Batch Norm(批归一化) 是现代深度学习实践者工具包的重要组成部分。 在批归一化论文中引入它后不久,它就被认为在创建可以更快训练的更深层次神经网络方面具有变革性。
Batch Norm 是一种神经网络层,现在在许多架构中普遍使用。 它通常作为线性或卷积块的一部分添加,并有助于在训练期间稳定网络。
在本文中,我们将探讨什么是 Batch Norm、为什么需要它以及它是如何工作的。
但在我们讨论批归一化本身之前,让我们先了解一些有关归一化的背景知识。
NSDT在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、归一化输入数据
将数据输入深度学习模型时,标准做法是将数据归一化为零均值和单位方差。 这意味着什么?我们为什么要这样做?
假设输入数据由多个特征 x1、x2、…xn 组成。 每个特征可能有不同的值范围。 例如,特征 x1 的值可能在 1 到 5 之间,而特征 x2 的值可能在 1000 到 99999 之间。
因此,对于每个特征列,我们分别获取数据集中所有样本的值并计算平均值和方差。 然后使用下面的公式对值进行标准化。

如何归一化
下图中,我们可以看到数据归一化后的效果。 原始值(蓝色)现在以零(红色)为中心。 这确保了所有特征值现在都处于相同的比例。

归一化数据是什么样的
为了了解没有对数据归一化处理时会发生什么,让我们看一个只有两个尺度截然不同的特征的示例。 由于网络输出是每个特征向量的线性组合,这意味着网络学习每个特征的权重,这些特征也在不同的尺度上。 否则,大特征就会淹没小特征。
然后,在梯度下降期间,为了“改变损失”,网络必须对一个权重(与另一个权重相比)进行较大的更新。 这可能会导致梯度下降轨迹沿一维来回振荡,从而需要更多步骤才能达到最小值。
不同尺度的特征需要更长的时间才能达到最小值
在这种情况下,损失景观看起来就像一条狭窄的峡谷。 我们可以沿二维分解梯度。 它沿着一个维度陡峭,而沿着另一个维度则平缓得多。
由于梯度很大,我们最终对一个权重进行了更大的更新。 这会导致梯度下降反弹到斜坡的另一侧。 另一方面,沿第二方向的较小梯度导致我们进行较小的权重更新,从而采取较小的步长。 这种不均匀的轨迹需要更长的时间才能使网络收敛。

狭窄的山谷会导致梯度下降从一个斜坡反弹到另一个斜坡
相反,如果特征具有相同的尺度,则损失景观会像碗一样更加均匀。 然后梯度下降可以平滑地下降到最小值。
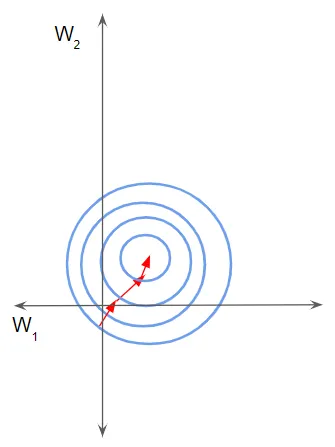
归一化数据有助于网络更快收敛
2、批归一化的必要性
现在我们了解了归一化是什么,需要批归一化的原因开始变得清晰。
考虑网络的任何隐藏层。 前一层的激活只是该层的输入。 例如,从下图中第 2 层的角度来看,如果我们“空白”所有先前的层,则来自第 1 层的激活与原始输入没有什么不同。
要求我们归一化第一层输入的相同逻辑也适用于每个隐藏层:

每个隐藏层的输入是前一层的激活,并且还必须进行归一化
换句话说,如果我们能够以某种方式对前一层的激活进行归一化,那么梯度下降在训练过程中就会更好地收敛。 这正是 Batch Norm 层为我们所做的事情。
3、批归一化如何工作?
批归一化只是插入隐藏层和下一个隐藏层之间的另一个网络层。 它的工作是获取第一个隐藏层的输出并对其进行标准化,然后将其作为下一个隐藏层的输入传递。
Batch Norm 层在到达第 2 层之前对来自第 1 层的激活进行归一化
就像任何网络层的参数(例如权重、偏差)一样,Batch Norm 层也有自己的参数:
- 两个可学习的参数称为 beta 和 gamma。
- 两个不可学习的参数(均值移动平均线和方差移动平均线)被保存为 Batch Norm 层“状态”的一部分。

