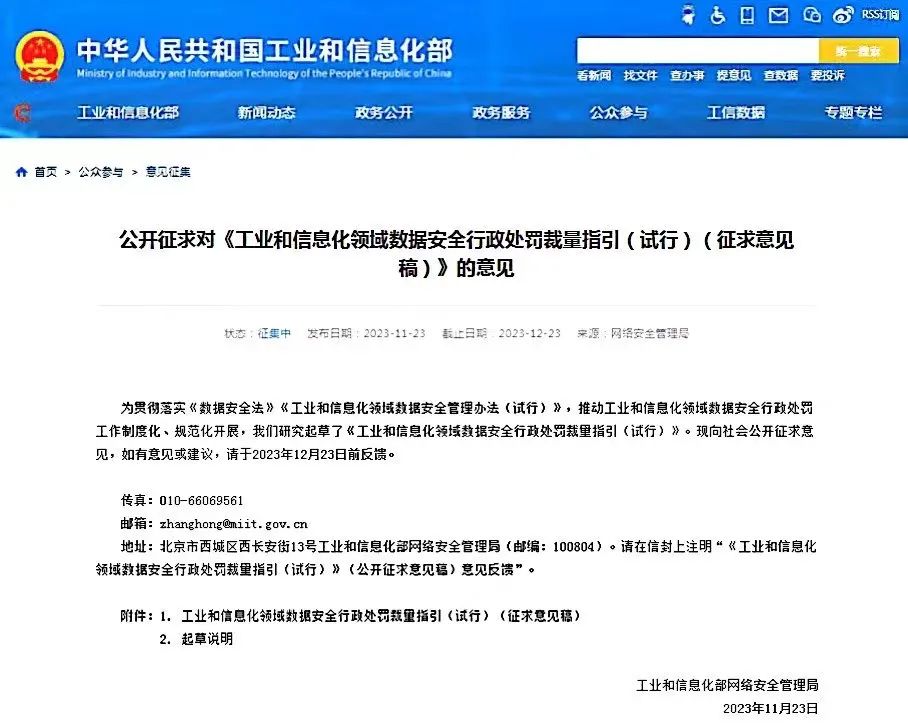
jieba分词主要有3种模式:
1、精确模式:jieba.cut(文本, cut_all=False)
2、全模式:jieba.cut(文本, cut_all=True)
3、搜索引擎模式:jieba.cut_for_search(文本)
分词后的关键词提取:
jieba.analyse.textrank(txt,topK=20, withWeight=False)topK:要提取的关键词个数,默认为20
withWeight:是否返回关键词权重,默认为False
allowPOS:是否指定关键词词性(名词、形容词、动词),默认为空,也就是不筛选
import jieba.analyse
import jieba
import chardet
import wordcloud
# 文件路径
path = 'C:\\Users\\86185\\PycharmProjects\\pythonProject\\practice\\txt'
file='lsm.txt'
#指定文件
txt_url=path+'\\'+file
#打开文件,这一次打开主要是为了获取编码格式
with open(txt_url, 'rb') as f:
cont = f.read()
encoding = chardet.detect(cont)['encoding']
if encoding == 'GB2312':
encoding = 'gbk'
elif encoding == None:
encoding = 'utf-8'
f.close()
#打开文件内容
with open(txt_url, encoding=encoding) as f:
txt = f.read()
txt_word=jieba.cut_for_search(txt)
#print(list(txt_word))
txt_main=jieba.analyse.textrank(txt,topK=20, withWeight=False)
print(txt_main)
如果展示权重: