一、背景
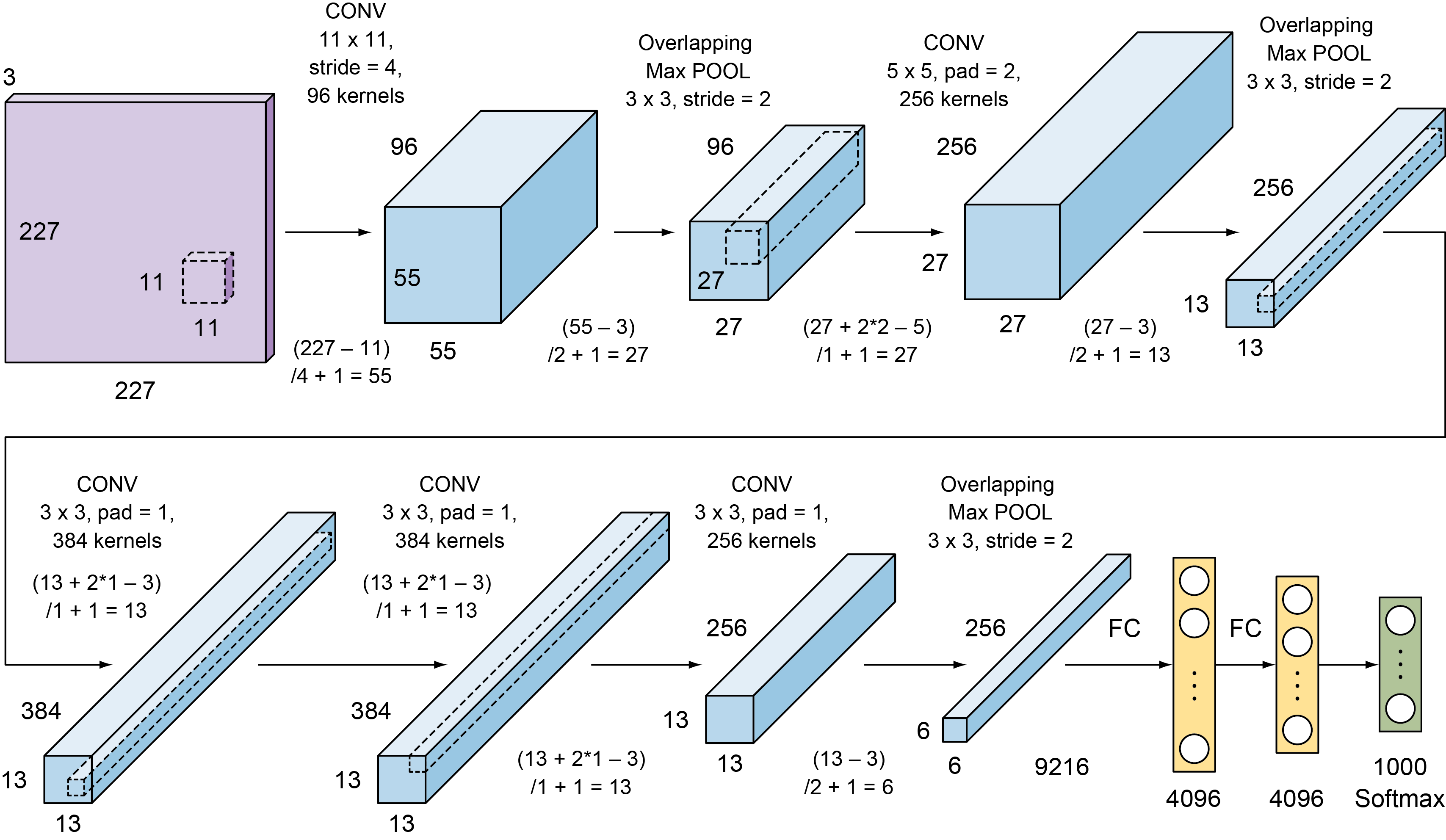
AlexNet是在2012年由Alex Krizhevsky等人提出的,该网络在2012年的ImageNet大赛上夺得了冠军,并且错误率比第二名高了很多。Alexnet共有8层结构,前5层为卷积层,后三层为全连接层。
论文地址:ImageNet Classification with Deep Convolutional Neural Networks
二、创新点
1、使用大型深度卷积神经网络
作者使用了一个大型深度卷积神经网络,在ImageNet数据集上取得了非常好的结果。说明大型网络对模型的效果影响比较大,这也是为什么现在大家都在做大模型的原因。
2、ReLU激活函数
该论文推广了使用整流线型单元(ReLC)激活函数,这有助于训练更深的网络,而不会出现梯度消失的问题。
3、局部响应一体化(LRN)的使用
4、数据增强
为了减少过拟合,作者采用数据增强的方法。通过对训练图像进行平移、翻转等操作来扩充训练集,从而增强了训练样本的多样性。
5、Dropout技术
为了进一步减少过拟合,作者采用了dropout技术。在训练过程中,以一定概率将隐藏层神经元的输出置为零。
可以看出,这篇文章发表在2012年,已经是很久以前,但是这篇文章用到的Relu函数,Dropout技术到目前还是广泛使用的。
三、AlexNet使用PyTorch框架实现
from torch import nn
class AlexNet(nn.Module):
def __init__(self,class_num):
super(AlexNet,self).__init__()
self.class_num = class_num
# input(N,3,224,224)
self.net = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=96,kernel_size=11,stride=4,padding_mode='zeros'),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5,alpha=1e-4,beta=0.75,k=2),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,stride=1,padding_mode='zeros'),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5,alpha=1e-4,beta=0.75,k=2),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding_mode='zeros'),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding_mode='zeros'),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding_mode='zeros'),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=1,stride=2)
)
self.fully_connected=nn.Sequential(
nn.Linear(in_features=256*6*6,out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096,out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096,out_features=self.class_num)
)
self.init_bias()
def init_bias(self):
for layer in self.net:
if isinstance(layer,nn.Conv2d):
nn.init.normal_(layer.weight,mean=0,std=0.01)
nn.init.constant_(layer.bias,0)
nn.init.constant_(self.net[4].bias,1)
nn.init.constant_(self.net[10].bias,1)
nn.init.constant_(self.net[12].bias,1)
nn.init.constant_(self.fully_connected[0].bias,1)
nn.init.constant_(self.fully_connected[3].bias,1)
def forward(self,x):
x = self.net(x)
x = x.view(-1,256*6*6)
x = self.fully_connected(x)
return x
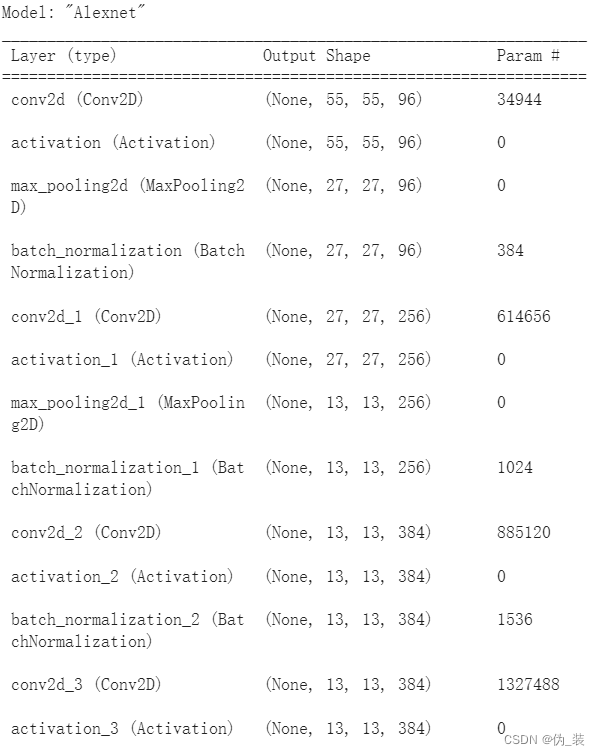
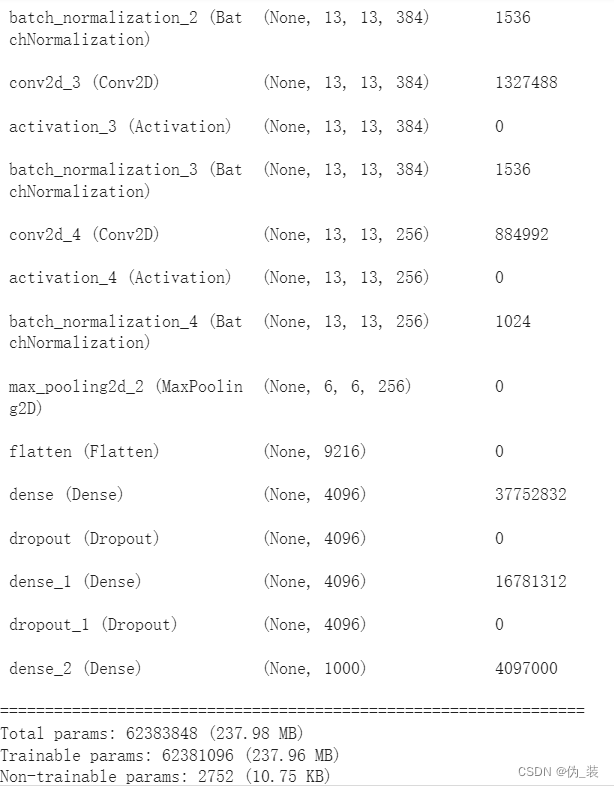
四、AlexNet使用keras框架实现
from keras.models import Sequential
from keras.layers import Conv2D, AveragePooling2D, Flatten, Dense,Activation,MaxPool2D, BatchNormalization, Dropout
from keras.regularizers import l2# 实例化一个空的顺序模型
model = Sequential(name="Alexnet")
# 1st layer (conv + pool + batchnorm)
model.add(Conv2D(filters= 96, kernel_size= (11,11), strides=(4,4), padding='valid', kernel_regularizer=l2(0.0005),
input_shape = (227,227,3)))
model.add(Activation('relu')) #<---- activation function can be added on its own layer or within the Conv2D function
model.add(MaxPool2D(pool_size=(3,3), strides= (2,2), padding='valid'))
