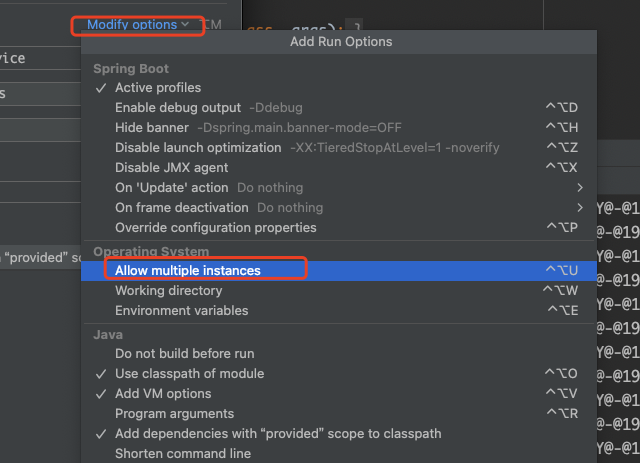
大家好,今天给大家介绍一款轻量、快速、稳定可编排的组件式规则引擎框架LiteFlow。
一、LiteFlow的介绍
前言
在每个公司的系统中,总有一些拥有复杂业务逻辑的系统,这些系统承载着核心业务逻辑,几乎每个需求都和这些核心业务有关,这些核心业务业务逻辑冗长,涉及内部逻辑运算,缓存操作,持久化操作,外部资源调取,内部其他系统RPC调用等等。时间一长,项目几经易手,维护的成本就会越来越高。各种硬代码判断,分支条件越来越多。代码的抽象,复用率也越来越低,各个模块之间的耦合度很高。一小段逻辑的变动,会影响到其他模块,需要进行完整回归测试来验证。如要灵活改变业务流程的顺序,则要进行代码大改动进行抽象,重新写方法。实时热变更业务流程,几乎很难实现。
LiteFlow框架的作用
LiteFlow就是为解耦复杂逻辑而生,如果你要对复杂业务逻辑进行新写或者重构,用LiteFlow最合适不过。它是一个轻量,快速的组件式流程引擎框架,组件编排,帮助解耦业务代码,让每一个业务片段都是一个组件,并支持热加载规则配置,实现即时修改。
使用LiteFlow,你需要去把复杂的业务逻辑按代码片段拆分成一个个小组件,并定义一个规则流程配置。这样,所有的组件,就能按照你的规则配置去进行复杂的流转。
LiteFlow的设计原则
LiteFlow是基于工作台模式进行设计的,何谓工作台模式?
n个工人按照一定顺序围着一张工作台,按顺序各自生产零件,生产的零件最终能组装成一个机器,每个工人只需要完成自己手中零件的生产,而无需知道其他工人生产的内容。每一个工人生产所需要的资源都从工作台上拿取,如果工作台上有生产所必须的资源,则就进行生产,若是没有,就等到有这个资源。每个工人所做好的零件,也都放在工作台上。
这个模式有几个好处:
-
每个工人无需和其他工人进行沟通。工人只需要关心自己的工作内容和工作台上的资源。这样就做到了每个工人之间的解耦和无差异性。
-
即便是工人之间调换位置,工人的工作内容和关心的资源没有任何变化。这样就保证了每个工人的稳定性。
-
如果是指派某个工人去其他的工作台,工人的工作内容和需要的资源依旧没有任何变化,这样就做到了工人的可复用性。
-
因为每个工人不需要和其他工人沟通,所以可以在生产任务进行时进行实时工位更改:替换,插入,撤掉一些工人,这样生产任务也能实时地被更改。这样就保证了整个生产任务的灵活性。
这个模式映射到LiteFlow框架里,工人就是组件,工人坐的顺序就是流程配置,工作台就是上下文,资源就是参数,最终组装的这个机器就是这个业务。正因为有这些特性,所以LiteFlow能做到统一解耦的组件和灵活的装配。
二、LiteFlow的使用
1)非Spring环境下
引入pom依赖
<dependency><groupId>com.yomahub</groupId><artifactId>liteflow-core</artifactId><version>2.6.13</version></dependency>
