高动态视频生成的新进展
- Make Pixels Dance: High-Dynamic Video Generation
- 高动态视频生成的新进展
- 前言
- 视频生成模式
- 摘要
- 论文十问
- 实验
- 数据集
- 定量评估指标
- 消融研究
- 训练和推理技巧
- 训练技术
- 推理技术
- 更多的应用
Make Pixels Dance: High-Dynamic Video Generation
高动态视频生成的新进展

前言
动态视频生成一直是人工智能领域的一个重要且富有挑战性的目标。尤其是生成复杂场景和丰富动作的高质量视频,更是难上加难。很多现有的视频生成模型,主要集中在从文本描述生成视频,往往只能输出运动幅度非常小的视频,这也是行业的一个难点。
最近,字节跳动的研究人员提出了一个非常有创意的方法——PixelDance,利用图像的先验知识指导视频生成过程,从而大幅提升了视频的动态性。具体来说,该方法除了使用文本描述,还同时使用视频的第一帧图像和最后一帧图像作为条件,来生成中间的动态视频内容。
第一帧图像主要提供复杂场景和对象细节信息
最后一帧图像则指导视频朝着期望的方向生成。
为了提高模型的泛化性,研究人员使用了一些巧妙的数据增强技术,避免模型严格复制最后一帧的图像作为视频结尾。
在MSR-VTT和UCF-101公开数据集上,PixelDance都取得了非常显著的性能提升。
尤其令人印象深刻的是,这种利用图像先验知识的方法,甚至可以让模型生成一些完全不存在于训练数据中的域,如动漫、科幻等风格的视频。我相信这种通过引导模型关注生成内容动力学的做法,为动态视频生成开辟了新的思路,也会对创意视频内容的合成产生深远的影响。下一步,进一步扩大模型规模,使用更高质量的开放域视频数据进行训练,都将是有益探索的方向。
总的来说,这篇研究为复杂高动态视频生成树立了新的基准,值得关注。我期待未来的研究能更进一步,让机器像电影导演一样,创作出有连贯剧情的长视频,甚至智能电影!
论文地址:https://arxiv.org/abs/2311.10982
官网地址:https://makepixelsdance.github.io
视频生成模式
第一种模式为基础模式,用户只需提供一张指导图片和相应文本描述,即可生成高度一致且富有动态性的视频。
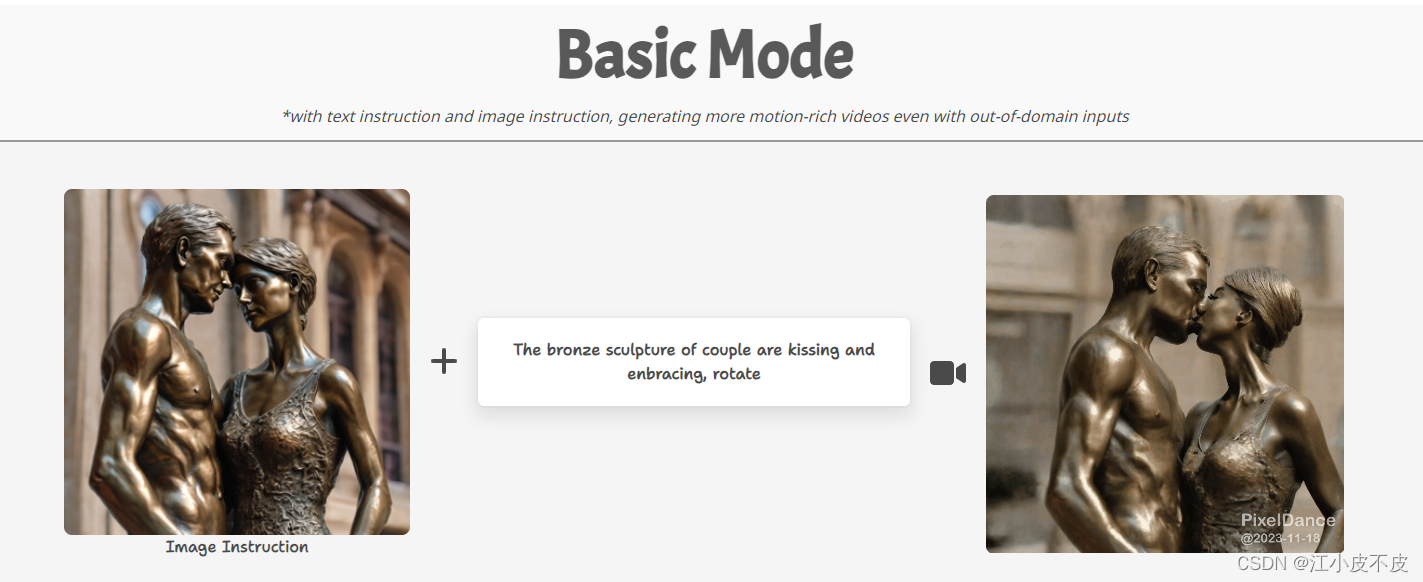

