Elk(Elasticsearch, Logstash, Kibana)是一套日志收集、存储和展示方案,是由Elastic公司开发的开源软件组合。
-
Elasticsearch:是一个分布式的搜索和分析引擎。它能够处理大量的数据,并提供快速、准确的搜索结果,支持复杂的数据分析和可视化。
-
Logstash:是一个日志收集和处理工具。它可以从各种数据源收集数据,并对数据进行过滤、解析和转换,使其能够被Elasticsearch等系统所理解。
-
Kibana:是一个数据可视化工具,提供了强大的图形化界面,能够帮助用户更好地理解和分析数据。它支持各种图表和图形,可以直观地展示数据趋势、关系和特征。
使用Elk可以方便地收集和分析各种类型的数据,如服务器日志、应用程序日志、网络流量、传感器数据等等。它的使用非常广泛,包括企业级应用、安全监控、搜索引擎、日志分析等领域。
部署ELk
| 安装软件配置 | 主机名 | IP地址 | 系统版本 |
| Elasticsearch/Logstash/kibana | ELK | 10.36.192.157 | CentOs7.9.2009 2核4G |
| Elasticsearch | Es1 | 10.36.192.158 | CentOs7.9.2009 2核3G |
| Elasticsearch | Es2 | 10.36.192.159 | CentOs7.9.2009 2核2G |
| zookeeper/kafka | Kafka1 | 10.36.192.160 | CentOs7.9.2009 1核2G |
| zookeeper/kafka | Kafka2 | 10.36.192.161 | CentOs7.9.2009 1核2G |
| zookeeper/kafka | Kafka3 | 10.36.192.166 | CentOs7.9.2009 1核2G |
环境部署
1.获取系统版本信息
[root@initial ~]# cat /etc/centos-release
CentOS Linux release 7.9.2009 (Core)2.添加主机名解析
#每个节点都添加下解析
[root@elk bin]# vim /etc/hosts
10.36.192.157 elk
10.36.192.158 es1
10.36.192.159 es2
10.36.192.160 kafka1
10.36.192.161 kafka2
10.36.192.166 kafka33.软件包的版本号
#相应的版本最好下载对应的插件
Elasticsearch: 7.13.2
Logstash: 7.13.2
Kibana: 7.13.2
Kafka: 2.11-1
Filebeat: 7.13.24.搭建架构

1、日志数据由filebeat进行收集,定义日志位置,定义kafka集群,定义要传给kafka的那个topic
2、kafka接受到数据后,端口为9092,等待消费
3、logstash消费kafka中的数据,对数据进行搜集、分析,根据输入条件,过滤条件,输出条件处理后,将数据传输给es集群
4、es集群接受数据后,搜集、分析、存储
5、kibana提供可视化服务,将es中的数据展示。
5.相关地址
相关地址:
官网地址:https://www.elastic.co
官网搭建:Starting with the Elasticsearch Platform and its Solutions | Elastic
elasticsearch集群部署
-
软件包:elasticsearch-7.13.2-linux-x86_64.tar.gz
-
示例节点IP:10.36.192.157 10.36.192.158 10.36.192.159
安装es
1.创建普通用户es
[root@elk ~]# useradd es2.安装es
[root@elk ~]# tar xf elasticsearch-7.13.2-linux-x86_64.tar.gz -C /usr/local/
[root@elk ~]# cd /usr/local/
[root@elk local]# mv elasticsearch-7.13.2/ es3.创建es数据目录,日志目录
[root@elk ~]# mkdir -p /data/elasticsearch/data
[root@elk ~]# mkdir -p /data/elasticsearch/logs4.修改文件属性
[root@elk ~]# chown -R es.es /data/elasticsearch
[root@elk ~]# chown -R es.es /usr/local/es5.编辑yml配置文件
#node.name,每个节点要不同
#data路径、logs路径要在提前创建好
#discovery.seed_hosts写其它节点的IP
[root@elk ~]# vim /usr/local/es/config/elasticsearch.yml
cluster.name: bjbpe01-elk
cluster.initial_master_nodes: ["10.36.192.157","10.36.192.158","10.36.192.159"] # 单节点模式这里的地址只填写本机地址
node.name: elk01
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["10.36.192.158", "10.36.192.159"]
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping_timeout: 150s
discovery.zen.fd.ping_retries: 10
client.transport.ping_timeout: 60s
http.cors.enabled: true
http.cors.allow-origin: "*"6.设置jvm堆大小
#默认为4G
[root@elk ~]# sed -i 's/## -Xms4g/-Xms4g/' /usr/local/es/config/jvm.options
[root@elk ~]# sed -i 's/## -Xmx4g/-Xmx4g/' /usr/local/es/config/jvm.options7.系统优化
#增加最大文件打开数
[root@elk ~]# echo "* soft nofile 65536" >> /etc/security/limits.conf#增加最大进程数
[root@elk ~]# echo "* soft nproc 65536" >> /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
#更多的参数调整可以直接用这个#增加最大内存映射数
[root@elk ~]# echo "vm.max_map_count=262144" >> /etc/sysctl.conf
[root@elk ~]# sysctl -p8.启动es
#su 与su -的区别是,su切换用户后,当前的路径不变
#可以使用&将服务放在后台
[root@elk ~]# cd /usr/local/es/bin
[root@elk bin]# su es
[es@elk bin]$ ./elasticsearch &9.验证是否正常启动
默认访问端口9200




安装es监控软件head
-
软件包:node-v10.24.1-linux-x64.tar.gz
-
示例节点:10.36.192.157
1.安装配置head监控插件
解压插件
[root@elk ~]# tar xf node-v10.24.1-linux-x64.tar.gz -C /usr/local/
[root@elk ~]# cd /usr/local/
[root@elk local]# mv node-v10.24.1-linux-x64/ node添加node环境变量
[root@elk local]# vim /etc/profile.d/node.sh
NODE_HOME=/usr/local/node
PATH=$PATH:$NODE_HOME/bin
[root@elk local]# source /etc/profile.d/node.sh
[root@elk local]# node -v
v10.24.1安装head插件
[root@elk ~]# yum provides unzip
[root@elk ~]# yum -y install unzip
[root@elk ~]# unzip elasticsearch-head-master.zip -d /usr/local/ &> /dev/null安装grunt组件

[root@elk ~]# cd /usr/local/elasticsearch-head-master
[root@elk ~]# npm install -g grunt-cli
[root@elk ~]# grunt -version
grunt-cli v1.4.3修改head源码文件

[root@elk elasticsearch-head-master]# cp /usr/local/elasticsearch-head-master/Gruntfile.js /usr/local/elasticsearch-head-master/Gruntfile.js.bak
[root@elk elasticsearch-head-master]# vi /usr/local/elasticsearch-head-master/Gruntfile.js
[root@elk elasticsearch-head-master]# cp /usr/local/elasticsearch-head-master/_site/app.js /usr/local/elasticsearch-head-master/_site/app.js.bak
[root@elk elasticsearch-head-master]# vim /usr/local/elasticsearch-head-master/_site/app.js +4373
#如果head与ES不在同一个节点,那么就需要在head的这个配置文件里指名ES的IP2.下载head其他必要组件
[root@elk ~]# mkdir /tmp/phantomjs
[root@elk ~]# tar -xjf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /tmp/phantomjs/
[root@elk ~]# chmod 777 -R /tmp/phantomjs 3.运行head
[root@elk ~]# cd /usr/local/elasticsearch-head-master/
[root@elk elasticsearch-head-master]# npm install phantomjs-prebuilt@2.1.16 --ignore-scripts
[root@elk elasticsearch-head-master]# nohup grunt server &
[root@elk elasticsearch-head-master]# ss -nplt如果显示找不到grunt

#安装grunt组件时有时候会出现错误,再次安装下载后虽然可以使用grunt -version看到版本号,但是一般这个grunt是组件不全的
#上图这个错误提示表明在运行grunt缺少一些必要的grunt插件。
#解决办法:它显示有几个没发现,就下载对应几个插件
npm install grunt-contrib-clean --save-dev
npm install grunt-contrib-concat --save-dev
npm install grunt-contrib-watch --save-dev
npm install grunt-contrib-copy --save-dev
npm install grunt-contrib-connect --save-dev
npm install grunt-contrib-jasmine --save-devhead正常运行后,默认使用9100端口