第一步构建自己的业务Node,也就是继承NodeComponent,重写process方法,业务执行的过程中,会调用process来执行节点的业务。
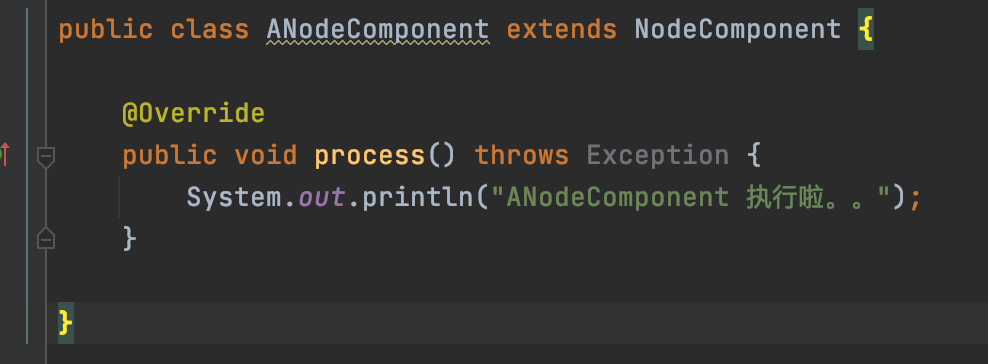
我这里写了三个
然后编写xml文件,直接放在resources底下
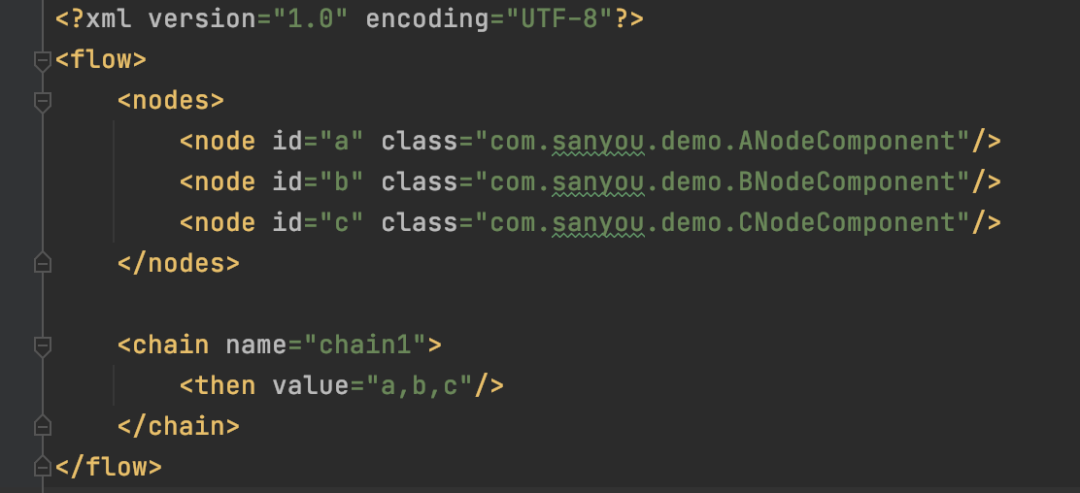
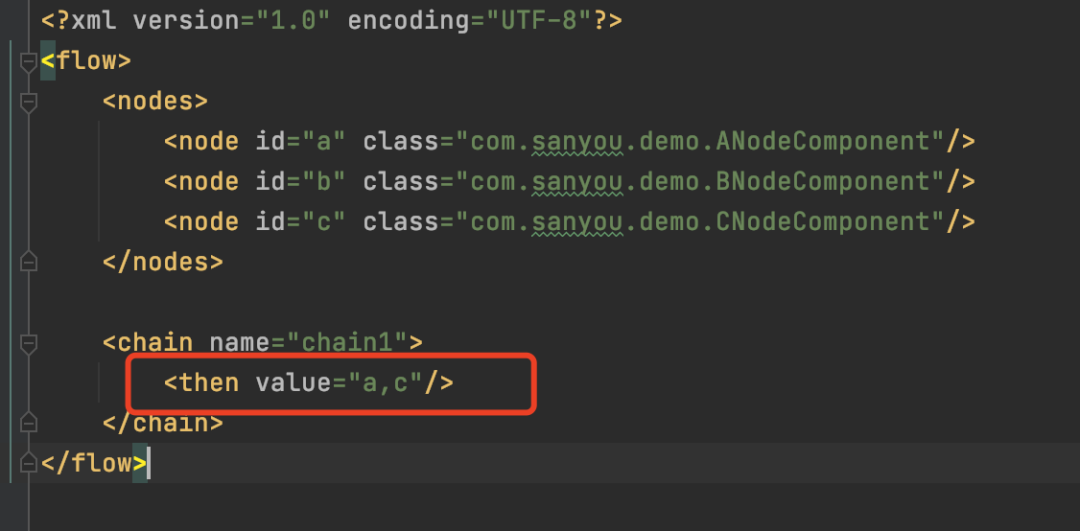
<nodes/>配置了每个业务的节点,这里配置了我们写的那几个,<chain/>标签代表了每一个业务的执行流程,配置了<when/>和<then/>标签,然后value标签设置了上面配置的<node/>的id,至于为什么这么配置,后面会解析。
然后执行这个demo
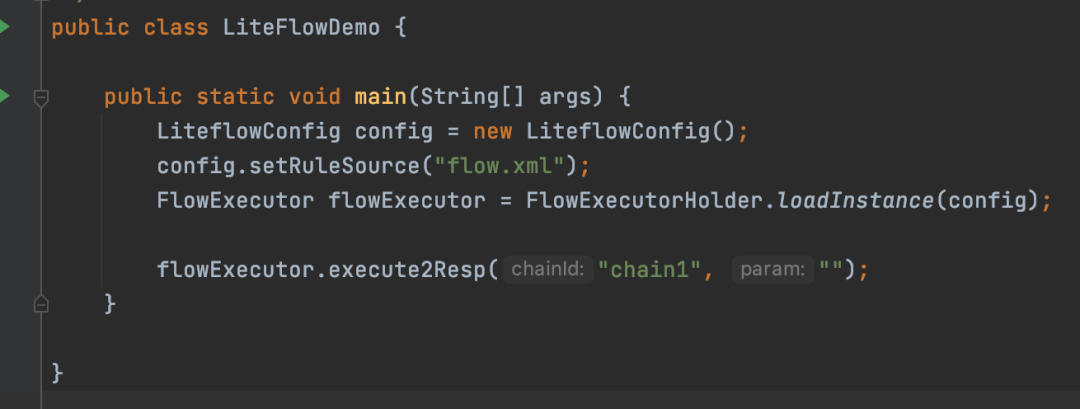
构建了一个LiteflowConfig,传入xml的路径,然后构建FlowExecutor,最后调用FlowExecutor的execute2Resp,传入需要执行的业务流程名字 chain1 ,就是xml中配置的,执行业务流程。
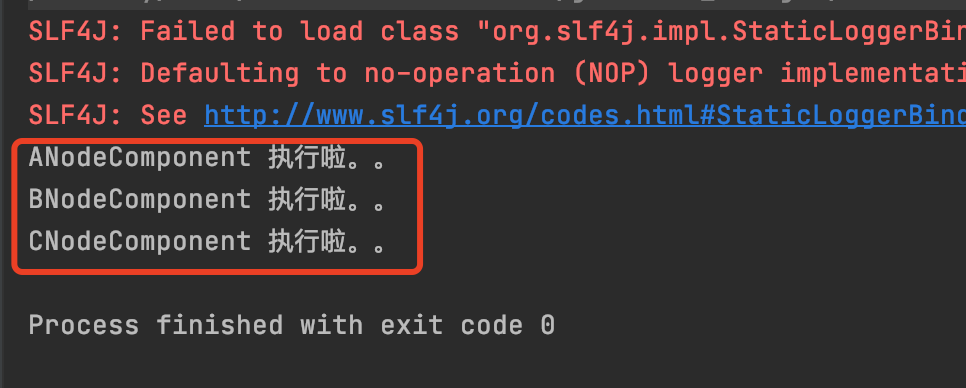
结果
如果业务变动,现在不需要执行B流程了,那么直接修改规则文件就行了,如图。
运行结果
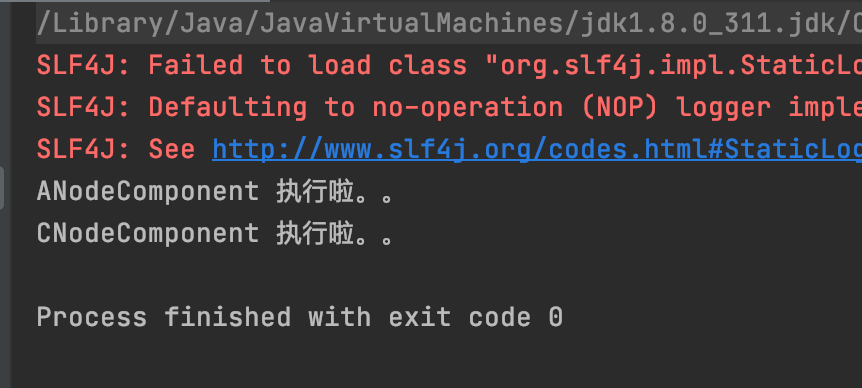
这里发现B就没执行了。
2)SpringBoot环境下
引入pom依赖
<dependency><groupId>com.yomahub</groupId><artifactId>liteflow-spring-boot-starter</artifactId><version>2.6.13</version></dependency>
构建自己的业务Node,只不过在Spring的环境底下,可以不需要在xml配置<node/>标签,直接使用@LiteflowComponent注解即可

xml中没有声明<node/>标签
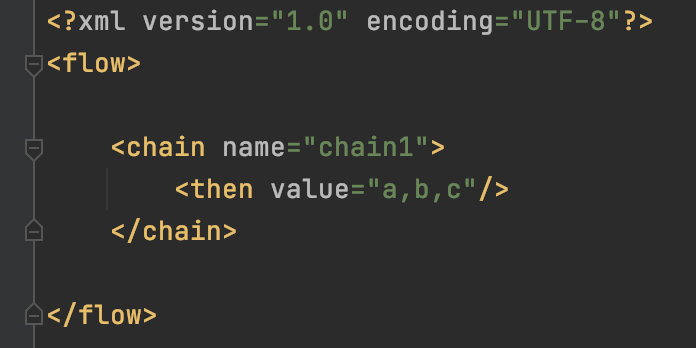
application.properties中配置xml文件的路径
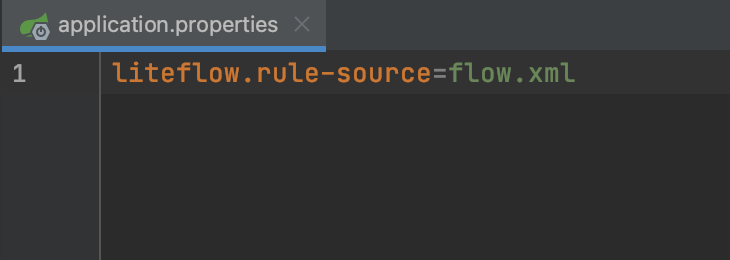
测试代码
执行结果
跟非spring的环境结果一致。
如果有想要获取demo的小伙伴在微信公众号后台回复 LiteFlow 即可获取。
通过上面的例子我们可以看出,其实每个业务节点之间是没有耦合的,用户只需要按照一定的业务规则配置节点的执行顺序,LiteFlow就能实现业务的执行。
三、LiteFlow核心组件讲解
讲解核心组件的时候如果有什么不是太明白的,可以继续往下看,后面会有源码解析。
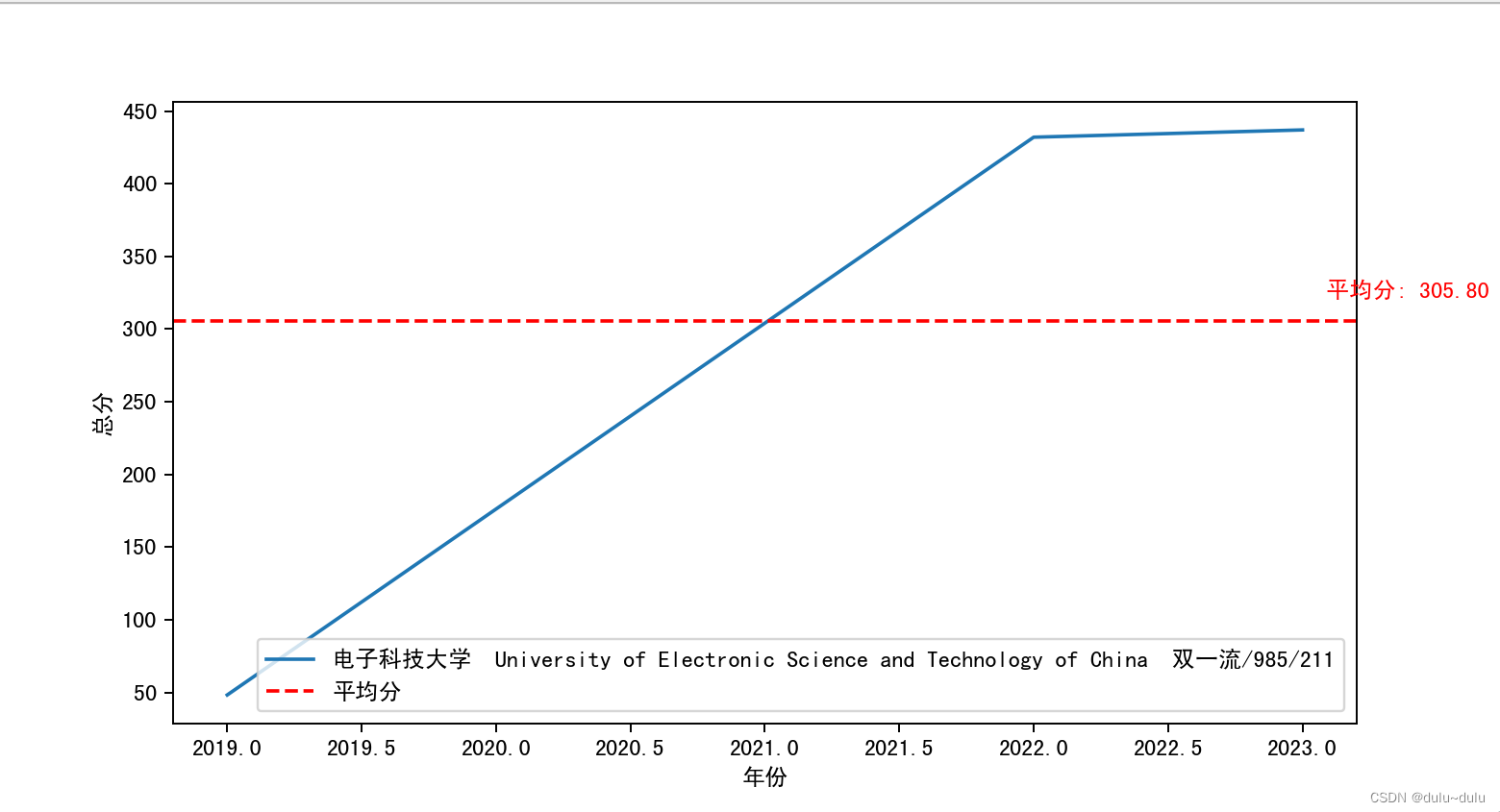
下图为LiteFlow整体架构图
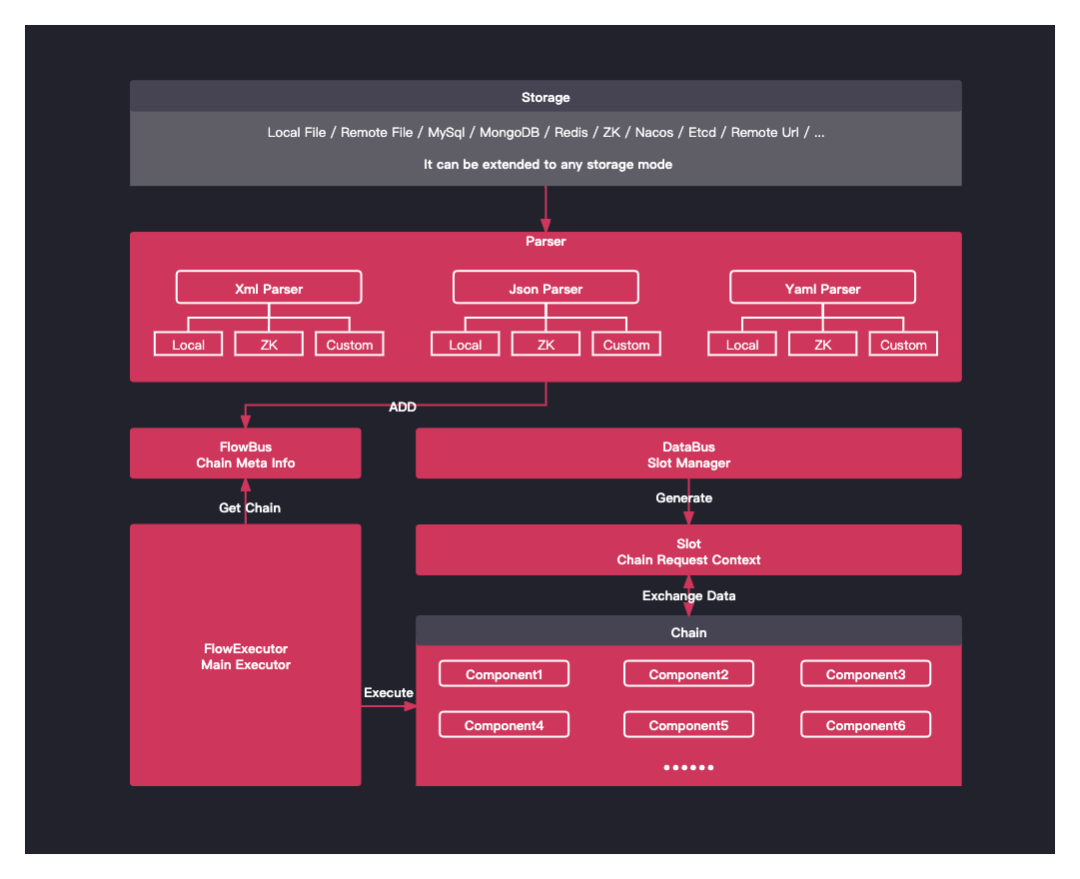
1)Parser
这个组件的作用就是用来解析流程配置的规则,也就是将你配置的规则文件解析成Java代码来运行。支持的文件格式有xml、json、yaml,其实不论是什么格式,只是形式的不同,用户可根据自身配置的习惯来选择规则文件的格式。
同时,规则文件的存储目前官方支持基于zk或者本地文件的形式,同时也支持自定义的形式。
对于xml来说,Parser会将<node/>标签解析成Node对象,将<chain/>解析成Chain对象,将<chain/>内部的比如<when/>、<then/>等标签都会解析成Condition对象。
如下图所示。
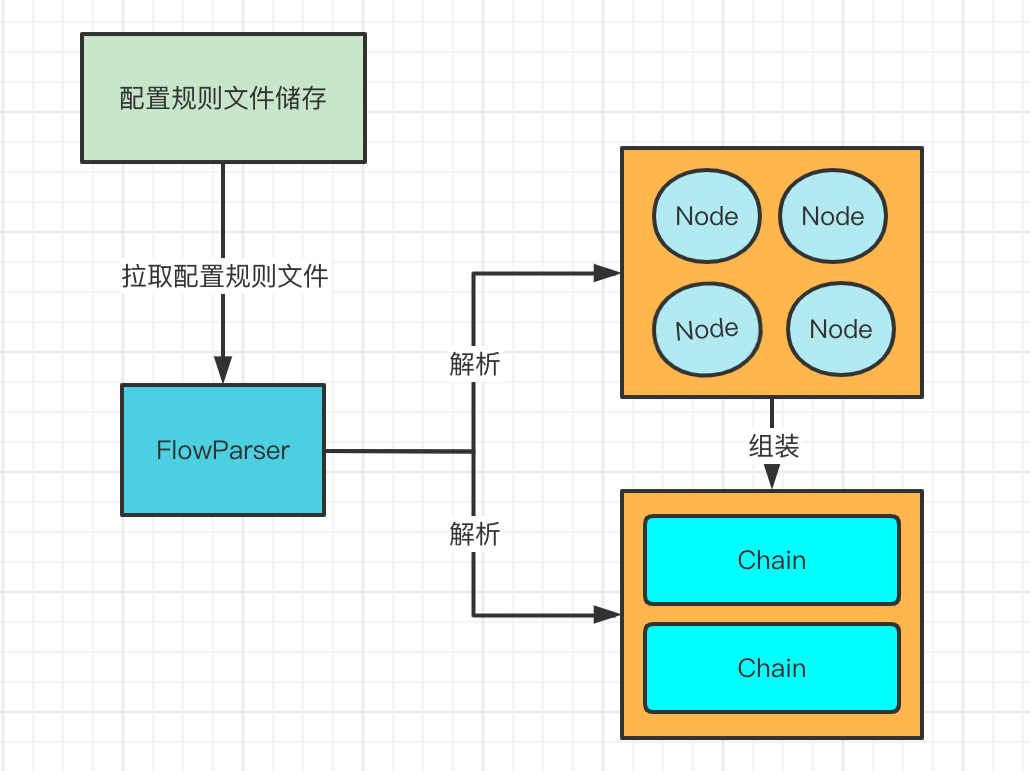
-
Node其实就是代表了你具体业务执行的节点,就是真正的业务是在Node中执行的
-
Condition可以理解为一种条件,比如前置条件,后置条件,里面一个Condition可以包含许多需要执行的Node
-
Chain可以理解成整个业务执行的流程,按照一定的顺序来执行Condition中的Node也就是业务节点
Condition和Node的关系

Condition分为以下几种
-
PreCondition:在整个业务执行前执行,就是前置的作用
-
ThenCondition:内部的Node是串行执行的
-
WhenCondition:内部的Node是并行执行的
-
FinallyCondition:当前面的Condition中的Node都执行完成之后,就会执行这个Condition中的Node节点
Chain和Condition的关系
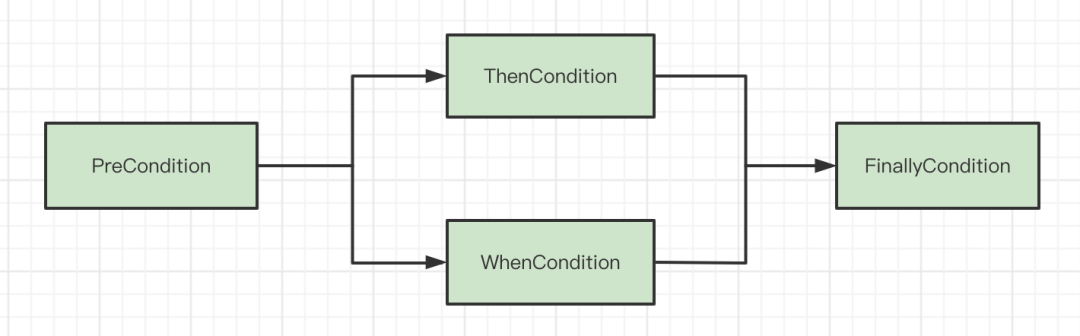
Chain内部其实就是封装了一堆Condition,Chain的执行就是指从不同的Condition中拿出里面的Node来执行,首先会拿出来PreCondition中的Node节点来执行,执行完之后会执行ThenCondition和WhenCondition中的Node节点,最后执行完之后才会执行FinallyCondition中的Node节点。
2)FlowBus
这个组件主要是用来存储上一步骤解析出来的Node和Chain的
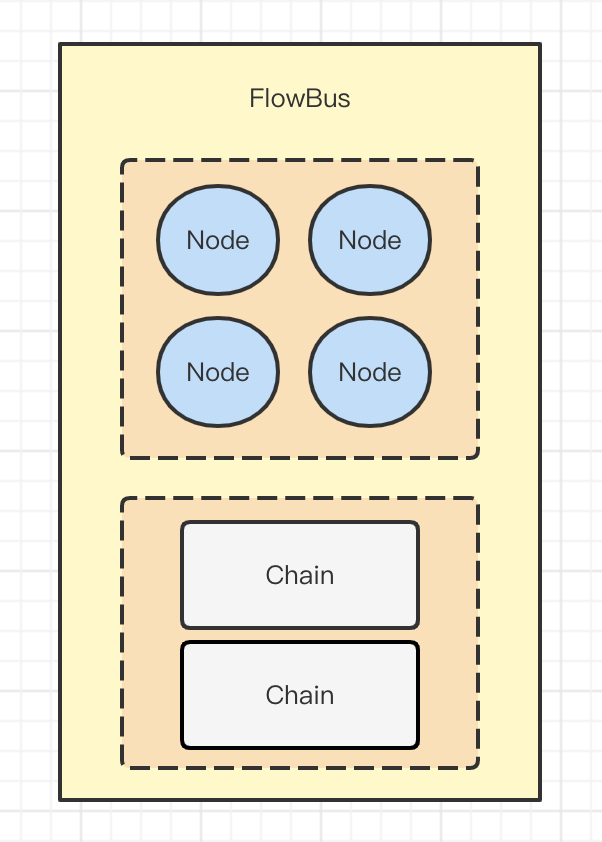
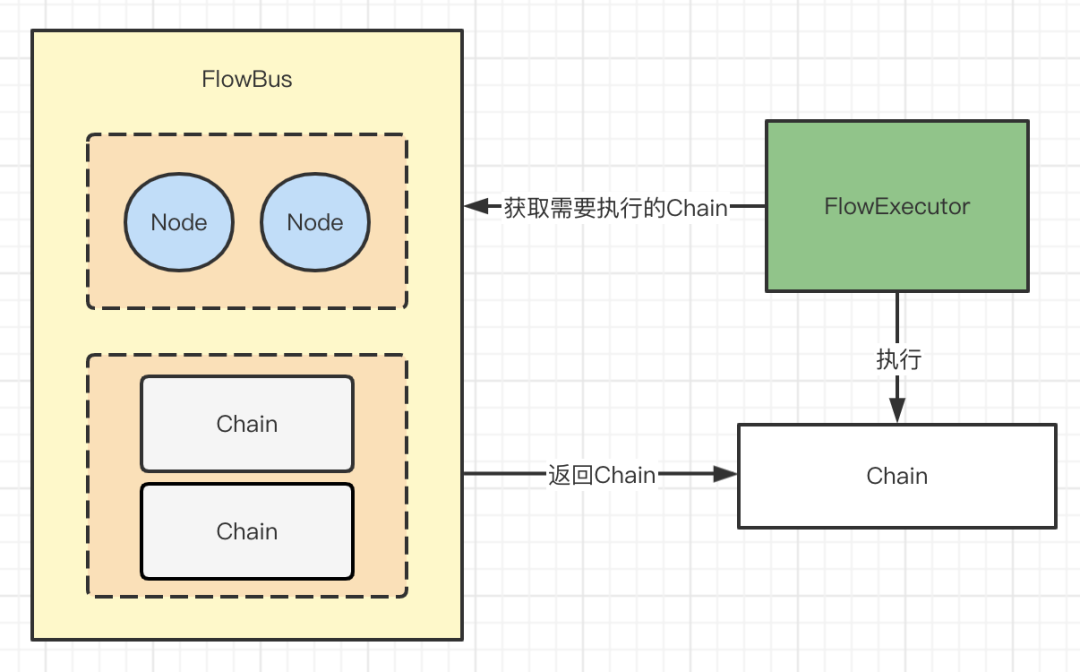
3)FlowExecutor
这个其实是用来执行上面解析出来的业务流程,从FlowBus找到需要执行的业务流程Chain,然后执行Chain,也就是按照Condition的顺序来分别执行每个Condition的Node,也就是业务节点。
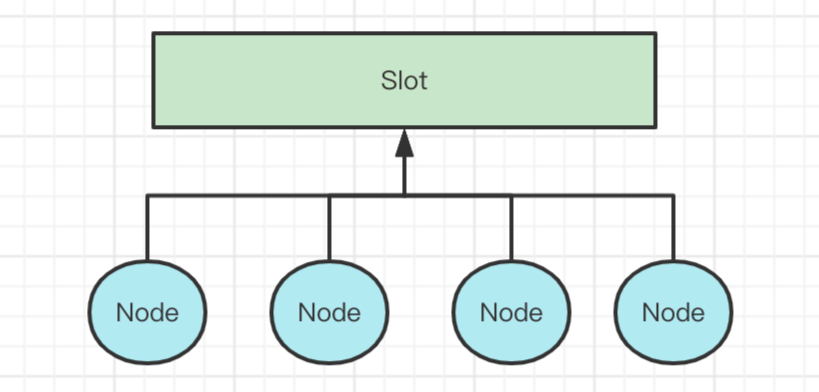
4)Slot
Slot可以理解为业务的上下文,在一个业务流程中,这个Slot是共享的。
Slot有个默认的实现DefaultSlot,DefaultSlot虽然可以用,但是在实际业务中,用这个会存在大量的弱类型,存取数据的时候都要进行强转,颇为不方便。所以官方建议自己去实现自己的Slot,可以继承AbsSlot。
