借助于在 AutoDev 与 IDE 上的 AI 沉浸式体验设计,我们开始构建一个 AI 原生的文本编辑器,以探索沉浸式创作体验。其适用于需求编写、架构文档等等文档场景,以加速软件开发中的多种角色的日常工作。
GitHub:https://github.com/unit-mesh/3b (项目还在 AI 体验设计阶段,还没有接入模型,如果大家有模型,欢迎自行接入和赞助)
在线预览:https://editor.unitmesh.cc/
引子

在过去的几个月里,我们一直在探索什么才是最好的 Copilot (副驾驶)型工具。在过程中,我们构建的 AutoDev 工具,也成为了目前最贴合 Copilot 定义的开源 AI 辅助 IDE 插件。围绕于开发人员的日常活动设计,借助生成式 AI 增强体验,以打造沉浸式的编码体验 。
而在日常工作中,写代码只是我们众多工作的一部分,我们还有大量的记录工作要做 —— 诸如需求文档、架构文档、开发文档等等。对于这些文档工作来说,也需要类似的 AI 辅助的沉浸式创作工具。
作为经常写作的人,以及多本技术书籍的作者,我一直在打造、并重新打造适合自己的编辑器:
基于 Electron 与微前端架构:Phodit (https://github.com/phodal/phodit)
基于 Rust 语言的知识管理工具:Quake(https://github.com/phodal/quake)
微信公众号 markdown 渲染工具:MD(https://github.com/phodal/md)
也因此我大抵算得上是这方面的半个专家。对于这个领域来说,问题域已经从一个写作工具,转变为:如何结合知识管理 + 智能增强 + 搜索增强,以构建更好的创作体验?
文本内容创作的不同 AI 场景

写稿,是我老婆的日常工作的一部分。然而他们的行业领域是越剧——一个传统戏剧剧种。很多时候她也想借AI的东风,但往往事与愿违:他们很难从 Bing、百度文心或者 ChatGPT 这一类生成式 AI 获得足够准确的专业知识。
AI 辅助写作:借助生成式 AI 启发内容
在从受众角度来编写内容时,ChatGPT 显示了非常良好的素质。但是呢,在结合生成式 AI 写作时,会出现一些莫名其妙的事实性问题:
越剧《新龙门客栈》是由浙江越剧团和浙江电视台联合制作的一部现代越剧电视剧,改编自著名导演李安的电影《卧虎藏龙》。这部电视剧于 2022 年 12 月在浙江卫视首播,引起了强烈的社会反响,收视率屡创新高,网络点击量超过 10 亿,成为了一部现象级的作品。
所以,在这时,我们只能参考它的写作基本逻辑。基于它的创作逻辑,再展开我们对于文化事业的思考。
AI 辅助写作:结合事实的上下文
为了避免如此多的专业性问题,我们往往可以借助搜索引擎来进行写作。现在有了类似于百度一言、 Bing 可以获得实时的网页结果,以构建更好的上下文的生成式 AI 工具。我们就能获得更好的事实性:
越剧《新龙门客栈》是一部由浙江小百花越剧院、百越文化创意有限公司和一台好戏极致演艺文化传播(上海)有限公司联合出品的新国风·环境式越剧。该剧于 2023 年 3 月 28 日在浙江杭州蝴蝶剧场首演。剧情讲述了明朝中叶,宦官专权,东厂总督曹少钦杀害兵部尚书杨宇轩,并想借追杀其后代的方法诱捕杨宇轩旧部周淮安……
于是,如我们所知的,在有了这个上下文之后,生成式 AI 们能生成更准确的事实。
AI 辅助写作:上下文与历史内容关联
几年前,诸如 Notion 这样的知识管理工具火爆不是没有原因的 —— 知识之间是有关联的。在编写文章时,为了做一些铺垫,我们需要一些历史材料作为上下文,诸如于文化自信自强:
越剧作为中国传统文化的重要组成部分,具有不可替代的文化价值。在创新发展的过程中,越剧必须坚持文化自信,发扬传统文化精髓,让观众在欣赏艺术的同时,感受到中国传统文化的魅力。
而取决于不同的背景和场合来说,这些 “史料” 是要结合不同场景来编写的。
AI 辅助写作:内容拼写与内容优化
最后,在我们构建了初稿之后,就需要查看是否有表达问题,以及一些领导意见来改进段落,以使得我们的内容更加的贴合发言人的想法。
所以,我们可以用不同的语气,让生成式 AI 帮我们优化一下内容:
最终,一旦初稿完成,我们便需审查其表达是否存在疏漏,并接纳领导的建议,以进一步优化内容,确保更符合发言人的意图。
而这一类的工作是非常繁琐的,并且反复。
AI 辅助的需求编写
回到软件开发领域中,相信大部分人的痛点在于:需求写得不清楚。前者不清晰就会导致后续的实现功能出问题,进而浪费大量的时间在需求的返工上。
在有了 AutoDev 的丰富开发经验,以及受限于国内外的模型、开源模型能力之后,对于需求工具的重点应该是:生成需求草稿之后,辅助需求细化过程。回顾 AutoDev 在编码上的功能和过程:
阅读和分析历史代码(可选)。
生成初步的骨架代码(可选)。
进行自动化代码补全。
生成自动化测试、文档。
重构和优化代码。
所以,当我们开发一个类似的需求编写工具时,就需要实现如下的功能:
历史需求澄清(可选)。从代码与发布文档等中,获得历史需求,作为功能特性的一部分。
草稿生成。生成贴合于内容的需求大纲。
细化子项。根据需求特性规范,生成不同子项所需要的内容,诸如流程图等。
优化需求。检查需求是否有遗漏等问题。
而这也意味着,和内容编写一样,我们需要将 AI 融合编写需求全生成周期之中。
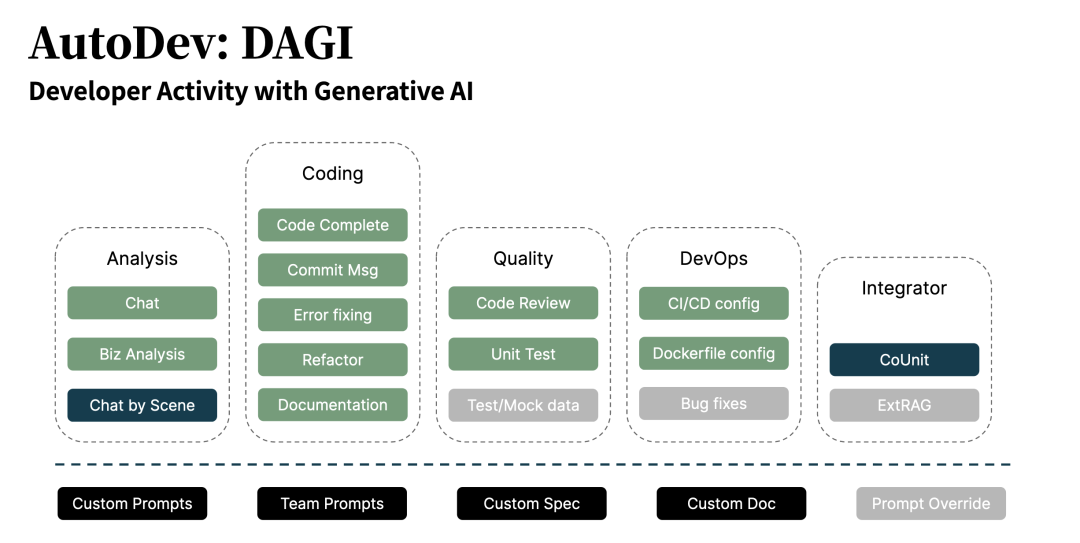
沉浸式 AI 的设计原则
在我们介绍了这么多上下文之后,我相信你也会和我保持一样的观点:和微软一样做 Copilot 型工具增强是最现实的。那么,我们应该怎么去考虑这个问题呢?
也因此,在我们从开发侧往需求侧移动时,考虑的第一个问题是:有没有更易于可扩展的编辑器?
3B 编辑器:重新思考 AI 编辑器
基于上述的思考,我们开始创建一个 “全新” 的内容编辑器 —— 当然是基于开源的编辑器作为基础。在设计这个编辑器时,我们参考了一系列已有的编辑器:
Notion。今年我写作时的主要工具,就是桌面版卡顿。
Jira AI。作为需求助手,Jira 展示了非常好的编辑体验。
Microsoft Word。世界上最知名的老牌编辑器。
其它一些 AI 编辑器。
以及我们在开发 AutoDev 时积累下来的一系列 AI IDE 相关(JetBrains AI Assistant、GitHub Copilot、Bloop、Cursor)的体验。既然,我们定义的 3B 是一个沉浸性的 AI 编辑器,那么必然让 AI 在这个编辑中触手可得,同时还能进行大量的自定义。
在当前的版本里 3B 编辑器里,主要关注于三点设计原则:
智能嵌入。将人工智能与用户界面深度融合,确保在编辑器的各个界面位置巧妙地引入 AI 模型,以实现更直观、智能的用户交互体验。
本地优化。通过引入本地推理模型,追求在用户本地环境下提供高效、流畅的写作体验。
上下文灵活性。通过上下文 API,赋予用户自定义 Prompt 和预定义上下文等工具,以便更灵活地塑造编辑环境。
可能还有其它忘记考虑的点。
原则 1. 智能嵌入
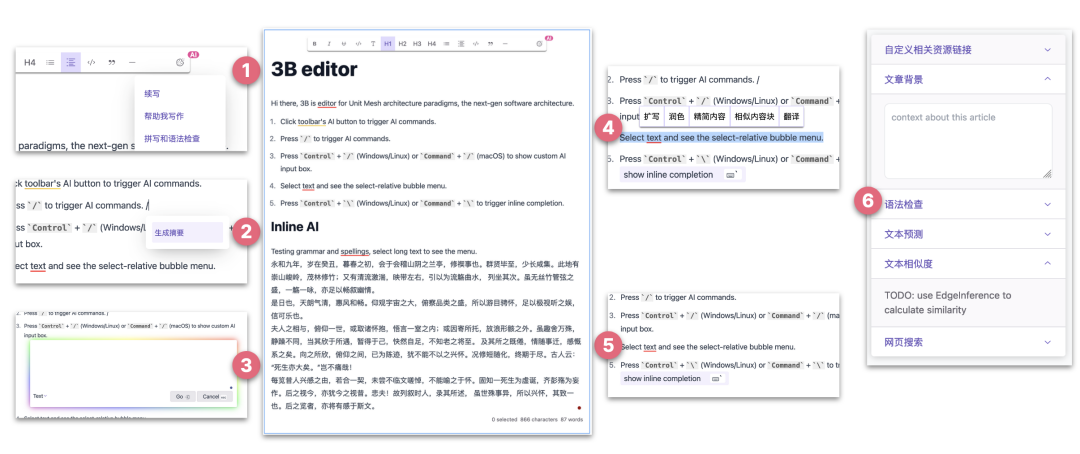
如我们在文档所述,致力于智能嵌入,为用户提供无缝的 AI 原生 UI 交互体验。以下是五种触发方式的 AI 增强写作:
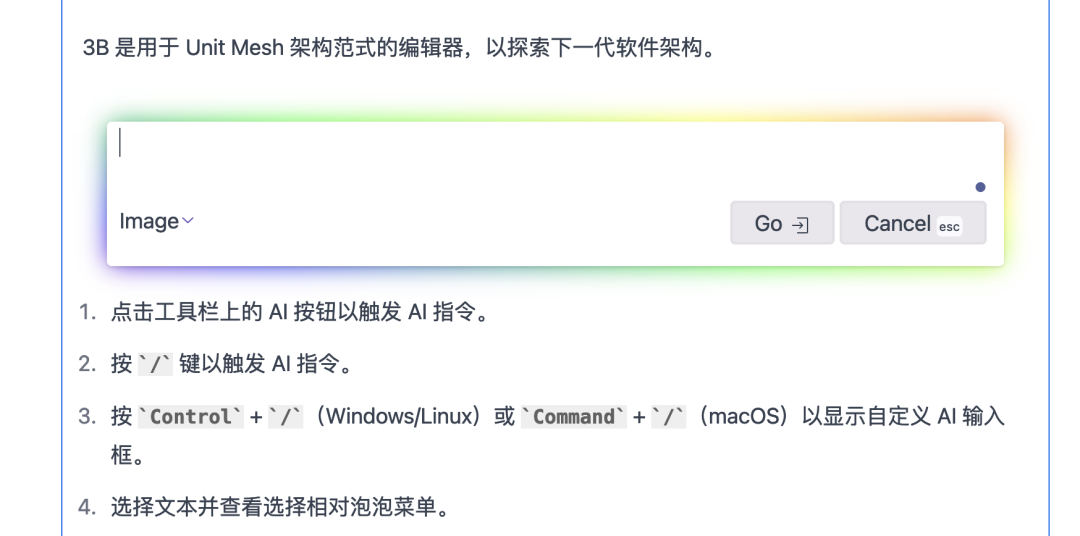
工具栏按钮触发: 通过点击工具栏上的专门设计的 AI 按钮,用户可以直观地触发 AI 指令,使得AI功能在编辑过程中更加直接可控。
快捷键触发: 用户可通过按下
/键,轻松触发AI指令,提供了一种快速且便利的方式来与AI进行交互。自定义输入框显示: 通过按下
Control+/(Windows/Linux)或Command+/(macOS),我们引入了自定义 AI 输入框,使用户能够更灵活地定制 AI 指令,增强了用户对 AI 的掌控感。文本选择泡泡菜单: 在选择文本的同时,用户可以方便地查看选择相对泡泡菜单,从而触发相应的AI功能,为用户提供了一种直观而智能的操作方式。