4.页面测试
http://10.36.192.157:9100

安装部署kibana
-
软件包:kibana-7.13.2-linux-x86_64.tar.gz
-
示例节点:10.36.192.157
1.解压kibana
[root@elk ~]# tar -xzf kibana-7.13.2-linux-x86_64.tar.gz -C /usr/local/2.配置kibana
[root@elk ~]# echo '
server.port: 5601
server.host: "10.36.192.157"
elasticsearch.hosts: ["http://10.36.192.157:9200"]
kibana.index: ".kibana"
i18n.locale: "zh-CN"
'>>/usr/local/kibana-7.13.2-linux-x86_64/config/kibana.yml3.访问kibana页面
[root@elk kibana-7.13.2-linux-x86_64]# nohup ./bin/kibana --allow-root &如果访问kibana界面,显示服务还没准备好,请将所有es集群的节点的es服务都启动启动
http://10.36.192.157:5601/

使用nginx实现head和kibana的反向代理
1.下载nginx仓库
[root@elk ~]# rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm2.配置nginx的反向代理
[root@elk ~]# yum -y install nginx
[root@elk ~]# vim /etc/nginx/nginx.conf
user nginx;
worker_processes 4;
error_log /var/log/nginx/error.log;
pid /var/run/nginx.pid;
worker_rlimit_nofile 65535;
events {
worker_connections 65535;
use epoll;
}
http {
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
server_names_hash_bucket_size 128;
autoindex on;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 120;
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
#gzip模块设置
gzip on; #开启gzip压缩输出
gzip_min_length 1k; #最小压缩文件大小
gzip_buffers 4 16k; #压缩缓冲区
gzip_http_version 1.0; #压缩版本(默认1.1,前端如果是squid2.5请使用1.0)
gzip_comp_level 2; #压缩等级
gzip_types text/plain application/x-javascript text/css application/xml; #压缩类型,默认就已经包含textml,所以下面就不用再写了,写上去也不会有问题,但是会有一个warn。
gzip_vary on;
#开启限制IP连接数的时候需要使用
#limit_zone crawler $binary_remote_addr 10m;
#tips:
#upstream bakend{#定义负载均衡设备的Ip及设备状态}{
# ip_hash;
# server 127.0.0.1:9090 down;
# server 127.0.0.1:8080 weight=2;
# server 127.0.0.1:6060;
# server 127.0.0.1:7070 backup;
#}
#在需要使用负载均衡的server中增加 proxy_pass http://bakend/;
server {
listen 80;
server_name localhost;
#charset koi8-r;
# access_log /var/log/nginx/host.access.log main;
access_log off;
location / {
#与你创建的用户对应起来
auth_basic "kibana"; #可以是string或off,任意string表示开启认证,off表示关闭认证。
auth_basic_user_file /etc/nginx/passwd.db; #指定存储用户名和密码的认证文件。
proxy_pass http://10.36.192.157:5601;
proxy_set_header Host $host:5601;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Via "nginx";
}
location /status {
stub_status on; #开启网站监控状态
access_log /var/log/nginx/kibana_status.log; #监控日志
auth_basic "NginxStatus"; }
location /head/{
#与你创建的用户对应起来
auth_basic "head";
auth_basic_user_file /etc/nginx/passwd.db;
proxy_pass http://10.36.192.157:9100/;
proxy_set_header Host $host:9100;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Via "nginx";
}
# redirect server error pages to the static page /50x.html
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
配置用户及密码
[root@elk es]# cd /etc/nginx/
[root@elk nginx]# echo > passwd.db
[root@elk nginx]# yum provides htpasswd
[root@elk nginx]# yum -y install hthttpd-tools
[root@elk nginx]# htpasswd -cm /etc/nginx/passwd.db kibana
New password:
Re-type new password:
Adding password for user kibana
[root@elk nginx]# htpasswd -m /etc/nginx/passwd.db head
New password:
Re-type new password:
Adding password for user head
[root@elk nginx]# systemctl restart nginx安装部署logstash
-
软件包:logstash-7.13.2-linux-x86_64.tar.gz
-
示例节点:10.36.192.15
1.解压包
[root@elk ~]# tar xf logstash-7.13.2-linux-x86_64.tar.gz -C /usr/local/2.测试logstash
[root@elk local]# cd logstash-7.13.2/
[root@elk logstash-7.13.2]# mkdir conf
[root@elk logstash-7.13.2]# cd conf
#logstash文件目录里的conf目录默认是空,可以在这里写测试的输入配置、输出配置文件
[root@elk conf]# vim stdin.conf
input {
stdin {}
}
[root@elk conf]# vim stdout.conf
output {
stdout {
codec => rubydebug
}
}
#测试与ES集群是否连接通畅
[root@elk conf]# vim stdout.conf
output {
stdout {
codec => rubydebug
}
#添加与ES集群的连接
elasticsearch {
hosts => ["10.3.145.14","10.3.145.56","10.3.145.57"]
index => 'logstash-debug-%{+YYYY-MM-dd}'
}
}3.启动logstash
# -f 指定自定义的输出配置文件、输入配置文件、过滤配置文件
[root@elk conf]# ./bin/logstash -f conf/ 4.测试页面访问
访问 http://10.36.192.157/head