5)DataBus
用来管理Slot的,从这里面可以获取当前业务流程执行的Slot。
四、LiteFlow源码探究
说完核心的组件,接下来就来剖析一下源码,来看一看LiteFlow到底是如何实现规则编排的。
1)FlowExecutor的构造流程
我们这里就以非Spring环境的例子来说,因为在SpringBoot环境底下,FlowExecutor是由Spring创建的,但是创建的过程跟非Spring的例子是一样的。
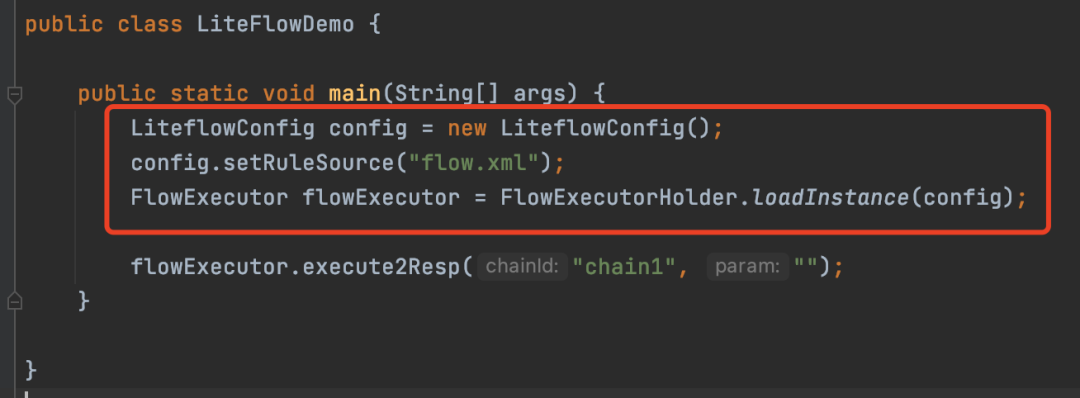
这里在构建FlowExecutor,传入了一个规则的路径flow.xml,也就是ruleSource属性值。
进入loadInstance这个方法,其实就是直接new了一个FlowExecutor。
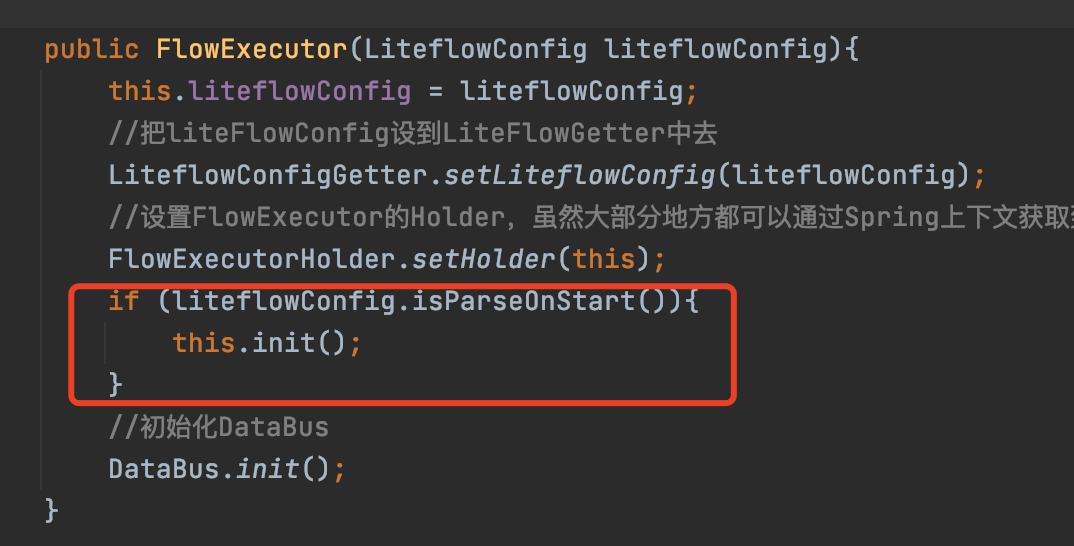
进入FlowExecutor构造方法,前面就是简单的赋值操作。然后调用liteflowConfig.isParseOnStart(),这个方法默认是返回true的,接下来会调用init方法,也就是在启动时,就去解析规则文件,保证运行时的效率。
接下来进入init方法。
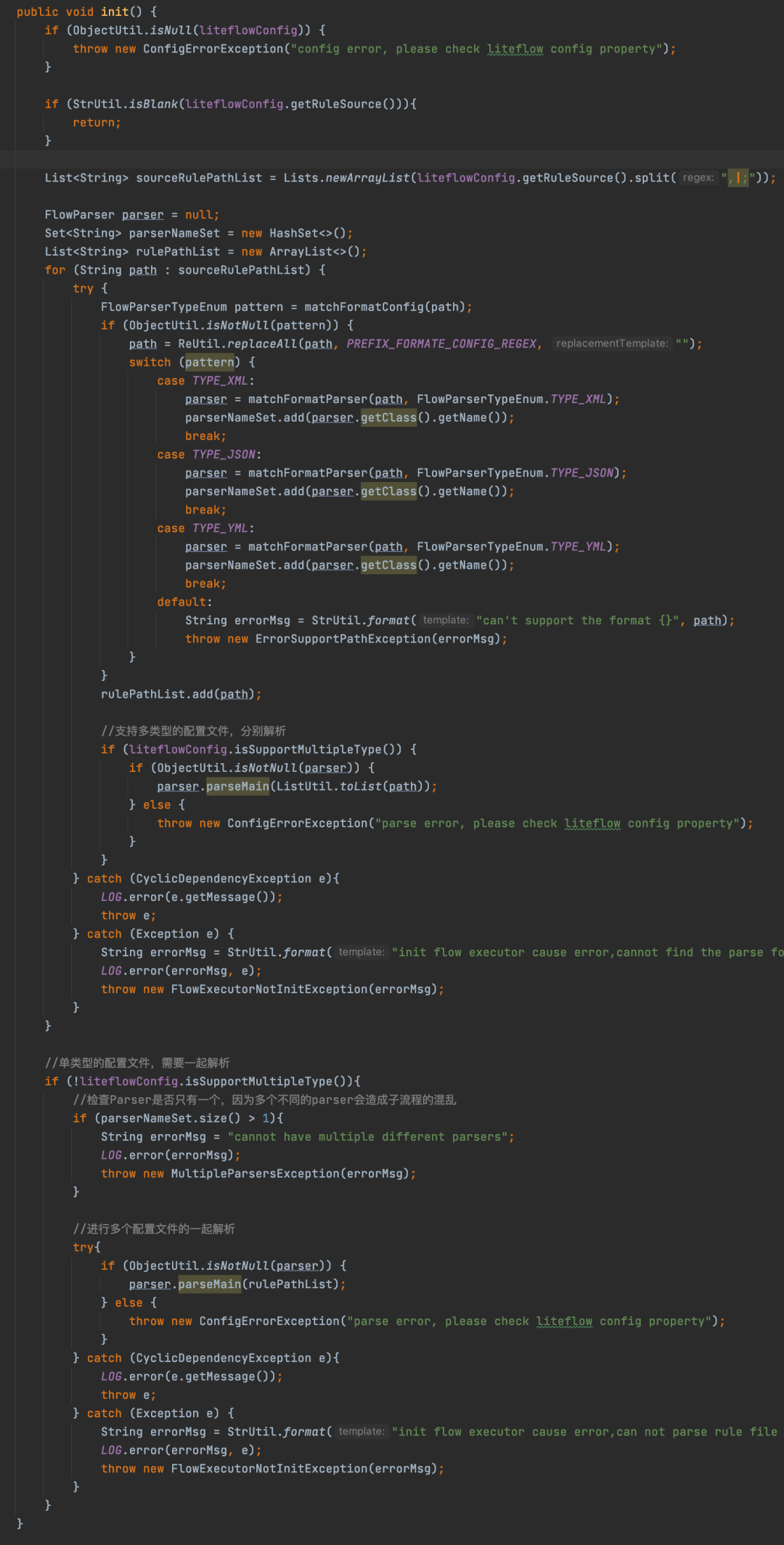
init方法非常长,来一步一步解析
前面就是校验,不用care
List<String> sourceRulePathList = Lists.newArrayList(liteflowConfig.getRuleSource().split(",|;"));这行代码的意思就是将我们传入的规则文件路径进行分割成多个路径,从这可以看出支持配置多个规则的文件。对我们这个demo来说其实就是只有一个,那就是flow.xml。
分割完之后,就会遍历每个路径,然后判断文件的格式,比如xml、json、yaml,然后根据文件格式找到对应的FlowParser。
随后根据liteflowConfig.isSupportMultipleType()判断是不是支持多类型的,什么叫多类型,就是指规则文件配置了多个并且文件的格式不同,如果支持的话,需要每个规则文件单独去解析,如果不支持,那就说明文件的格式一定是相同的,相同可以在最后统一解析,解析是通过调用FlowParser的parseMain来解析的。
剖析完之后整个init方法就会结束,然后继续调用DataBus的init方法,其实就是初始化DataBus。
到这其实构建FlowExecutor就完成了,从上面我们得出一个结论,那就是在构造FlowExecutor的时候会通过FlowParser的parseMain来处理对应规则文件的路径,所以接下来我们分析一下这个FlowParser是如何解析xml的,并且解析了之后干了什么。
2)FlowParser规则解析流程
接下来我们进入FlowParser来看看一个是如何解析规则的。
