目录
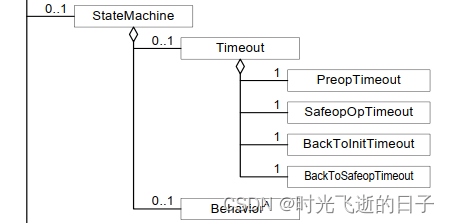
14.1.5.2. MemStore 刷盘
全局内存控制
MemStore 达到上限
RegionServer 的 Hlog 数量达到上限
手工触发
关闭 RegionServer 触发
Region 使用 HLOG 恢复完数据后触发
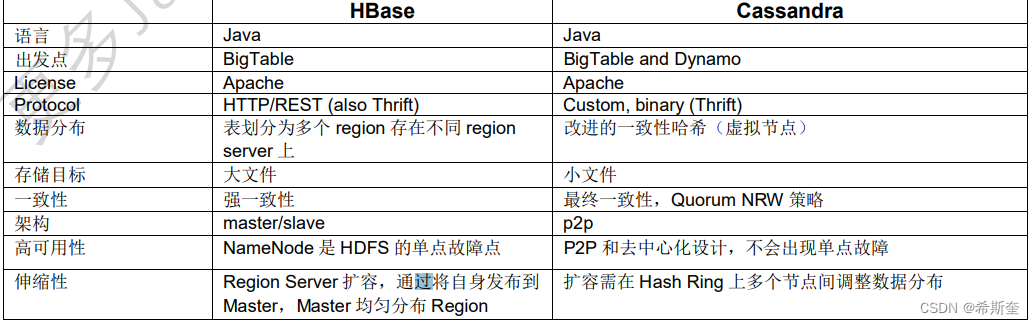
14.1.6.HBase vs Cassandra
15. MongoDB
15.1.1. 概念
15.1.2. 特点
16. Cassandra
16.1.1. 概念
16.1.2. 数据模型
16.1.3. Cassandra 一致 Hash 和虚拟节点
16.1.4. Gossip 协议
Gossip 节点的通信方式及收敛性
Gossip 两个节点(A、B)之间存在三种通信方式(push、pull、push&pull)
gossip 的协议和 seed list(防止集群分列)
16.1.5. 数据复制
Partitioners(计算 primary key token 的 hash 函数)
两种可用的复制策略:
NetworkTopologyStrategy:可用于较复杂的多数据中心。
16.1.6. 数据写请求和协调者
协调者(coordinator)
16.1.7. 数据读请求和后台修复
16.1.8. 数据存储(CommitLog、MemTable、SSTable)
SSTable 文件构成(BloomFilter、index、data、static)
16.1.9. 二级索引(对要索引的 value 摘要,生成 RowKey)
16.1.10. 数据读写
数据写入和更新(数据追加)
数据的写和删除效率极高
错误恢复简单
读的复杂度高
数据删除(column 的墓碑)
墓碑
垃圾回收 compaction
数据读取(memtable+SStables)
MemTable:
Row Cache(SSTables 中频繁被访问的数)
Bloom Filter(查找数据可能对应的 SSTable)
Partition Key Cache(查找数据可能对应的 Partition key)
Partition Summary(内存中存储一些 partition index 的样本)
Partition Index(磁盘中)
Compression offset map(磁盘中)

14.1.5.2. MemStore 刷盘
为了提高 Hbase 的写入性能,当写请求写入 MemStore 后,不会立即刷盘。而是会等到一 定的时候进行刷盘的操作。具体是哪些场景会触发刷盘的操作呢?总结成如下的几个场景:
全局内存控制
1. 这个全局的参数是控制内存整体的使用情况,当所有 memstore 占整个 heap 的最大比 例的时候,会触发刷盘的操作。这个参数是 hbase.regionserver.global.memstore.upperLimit,默认为整个 heap 内存的 40%。 但这并不意味着全局内存触发的刷盘操作会将所有的 MemStore 都进行输盘,而是通过 另外一个参数 hbase.regionserver.global.memstore.lowerLimit 来控制,默认是整个 heap 内存的 35%。当 flush 到所有 memstore 占整个 heap 内存的比率为 35%的时 候,就停止刷盘。这么做主要是为了减少刷盘对业务带来的影响,实现平滑系统负载的 目的。
MemStore 达到上限
2. 当 MemStore 的大小达到 hbase.hregion.memstore.flush.size 大小的时候会触发刷 盘,默认 128M 大小
RegionServer 的 Hlog 数量达到上限
3. 前面说到 Hlog 为了保证 Hbase 数据的一致性,那么如果 Hlog 太多的话,会导致故障 恢复的时间太长,因此 Hbase 会对 Hlog 的最大个数做限制。当达到 Hlog 的最大个数 的时候,会强制刷盘。这个参数是 hase.regionserver.max.logs,默认是 32 个。
手工触发
4. 可以通过 hbase shell 或者 java api 手工触发 flush 的操作。
关闭 RegionServer 触发
5. 在正常关闭 RegionServer 会触发刷盘的操作,全部数据刷盘后就不需要再使用 Hlog 恢 复数据。
Region 使用 HLOG 恢复完数据后触发
6. :当 RegionServer 出现故障的时候,其上面的 Region 会迁移到其他正常的 RegionServer 上,在恢复完 Region 的数据后,会触发刷盘,当刷盘完成后才会提供给 业务访问。
14.1.6.HBase vs Cassandra


15. MongoDB
15.1.1. 概念
MongoDB 是由 C++语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情 况下,添加更多的节点,可以保证服务器性能。MongoDB 旨在为 WEB 应用提供可扩展的高性能 数据存储解决方案。 MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似 于 JSON 对象。字段值可以包含其他文档,数组及文档数组。

15.1.2. 特点
MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
你可以在 MongoDB 记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Ga ndhi Road")来实现更快的排序。
你可以通过本地或者网络创建数据镜像,这使得 MongoDB 有更强的扩展性。
如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其 他节点上这就是所谓的分片。
Mongo 支持丰富的查询表达式。查询指令使用 JSON 形式的标记,可轻易查询文档中内嵌的 对象及数组。
MongoDb 使用 update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
Mongodb 中的 Map/reduce 主要是用来对数据进行批量处理和聚合操作。
Map 和 Reduce。Map 函数调用 emit(key,value)遍历集合中所有的记录,将 key 与 value 传 给 Reduce 函数进行处理。
Map 函数和 Reduce 函数是使用 Javascript 编写的,并可以通过 db.runCommand 或 mapre duce 命令来执行 MapReduce 操作。
GridFS 是 MongoDB 中的一个内置功能,可以用于存放大量小文件。
MongoDB 允许在服务端执行脚本,可以用 Javascript 编写某个函数,直接在服务端执行,也 可以把函数的定义存储在服务端,下次直接调用即可。
16. Cassandra
16.1.1. 概念
Apache Cassandra 是高度可扩展的,高性能的分布式 NoSQL 数据库。 Cassandra 旨在处理许 多商品服务器上的大量数据,提供高可用性而无需担心单点故障。 Cassandra 具有能够处理大量数据的分布式架构。 数据放置在具有多个复制因子的不同机器上, 以获得高可用性,而无需担心单点故障。
16.1.2. 数据模型
Key Space(对应 SQL 数据库中的 database)
1. 一个 Key Space 中可包含若干个 CF,如同 SQL 数据库中一个 database 可包含多个 table
Key(对应 SQL 数据库中的主键)
2. 在 Cassandra 中,每一行数据记录是以 key/value 的形式存储的,其中 key 是唯一标识。 column(对应 SQL 数据库中的列)
3. Cassandra 中每个 key/value 对中的 value 又称为 column,它是一个三元组,即:name, value 和 timestamp,其中 name 需要是唯一的。
super column(SQL 数据库不支持)
4. cassandra 允许 key/value 中的 value 是一个 map(key/value_list),即某个 column 有多个 子列。
Standard Column Family(相对应 SQL 数据库中的 table)
5. 每个 CF 由一系列 row 组成,每个 row 包含一个 key 以及其对应的若干 column。
Super Column Family(SQL 数据库不支持)
6. 每个 SCF 由一系列 row 组成,每个 row 包含一个 key 以及其对应的若干 super column。
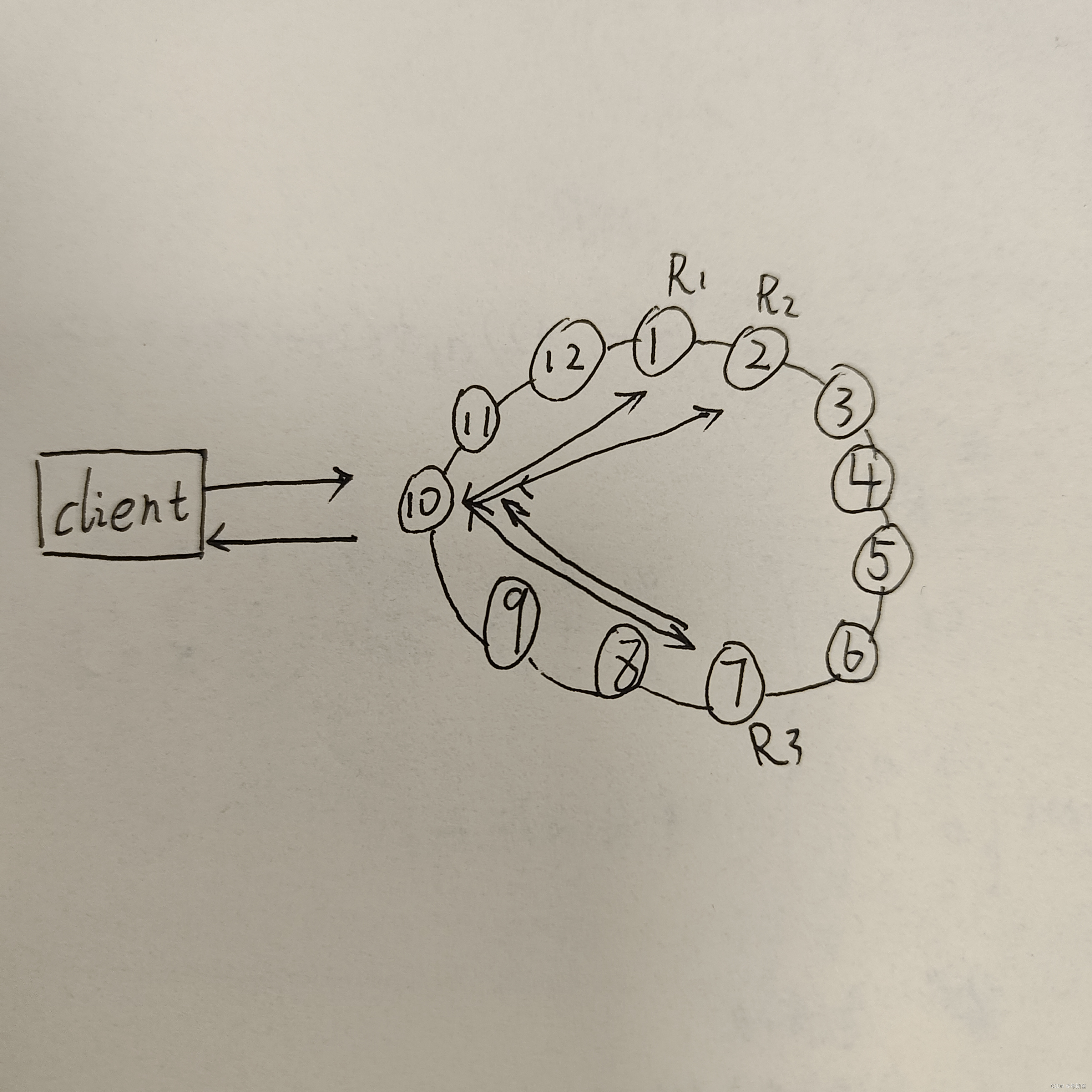
16.1.3. Cassandra 一致 Hash 和虚拟节点
一致性 Hash(多米诺 down 机)
为每个节点分配一个 token,根据这个 token 值来决定节点在集群中的位置以及这个节点所存储 的数据范围。
虚拟节点(down 机多节点托管)
由于这种方式会造成数据分布不均的问题,在 Cassandra1.2 以后采用了虚拟节点的思想:不需要 为每个节点分配 token,把圆环分成更多部分,让每个节点负责多个部分的数据,这样一个节点移 除后,它所负责的多个 token 会托管给多个节点处理,这种思想解决了数据分布不均的问题。

如图所示,上面部分是标准一致性哈希,每个节点负责圆环中连续的一段,如果 Node2 突然 down 掉,Node2 负责的数据托管给 Node1,即 Node1 负责 EFAB 四段,如果 Node1 里面有 很多热点用户产生的数据导致 Node1 已经有点撑不住了,恰巧 B 也是热点用户产生的数据,这样 一来 Node1 可能会接着 down 机,Node1down 机,Node6 还 hold 住吗?
下面部分是虚拟节点实现,每个节点不再负责连续部分,且圆环被分为更多的部分。如果 Node2 突然 down 掉,Node2 负责的数据不全是托管给 Node1,而是托管给多个节点。而且也保持了一 致性哈希的特点。
16.1.4. Gossip 协议
Gossip 算法如其名,灵感来自办公室八卦,只要一个人八卦一下,在有限的时间内所有的人都 会知道该八卦的信息,这种方式也与病毒传播类似,因此 Gossip 有众多的别名“闲话算法”、 “疫情传播算法”、“病毒感染算法”、“谣言传播算法”。 Gossip 的特点:在一个有界网络中, 每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一 致。因为 Gossip 不要求节点知道所有其他节点,因此又具有去中心化的特点,节点之间完全对等, 不需要任何的中心节点。实际上 Gossip 可以用于众多能接受“最终一致性”的领域:失败检测、 路由同步、Pub/Sub、动态负载均衡。
Gossip 节点的通信方式及收敛性
Gossip 两个节点(A、B)之间存在三种通信方式(push、pull、push&pull)
1. push: A 节点将数据(key,value,version)及对应的版本号推送给 B 节点,B 节点更新 A 中比自 己新的数据。
2. pull:A 仅将数据 key,version 推送给 B,B 将本地比 A 新的数据(Key,value,version)推送 给 A,A 更新本地。
3. push/pull:与 pull 类似,只是多了一步,A 再将本地比 B 新的数据推送给 B,B 更新本地。 如果把两个节点数据同步一次定义为一个周期,则在一个周期内,push 需通信 1 次,pull 需 2 次, push/pull 则需 3 次,从效果上来讲,push/pull 最好,理论上一个周期内可以使两个节点完全一 致。直观上也感觉,push/pull 的收敛速度是最快的。
gossip 的协议和 seed list(防止集群分列)
cassandra 使用称为 gossip 的协议来发现加入 C 集群中的其他节点的位置和状态信息。gossip 进 程每秒都在进行,并与至多三个节点交换状态信息。节点交换他们自己和所知道的信息,于是所 有的节点很快就能学习到整个集群中的其他节点的信息。gossip 信息有一个相关的版本号,于是 在一次 gossip 信息交换中,旧的信息会被新的信息覆盖重写。要阻止分区进行 gossip 交流,那么 在集群中的所有节点中使用相同的 seed list,种子节点的指定除了启动起 gossip 进程外,没有其 他的目的。种子节点不是一个单点故障,他们在集群操作中也没有其他的特殊目的,除了引导节 点以外。
16.1.5. 数据复制
Partitioners(计算 primary key token 的 hash 函数)
在 Cassandra 中,table 的每行由唯一的 primarykey 标识,partitioner 实际上为一 hash 函数用 以计算 primary key 的 token。Cassandra 依据这个 token 值在集群中放置对应的行
两种可用的复制策略:
SimpleStrategy:仅用于单数据中心,
将第一个 replica 放在由 partitioner 确定的节点中,其余的 replicas 放在上述节点顺时针方向的 后续节点中。
NetworkTopologyStrategy:可用于较复杂的多数据中心。
可以指定在每个数据中心分别存储多少份 replicas。 复制策略在创建 keyspace 时指定,如 CREATE KEYSPACE Excelsior WITH REPLICATION = { 'class' : 'SimpleStrategy','replication_factor' : 3 }; CREATE KEYSPACE Excalibur WITH REPLICATION = {'class' :'NetworkTopologyStrategy', 'dc1' : 3, 'dc2' : 2};
16.1.6. 数据写请求和协调者
协调者(coordinator)
协调者(coordinator)将 write 请求发送到拥有对应 row 的所有 replica 节点,只要节点可用便获取 并执行写请求。写一致性级别(write consistency level)确定要有多少个 replica 节点必须返回成功 的确认信息。成功意味着数据被正确写入了 commit log 和 memtable。

其中 dc1、dc2 这些数据中心名称要与 snitch 中配置的名称一致.上面的拓扑策略表示在 dc1 配置 3 个副本,在 dc2 配置 2 个副本
16.1.7. 数据读请求和后台修复
1. 协调者首先与一致性级别确定的所有 replica 联系,被联系的节点返回请求的数据。
2. 若多个节点被联系,则来自各 replica 的 row 会在内存中作比较,若不一致,则协调者使用含 最新数据的 replica 向 client 返回结果。那么比较操作过程中只需要传递时间戳就可以,因为要 比较的只是哪个副本数据是最新的。
3. 协调者在后台联系和比较来自其余拥有对应 row 的 replica 的数据,若不一致,会向过时的 replica 发写请求用最新的数据进行更新 read repair。
16.1.8. 数据存储(CommitLog、MemTable、SSTable)
写请求分别到 CommitLog 和 MemTable, 并且 MemTable 的数据会刷写到磁盘 SSTable 上. 除 了写数据,还有索引也会保存到磁盘上.
先将数据写到磁盘中的 commitlog,同时追加到中内存中的数据结构 memtable 。这个时候就会 返回客户端状态 , memtable 内 容 超 出 指 定 容 量 后 会 被 放 进 将 被 刷 入 磁 盘 的 队 列 (memtable_flush_queue_size 配置队列长度)。若将被刷入磁盘的数据超出了队列长度,将内存 数据刷进磁盘中的 SSTable,之后 commit log 被清空。
SSTable 文件构成(BloomFilter、index、data、static)
SSTable 文件有 fileer(判断数据 key 是否存在,这里使用了 BloomFilter 提高效率),index(寻 找对应 column 值所在 data 文件位置)文件,data(存储真实数据)文件,static(存储和统计 column 和 row 大小)文件。
16.1.9. 二级索引(对要索引的 value 摘要,生成 RowKey)
在 Cassandra 中,数据都是以 Key-value 的形式保存的。

KeysIndex 所创建的二级索引也被保存在一张 ColumnFamily 中。在插入数据时,对需要进行索 引的 value进行摘要,生成独一无二的key,将其作为 RowKey保存在索引的 ColumnFamily 中; 同时在 RowKey 上添加一个 Column,将插入数据的 RowKey 作为 name 域的值,value 域则赋 空值,timestamp 域则赋为插入数据的时间戳。
如果有相同的 value 被索引了,则会在索引 ColumnFamily 中相同的 RowKey 后再添加新的 Column。如果有新的 value 被索引,则会在索引 ColumnFamily 中添加新的 RowKey 以及对应 新的 Column。
当对 value 进行查询时,只需计算该 value 的 RowKey,在索引 ColumnFamily 中的查找该 RowKey,对其 Columns 进行遍历就能得到该 value 所有数据的 RowKey。
16.1.10. 数据读写
数据写入和更新(数据追加)
Cassandra 的设计思路与这些系统不同,无论是 insert 还是 remove 操作,都是在已有的数据后 面进行追加,而不修改已有的数据。这种设计称为 Log structured 存储,顾名思义就是系统中的 数据是以日志的形式存在的,所以只会将新的数据追加到已有数据的后面。Log structured 存储 系统有两个主要优点:
数据的写和删除效率极高
传统的存储系统需要更新元信息和数据,因此磁盘的磁头需要反复移动,这是一个比较耗时 的操作,而 Log structured 的系统则是顺序写,可以充分利用文件系统的 cache,所以效率 很高。
错误恢复简单
由于数据本身就是以日志形式保存,老的数据不会被覆盖,所以在设计 journal 的时候不需 要考虑 undo,简化了错误恢复。
读的复杂度高
但是,Log structured 的存储系统也引入了一个重要的问题:读的复杂度和性能。理论上 说,读操作需要从后往前扫描数据,以找到某个记录的最新版本。相比传统的存储系统,这 是比较耗时的
数据删除(column 的墓碑)
如果一次删除操作在一个节点上失败了(总共 3 个节点,副本为 3, RF=3).整个删除操作仍然被 认为成功的(因为有两个节点应答成功,使用 CL.QUORUM 一致性)。接下来如果读发生在该节 点上就会变的不明确,因为结果返回是空,还是返回数据,没有办法确定哪一种是正确的。
Cassandra 总是认为返回数据是对的,那就会发生删除的数据又出现了的事情,这些数据可以叫” 僵尸”,并且他们的表现是不可预见的。
墓碑
删除一个 column 其实只是插入一个关于这个 column 的墓碑(tombstone),并不直接删除原 有的 column。该墓碑被作为对该 CF 的一次修改记录在 Memtable 和 SSTable 中。墓碑的内容 是删除请求被执行的时间,该时间是接受客户端请求的存储节点在执行该请求时的本地时间 (local delete time),称为本地删除时间。需要注意区分本地删除时间和时间戳,每个 CF 修改 记录都有一个时间戳,这个时间戳可以理解为该 column 的修改时间,是由客户端给定的。
垃圾回收 compaction
由于被删除的 column 并不会立即被从磁盘中删除,所以系统占用的磁盘空间会越来越大,这就 需要有一种垃圾回收的机制,定期删除被标记了墓碑的 column。垃圾回收是在 compaction 的过 程中完成的。
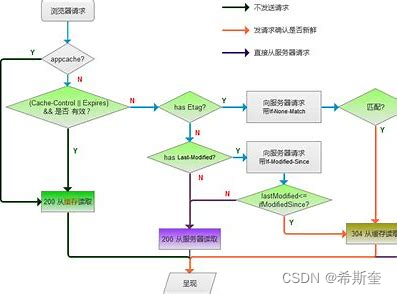
数据读取(memtable+SStables)
为了满足读 cassandra 读取的数据是 memtable 中的数据和 SStables 中数据的合并结果。读取 SSTables 中的数据就是查找到具体的哪些的 SSTables 以及数据在这些 SSTables 中的偏移量 (SSTables 是按主键排序后的数据块)。首先如果 row cache enable 了话,会检测缓存。缓存命中 直接返回数据,没有则查找 Bloom filter,查找可能的 SSTable。然后有一层 Partition key cache, 找 partition key 的位置。如果有根据找到的 partition 去压缩偏移量映射表找具体的数据块。如果 缓存没有,则要经过 Partition summary,Partition index 去找 partition key。然后经过压缩偏移 量映射表找具体的数据块。
1. 检查 memtable
2. 如果 enabled 了,检查 row cache
3. 检查 Bloom filter
4. 如果 enable 了,检查 partition key 缓存
5. 如果在 partition key 缓存中找到了 partition key,直接去 compression offset 命中,如果没 有,检查 partition summary
6. 根据 compression offset map 找到数据位置
7. 从磁盘的 SSTable 中取出数据
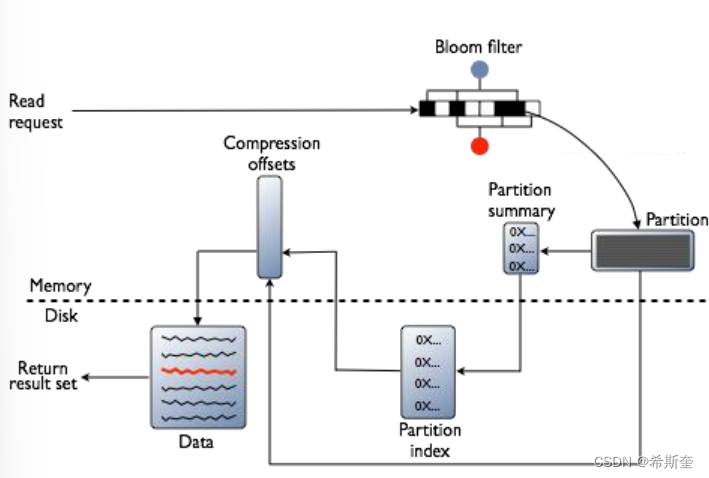
行缓存和键缓存请求流程图:
MemTable:
如果 memtable 有目标分区数据,这个数据会被读出来并且和从 SSTables 中读出 来的数据进行合并。SSTable 的数据访问如下面所示的步骤。
Row Cache(SSTables 中频繁被访问的数)
Row Candra2.2+,它们被存储在堆外内存,使用全新的实现避免造成垃圾回收对 JVM 造成压力。 存在在 row cache 的子集数据可以在特定的一段时间内配置一定大小的内存。row cache 使用 LRU(least-recently-userd)进行回收在申请内存。存储在 row cache 中的数据是 SSTables 中频繁 被访问的数据。存储到row cache中后,数据就可以被后续的查询访问。row cache不是写更新。 如果写某行了,这行的缓存就会失效,并且不会被继续缓存,直到这行被读到。类似的,如果一 个partition更新了,整个partition的cache都会被移除,但目标的数据在row cache中找不到, 就会去检查 Bloom filter。
Bloom Filter(查找数据可能对应的 SSTable)
首先,Cassandra 检查 Bloom filter 去发现哪个 SSTables 中有可能有请求的分区数据。Bloom filter 是存储在堆外内存。每个 SSTable 都有一个关联的 Bloom filter。一个 Bloom filter 可以建 立一个 SSTable 没有包含的特定的分区数据。同样也可以找到分区数据存在 SSTable 中的可能性。 它可以加速查找 partition key 的查找过程。然而,因为 Bloom filter 是一个概率函数,所以可能 会得到错误的结果,并不是所有的 SSTables 都可以被 Bloom filter 识别出是否有数据。如果 Bloom filter 不能够查找到 SSTable,Cassandra 会检查 partition key cache。Bloom filter 大小 增长很适宜,每 10 亿数据 1~2GB。在极端情况下,可以一个分区一行。都可以很轻松的将数十 亿的 entries 存储在单个机器上。Bloom filter 是可以调节的,如果你愿意用内存来换取性能。
Partition Key Cache(查找数据可能对应的 Partition key)
partition key 缓存如果开启了,将 partition index 存储在堆外内存。key cache 使用一小块可配 置大小的内存。在读的过程中,每个”hit”保存一个检索。如果在 key cache 中找到了 partition key。就直接到 compression offset map 中招对应的块。partition key cache 热启动后工作的更 好,相比较冷启动,有很大的性能提升。如果一个节点上的内存非常受限制,可能的话,需要限 制保存在 key cache 中的 partition key 数目。如果一个在 key cache 中没有找到 partition key。 就会去partition summary中去找。partition key cache 大小是可以配置的,意义就是存储在key cache 中的 partition keys 数目。
Partition Summary(内存中存储一些 partition index 的样本)
partition summary 是存储在堆外内存的结构,存储一些 partition index 的样本。如果一个 partition index 包含所有的 partition keys。鉴于一个 partition summary 从每 X 个 keys 中取 样,然后将每 X 个 key map 到 index 文件中。例如,如果一个 partition summary 设置了 20keys 进行取样。它就会存储 SSTable file 开始的一个 key,20th 个 key,以此类推。尽管并不知道 partition key 的具体位置,partition summary 可以缩短找到 partition 数据位置。当找到了 partition key 值可能的范围后,就会去找 partition index。通过配置取样频率,你可以用内存来 换取性能,当 partition summary 包含的数据越多,使用的内存越多。可以通过表定义的 index interval 属性来改变样本频率。固定大小的内存可以通过 index_summary_capacity_in_mb 属性 来设置,默认是堆大小的 5%。
Partition Index(磁盘中)
partition index 驻扎在磁盘中,索引所有 partition keys 和偏移量的映射。如果 partition summary 已经查到 partition keys 的范围,现在的检索就是根据这个范围值来检索目标 partition key。需要进行单次检索和顺序读。根据找到的信息。然后去 compression offset map 中去找磁 盘中有这个数据的块。如果 partition index 必须要被检索,则需要检索两次磁盘去找到目标数据。
Compression offset map(磁盘中)
compression offset map 存储磁盘数据准确位置的指针。存储在堆外内存,可以被 partition key cache 或者 partition index 访问。一旦 compression offset map 识别出来磁盘中的数据位置, 就会从正确的 SStable(s)中取出数据。查询就会收到结果集。