5.配置logstash
[root@elk conf]# mkdir -p /usr/local/logstash-7.13.2/etc/conf.d
#配置logstash的输入
[root@elk conf]# vim /usr/local/logstash-7.13.2/etc/conf.d/input.conf
input {
kafka {
type => "audit_log"
codec => "json"
topics => "nginx"
decorate_events => true
bootstrap_servers => "10.36.192.157:9092, 10.36.192.158:9092, 10.36.192.159:9092"
}
}
#配置logstash的输出
[root@elk conf]# vim /usr/local/logstash-7.13.2/etc/conf.d/output.conf
output {
if [type] == "audit_log" {
elasticsearch {
hosts => ["10.36.192.157","10.36.192.158","10.36.192.159"]
index => 'logstash-audit_log-%{+YYYY-MM-dd}'
}
}
}
#配置logstash的过滤
[root@elk conf]# vim /usr/local/logstash-7.13.2/etc/conf.d/output.conf
filter {
json { # 如果日志原格式是json的,需要用json插件处理
source => "message"
target => "nginx" # 组名
}
}6.启动logstash
[root@elk logstash-7.13.2]# nohup bin/logstash -f etc/conf.d/ --config.reload.automatic & [2] 2398kafka集群部署
-
软件包:jdk-8u121-linux-x64.tar.gz、kafka_2.11-2.0.0.tgz
-
示例节点:10.36.192.160
a. 安装jdk8
1.kafka,zookeeper简称(ZK)运行依赖jdk8
[root@elk ~]# tar -xzf jdk-8u211-linux-x64.tar.gz -C /usr/local/
[root@elk ~]# cd /usr/local/
[root@elk local]# mv jdk1.8.0_211/ java
#配置环境变量,JAVA_HOME的路径要与你实际的对应
[root@elk local]# vim /etc/profile.d/java.sh
JAVA_HOME=/usr/local/java
PATH=$PATH:$JAVA_HOME/bin
[root@elk local]# source /etc/profile.d/java.sh
[root@elk local]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)b. 安装配置ZK
[root@elk ~]# echo '
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=10.36.192.160:2888:3888 //kafka集群IP:Port .1为id 3处要对应
server.2=10.36.192.161:2888:3888
server.3=10.36.192.166:2888:3888
'> /usr/local/kafka_2.11-2.0.0/config/zookeeper.properties3.创建ZK的数据,日志目录
[root@kafka2 local]# mkdir -p /opt/data/zookeeper/{data,logs}
#所有的kafka节点需要有不同的myid,在其它节点记得myid不能再是1了
[root@kafka2 local]# echo 1 > /opt/data/zookeeper/data/myidc. 配置kafka
[root@elk ~]# mkdir -p/opt/data/kafka/logs
[root@elk ~]# echo '
broker.id=1
listeners=PLAINTEXT://10.36.192.160:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=10.36.192.160:2181,10.36.192.161:2181,10.36.192.166:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
' > /usr/local/kafka_2.11-2.0.0/config/server.propertiesd. 其他kafka看节点配置
#只需把配置好的安装包直接分发到其他节点,然后修改ZK的myid,Kafka的broker.id和listeners就可以了。
e.启动运行
#集群所有节点都执行一下
#先启动zookeeper
[root@kafka1 ~]# cd /usr/local/kafka_2.11-2.0.0/
[root@kafka1 ~]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
#再启动kafka
[root@kafka1 ~]# cd /usr/local/kafka_2.11-2.0.0/