以本文的例子为例,因为是配置本地的xml文件,找到的FlowParser的实现是LocalXmlFlowParser。

接下会调用parseMain方法,parseMain的方法的实现很简单,首先根据PathContentParserHolder拿到一个PathContentParser来解析路径,对上面案例来说,就是flow.xml路径,拿到路径对应文件的内容,其实就是拿到了flow.xml内容。然后调用父类的parse方法来解析xml的内容,所以parse方法才是解析xml的核心方法。
这里有个细节说一下,PathContentParserHolder其实内部使用了Java的SPI机制来加载PathContentParser的实现,然后解析路径,拿到内容,在Spring环境中默认基于Spring的实现的优先级高点,但是不论是怎么实现,作用都是一样的,那就是拿到路径对应的xml文件的内容,这里就不继续研究PathContentParser是如何加载文件的源码了。
其实不光是PathContentParser,LiteFlow内部使用了很多SPI机制,但是基本上整合Spring的实现的优先级都高于框架本身的实现。
接下来我们就来看一下LocalXmlFlowParser父类中的parse方法的实现。
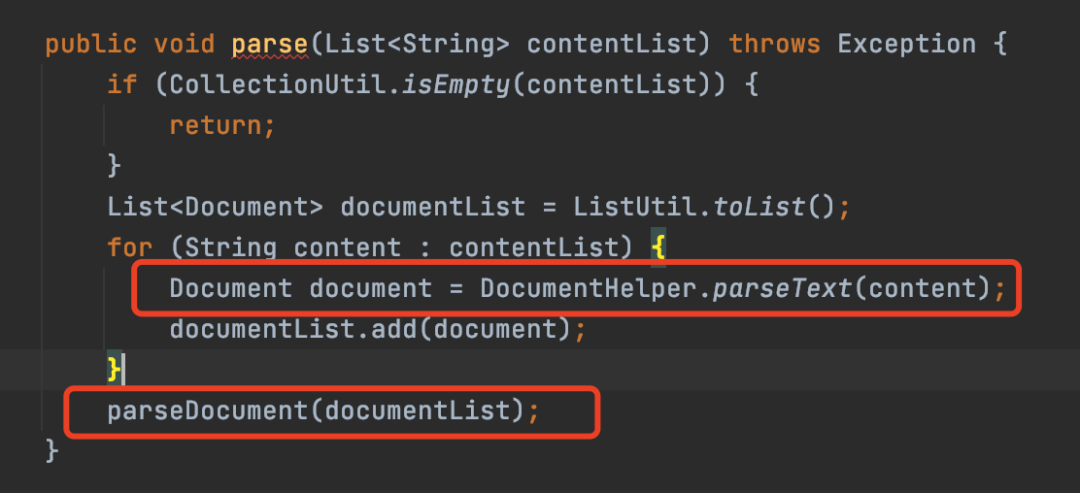
首先遍历每个文件中的内容,然后转成Document,Document其实是dom4j的包,其实就是将xml转成Java对象,这样可以通过Java中的方法来获取xml中每个标签的数据。
将文件都转换成Document之后,调用parseDocument方法。
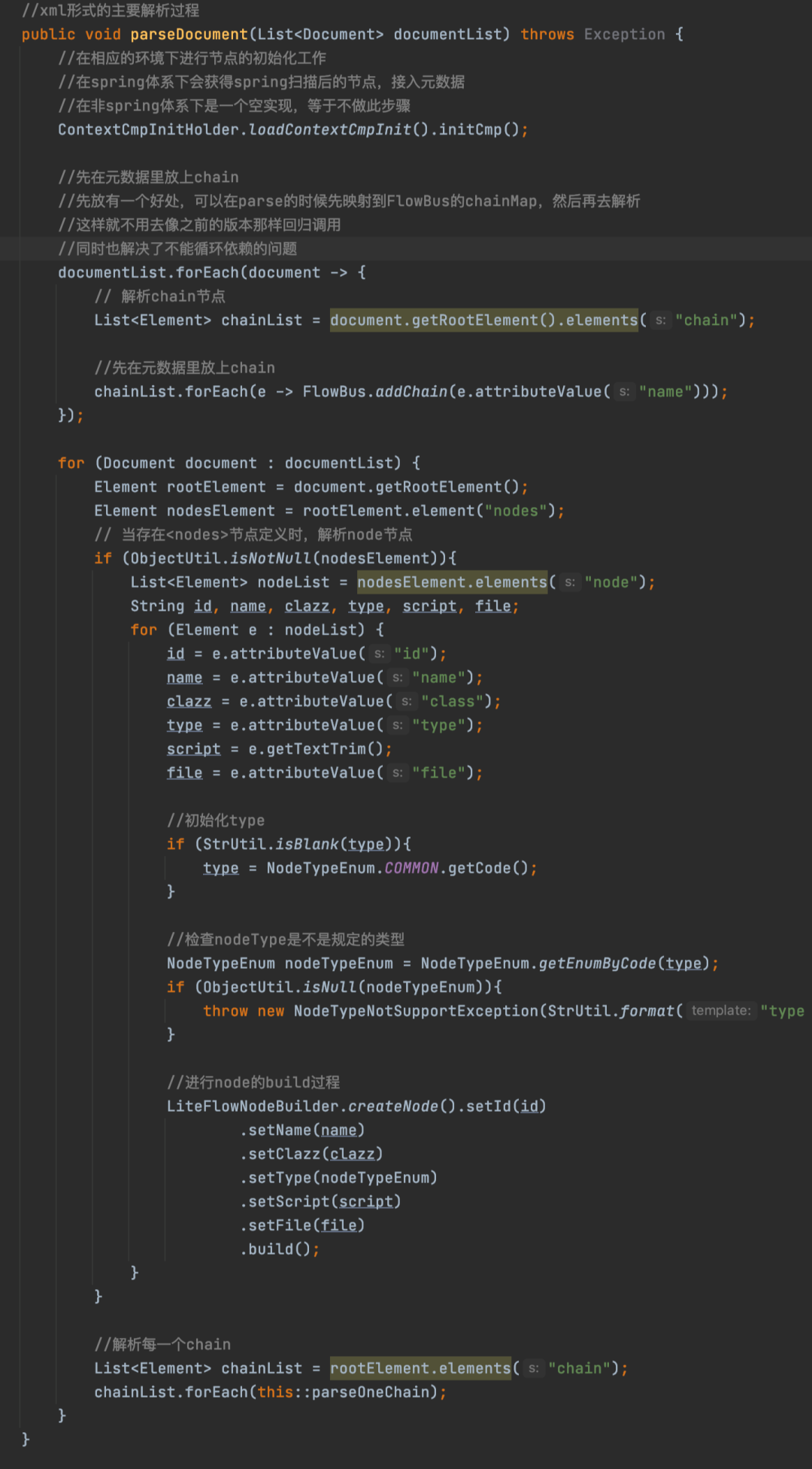
首先调用了ContextCmpInitHolder.loadContextCmpInit().initCmp() ,这行代码也是通过SPI机制来加载ContextCmpInit,调用initCmp方法。框架本身对于initCmp的实现是空实现,但是在Spring环境中,主要是用来整合Spring中的Node节点的,将Node节点添加到FlowBus中,这也是为什么在Spring环境中的那个案例中不需要在xml文件中配置<nodes/>的原因,因为LiteFlow会自动识别这些Node节点的Spring Bean。至于怎么整合Spring的,有兴趣的同学可以看一下ComponentScanner类的实现,主要在Bean初始化之后进行判断的,这里画一张图来总结一下initCmp方法的作用。
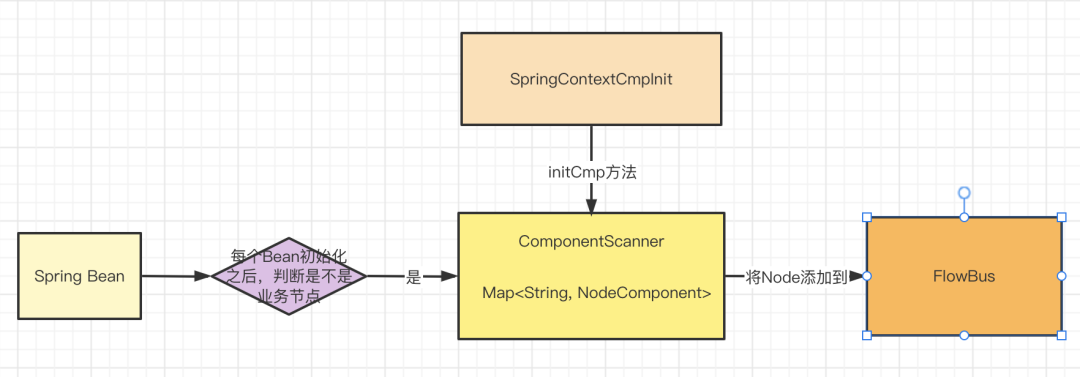
至于为什么需要先将Spring中的Node节点添加到FlowBus,其实很简单,主要是因为构建Chain是需要Node,需要保证构建Chain之前,Spring中的Node节点都已经添加到了FlowBus中。
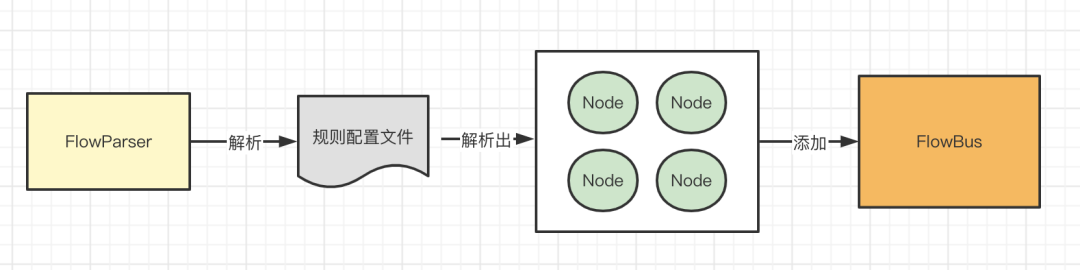
