1、需求
想要获取网站上所有的气象信息,网站如下所示:

目前总共有67页,随便点开一个如下所示:

需要获取所有天气数据,如果靠一个个点开再一个个复制粘贴那么也不知道什么时候才能完成,这个时候就可以使用C#来实现网页爬虫获取这些数据。
2、效果
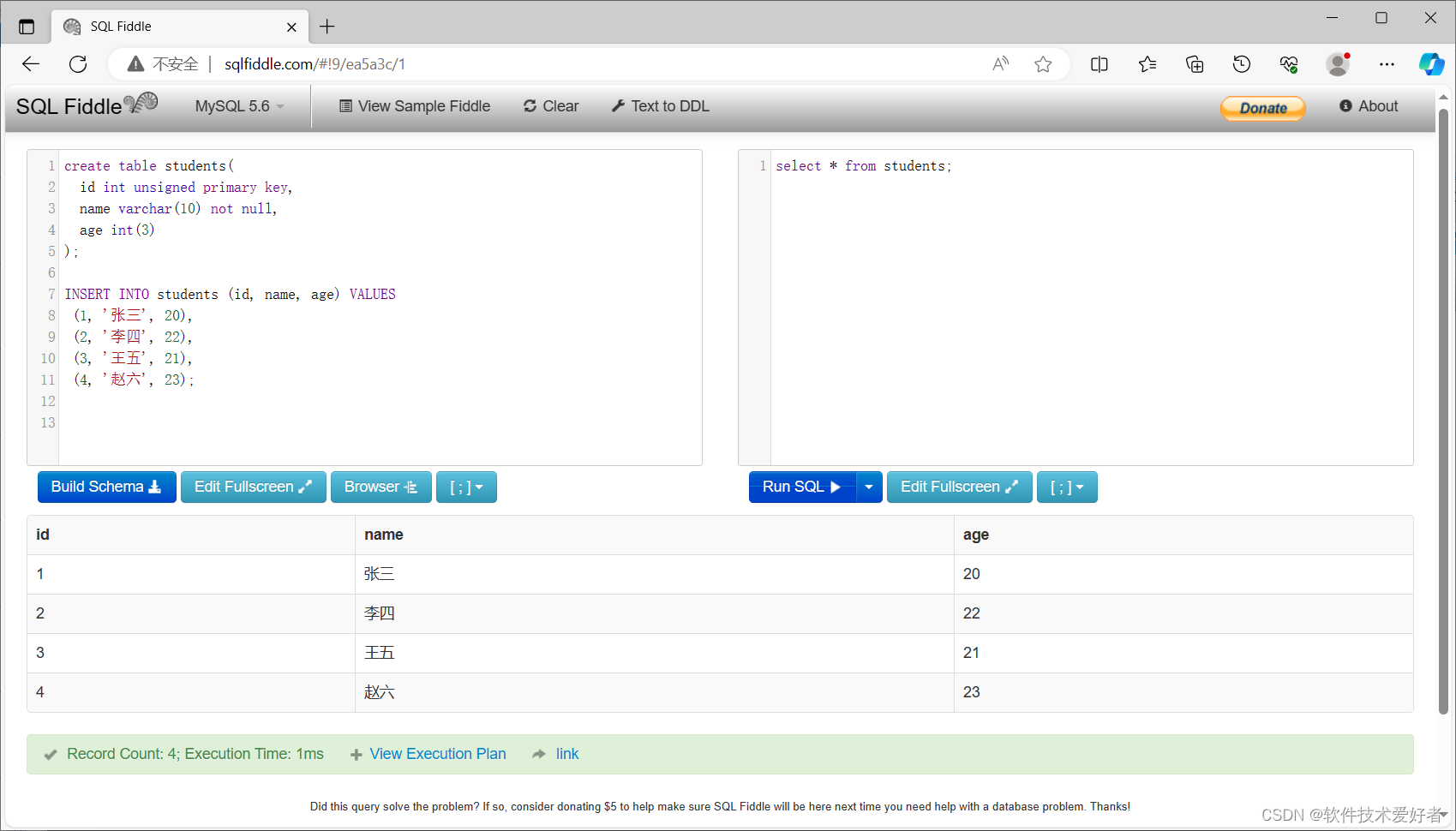
先来看下实现的效果,所有数据都已存入数据库中,如下所示:

总共有4万多条数据。
3、具体实现
构建每一页的URL
第一页的网址如下所示:

最后一页的网址如下所示:
![]()
可以发现是有规律的,那么就可以先尝试构建出每个页面的URL
// 发送 GET 请求
string url = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
HttpResponseMessage response = await httpClient.GetAsync(url);
// 处理响应
if (response.IsSuccessStatusCode)
{
string responseBody = await response.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody);
//获取需要的数据所在的节点
var node = doc.DocumentNode.SelectSingleNode("//div[@class=\"page\"]/script");
string rawText = node.InnerText.Trim();
// 使用正则表达式来匹配页数数据
Regex regex = new Regex(@"\b(\d+)\b");
Match match = regex.Match(rawText);
if (match.Success)
{
string pageNumber = match.Groups[1].Value;
Urls = GetUrls(Convert.ToInt32(pageNumber));
MessageBox.Show($"获取每个页面的URL成功,总页面数为:{Urls.Length}");
}
} //构造每一页的URL
public string[] GetUrls(int pageNumber)
{
string[] urls = new string[pageNumber];
for (int i = 0; i < urls.Length; i++)
{
if (i == 0)
{
urls[i] = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/index.shtml";
}
else
{
