C++11中提供的线程类std::thread,基于此类创建一个新的线程相对简单,只需要提供线程函数和线程对象即可
一.命名空间 this_thread
C++11 添加一个关于线程的命名空间std::this_pthread ,此命名空间中提供四个公共的成员函数;
1.1 get_id()
调用命名空间std::this_thread 中的 get_id() 方法可以得到当前线程ID:
示例如下:
#include <iostream>
#include <thread>
#include <mutex>
void func() {
std::cout << "子线程ID:" << std::this_thread::get_id() << std::endl;
}
int main() {
std::cout << "主线程ID:" << std::this_thread::get_id() << std::endl;
std::thread t1(func);
t1.join();
return 0;
}
1.2 sleep_for()
线程被创建出来之后有5中状态 创建态、就绪态、阻塞态、运行态、推出态 ;
线程和进程在使用时非常相识,在计算机中启动的多个线程都需要占用 CPU 资源,但是 CPU 的个数是有限的并且每个 CPU 在同一时间点不能同时处理多个任务。为了能够实现并发处理,多个线程都是分时复用CPU时间片,快速的交替处理各个线程中的任务。因此多个线程之间需要争抢CPU时间片,抢到了就执行,抢不到则无法执行(因为默认所有的线程优先级都相同,内核也会从中调度,不会出现某个线程永远抢不到 CPU 时间片的情况)。
命名空间 this_thread 中提供了一个休眠函数 sleep_for(),调用这个函数的线程会马上从运行态变成阻塞态并在这种状态下休眠一定的时长 ,因为阻塞态的线程已经让出了 CPU 资源,代码也不会被执行,所以线程休眠过程中对 CPU 来说没有任何负担;
示例:
#include <iostream>
#include <thread>
#include <mutex>
void func() {
for (size_t i = 0; i < 5; ++i){
std::this_thread::sleep_for(std::chrono::seconds(2));
std::cout << "子线程ID:" << std::this_thread::get_id() << std::endl;
}
}
int main() {
std::cout << "主线程ID:" << std::this_thread::get_id() << std::endl;
std::thread t1(func);
t1.join();
return 0;
}
在for循环中使用this_thread::sleep_for(chrono::seconds(2)); 后每次循环一次都会阻塞1s ,即每隔1s输出一次;注意: 程序休眠之后会从阻塞态变为就绪态,就绪态的线程需要再次抢夺CPU时间片,抢到之后会变成运行态,程序才能继续运行下去;
1.3 sleep_until
this_thread命名空间还提供另一个休眠函数 sleep_until ,和 sleep_for 有不同的参数类型;
sleep_until(): 指定线程阻塞到某一个时间点 time_point类型 ,之后解除;
sleep_for(): 指定线程阻塞一定的时间长度 duration类型 ,之后解除阻塞;
示例:
#include <iostream>
#include <thread>
#include <mutex>
void func() {
for (size_t i = 0; i < 5; ++i){
/* 获取当前的时间 */
auto current_time = std::chrono::system_clock::now();
/* 时间间隔 */
std::chrono::seconds sec(5);
/* 当前时间点后休眠5秒 */
std::this_thread::sleep_until(current_time + sec);
std::cout << "子线程ID:" << std::this_thread::get_id() << std::endl;
}
}
int main() {
std::cout << "主线程ID:" << std::this_thread::get_id() << std::endl;
std::thread t1(func);
t1.join();
return 0;
}
sleep_until 和 sleep_for 函数功能一样 ,前者基于时间点阻塞 ,后者基于时间段阻塞。
1.4 yield()
this_thread命名空间提供能主动由运行态退让出已经抢到时间片 的线程函数 yield() ,最终变为就绪态,这样其他线程就能抢到CPU时间片;
线程调用了 yield () 之后会主动放弃 CPU 资源,但是这个变为就绪态的线程会马上参与到下一轮 CPU 的抢夺战中,不排除它能继续抢到 CPU 时间片的情况。
示例:
#include <iostream>
#include <thread>
#include <mutex>
void func() {
for (size_t i = 0; i < 10000000; ++i){
std::this_thread::yield();
std::cout << "子线程ID:" << std::this_thread::get_id() << ",i = " << i << std::endl;
}
}
int main() {
std::cout << "主线程ID:" << std::this_thread::get_id() << std::endl;
std::thread t1(func);
std::thread t2(func);
t1.join();
t1.join();
return 0;
}