接下来就会继续遍历每个Document,也就是每个xml,然后拿到解析<nodes></nodes>中的每个<node></node>标签,拿出每个node标签中的属性,通过LiteFlowNodeBuilder构建Node,然后放入到FlowBus中,至于如何放入到FlowBus中,可以看一下LiteFlowNodeBuilder的build方法的实现。
解析完Node之后,接下来就是解析<chain/>标签,拿到每一个<chain/>标签对应的Element之后,调用parseOneChain来解析<chain/>标签的内容。
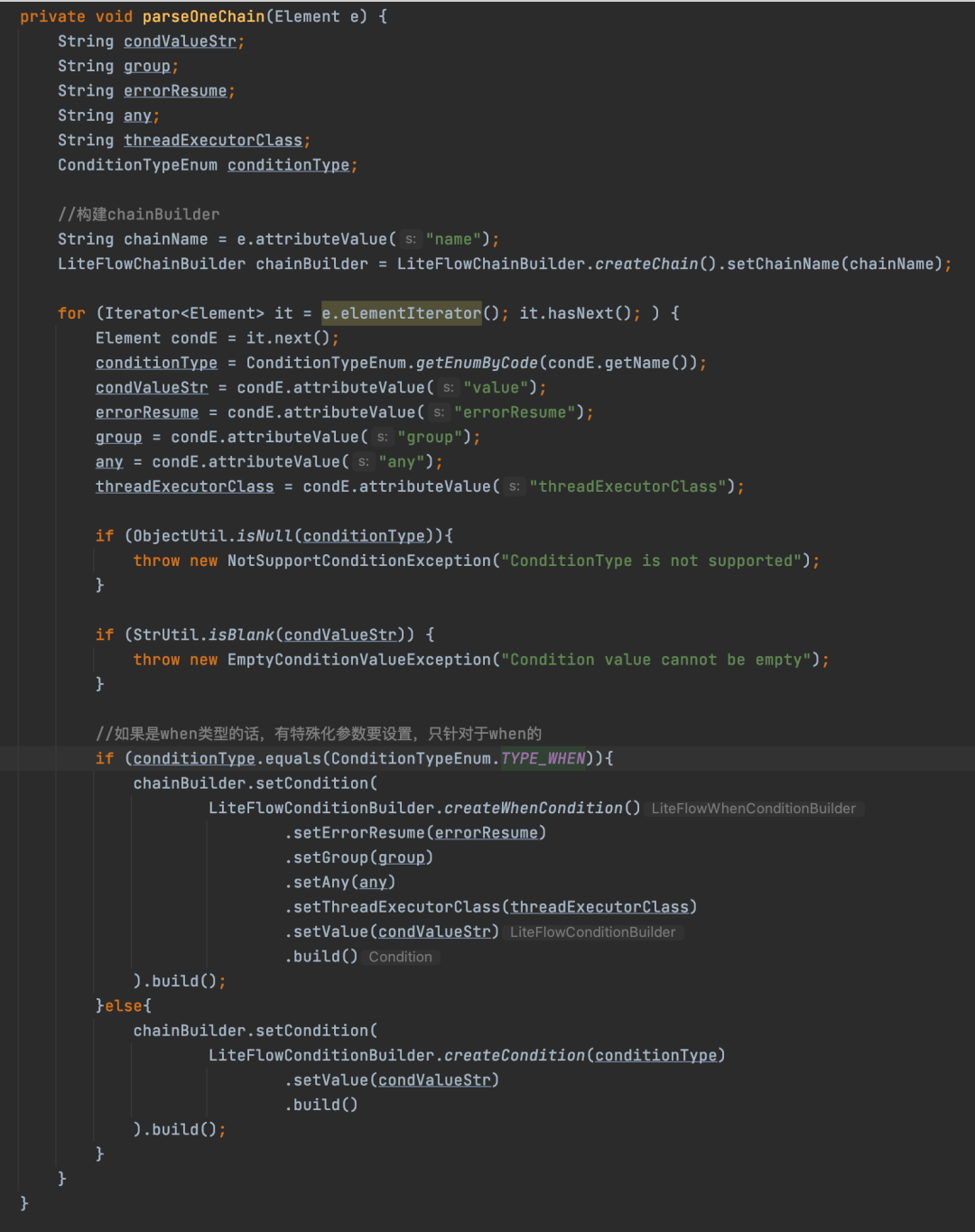
parseOneChain方法,先拿到<chain/>底下所有的标签,然后判断标签类型,标签的类型主要有四种类型:then、when、pre、finally,然后拿到每个标签的值,构建对应的Condition,就是上文提到的ThenCondition、WhenCondition、PreCondition、FinallyCondition,然后加入到Chain中,至于如何将Node设置到Condition中,主要是通过LiteFlowConditionBuilder的setValue方法来实现的,setValue这个方式设置的值是条件标签的value属性值,然后解析value属性值,然后从FlowBus中clone一个新的Node,加入到Condition中,至于为什么需要clone一下新的Node,因为同一个业务节点,可能在不同的执行链中,为了保证不同业务中的同一个业务节点不相互干扰,所以得重新clone一个新的Node对象。
构建好Condition之后,都设置到了对应的Chain中,最后将Chain添加到FlowBus中。
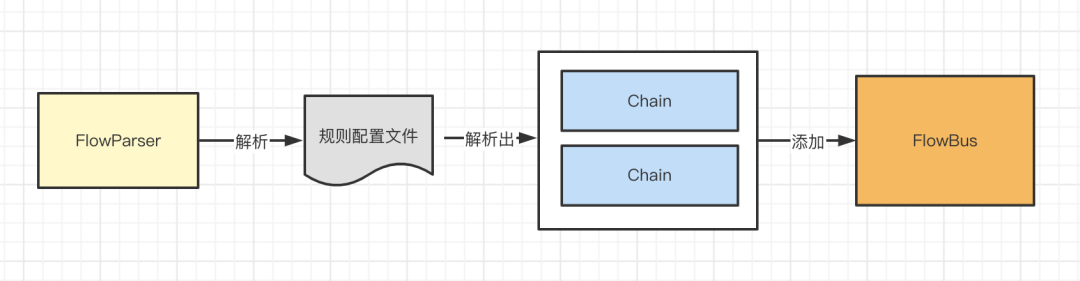
到这里,其实整个xml就解析完了,FlowParser的最主要的作用就是解析xml,根据配置构建Node、Condition和Chain对象,有了这些基础的组件之后,后面才能运行业务流程。其实从这里也可以看出是如何流程编排的,其实就是根据配置,将一个个Node添加到Condition中,Condition再添加到Chain中,这样相同的业务节点,可能分布在不同的Chain中,这样就实现了业务代码的复用和流程的编排。
3)Chain的执行流程
剖析完FlowParser的作用,也就是Node和Chain的构造流程之后,接下来看一下Chain是如何执行的。
流程执行是通过FlowExecutor来执行的,FlowExecutor执行的方法很多,我们以上面demo调用的execute2Resp为例,最终会走到如下图的重载方法。
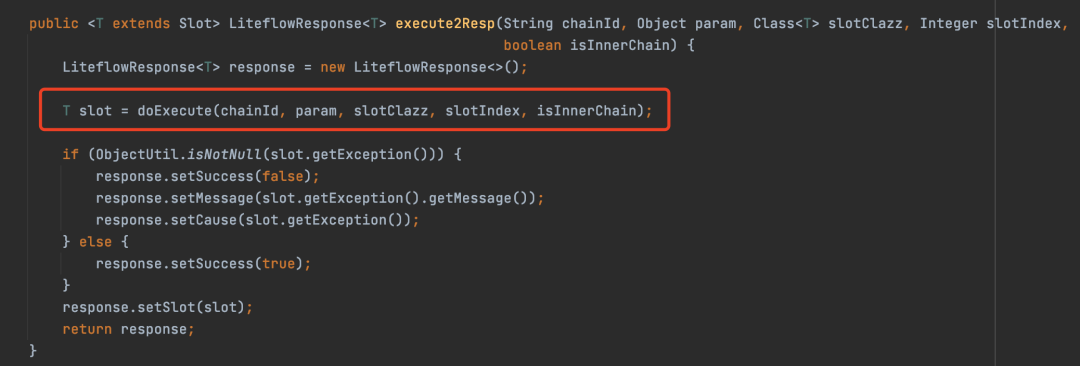
execute2Resp方法就会调用doExecute方法的实现,然后拿到Slot,封装成一个LiteflowResponse返回回去,所以从这里可以看出,doExecute是核心方法。
接下来看看doExecute方法的实现。