urls[i] = $"https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/index_{i}.shtml";
}
}
return urls;
}这里使用了HtmlAgilityPack

HtmlAgilityPack(HAP)是一个用于处理HTML文档的.NET库。它允许你方便地从HTML文档中提取信息,修改HTML结构,并执行其他HTML文档相关的操作。HtmlAgilityPack 提供了一种灵活而强大的方式来解析和处理HTML,使得在.NET应用程序中进行网页数据提取和处理变得更加容易。
// 使用HtmlAgilityPack解析网页内容
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml("需要解析的Html");
//获取需要的数据所在的节点
var node = doc.DocumentNode.SelectSingleNode("XPath");那么XPath是什么呢?
XPath(XML Path Language)是一种用于在XML文档中定位和选择节点的语言。它是W3C(World Wide Web Consortium)的标准,通常用于在XML文档中执行查询操作。XPath提供了一种简洁而强大的方式来导航和操作XML文档的内容。
构建每一天的URL
获取到了每一页的URL之后,我们发现在每一页的URL都可以获取关于每一天的URL信息,如下所示:
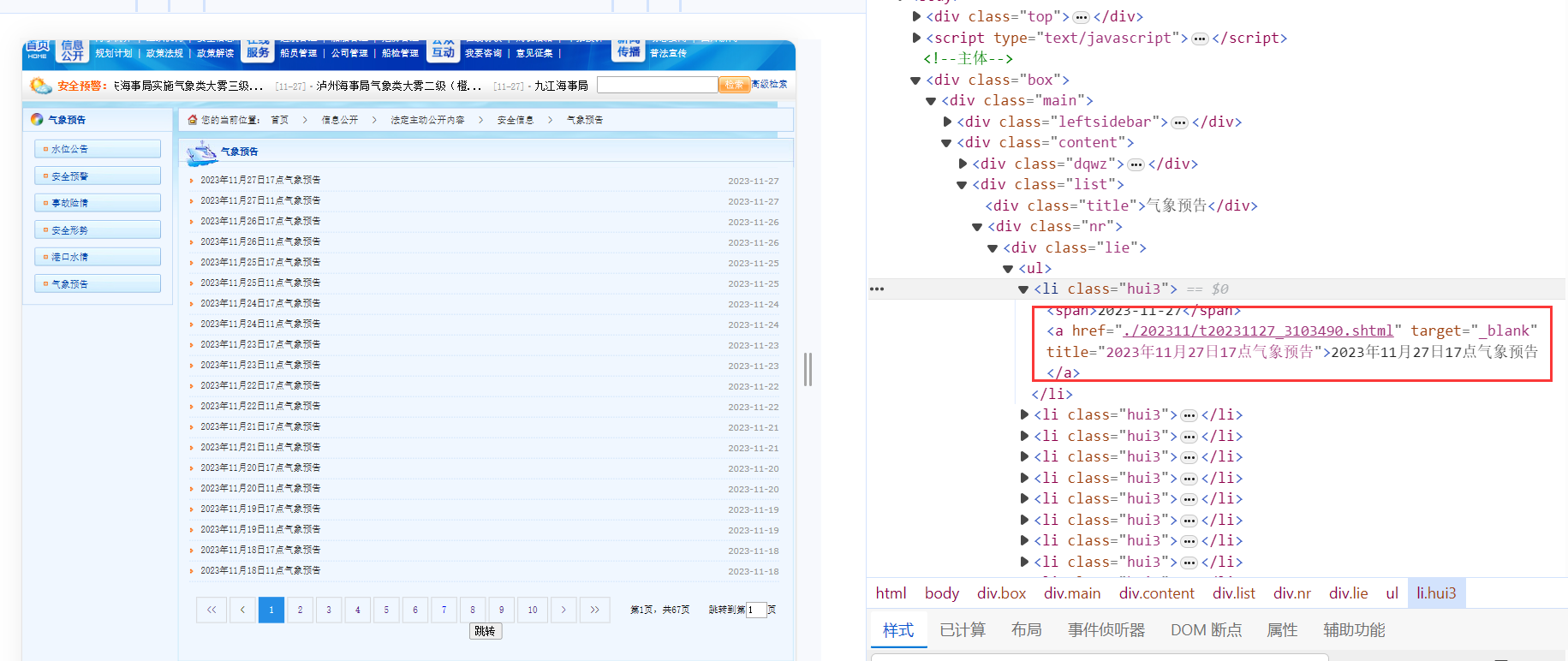
可以进一步构建每一天的URL,同时可以根据a的文本获取时间,当然也可以通过其他方式获取时间,但是这种可以获取到11点或者17点。
代码如下所示:
for (int i = 0; i < Urls.Length; i++)
{
// 发送 GET 请求
string url2 = Urls[i];
HttpResponseMessage response2 = await httpClient.GetAsync(url2);
// 处理响应
if (response2.IsSuccessStatusCode)
{
string responseBody2 = await response2.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody2);
var nodes = doc.DocumentNode.SelectNodes("//div[@class=\"lie\"]/ul/li");
for (int j = 0; j < nodes.Count; j++)
{
var name = nodes[j].ChildNodes[3].InnerText;
