有零均值。
参数:
Y (ndarray): 用户对物品的评分矩阵,形状通常为 (num_users, num_items)。
R (ndarray): 指示矩阵,其中 R[i, j] = 1 表示用户 i 对物品 j 进行了评分,否则为 0。
返回:
Ynorm (ndarray): 规范化后的评分矩阵。
Ymean (ndarray): 每个用户的平均评分。
"""
# 计算每个用户的加权平均分。这里,加权是指只考虑用户实际评分的项目。
# 分母加上 1e-12 是为了避免除以零的情况。
Ymean = (np.sum(Y * R, axis=1) / (np.sum(R, axis=1) + 1e-12)).reshape(-1, 1)
# 从原始评分中减去每个用户的平均分,得到规范化后的评分。
# 注意,我们只更新那些用户实际评分的项目。
Ynorm = Y - np.multiply(Ymean, R)
return Ynorm, Ymean
# 加载评分
Y, R = load_ratings_small()
# 规范化数据集,使其具有零均值
Ynorm, Ymean = normalizeRatings(Y, R)
# 开始训练
num_movies, num_users = Y.shape # 获取电影和用户的数量
num_features = 100 # 设置特征的数量
# 设置初始参数(W, X),使用tf.Variable来跟踪这些变量,这样在训练过程中可以更新它们。
tf.random.set_seed(1234) # 设置随机种子以确保结果的一致性
W = tf.Variable(tf.random.normal((num_users, num_features), dtype=tf.float64), name='W') # 用户参数矩阵
X = tf.Variable(tf.random.normal((num_movies, num_features), dtype=tf.float64), name='X') # 电影特征矩阵
b = tf.Variable(tf.random.normal((1, num_users), dtype=tf.float64), name='b') # 用户偏置参数
step4:设置优化器,开始梯度下降
# 实例化一个优化器,这里选择的是Adam优化器,学习率设置为0.1
optimizer = keras.optimizers.Adam(learning_rate=1e-1)
# 设置迭代次数和正则化参数
iterations = 400
lambda_ = 1
# 开始迭代
for iter in range(iterations):
# 使用TensorFlow的GradientTape来记录计算代价所涉及的操作
with tf.GradientTape() as tape:
# 计算代价(前向传播已经包含在cost_value中)
cost_value = cofi_cost_func_v(X, W, b, Ynorm, R, lambda_)
# 使用gradient tape自动获取可训练变量关于损失的梯度
grads = tape.gradient(cost_value, [X, W, b])
# 使用优化器运行一步梯度下降,更新变量的值以最小化损失
optimizer.apply_gradients(zip(grads, [X, W, b]))
# 定期记录训练损失
if iter % 20 == 0:
print(f"Training loss at iteration {iter}: {cost_value:0.1f}")
step5:对所有用户进行预测,并去归一化
# Make a prediction using trained weights and biases
p = np.matmul(X.numpy(), np.transpose(W.numpy())) + b.numpy()
#restore the mean
pm = p + Ymean
step6:查看结果
# 查看第一个用户的结果
my_predictions = pm[:,0]
# sort predictions
ix = tf.argsort(my_predictions, direction='DESCENDING')
# 查看第一个用户的打分最高的结果
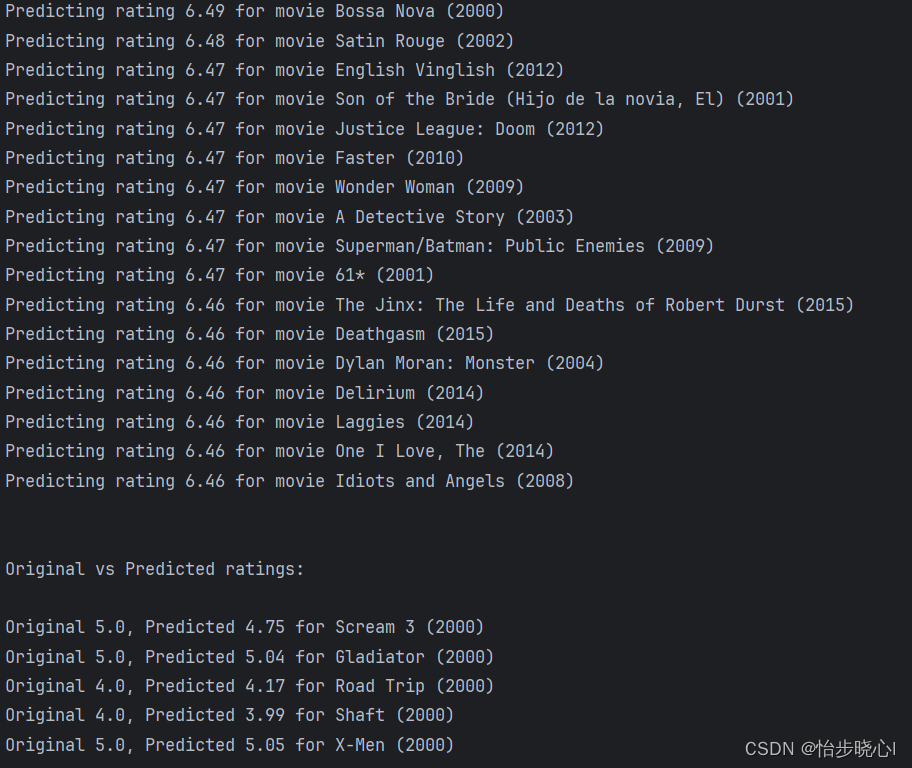
for i in range(17):
j = ix[i]
if j not in my_rated:
print(f'Predicting rating {my_predictions[j]:0.2f} for movie {movieList[j]}')
# 查看第一个用户的预测打分和实际打分对比
print('\n\nOriginal vs Predicted ratings:\n')
for i in range(len(Y[:,0])):
if Y[i,0] > 0:
print(f'Original {Y[i,0]}, Predicted {my_predictions[i]:0.2f} for {movieList[i]}')
查看的是第一个用户的结果,首先查看的是系统对第一个用户的打分的排名最高的结果,其次是系统对第一个用户预计的打分结果和实际打分结果的对比:
4、全部代码
数据集和全部代码在最上方链接下载:
import numpy as np
import tensorflow as tf
from tensorflow import keras
from numpy import loadtxt
import pandas as pd
def normalizeRatings(Y, R):
"""
规范化用户评分矩阵,使其具有零均值。
参数:
Y (ndarray): 用户对物品的评分矩阵,形状通常为 (num_users, num_items)。
R (ndarray): 指示矩阵,其中 R[i, j] = 1 表示用户 i 对物品 j 进行了评分,否则为 0。
返回:
Ynorm (ndarray): 规范化后的评分矩阵。
Ymean (ndarray): 每个用户的平均评分。
"""