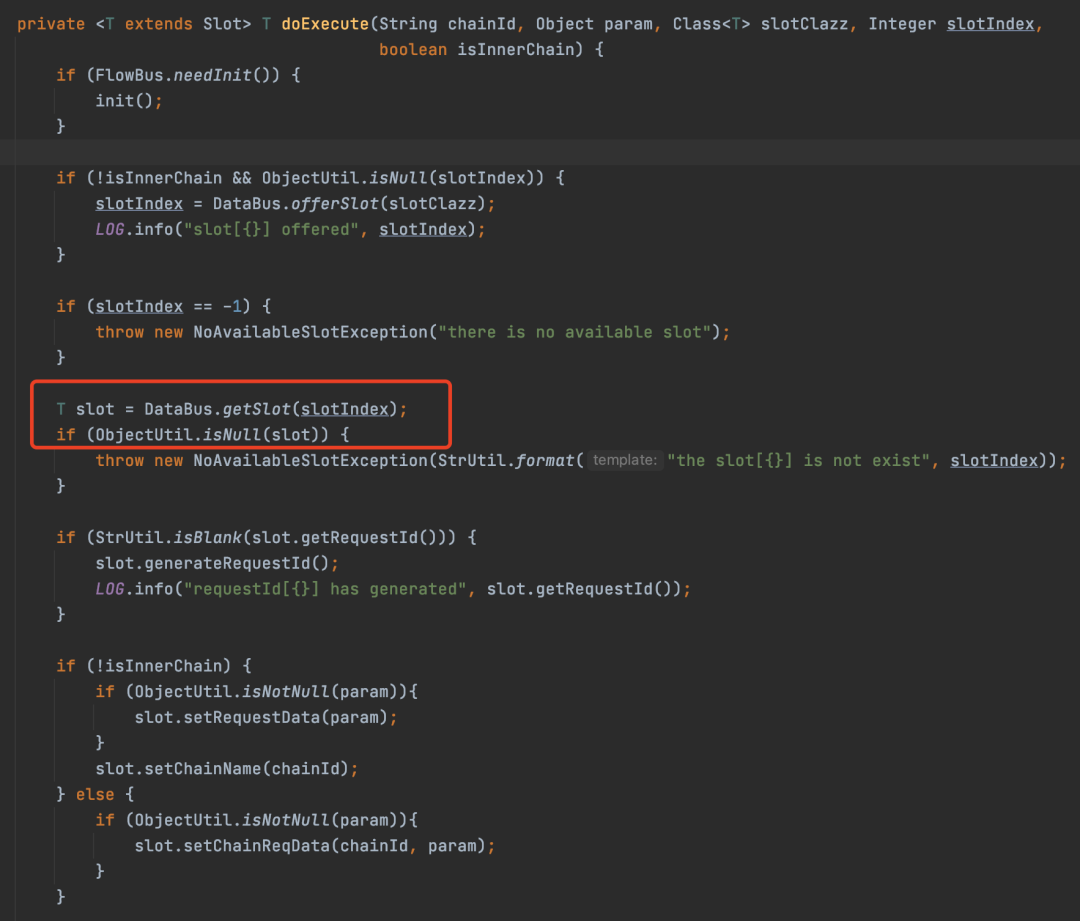
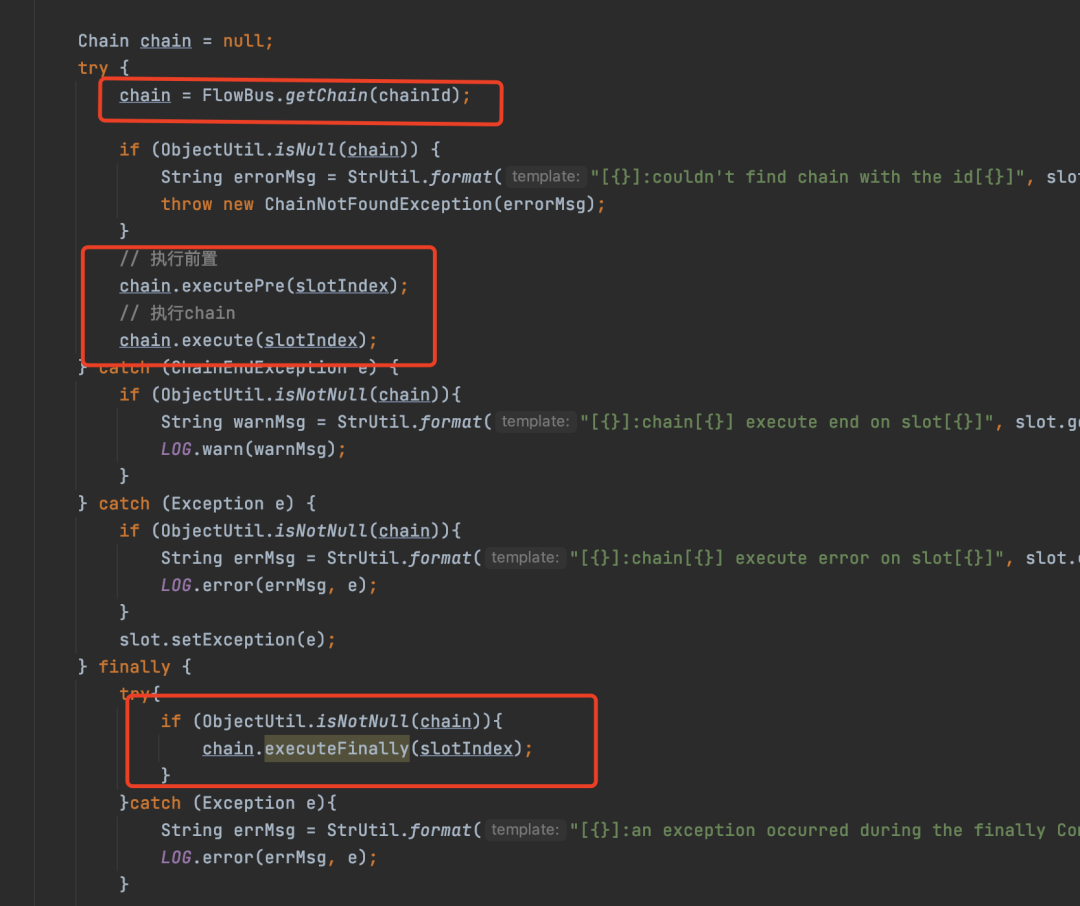
doExecute方法比较长,我截了两张图
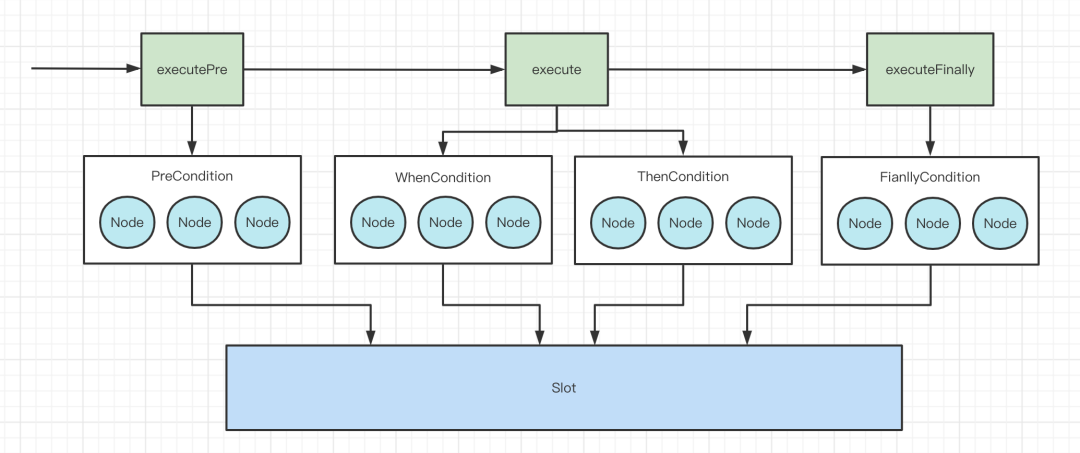
首先从DataBus中获取一个Slot,也就是当前业务执行的上下文。之后从FlowBus中获取需要执行的Chain,最后分别调用了Chain的executePre、execute、executeFinally方法,其实不用看也知道这些方法干了什么,其实就是调用不同的Condition中Node方法。
executePre和executeFinally方法
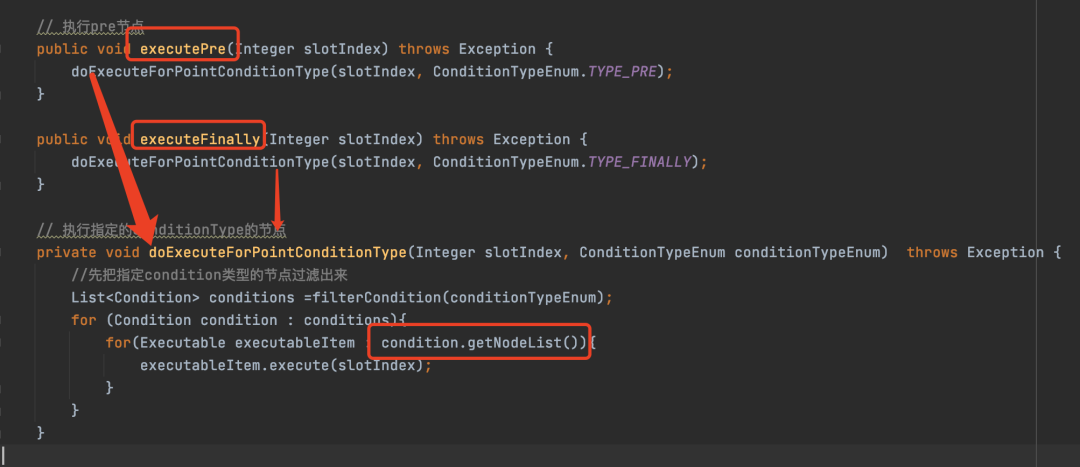
这两个方法最后调用的是同一个方法,就是分别找到PreCondition和FinallyCondition,取出里面的Node节点,执行excute方法。
这里有重点说明一下,其实在Condition中存的不是直接的Node,而是Executable,Executable的有两个实现,一个就是我们所说的Node,还有一个就是我们一直说的Chain,为了方便大家理解,我一直说的是Node,其实这里的Executable是有可能为Chain的,取决于规则的配置。当是一个Chain的时候,其实就是一个嵌套的子流程,也就是在一个流程中嵌套另一个流程的意思,大家注意一下就行了,其实不论怎么嵌套,流程执行到最后一定是Node,因为如果是Chain,那么还会继续执行,不会停止,只有最后一个流程的Executable都是Node的时候流程才能执行完。
executePre和executeFinally方法说完之后,看一看execute方法的实现。

execute方法主要是判断Condition的类型,然后判断是ThenCondition还是WhenCondition,ThenCondition的话其实也就是拿出Node直接执行,如果是WhenCondition的话,其实就是并行执行每个Node节点。这也是ThenCondition和WhenCondition的主要区别。
画图总结一下Chain的执行流程
4)Node的执行流程
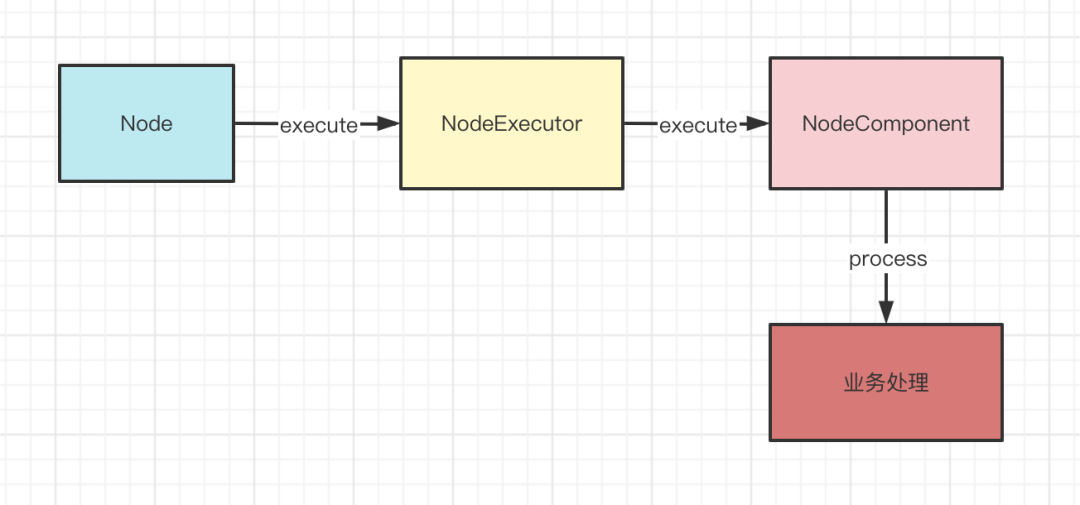
从上面我们可以看出,Chain的执行其实最终都是交给Node来执行的,只不过是不同阶段调用不同的Node而已,其实最终也就是会调用Node的execute方法,所以我们就来着重看一下Node的execute方法。
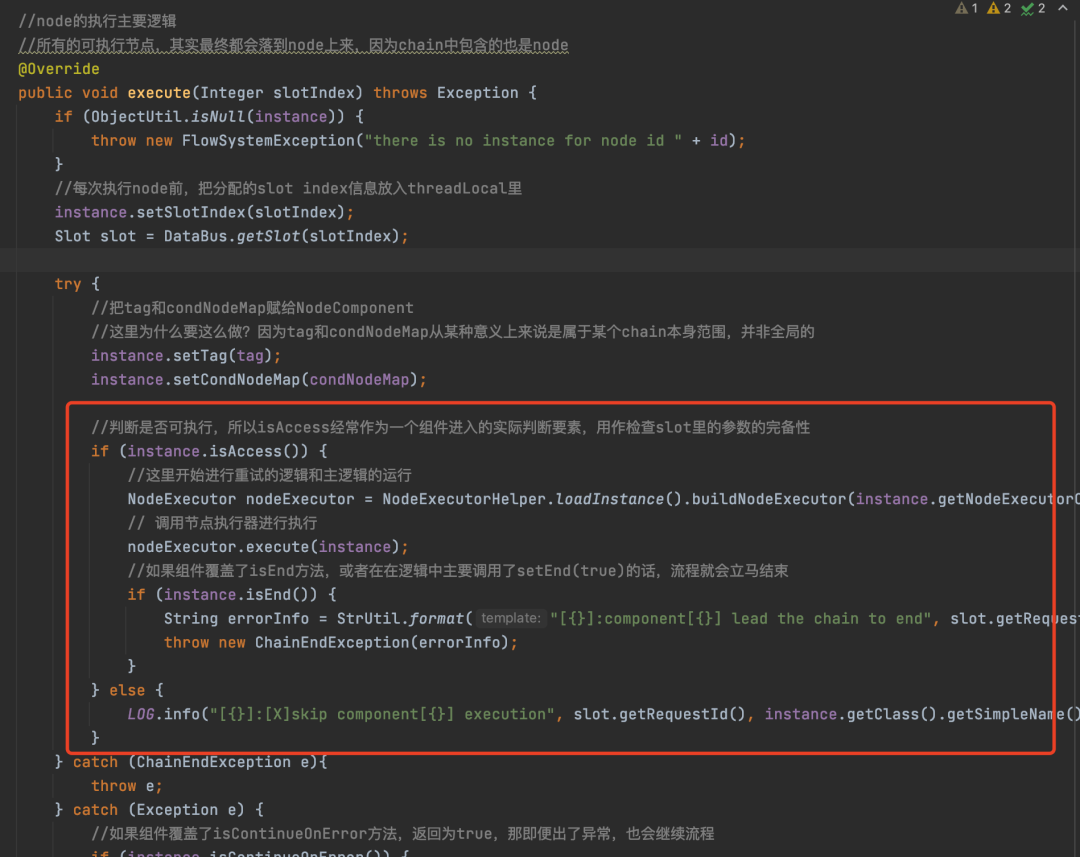
instance就是NodeComponent对象,也就是我们自定义实现的节点对象,好家伙,终于要执行到业务了。有人可能好奇NodeComponent是如何设置到Node对象中的,其实就是在往FlowBus添加Node的时候设置的,不清楚的小伙伴可以翻一下那块相关的源码,在解析xml那块我有说过。