//只有name符合下面的格式才能成功转换为时间,所以这里需要有一个判断
if (name != "" && name.Contains("气象预告"))
{
var dayUrl = new DayUrl();
//string format;
//DateTime date;
// 定义日期时间格式
string format = "yyyy年M月d日H点气象预告";
// 解析字符串为DateTime
DateTime date = DateTime.ParseExact(name, format, null);
var a = nodes[j].ChildNodes[3];
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = "";
realUrl = newValue + urlText.Substring(1);
dayUrl.Date = date;
dayUrl.Url = realUrl;
dayUrlList.Add(dayUrl);
}
else
{
Debug.WriteLine($"在{name}处,判断不符合要求");
}
}
}
}
// 将数据存入SQLite数据库
db.Insertable(dayUrlList.OrderBy(x => x.Date).ToList()).ExecuteCommand();
MessageBox.Show($"获取每天的URL成功,共有{dayUrlList.Count}条");
}在这一步骤需要注意的是XPath的书写,以及每一天URL的构建,以及时间的获取。
XPath的书写:
var nodes = doc.DocumentNode.SelectNodes("//div[@class=\"lie\"]/ul/li");表示一个类名为"lie"的div下的ul标签下的所有li标签,如下所示:
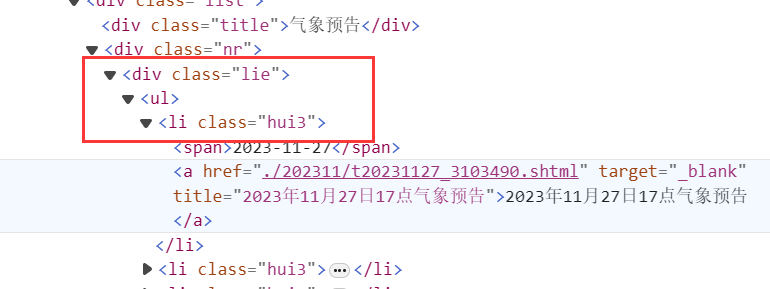
构建每一天的URL:
var a = nodes[j].ChildNodes[3];
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = "";
realUrl = newValue + urlText.Substring(1);这里获取li标签下的a标签,如下所示:

string urlText = a.GetAttributeValue("href", "");这段代码获取a标签中href属性的值,这里是./202311/t20231127_3103490.shtml。
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = newValue + urlText.Substring(1);这里是在拼接每一天的URL。
var name = nodes[j].ChildNodes[3].InnerText;
// 定义日期时间格式
string format = "yyyy年M月d日H点气象预告";
// 解析字符串为DateTime
DateTime date = DateTime.ParseExact(name, format, null);这里是从文本中获取时间,比如文本的值也就是name的值为:“2023年7月15日17点气象预告”,name获得的date就是2023-7-15 17:00。
// 将数据存入SQLite数据库
db.Insertable(dayUrlList.OrderBy(x => x.Date).ToList()).ExecuteCommand();
MessageBox.Show($"获取每天的URL成功,共有{dayUrlList.Count}条");
这里是将数据存入数据库中,ORM使用的是SQLSugar,类DayUrl如下:
internal class DayUrl
{
[SugarColumn(IsPrimaryKey = true, IsIdentity = true)]
public int Id { get; set; }
public DateTime Date { get; set; }
public string Url { get; set; }
}最后获取每一天URL的效果如下所示:
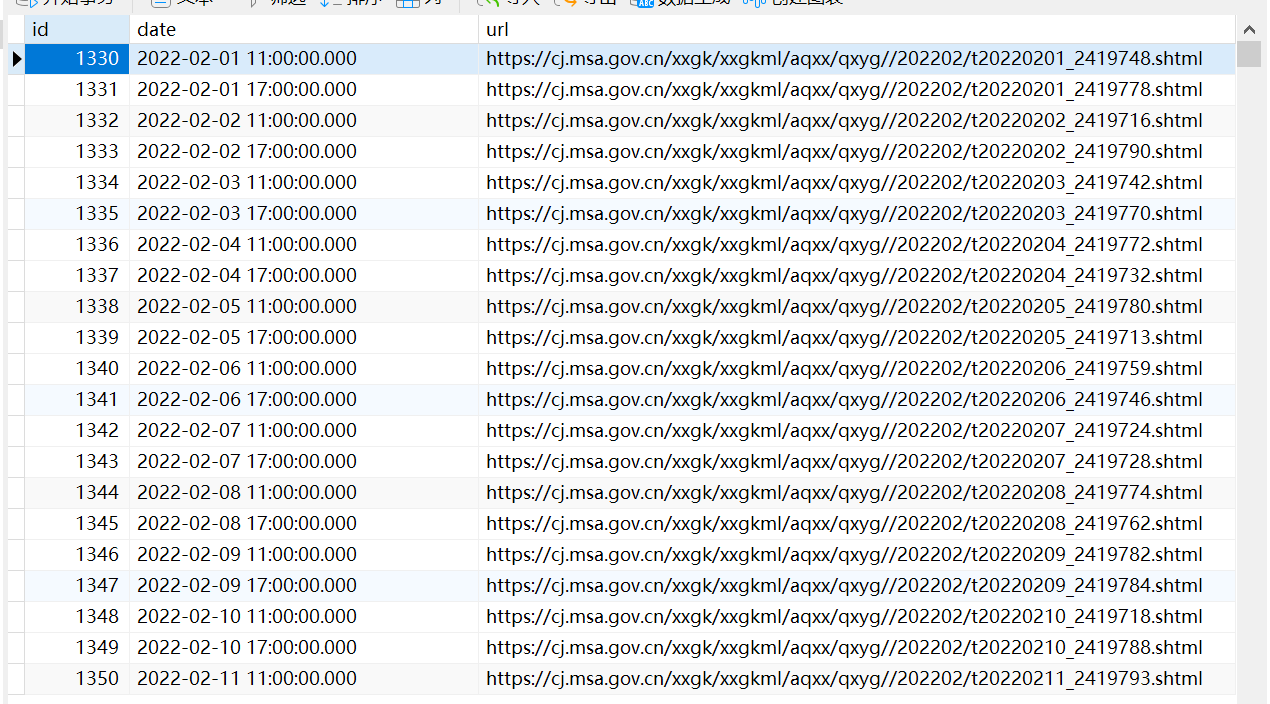
获取温度数据
需要获取的内容如下:

设计对应的类如下:
internal class WeatherData
{
[SugarColumn(IsPrimaryKey = true, IsIdentity = true)]
public int Id { get; set; }
public string? StationName { get; set; }
public string? Weather { get; set; }
public string? Tem_Low { get; set; }
public string? Tem_High { get; set; }
public string? Wind { get; set; }
public string? Visibility_Low { get; set; }
public string? Visibility_High { get; set; }
public string? Fog { get; set; }
public string? Haze { get; set; }