# 计算每个用户的加权平均分。这里,加权是指只考虑用户实际评分的项目。
# 分母加上 1e-12 是为了避免除以零的情况。
Ymean = (np.sum(Y * R, axis=1) / (np.sum(R, axis=1) + 1e-12)).reshape(-1, 1)
# 从原始评分中减去每个用户的平均分,得到规范化后的评分。
# 注意,我们只更新那些用户实际评分的项目。
Ynorm = Y - np.multiply(Ymean, R)
return Ynorm, Ymean
def load_precalc_params_small():
file = open('./Collaborative_Filtering_data/small_movies_X.csv', 'rb')
X = loadtxt(file, delimiter=",")
file = open('./Collaborative_Filtering_data/small_movies_W.csv', 'rb')
W = loadtxt(file, delimiter=",")
file = open('./Collaborative_Filtering_data/small_movies_b.csv', 'rb')
b = loadtxt(file, delimiter=",")
b = b.reshape(1, -1)
num_movies, num_features = X.shape
num_users, _ = W.shape
return (X, W, b, num_movies, num_features, num_users)
def load_ratings_small():
file = open('./Collaborative_Filtering_data/small_movies_Y.csv', 'rb')
Y = loadtxt(file, delimiter=",")
file = open('./Collaborative_Filtering_data/small_movies_R.csv', 'rb')
R = loadtxt(file, delimiter=",")
return (Y, R)
def load_Movie_List_pd():
""" returns df with and index of movies in the order they are in in the Y matrix """
df = pd.read_csv('./Collaborative_Filtering_data/small_movie_list.csv', header=0, index_col=0, delimiter=',', quotechar='"')
mlist = df["title"].to_list()
return(mlist, df)
def cofi_cost_func(X, W, b, Y, R, lambda_):
nm, nu = Y.shape
J = 0
for j in range(nu):
# 获取第j个用户的兴趣权重
w = W[j, :]
b_j = b[0, j]
for i in range(nm):
#获取第i个电影的特征,和第j个用户对其的打分
x = X[i, :]
y = Y[i, j]
r = R[i, j]
J += np.square(r * (np.dot(w, x) + b_j - y))
# 正则化
J += lambda_ * (np.sum(np.square(W)) + np.sum(np.square(X)))
J = J / 2
return J
def cofi_cost_func_v(X, W, b, Y, R, lambda_):
"""
计算基于内容的过滤的代价函数。
为了速度进行了向量化。使用TensorFlow操作以与自定义训练循环兼容。
参数:
X (ndarray (num_movies,num_features)):物品特征矩阵
W (ndarray (num_users,num_features)):用户参数矩阵
b (ndarray (1, num_users)):用户参数向量
Y (ndarray (num_movies,num_users)):用户对电影的评分矩阵
R (ndarray (num_movies,num_users)):矩阵,其中R(i, j) = 1表示第j个用户对第i部电影进行了评分
lambda_ (float):正则化参数
返回:
J (float):代价函数的值
"""
# 使用矩阵乘法和偏置计算预测评分,然后与实际评分相减,并乘以评分指示矩阵R
j = (tf.linalg.matmul(X, tf.transpose(W)) + b - Y) * R
# 计算代价函数的值,包括正则化部分
J = 0.5 * tf.reduce_sum(j ** 2) + (lambda_ / 2) * (tf.reduce_sum(X ** 2) + tf.reduce_sum(W ** 2))
return J
#加载数据
# Y是所有电影的打分的数据,数据大小是nm*nu
# R的数据大小是nm*nu,格式为bool,表示第j列的用户是否对第i行的用户打分
Y, R = load_ratings_small()
num_movies, num_users = Y.shape
print("Y", Y.shape, "R", R.shape)
print("num_movies", num_movies)
print("num_users", num_users)
# 按照自己的喜好给电影打分
movieList, movieList_df = load_Movie_List_pd()
my_ratings = np.zeros(num_movies) # Initialize my ratings
# Check the file small_movie_list.csv for id of each movie in our dataset
# For example, Toy Story 3 (2010) has ID 2700, so to rate it "5", you can set
my_ratings[2700] = 5
#Or suppose you did not enjoy Persuasion (2007), you can set
my_ratings[2609] = 2;