第二种模式是高级魔法模式,为用户提供更大的想象和创造空间。在这一模式下,用户需要提交两张指导图片和相关文本描述,以生成更具挑战性的视频内容。


摘要
如何制作动作丰富、视觉效果复杂的高动态视频,是人工智能领域面临的重大挑战。
不幸的是,目前最先进的视频生成方法,主要专注于文本到视频的生成,倾向于以最小的动作制作视频剪辑,尽管保持高保真度。
我们认为仅仅依靠文本指令是不够的,对于视频生成来说是次优的。在本文中,我们介绍了PixelDance,这是一种基于扩散模型的新方法,它将第一帧和最后一帧的图像指令与视频生成的文本指令结合在一起。
综合实验结果表明,使用公开数据训练的pixeldance在合成复杂场景和复杂动作的视频方面表现出明显更好的熟练程度,为视频生成树立了新的标准
论文十问
- 论文试图解决什么问题?
这篇论文解决了高动态视频生成的问题,包括复杂场景和精细运动。现有的文本生成视频产生的视频短且动作小。
- 这是否是一个新的问题?
不是一个新的问题,是视频生成领域的一个关键难题。文章提出来一种图文视频生成框架解决了这个问题。
- 这篇文章要验证一个什么科学假设?
以往的研究都是采用文本生成视频,作者认为,仅依靠文本指令对于视频生成是不够的,应该加入第一帧和最后一帧指令。这样可以显著提高视频的生成质量和动态性。
- 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
相关研究包括基于GAN、具有VQVAE的Transfomers的文本到视频生成过程。关键研究员有Songwei Ge、Jonathan Ho等。
- 论文中提到的解决方案之关键是什么?
采用第一帧,文本提示,最后一帧来指导视频生成过程。并且设置了精妙的训练推理技巧。
- 论文中的实验是如何设计的?
在MSR-VTT、UCF-101数据集上进行定量评估。针对不同指导条件做消融实验。生成长视频进行质量分析。
- 用于定量评估的数据集是什么?代码有没有开源?
使用的公开数据集有MSR-VTT、UCF-101、LAION-400M等。代码暂未开源。
MSR-VTT 是一个视频检索数据集,每个视频都有描述。
UCF-101 是一个动作识别数据集,具有 101 个动作类别。
- 论文中的实验及结果有没有很好地支持需要验证的科学假设?
定量结果和质量分析充分验证了科学假设。
- 这篇论文到底有什么贡献?
主要贡献是提出图文视频生成框架PixelDance,在公开数据上取得新成绩。
1.生成更长的视频。
2.动作更加丰富。
3.自然转换镜头。
- 下一步呢?有什么工作可以继续深入?
下一步的工作可以使用更高质量的视频数据进行训练,在特定域进行微调,扩大模型规模等。
实验
数据集
MSR-VTT: 是一个视频检索数据集,每个视频都有描述。