public DateTime Date { get; set; }
}增加了一个时间,方便以后根据时间获取。
获取温度数据的代码如下:
var list = db.Queryable<DayUrl>().ToList();
for (int i = 0; i < list.Count; i++)
{
HttpResponseMessage response = await httpClient.GetAsync(list[i].Url);
// 处理响应
if (response.IsSuccessStatusCode)
{
string responseBody2 = await response.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody2);
var nodes = doc.DocumentNode.SelectNodes("//table");
if (nodes != null)
{
var table = nodes[5];
var trs = table.SelectNodes("tbody/tr");
for (int j = 1; j < trs.Count; j++)
{
var tds = trs[j].SelectNodes("td");
switch (tds.Count)
{
case 8:
var wd8 = new WeatherData();
wd8.StationName = tds[0].InnerText.Trim().Replace(" ", "");
wd8.Weather = tds[1].InnerText.Trim().Replace(" ", "");
wd8.Tem_Low = tds[2].InnerText.Trim().Replace(" ", "");
wd8.Tem_High = tds[3].InnerText.Trim().Replace(" ", "");
wd8.Wind = tds[4].InnerText.Trim().Replace(" ", "");
wd8.Visibility_Low = tds[5].InnerText.Trim().Replace(" ", "");
wd8.Visibility_High = tds[6].InnerText.Trim().Replace(" ", "");
wd8.Fog = tds[7].InnerText.Trim().Replace(" ", "");
wd8.Date = list[i].Date;
weatherDataList.Add(wd8);
break;
case 9:
var wd9 = new WeatherData();
wd9.StationName = tds[0].InnerText.Trim().Replace(" ", "");
wd9.Weather = tds[1].InnerText.Trim().Replace(" ", "");
wd9.Tem_Low = tds[2].InnerText.Trim().Replace(" ", "");
wd9.Tem_High = tds[3].InnerText.Trim().Replace(" ", "");
wd9.Wind = tds[4].InnerText.Trim().Replace(" ", "");
wd9.Visibility_Low = tds[5].InnerText.Trim().Replace(" ", "");
wd9.Visibility_High = tds[6].InnerText.Trim().Replace(" ", "");
wd9.Fog = tds[7].InnerText.Trim().Replace(" ", "");
wd9.Haze = tds[8].InnerText.Trim().Replace(" ", "");
wd9.Date = list[i].Date;
weatherDataList.Add(wd9);
break;
default:
break;
}
}
}
else
{
}
}
// 输出进度提示
Debug.WriteLine($"已处理完成第{i}个URL");
}
// 将数据存入SQLite数据库
db.Insertable(weatherDataList.OrderBy(x => x.Date).ToList()).ExecuteCommand();
MessageBox.Show($"获取天气数据成功,共有{weatherDataList.Count}条");
}这里使用swith case是因为网页的格式并不是一层不变的,有时候少了一列,没有霾的数据。
wd9.StationName = tds[0].InnerText.Trim().Replace(" ", "");这里对文本进行这样处理是因为原始的数据是“\n内容 \n”,C#中String.Trim()方法会删除字符串前后的空白,string.Replace("a","b")方法会将字符串中的a换成b。
效果如下所示:
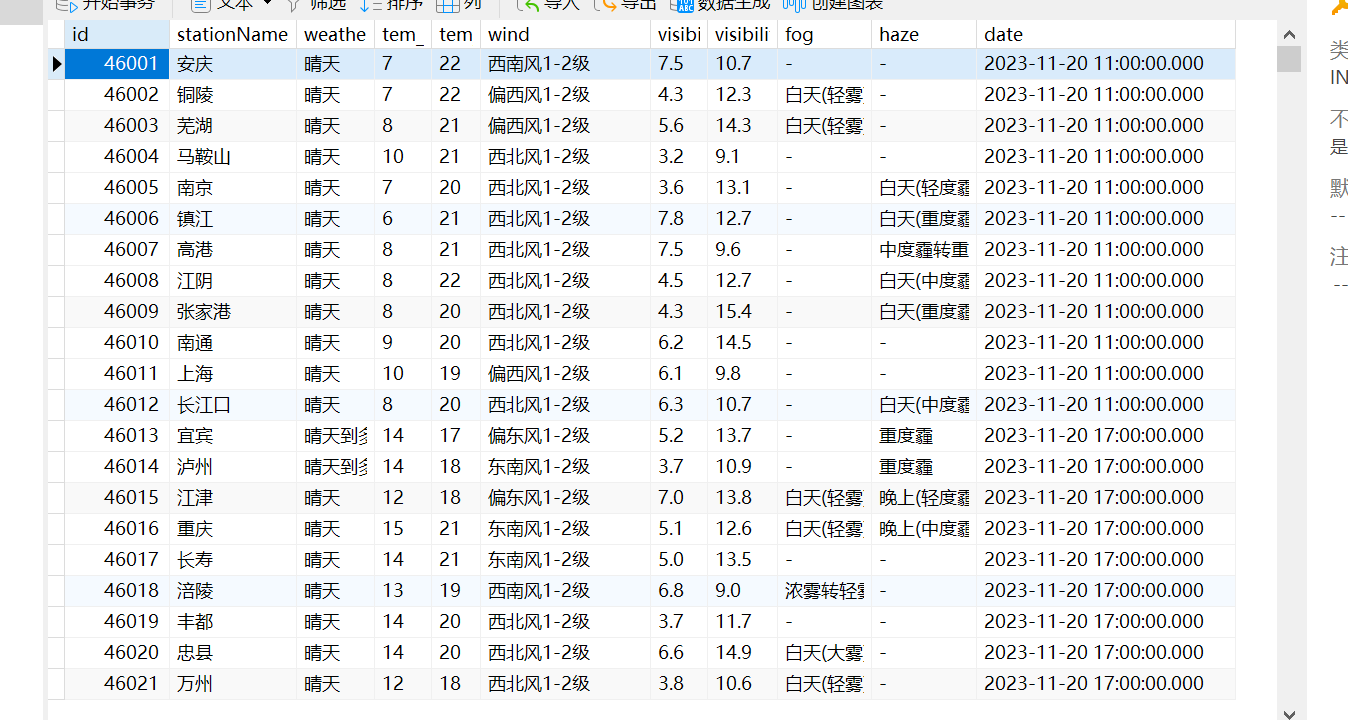
将数据全部都存入数据库中了。
4、最后
通过这个实例说明了其实C#也是可以实现网页爬虫的,对于没有反爬的情况下是完全适用的,再配合linq做数据处理也是可以的。
文章转载自:mingupupup
原文链接:https://www.cnblogs.com/mingupupu/p/17860491.html