©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 月之暗面
研究方向 | NLP、神经网络
Efficient Transformer,泛指一切致力于降低 Transformer 的二次复杂度的工作,开始特指针对 Attention 的改进,后来更一般的思路,如傅立叶变换、线性 RNN 等,也被归入这个范畴。不得不说,为了降低 Transformer 的二次复杂度,各路大牛可谓是“八仙过海,各显神通”,各种神奇的思路“百花齐放”,笔者也从中学习到了不少理论知识。
然而,尽管 Efficient Transformer 在理论上是精彩的,但实际上该领域一直都是不愠不火的状态,并没有实际表现十分出色的模型,在 LLM 火爆的今天,甚至已经逐渐淡出了大家的视野,也淡出了笔者的兴趣范围。
不过,最近有一篇论文《Transformer-VQ: Linear-Time Transformers via Vector Quantization》[1],却让笔者为之拍案叫绝。作者非常高明地洞察到,只需要对标准 Attention 的 Key 做一下 VQ(Vector Quantize),复杂度就会自动降低为线性!这种线性化思路保留了标准 Attention 的形式,是标准 Attention 到线性 Attention 的一个完美过渡,同时最大程度上保留了标准 Attention 的能力。

高效难题
说起来,本站也算是比较早关注 Efficient Transformer 相关工作了,最早可以追溯到 2019 年解读 Sparse Transformer 的一篇文章《为节约而生:从标准Attention到稀疏Attention》。此后,陆续写的关于 Efficient Transformer 的其他文章还有:
线性Attention的探索:Attention必须有个Softmax吗?
Performer:用随机投影将Attention的复杂度线性化
Nyströmformer:基于矩阵分解的线性化Attention方案 [2]
Transformer升级之路:从Performer到线性Attention
线性Transformer应该不是你要等的那个模型
FLASH:可能是近来最有意思的高效Transformer设计
Google新作试图“复活”RNN:RNN能否再次辉煌?
然而,正如本文开头所说,尽管 Efficient Transformer 已有不少工作,也曾被大家寄予厚望,但实际上该领域一直都没什么能“出圈”的作品,这其中的原因可能是:
1. 不少 Efficient Transformer 的提速以牺牲效果为代价;
2. 很多 Efficient Transformer 的复杂度降低仅仅是理论上的,实际使用提升不明显;
3. 有些 Efficient Transformer 难以用来训练 Causal LM,所以在 LLM 流行的今天就没有了用武之地;
4. Flash Attention 的出现表明即便是标准的 Transformer 仍有很大的提速空间。

VQ一下
那么,Transformer-VQ 为何又具备的“出圈”潜力?
简单来说,Transformer-VQ 就是对 Attention 的 Key 向量序列进行了“聚类”,并用所属类的类别中心近似原向量,然后 Attention 的复杂度就变成线性了。也就是说,Transformer-VQ 仅仅改变了 Key 的形似,其余部分(理论上)完全不变,所以这是一种对 Attention 改动非常小的线性化方案,也能非常清楚体现出线性化后损失的精度在哪里(即用类别中心近似原向量的差距)。
铺垫得有点多了,现在我们正式介绍 Transformer-VQ。首先,我们假设 ,标准 Attention 就是
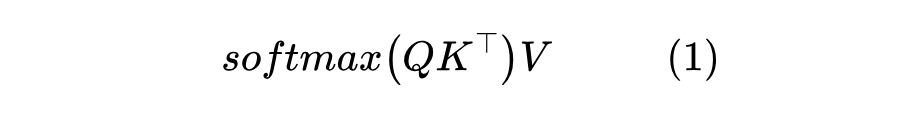
简单起见,这里省略了 scale factor。Transformer-VQ 改为
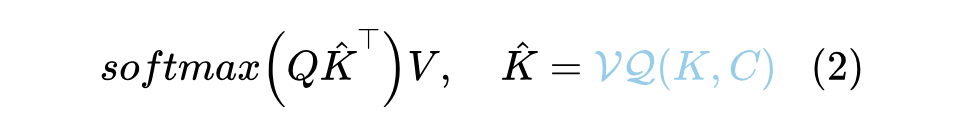
其中 是训练参数,也是 VQ 的编码表(Codebook)。对了,这里的 “VQ” 就是指 VQ-VAE 中的 VQ,不了解的读者可以移步参考《VQ-VAE的简明介绍:量子化自编码器》[3] 和《简单得令人尴尬的 FSQ:“四舍五入”超越了 VQ-VAE》,这里不重复介绍了。总之,经过 之后,最直接的表现就是 的每个向量都变成了 中与之最相近的那个,这意味着 的每个向量都是 的向量之一,用数学的语言就是说 变成了。

Encoder
当然,直接按照式(2)去实现 Transformer-VQ 的话,复杂度还是二次的,但由于 的每个向量都是 的向量之一,所以我们可以先算 ,然后从中“挑出” 对应的结果,而由于 的大小是固定的,所以关键运算 的复杂度是线性的,这就是 Transformer-VQ 能线性化的原理(我们不妨称为“挑出”技巧)。
作为铺垫,我们先考虑双向注意力的 Encoder 情形。由于
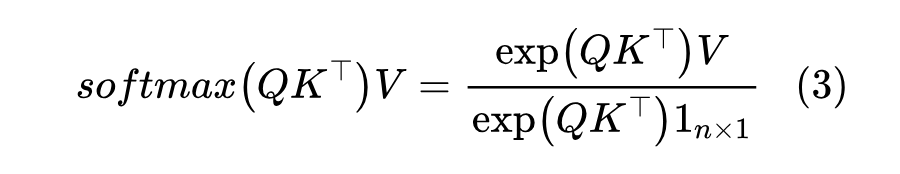
这里 指的是 大小的全1矩阵,分母可以视为分子的一个特殊形式,所以我们只需要考虑分子 。由于 的每个向量都是 中之一,所以我们可以构建一个 one hot 矩阵 ,其中 是一个 one hot 向量,如果 1 所在的维度为 ,那么 ,于是 。
于是对于 Transformer-VQ 来说有:
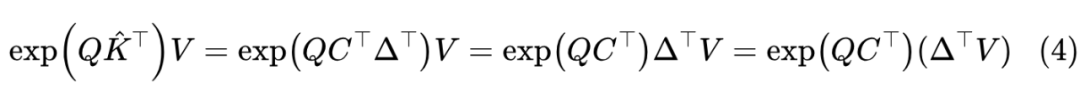
很明显,这里最关键的地方就是第二个等号!对于 one hot 矩阵 ,右乘以它的转置可以从 中分离出来,这就是原理中的“挑出”技巧的数学表述。分离出来之后,由于矩阵乘法结合律, 可以先跟 相乘,得到一个 的矩阵,而 是一个 的矩阵,乘以 就得到一个 的矩阵,总的理论复杂度是 。
最后,根据式(3),将 的结果代入去,就可以计算完整的 Attention 结果(可能还要加一些避免溢出的细节),整个过程可以在线性复杂度内完成。

Decoder
现在我们来考虑单向注意力的 Decoder,这是训练生成模型的关键,也是当前 LLM 的基础。有了 Encoder 的铺垫后,Decoder 理解起来也就没那么困难了。假设 是向量序列 的行向量之一,那么对于 Decoder 的分子有
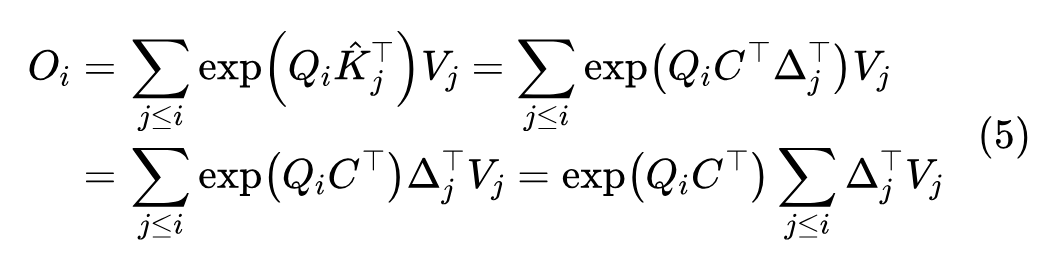
如果 不大,那么最后的式子可以直接用 算子完成,不过一般情况下,尤其是 Multi-Heaad 时,为了节省显存,通常是跟《线性Attention的探索:Attention必须有个Softmax吗?》中的“自回归生成”一节一样,转为 RNN 来递归计算,即设 ,那么
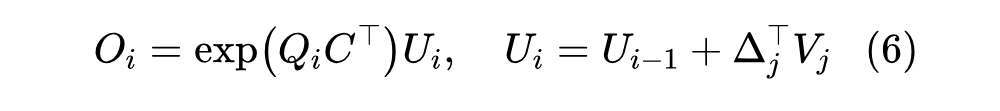
在推理阶段这样 step by step 递归计算自然是没问题,但训练阶段 step by step 的话可能会比较慢,我们可以改为 block by block 来加速:不失一般性,设 , 代表 block_size, 代表 block 数目,block 切片 简写为 ,那么
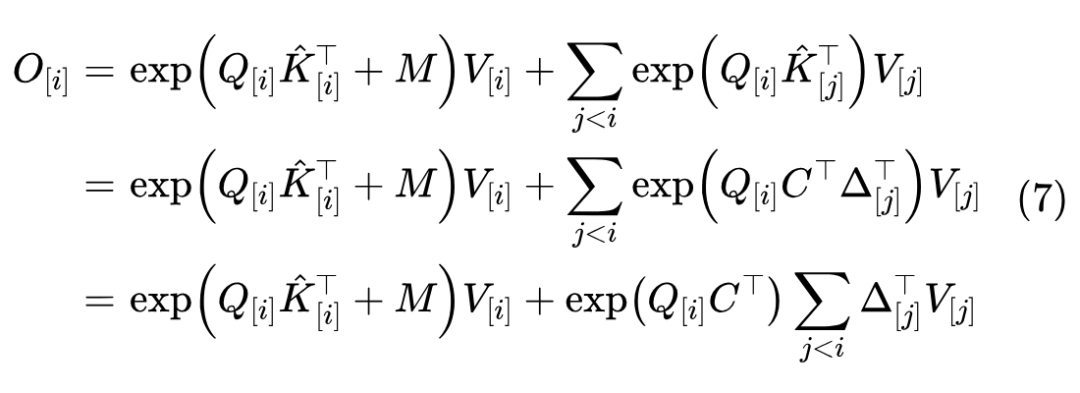
其中 是下三角的 Attention Mask,即当 时 ,否则 。于是记 后,我们有
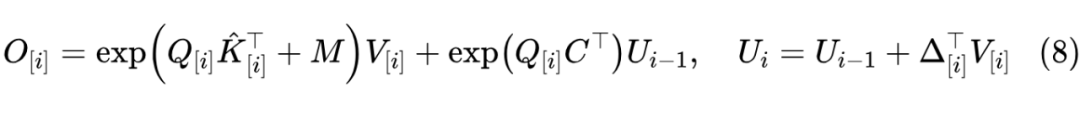
这样我们就将递归步数减少为 了,可以在保证线性效率的同时,更充分发挥硬件的并行能力。用同样的方式也可以计算分母,最后相除得到完整的 Attention 结果。

局域增强
就这样完了?并不是,如果仅仅是这样的话,Transformer-VQ 可能跟以往基于矩阵分解的 Kernelized Attention 如 Performer 并没有太多区别。当序列长度 远大于编码表大小 时,由抽屉原理我们知道部分编码向量必然会反复出现,甚至可以合理猜测所有编码向量应该会均匀分布在整个序列中。
这样一来,邻近 token 的 Attention 就会跟远处某些 token 的 Attention一样,也就是说模型无法区分远近,这本质上就是所有 Kernelized Attention都存在的低秩问题。
已有的经验告诉我们,对于语言模型来说,相对于远处的 token 的来说邻近的 token 往往更为重要,所以一个好的语言模型架构应该具有区分远近的能力。为此,Transformer-VQ 选择在 之后,加上一个 Sliding Window 形状的 Attention Bias(记为 ),来对邻近 token 进行加权,如下图:
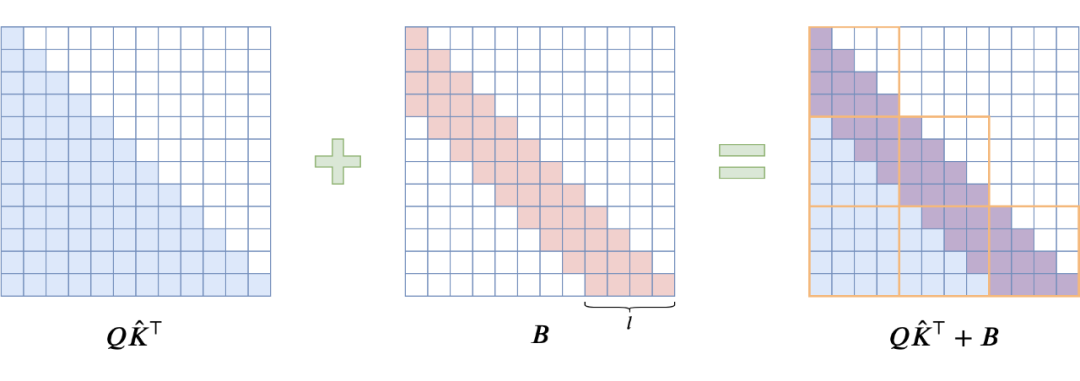
▲ Window Attention Bias 示意图
从最后一个图可以看出,如果将 Window 大小直接设为 block 大小 ,即 或者 时 ,那么在分 block 计算时,矩阵 顶多影响最邻近的两个 block,再远的 block 依旧可以用“挑出”技巧来线性化。为了便于下面的推导,我们记 ,那么
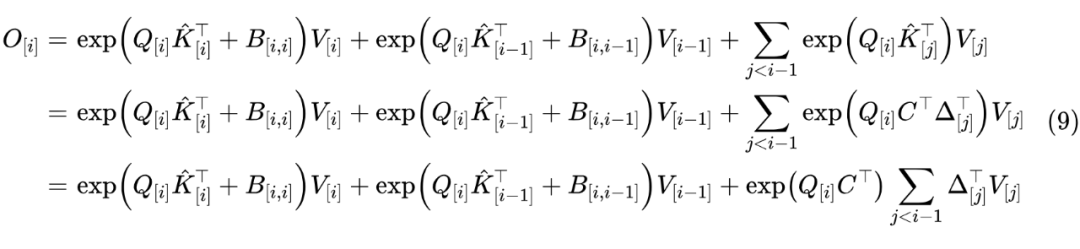
所以很明显,有(约定 都是全零矩阵):
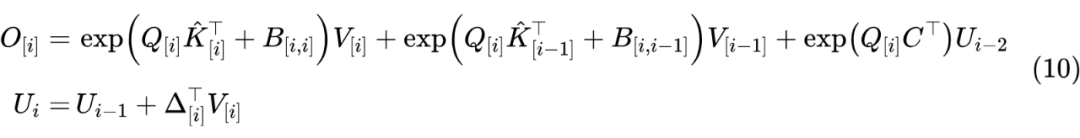
笔者认为, 的引入是 Transformer-VQ 是跟其他 Kernelized Attention 拉开差距的关键,为了减少参数量且支持变长生成,我们约束 的非零部分为 “Toeplitz 矩阵”,即 是 的函数,此时 就相当于加性相对位置编码。除了这种做法外,也可以考虑换为笔者之前提出的 ReRoPE,它是旋转位置编码的窗口版,跟 具有同样的相对位置编码形状。