行内补全触发: 通过按下
Control+\(Windows / Linux)或Command+\,我们引入了行内补全的触发方式,提供更加细致和高效的AI功能操作。
随着本地推理能力的不断完善,编辑器将更加智能地自动触发更多高级AI功能,为用户带来更为自然和智能的写作体验。
原则 2. 本地优化
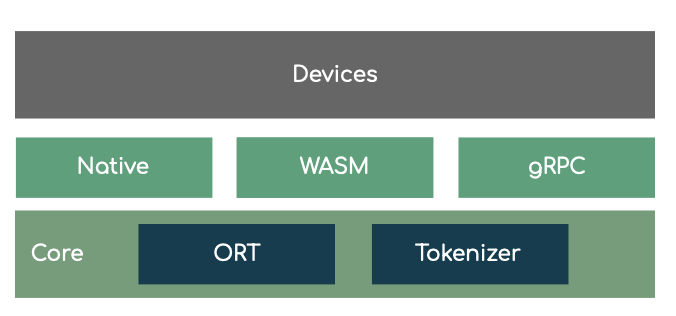
在上一篇文章《探索交互体验变革与边缘智能基础设施篇》里,介绍了我们看到的大模型在体积与速度上的一些趋势。因此,有必要优化考虑:本地(on-premise)模型优先与在本地(on-premise)的优化。这些优化的方式是多种多样的:
语义化搜索增强。既然历史文档是写作的关键部分,那么我们就需要在本地向量化,并进行相关的向量化搜索,如我们在《代码库 AI 助手的语义化搜索设计》所介绍的架构。
本地语法检查。这个功能已经很多了,相信大家都懂的。
文本预测。与编写代码相似,单行、多行的内容补全,对于写作来说也会有很好的提升 —— 问题在于要构建一个对应的小模型。
而这些内容,只是作为我们写作时的一些材料补充,方便于提供更多的上下文。
原则 3. 上下文灵活性

在 AutoDev 中,我们提供了强大的自定义能力,从适用于个人的自定义文档、规范,再到适用于团队的 Team Prompts。相似的,对于写作也是类似的,受限于不同的场景,人们所需要的 AI 能力是不同的。
上下文即变量。与 AutoDev 不同的是,3B 的所有上下文都是变量,即:
$beforeCursor,$afterCursor,$selection,$similarChunk,$relatedChunk,你可以用它来组合你的 prompt。自定义所有的 Prompt。在 3B 里,系统提供的 AI 功能,也只是一个配置信息,你可以覆盖它。
可扩展的变量(实现中)。写作需要一系列的补充信息,诸如背景信息、互联网资料,它应该作为上下文的一部分,发送给大模型。
通过这种灵活性,深度用户可以大大地控制 AI 的生成能力。
3B 是如何实现的?