[root@kafka1 ~]# nohup bin/kafka-server-start.sh config/server.properties &f. kafka集群验证
#在集群任一节点上创建topic,如在10.36.192.160上创建topic
[root@kafka1 ~]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic
#在集群的任一节点都可以看到,如在10.36.192.161上查看topic
[root@kafka2 kafka_2.11-2.0.0]# bin/kafka-topics.sh --zookeeper 10.36.192.161:2181 --list
[root@kafka2 kafka 2.11-2.0.0]# bin/kafka-topics.sh --zookeeper 10,36.192.160:2181 --list
[root@kafka2 kafka 2.11-2.0.0]# bin/kafka-topics.sh --zookeeper 10,36.192.166:2181 --list
#模拟消息的产生和消费
#在节点10.36.192.160上发送信息
[root@kafka1 ~]# bin/kafka-console-producer.sh --broker-list 10.3.145.41:9092 --topic testtopic
>hello world!
#在另一节点10.36.192.161接收消息
[root@kafka2 ~]# bin/kafka-console-consumer.sh --bootstrap-server 10.36.192.161:9092 --topic testtopic --from-beginning
Hello World!#删除kafka集群的topic
[root@kafka1 ~]# bin/kafka-topics.sh --delete --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic安装部署filebeat
-
filebeat需要部署在每台需要监控日志的应用服务器上面,可以使用容器、ansilbe、Salt来批量部署
-
软件包:filebeat-7.13.2-x86_64.tar.gz
-
示例节点:10.36.192.161
[root@kafka2 ~]# tar -xzf filebeat-7.13.2-x86_64.tar.gz -C /usr/local
[root@kafka2 ~]# cd /usr/local
[root@kafka2 ~]# mv filebeat-7.13.2-x86_64 filebeat
[root@kafka2 ~]# cd filebeat
#修改filebeat配置,输出到logstash,多余的通过kafka集群进行缓存,缓解logstash写的压力(ELK)
[root@kafka2 ~]# yum -y install nginx
[root@kafka2 ~]# systemctl start nginx
#启动zookeeper,启动kafka集群,示例获取nginx的日志信息,创建名为nginx的topic
[root@kafka1 ~]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic nginx
[root@kafka2 ~]# vim filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
#filebeat6.x的版本,只能有一个output了,ELK架构就选择输出到kafka集群的topic那里
#下面是直接输出到logstash的,与输出到kafka集群的
output.logstash:
hosts: ["10.36.192.161:5000"]
output.kafka:
hosts: ["10.36.192.160:9092","10.36.192.161:9092","10.36.192.166:9092"]
topic: 'nginx' #与创建的topic名一致案例
-
案例:使用filebeat将mysql日志直接发送给ES集群
-
ELK基本已经部署完毕,filebeat可以搜集应用服务器的日志,并按需求发送给指定的集群或节点。
-
发送到Kafka集群
-
或者越过kafka集群发给logstash
-
又或者直接越过所有中间件直接发送给ES集群的任一节点
-
也可以发送给logstash和kafka集群(ELK)
-
-
#举例,使用任意一台虚拟机作为一个数据库节点,使用filebeat收集它的日志信息
#由于电脑配置限制,我就选其中一个kafka节点作为web应用服务器来实验
[root@kafka2 ~]# yum -y install mysql-server mysql
[root@kafka2 ~]# systemctl start mysqld#访问kibana网页界面,在里面选择添加数据,选择添加mysql日志
#然后根据页面步骤执行代码
#配置filebeat
#进入模块目录,可以查看当前版本的filebeat支持那么服务的日志收集服务,找到对应的模块名
[root@kafka2 filebeat]# cd modules.d/
#开启某一个模块,如开启mysql模块日志收集
[root@kafka2 filebeat]# ./filebeat modules enable mysql
[root@kafka2 ~]# vim filebeat.yml修改filebeat的输出位置,指定一台ES服务器