梯度回传
等等,我们好像忘记了点什么。了解 VQ-VAE 的读者都知道,“ 的每个向量都是 的向量之一”只是前向传播的表现,反向传播用的可是原始的 ,这意味着即便不同位置的 等于同一个 ,但它们的梯度却不相等,这叫做 STE(Straight-Through Estimator)。由于 STE 的存在,“挑出”技巧理论上仅可用于推理阶段,训练阶段是无法线性化的。
没有其他办法了吗?确实如此,如果我们坚持要获得精确的梯度结果,那么并没有线性化效率的方案。然而,考虑到 VQ 的梯度本身就是近似的,所以 Attention 获取精确的梯度似乎也没多大必要。于是作者想了个折衷的方案:依然是按照式 (10)进行递归计算,仅在前两项使用 STE(Key 序列可以获得梯度),而 的梯度直接停掉( 算子)。
这样我们就保持了模型的线性性,同时也已经保留了最重要的梯度(邻近的两个 block),算是一个比较合理的近似方案。从这一点来看,Transformer-VQ 跟 Transformer-XL [4] 很像,Transformer-XL 在递归的同时也停掉了历史窗口的梯度,即历史窗口可以参与递归计算,不传递梯度。
解决了梯度回传问题之后,在自回归交叉熵损失的基础上,再上 VQ 带来的用来更新编码表的辅助 loss,就得到完整的训练目标了。当然,对于编码表的更新,Transformer-VQ 采用了直接滑动平均的方案,所以只补充了 Key 的辅助 loss,这些细节读者在熟悉 VQ-VAE 之后,稍微看一下原论文就理解了。

实验结果
这一节我们来看一下原论文的实验结果。作者已经将代码开源如下:
Github:
https://github.com/transformer-vq/transformer_vq
值得指出的是,作者做 VQ 的基础架构并不是常规的 MHA(Multi-Head Attention),而是笔者一直很推崇的 GAU(Gated Attention Unit)+Softmax,Transformer-VQ更准确的命名应该是 “GAU-VQ”,不了解 GAU 的读者可以参考《FLASH:可能是近来最有意思的高效Transformer设计》和《听说Attention与Softmax更配哦》。简单来说,GAU 本身比 MHA 有着更高的效率,配合上 VQ 技巧后,就更加“如虎添翼”了。
实验方面,作者做了语言模型(ENWIK8、PG-19)和图像生成(IMAGENET64),所有的实验中的编码表大小都是 。模型最大参数量为 1.3B,虽然比不上主流的大模型参数量,但其实对于科研来说不算小了。实验结果总体来说算得上优异:

▲ PG-19的实验结果

▲ 母语与非母语对话占比
最后,让人惊奇的是,Transformer-VQ 的作者只有一个,并且身份是 “Independent Researcher”。

发散思考
笔者发现,从 Transformer-VQ 出发,可以联系到非常多的研究主题,这也是为什么笔者如此欣赏它的原因之一。
首先,再次为作者惊人的洞察力点赞,“只需 VQ一下Key,Transformer 的复杂度就会变成线性”这个发现实在太美妙了,它实现了标准 Attention 到线性 Attention 的自然过渡,并且可以通过加 Attention Bias 的方式让它比很多的 Kernelized Attention 都有效。然后,通过 VQ 进行“聚类”的方式,也比 Linformer [5]、Nyströmformer [2] 等更为高明,因为它防止了未来信息的泄漏,可以自然地用来做 Causal 的语言模型。
我们知道,VQ 本质上也是将序列转为离散 id 的运算,这跟 Tokenizer 的作用是非常相似的。从这个角度来看,Transformer-VQ 跟 MegaByte [6] 等模型一样,都是将 Tokenizer 内置在模型之中,并且相比 MegaByte,VQ 这一操作跟我们传统意义上的 Tokenizer 更为相似、直观。所以,Transformer-VQ 实际上非常适合用来训练直接以 Bytes 输入的 “No Tokenizer” 模型,事实上,上述 ENWIK8 实验就是 Bytes 输入,Transformer-VQ 效果明显优于 MegaByte。
相比近来出的 RetNet,Transformer-VQ 没有显式的远程衰减,所以 Long Context 能力有可能会更好,同时由于 Key 经过了 VQ,都是有限集合之一,所以不会出现没有学过的 Key,因此长度外推能力大概率也会更好。
虽然 Transformer-VQ 的基础架构 GAU 只是 Single-Head 的,但它在递归过程中模型记忆状态大小是 ,在默认的设置中,这比 Multi-Head 的 RetNet 还大(RetNet 的记忆状态大小是 ,默认设置下 ),因此,记忆容量理论上是足够的。
由于上一篇文章刚好写了《简单得令人尴尬的FSQ:“四舍五入”超越了VQ-VAE》,可能会有读者想知道可否用更简单的 FSQ 取代 VQ?笔者认为比较难,原因其实在上一篇文章给出了:
第一, 还属于 VQ 优于 FSQ 的编码数量范围,所以换 FSQ 大概率会掉效果;
第二,由于每层 Attention 的 Key 都要被VQ,所以平均来说 VQ 的 Encoder 和 Decoder 都不强,这种情况 VQ 近似精度更高,FSQ 更适合 Decoder 和 Decoder 都足够强的场景;
第三,Transformer-VQ 需要用的是 Key 被 VQ 之后的中心向量而不是 id,而 FSQ 则直接得到 id,反而不容易恢复为近似的中心向量。
除此之外,用 VQ 而不是 FSQ,使得 Transformer-VQ 有希望从现有的预训练模型如 LLAMA2 中微调过来,而不单单是从零训练。因为 VQ 具有鲜明的几何意义,跟 K-Means 有诸多相通之处,我们可以从现有预训练模型出发,选取一些样本计算出 Key,对 Key 进行 K-Means 得到中心向量作为编码表的初始化,然后在原模型基础上加上 VQ 进行微调。
不过 Transformer-VQ 不大好适配 RoPE,所以要如前面所说,RoPE 的模型要换成 ReRoPE 再 VQ 比较好,此时就可以不用加 Bias 了。
总之,在笔者眼中,Transformer-VQ 在众多 Efficient Transformer 工作中,是非常独特、出色而又潜力深厚的之一。

文章小结
本文介绍了一个名为 Transformer-VQ 的 Efficient Transformer 方案,它基于“只需 VQ一下Key,Transformer 的复杂度就会变成线性”的观察结果进行展开,个人认为是一种非常独特且亮眼的线性化思路,实验结果也很优异。它既可以理解为一种更高明的线性 Attention/RNN 模型,也可以理解为一个带有“可训练的 Tokenizer” 的 Attention 模型。

参考文献
[1] https://arxiv.org/abs/2309.16354
[2] https://kexue.fm/archives/8180
[3] https://kexue.fm/archives/6760
[4] https://arxiv.org/abs/1901.02860
[5] https://arxiv.org/abs/2006.04768
[6] https://arxiv.org/abs/2305.07185
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·