Batch Norm 层的参数
这些参数针对每个 Batch Norm 层。 因此,如果我们在网络中有三个隐藏层和三个 Batch Norm 层,那么这三个层就会有三个可学习的 beta 和 gamma 参数。 移动平均线参数也类似。

每个 Batch Norm 层都有自己的参数副本
在训练期间,我们一次向网络提供一小批数据。 在前向传递期间,网络的每一层都会处理该小批量数据。 Batch Norm 层按如下方式处理其数据:

Batch Norm 层执行的计算
- 激活
前一层的激活作为输入传递给 Batch Norm。 数据中的每个特征都有一个激活向量。
- 计算均值和方差
分别对于每个激活向量,计算小批量中所有值的均值和方差。
- 归一化
使用相应的均值和方差计算每个激活特征向量的归一化值。 这些标准化值现在均值和单位方差为零。
- 缩放和移位
这一步是 Batch Norm 引入的巨大创新,赋予了它强大的力量。 与输入层要求所有归一化值具有零均值和单位方差不同,Batch Norm 允许其值移动(到不同的均值)和缩放(到不同的方差)。 它通过将归一化值乘以系数 gamma 并添加系数 beta 来实现此目的。 请注意,这是逐元素乘法,而不是矩阵乘法。
缩放和移位这项创新的巧妙之处在于,这些因素不是超参数(即模型设计者提供的常量),而是由网络学习的可训练参数。 换句话说,每个 Batch Norm 层都能够最佳地找到适合自身的最佳因子,从而可以移动和缩放归一化值以获得最佳预测。
- 滑动平均
此外,Batch Norm 还保留均值和方差的指数滑动平均 (EMA:Exponential Moving Average) 的运行计数。 在训练期间,它只是计算 EMA,但不会对其执行任何操作。 在训练结束时,它只是将该值保存为层状态的一部分,以供在推理阶段使用。
稍后当我们讨论推理时,我们将回到这一点。 移动平均线计算使用标量“动量”,用下面的 alpha 表示。 这是一个仅用于 Batch Norm 移动平均值的超参数,不应与优化器中使用的动量混淆。
- 矢量形状
下面,我们可以看到这些向量的形状。 计算特定特征的向量所涉及的值也以红色突出显示。 但是,请记住,所有特征向量都是在单个矩阵运算中计算的。

批归一化向量的形状
在前向传播之后,我们照常进行反向传播。 计算梯度并更新所有层权重以及 Batch Norm 层中的所有 beta 和 gamma 参数。
4、推理过程中的批归一化
正如我们上面所讨论的,在训练期间,Batch Norm 首先计算小批量的均值和方差。 然而,在推理过程中,我们只有一个样本,而不是一个批。 在这种情况下我们如何获得均值和方差?
这就是两个滑动平均参数的用武之地—我们在训练期间计算并与模型一起保存的参数。 我们在推理过程中使用这些保存的平均值和方差值进行批归一化:

推理过程中的批归一化计算
理想情况下,在训练期间,我们可以计算并保存完整数据的均值和方差。 但这会非常昂贵,因为我们必须在训练期间将完整数据集的值保留在内存中。 相反,移动平均可以很好地代表数据的均值和方差。 它的效率要高得多,因为计算是增量的—我们只需记住最近的移动平均值。
5、Batch Norm 层的放置顺序
对于 Batch Norm 层应放置在架构中的位置有两种意见 - 激活之前和之后。 原始论文将其放在前面,尽管我认为你会发现文献中经常提到这两个选项。 有人说“之后”效果更好。
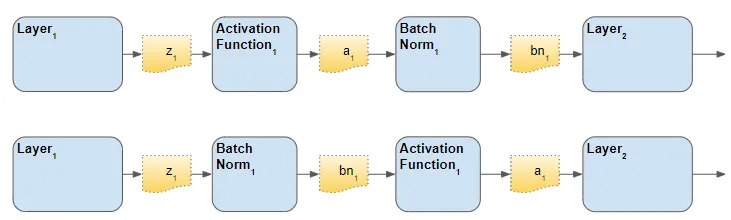
Batch Norm 可以在激活之前或之后使用
6、结束语
Batch Norm 是一个非常有用的层,你最终将在网络架构中经常使用它。 希望这篇文章能帮助你很好地理解批归一化的工作原理。
原文链接:批归一化图解 - BimAnt