model.add(BatchNormalization())
# 2nd layer (conv + pool + batchnorm)
model.add(Conv2D(filters=256, kernel_size=(5,5), strides=(1,1), padding='same', kernel_regularizer=l2(0.0005)))
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(3,3), strides=(2,2), padding='valid'))
model.add(BatchNormalization())
# layer 3 (conv + batchnorm) <--- note that the authors did not add a POOL layer here
model.add(Conv2D(filters=384, kernel_size=(3,3), strides=(1,1), padding='same', kernel_regularizer=l2(0.0005)))
model.add(Activation('relu'))
model.add(BatchNormalization())
# layer 4 (conv + batchnorm) <--- similar to layer 3
model.add(Conv2D(filters=384, kernel_size=(3,3), strides=(1,1), padding='same', kernel_regularizer=l2(0.0005)))
model.add(Activation('relu'))
model.add(BatchNormalization())
# layer 5 (conv + batchnorm)
model.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), padding='same', kernel_regularizer=l2(0.0005)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(3,3), strides=(2,2), padding='valid'))
# 平铺 CNN 输出,为其提供完全连接的层
model.add(Flatten())
# layer 6 (Dense layer + dropout)
model.add(Dense(units = 4096, activation = 'relu'))
model.add(Dropout(0.5))
# layer 7 (Dense layers)
model.add(Dense(units = 4096, activation = 'relu'))
model.add(Dropout(0.5))
# layer 8 (softmax output layer)
model.add(Dense(units = 1000, activation = 'softmax'))
# 打印模型摘要
model.summary()