UCF-101 :是一个动作识别数据集,具有 101 个动作类别。
定量评估指标
1.FID 和 FVD 都是测量生成的视频和真实数据之间的分布距离。
2.IS评估生成的视频的质量。
3.CLIPSIM估计生成的视频和相应文本之间的相似性。
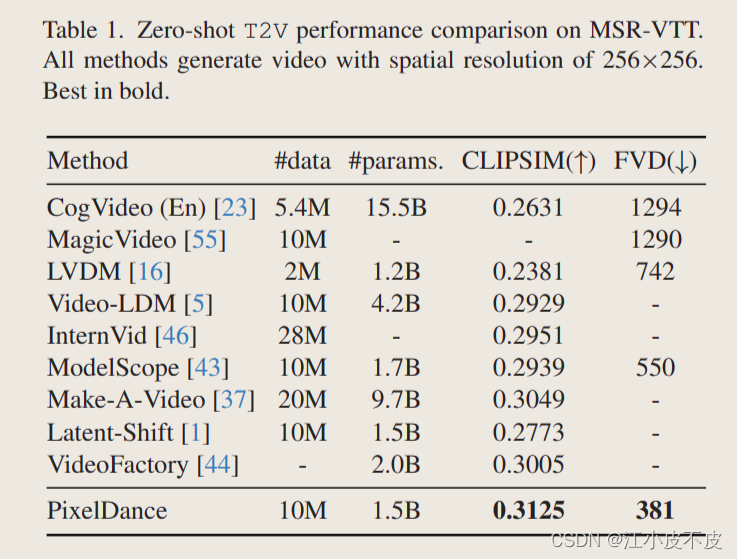
基于MSR-VTT数据集,指标为CLIPSIM和FVD。
可以看到PixelDance生成的视频和真实数据的分布最为接近,和文本描述最为相似。
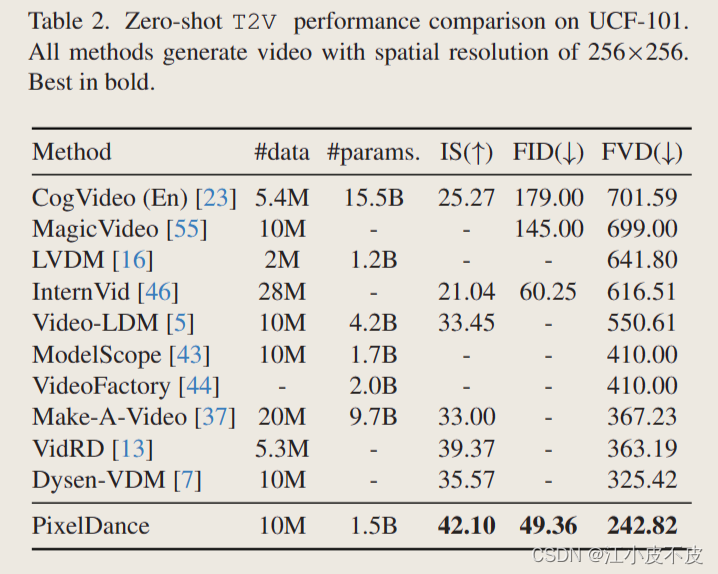
基于UCF-101数据集,指标为IS、FID和FVD。
可以看到PixelDance生成的视频和真实数据的分布最为接近,生成的视频质量最高。
消融研究
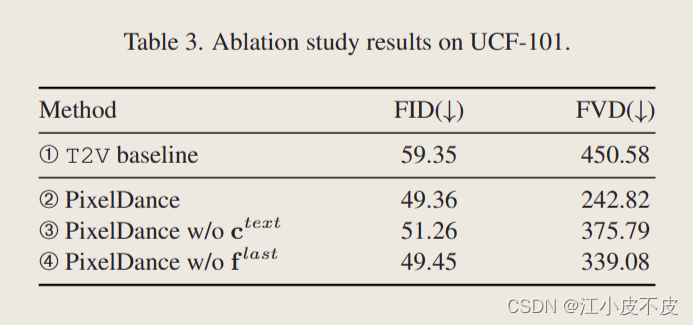
这篇论文进行了消融实验来评估PixelDance模型中的关键组成部分,包括文本指令、第一帧图像指令和最后一帧图像指令的作用。
- 和只使用文本指令的基准T2V模型相比,PixelDance取得了明显更好的生成视频质量,证明了图像指令的有效性。
- 当移除文本指令时,生成视频的FID和FVD指标有一定程度的下降。这说明文本指令可以帮助增强视频中关键元素的跨帧一致性,如人物服饰等。
- 当不使用最后一帧图像指令训练时,模型生成视频的质量也有所下降。这证明了最后一帧图像在指导视频生成朝着期望结束状态的效用。
- 即使在评估中不提供最后一帧图像,加入该指令进行训练的模型仍优于没有的模型。这说明最后一帧图像指令可以增强模型对运动动力学的建模能力和时序一致性。
- 整体而言,各种指令的组合可以让模型在复杂视频生成上取得巨大提升。每种指令都在帮助模型从不同方面学习如何生成连贯、逼真的视频。
所以这篇论文的消融实验全面验证了不同指令提供的价值,也解释了PixelDance为什么能生成质量更高、动作更丰富的视频。
训练和推理技巧
这篇论文为了更好地利用图像指令指导视频生成,设计了一些独特的训练和推理技术:
训练技术
(1)第一帧图像指令使用真实视频的第一帧,强制模型严格遵循该指令。
(2)最后一帧指令随机选择真实视频最后三帧中的一帧,增加样本多样性。
(3)在最后一帧指令上加入噪声,增强模型的鲁棒性。
(4)以一定概率随机丢弃最后一帧指令,避免模型过度依赖该指令。
推理技术
(1)前τ步使用最后一帧指令,指导视频生成推向期望结局。
(2)后T-τ步丢弃该指令,生成更流畅、连贯的内容。
(3)τ的大小控制最后一帧指令的影响程度。
这些技巧让模型在训练阶段学习视频内容的内在动力学,也让推理过程中生成的视频既遵循指令,又不死板苍白。τ的调整也提供了灵活的生成控制。
文本+第一帧