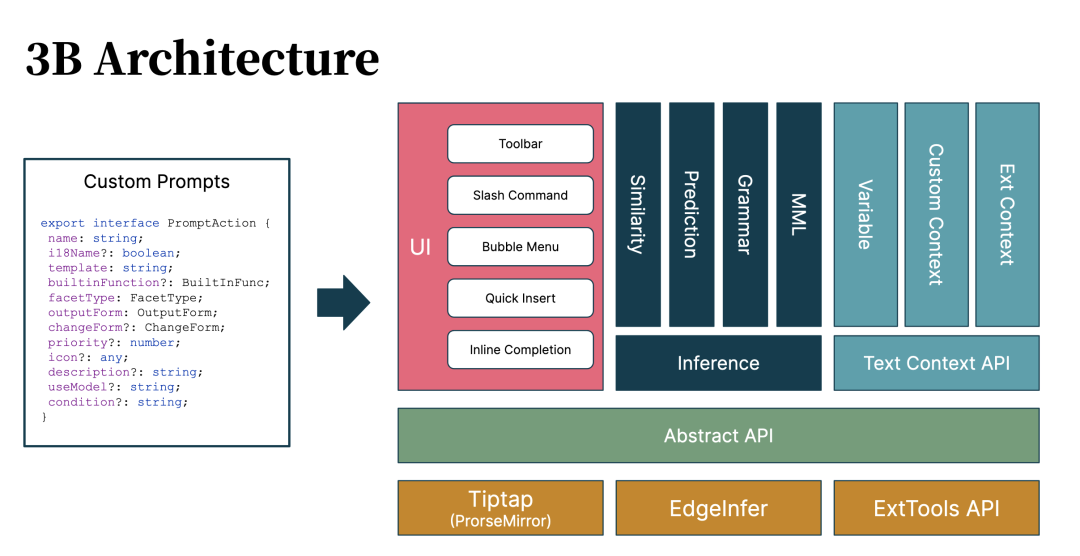
最后,让我们回到更有挑战性的技术部分。上述的一系列复杂度,也就导致了我们依然还在设计交互,而不是关注于如何快速接入 LLM 上线(PS:其实主要是没有足够的人来开发)。
技术选型
事实上,市面上已经有大量的 AI 编辑器,从选型上并没有太大的差异:
基础编辑器 ProseMirror、Tiptap:ProseMirror 提供了非常好的灵活性,让你可以自定义各种能力,并且有丰富的 AI 扩展组件。
本地推理 EdgeInfer :EdgeInfer 是我们使用 Rust + Onnx Runtime 构建的本地推理模型,以在浏览器、移动端、桌面等跨平台运行。
桌面端框架 Tauri:即可以充分利用 Rust 的基础设施,还可以在桌面端运行。
详细见我们的 Roadmap:https://github.com/unit-mesh/3b/issues/1 。
数据驱动的上下文
由于,我们只需要与 AI 和编辑器交互,所以我们只需要抽象这两部分即可。那么,对应的实现方式就是通过数据结构作为 API 的抽象。如下所示:
{
name: 'Polish',
i18Name: true,
template: `You are an assistant helping to polish sentence. Output in markdown format. \n ###${DefinedVariable.SELECTION}###`,
facetType: FacetType.BUBBLE_MENU,
outputForm: OutputForm.STREAMING,
}将系统的 AI 能力通过配置的方式来提供,就可以提供大量的灵活性。当然,这也意味着:系统的复杂度的上升。
在上述的示例配置里:
name 及 i18Name,决定了显示给用户的 AI 能力名称,及是否国际化。
template,包含了一系列的变量,以转换为 AI 的 prompt。
facetType,定义的与用户交互的类型,如工具栏、slash 菜单、bubble menu 等。
outputForm,即返回的内容应该如何输出。
当然了,还有其它的配置信息,以帮助开发人员更好地定制系统的能力。
其它
工具的指标
对于一个沉浸的 AI 工具来说,我们需要优化考虑的是考核指标。很多组织和团队将接受率作为工具的考试指标,但是它并没有那么合理 —— 接受率更多反应的是模型与 AI 工程的质量。在重度使用用户那里,接受率必然不低。作为沉浸式 AI 工具,使用频次是一个更好的指令 —— 即如何让 AI 更加顺手。如何将模型指标与工具指标分开?这是一个非常有意思的话题。
为什么叫 3B ?
因为:2B 青年,欢乐多。
总结
坑刚挖好,欢迎大家一起来贡献。
GitHub:https://github.com/unit-mesh/3b (项目还在 AI 体验设计阶段,还没有接入模型,如果大家有模型,欢迎自行接入和赞助)
在线预览:https://editor.unitmesh.cc/