先调用NodeComponent的isAccess方法来判断业务要不要执行,默认是true,你可以重写这个方法,自己根据其它节点执行的情况来判断当前业务的节点要不要执行,因为Slot是公共的,每个业务节点的执行结果可以放在Slot中。
随后通过这个方法获取了NodeExecutor,NodeExecutor可以通过execute方法来执行NodeComponent的,也就是来执行业务的,NodeExecutor默认是使用DefaultNodeExecutor子类的,当然你也可以自定义NodeExecutor来执行NodeComponent
NodeExecutor nodeExecutor = NodeExecutorHelper.loadInstance().buildNodeExecutor(instance.getNodeExecutorClass());DefaultNodeExecutor的execute方法也是直接调用父类NodeExecutor的execute方法,接下来我们来看一下NodeExecutor的execute方法。
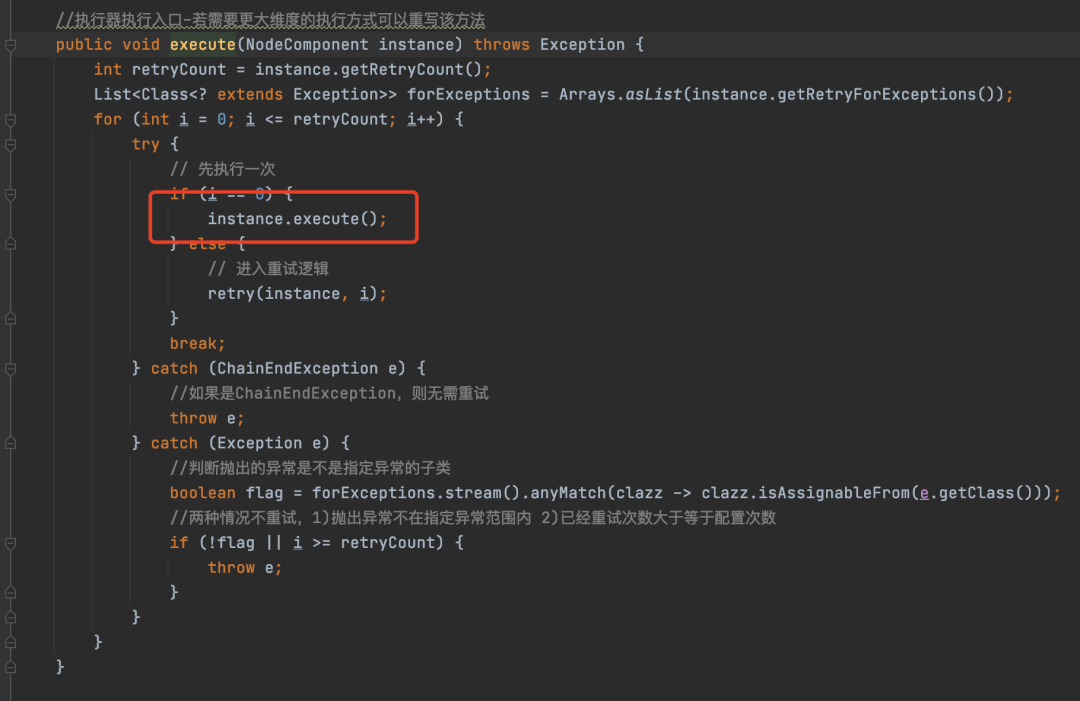
从这个方法的实现我们可以看出,LiteFlow对于业务的执行是支持重试功能的,但是不论怎么重试,最终一定调用的是NodeComponent的execute方法。
进入NodeComponent的execute方法
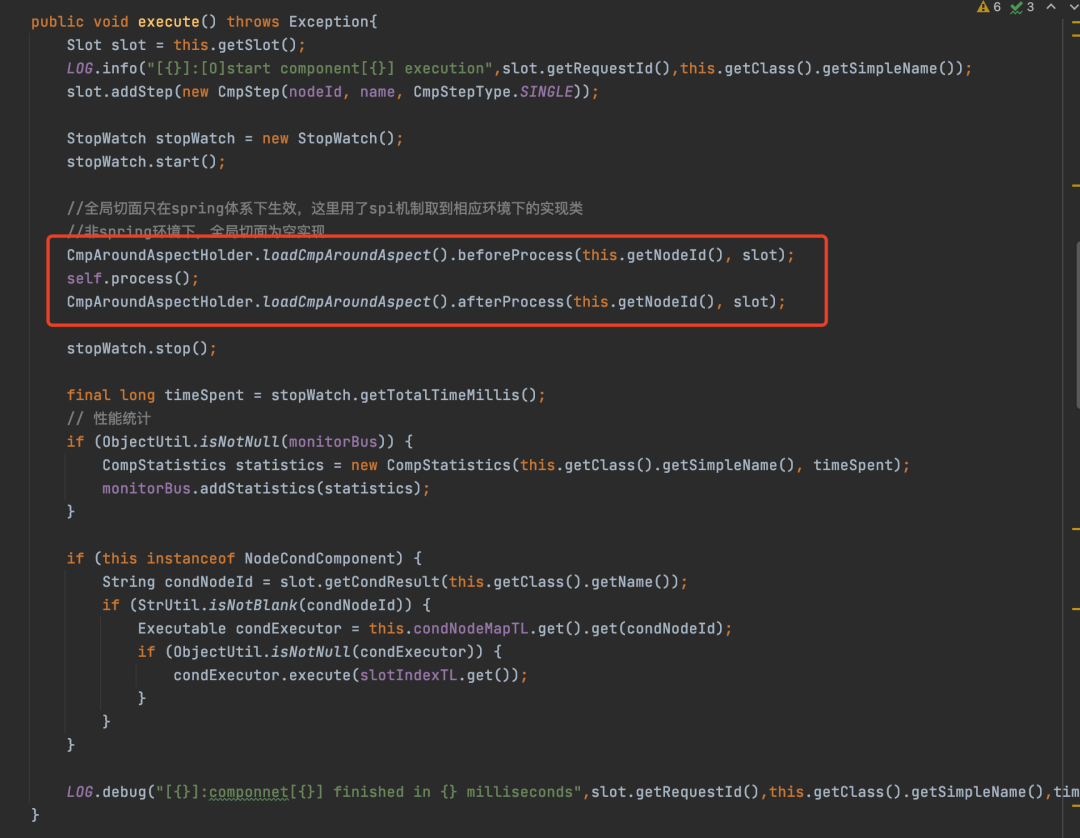
红框圈出来的,就是核心代码,self是一个变量,指的是当前这个NodeComponent对象,所以就直接调用当前这个NodeComponent的process方法,也就是用来执行业务的方法。
在执行NodeComponent的process方法前后其实有回调的,也就是可以实现拦截的效果,在Spring环境中会生效。
至于这里为什么要使用self变量而不是直接使用this,其实源码也有注释,简单点说就是如果process方法被动态代理了,那么直接使用this的话,动态代理会不生效,所以为了防止动态代理不生效,就单独使用了self变量来引用自己。至于为什么不生效,这是属于Spring的范畴了,这里就不过多赘述了。
其实到这里,一个Node就执行完成了,Node的执行其实就是在执行NodeComponent,而NodeComponent其实最终是交给NodeExecutor来执行的。
每个Condition中的Node执行完之后,就将Slot返回,这样就能在调用方就能通过Slot拿到整个流程的执行结果了。
到这里,其实核心流程源码剖析就完成了,总的来说就是将规则配置文件翻译成代码,生成Node和Chain,然后通过调用Chain来执行业务流程,最终其实就是执行我们实现的NodeComponent的process方法。
最终画一张图来总结整个核心源码。
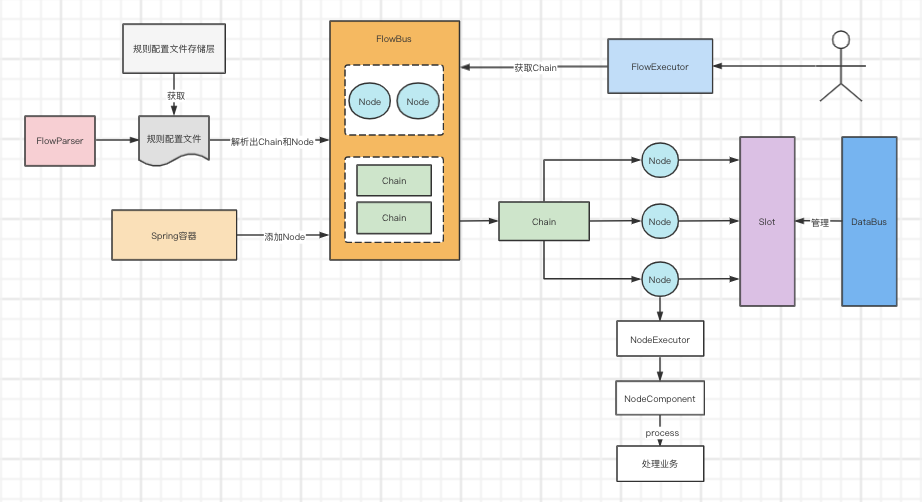
图中我省略了Condition的示意图,因为Condition其实最终也是执行Node的。