# We have selected a few movies we liked / did not like and the ratings we
# gave are as follows:
my_ratings[929] = 5 # Lord of the Rings: The Return of the King, The
my_ratings[246] = 5 # Shrek (2001)
my_ratings[2716] = 3 # Inception
my_ratings[1150] = 5 # Incredibles, The (2004)
my_ratings[382] = 2 # Amelie (Fabuleux destin d'Amélie Poulain, Le)
my_ratings[366] = 5 # Harry Potter and the Sorcerer's Stone (a.k.a. Harry Potter and the Philosopher's Stone) (2001)
my_ratings[622] = 5 # Harry Potter and the Chamber of Secrets (2002)
my_ratings[988] = 3 # Eternal Sunshine of the Spotless Mind (2004)
my_ratings[2925] = 1 # Louis Theroux: Law & Disorder (2008)
my_ratings[2937] = 1 # Nothing to Declare (Rien à déclarer)
my_ratings[793] = 5 # Pirates of the Caribbean: The Curse of the Black Pearl (2003)
my_rated = [i for i in range(len(my_ratings)) if my_ratings[i] > 0]
print('\nNew user ratings:\n')
for i in range(len(my_ratings)):
if my_ratings[i] > 0 :
print(f'Rated {my_ratings[i]} for {movieList_df.loc[i,"title"]}')
# 加载评分
Y, R = load_ratings_small()
# Y= np.c_[my_ratings, Y]
# R= np.c_[(my_ratings != 0).astype(int), R]
# 规范化数据集,使其具有零均值
Ynorm, Ymean = normalizeRatings(Y, R)
# 开始训练
num_movies, num_users = Y.shape # 获取电影和用户的数量
num_features = 100 # 设置特征的数量
# 设置初始参数(W, X),使用tf.Variable来跟踪这些变量,这样在训练过程中可以更新它们。
tf.random.set_seed(1234) # 设置随机种子以确保结果的一致性
W = tf.Variable(tf.random.normal((num_users, num_features), dtype=tf.float64), name='W') # 用户参数矩阵
X = tf.Variable(tf.random.normal((num_movies, num_features), dtype=tf.float64), name='X') # 电影特征矩阵
b = tf.Variable(tf.random.normal((1, num_users), dtype=tf.float64), name='b') # 用户偏置参数
# 实例化一个优化器,这里选择的是Adam优化器,学习率设置为0.1
optimizer = keras.optimizers.Adam(learning_rate=1e-1)
# 设置迭代次数和正则化参数
iterations = 400
lambda_ = 1
# 开始迭代
for iter in range(iterations):
# 使用TensorFlow的GradientTape来记录计算代价所涉及的操作
with tf.GradientTape() as tape:
# 计算代价(前向传播已经包含在cost_value中)
cost_value = cofi_cost_func_v(X, W, b, Ynorm, R, lambda_)
# 使用gradient tape自动获取可训练变量关于损失的梯度
grads = tape.gradient(cost_value, [X, W, b])
# 使用优化器运行一步梯度下降,更新变量的值以最小化损失
optimizer.apply_gradients(zip(grads, [X, W, b]))
# 定期记录训练损失
if iter % 20 == 0:
print(f"Training loss at iteration {iter}: {cost_value:0.1f}")
# Make a prediction using trained weights and biases
p = np.matmul(X.numpy(), np.transpose(W.numpy())) + b.numpy()
#restore the mean
pm = p + Ymean
my_predictions = pm[:,0]
# sort predictions
ix = tf.argsort(my_predictions, direction='DESCENDING')
for i in range(17):
j = ix[i]
if j not in my_rated:
print(f'Predicting rating {my_predictions[j]:0.2f} for movie {movieList[j]}')
print('\n\nOriginal vs Predicted ratings:\n')
for i in range(len(Y[:,0])):
if Y[i,0] > 0:
print(f'Original {Y[i,0]}, Predicted {my_predictions[i]:0.2f} for {movieList[i]}')