文本+第一帧+最后一帧

文本的重要性

τ的作用
如果没有这个参数,生成的视频会在给定的最后一帧指令中突然结束。
相比之下,加入这个参数会使生成的视频更加流畅、时间更加一致。

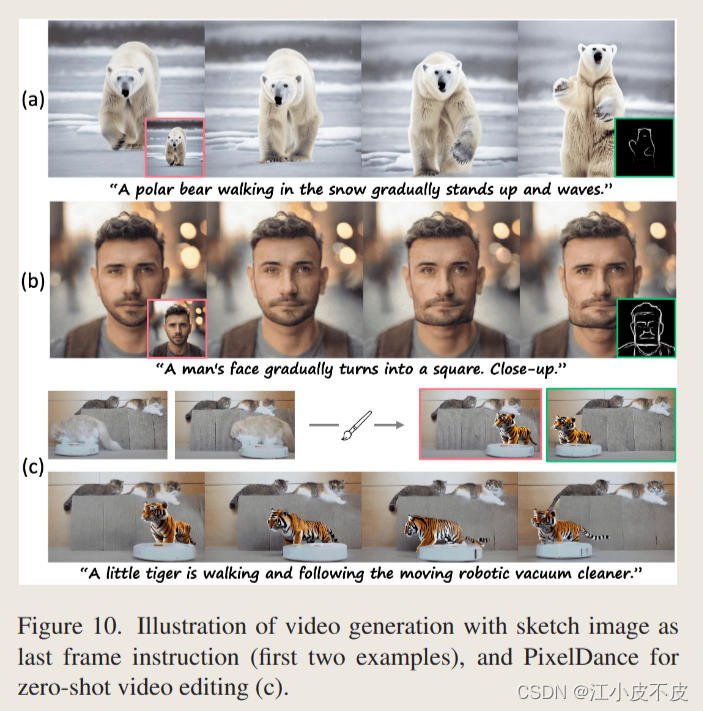
更多的应用
- 草图指令
- 视频编辑
这篇论文的PixelDance模型虽然主要是基于文本指令和图像指令进行视频生成,但文章最后还探索了使用简单的图像草图作为最后一帧指令的情况。
- 通过微调,PixelDance模型可以使用包含简单轮廓的草图图像作为最后一帧指令指导视频生成过程。
- 和真实图像类似,草图最后一帧提供的场景和主体信息,可以有效地指导模型合成逼真的视频内容。
- 尽管训练数据中不包含任何草图视频,但PixelDance展示了通过学习动力学和时序一致性的方法,可以在推理阶段实现零样本泛化到新的图像域(比如草图)。
- 这说明了图像指令通过提供先验场景和内容约束,可以引导模型学习到 Encoding-Generating 视频的本质动力学知识,这些知识适用于各类图像域,不仅限于训练数据中见过的。
- 总的来说,引入图像/草图指令为用户提供了强大的控制界面,通过简单的图像编辑就可以指导视频生成过程,实现比如零样本视频编辑等创意功能。
这是一个有趣的发现,未来视频生成或编辑系统可以更多地考虑与用户的主动交互,因为即使非专业人士提供的简易图像指令也可以产生惊人的效果。这也为创意视频内容的大规模生产提供了新的思路。