指定接受filebeat日志信息的kibana节点

启动filebeat,并在kibana建立索引模式
[root@kafka2 filebeat]# ./filebeat -e -c filebeat.yml在kibana操作

#在最侧边栏,点击三个横线的那里,下拉选到Stack Management

#我示例里面选的是@timestamp,是官方默认的时间字段,其它字段可以查看官方文档酌情选择

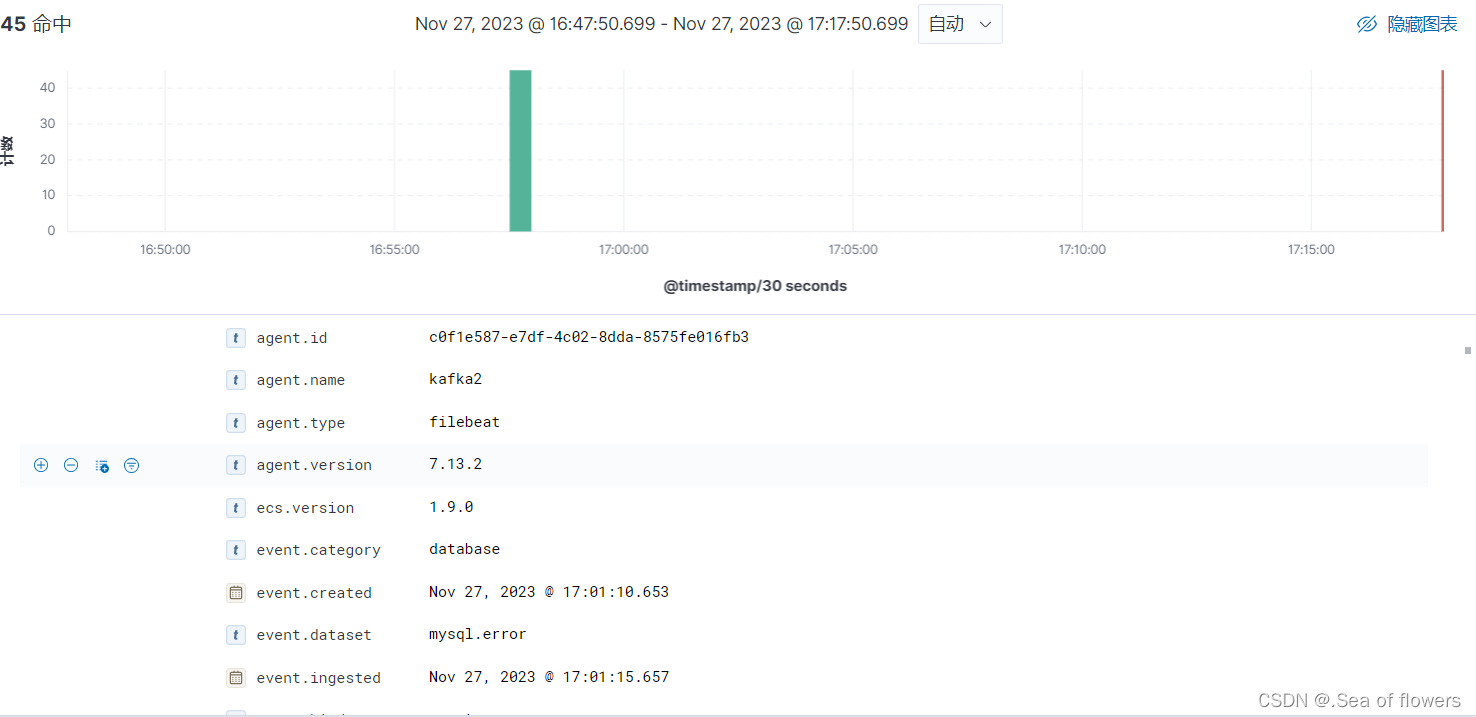
最后效果
summary
1.ELK是怎么实现高效快速处理日志信息的呢?
透过在所有的web应用服务器上面部署filebeat,
然后filebeat收集服务的日志信息,再发送给kafka集群的topic,
kafka集群极大的缓解了logstash的写的压力,
logstash再对收集到日志信息进行过滤、分析、处理,再发送给ES集群,
ES集群接收到所有处理好的日志信息,实时分析,并为它们建立索引,最后实现了日志信息的秒级查询速度
kibana将ES集群的日志信息进行可视化化展示2.ELK组件的简单介绍
kibana就是可视化的将ES集群里的日志信息展示到页面上的工具;
head是较为实用的监控ES集群的插件
kafka和rabbitMQ很像,都是为了缓解写压力被研发出来的
filebeat是一款轻量高效的日志信息处理服务
logstash与filebeat不同的是,功能更加多样,可以对日志信息进行切割处理
ES服务器为所有的日志信息添加索引,负载存储日志信息