func() 中的 for 循环会占用大量的时间 ,在极端情况下,如果当前线程占用 CPU 资源不释放就会导致其他线程中的任务无法被处理,或者该线程每次都能抢到 CPU 时间片,导致其他线程中的任务没有机会被执行。解决方案就是每执行一次循环,让该线程主动放弃 CPU 资源,重新和其他线程再次抢夺 CPU 时间片,如果其他线程抢到了 CPU 时间片就可以执行相应的任务了。
注意:
yield() 的目的是避免一个线程长时间占用CPU资源,从而多线程处理能力下降;
yield() 是让当前线程主动放弃自己抢到的CPU资源,但是在下一轮还会继续抢;
二. C++ 线程类
2.2.1 join() 函数
在子线程对象中调用 join()函数,调用此函数的线程会被阻塞 ,但是子线程对象中的任务函数会继续执行 ,当任务执行完毕之后 join()函数会清理当前子线程中的相关资源后返回,同时该线程函数会解除阻塞继续执行下去。==函数在那个线程中被执行,函数就阻塞那个函数。
如果要阻塞主线程的执行,只需要在主线程中通过子线程对象调用这个方法即可,当调用这个方法的子线程对象中的任务函数执行完毕之后,主线程的阻塞也就随之解除了。
int main() {
std::cout << "主线程ID:" << std::this_thread::get_id() << std::endl;
std::thread t1(func);
std::thread t2(func);
t1.join();
t1.join();
return 0;
}
当主线程运行到t1.join() ; 根据子线程对象 t1 的任务函数 func() 的执行情况,主线程会:
任务函数 func() 还没执行完毕,主线程阻塞直到任务执行完毕,主线程解除阻塞,继续向下执行
任务函数 func() 执行完毕,主线程不会阻塞 ,继续向下运行。
2.2.2 detach() 函数
detach() 函数的是进行线程分离 ,分离主线程和子线程。在线程分离之后,主线程退出也会销毁创建的所有子线程,在主线程推出之前,子线程可以脱离主线程继续独立运行,任务结束完毕之后,这个子线程会自动释放自己占用的系统资源。
#include <iostream>
#include <thread>
#include <mutex>
void func() {
for (size_t i = 0; i < 5; ++i){
auto current_time = std::chrono::system_clock::now();
std::chrono::seconds sec(1);
std::this_thread::sleep_until(current_time + sec);
std::cout << "i = " << i << std::endl;
}
}
void func1(int num) {
for (size_t i = 0; i < 5; ++i) {
std::cout << "num: = " << num << std::endl;
}
}
int main() {
std::cout << "主线程ID:" << std::this_thread::get_id() << std::endl;
std::thread t1(func);
std::thread t2(func1, 111);
std::cout << "线程t1的线程ID:" << t1.get_id() << std::endl;
std::cout << "线程t2的线程ID:" << t2.get_id() << std::endl;
/* 线程分离 */
t1.detach();
t2.detach();
/* 主线程等待子线程执行完毕 */
std::this_thread::sleep_for(std::chrono::seconds(5));
return 0;
}
注意:线程分离函数 detach () 不会阻塞线程,子线程和主线程分离之后,在主线程中就不能再对这个子线程做任何控制了,比如:通过 join () 阻塞主线程等待子线程中的任务执行完毕。
2.2.3 joinable() 函数
joinable() 函数用于判断主线程和子线程是否处于关联(连接)状态,通常情况下两者处于关联状态,该函数返回一个布尔类型:
返回 true : 主线程和子线程有关联;
返回 false 主线程和子线程没有关联;
#include <iostream>
#include <thread>
#include <mutex>
void func() {
std::this_thread::sleep_for(std::chrono::seconds(2));
}
int main() {
std::thread t1;
std::cout << "before starting, joinable: " << t1.joinable() << std::endl;
t1 = std::thread(func);
std::cout << "after starting, joinable: " << t1.joinable() << std::endl;
t1.join();
std::cout << "after joining, joinable: " << t1.joinable() << std::endl;
std::thread t2(func);
std::cout << "after starting, joinable: " << t2.joinable() << std::endl;
t2.detach();
std::cout << "after detaching, joinable: " << t2.joinable() << std::endl;
return 0;
}
打印结果:
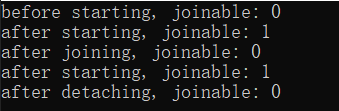
结论:
1.创建子线程对象时,如果没有指定任务函数,那么子线程不会启动,主线程和子线程也不会进行连接;
2.创建子线程对象时,如果指定任务函数,子线程启动并执行任务,主线程和子线程自动连接成功;
3.子线程调用detach()函数后,父子线程分离,两者的连接断开,调用joinable()返回 fasle;
4.子线程调用 join()函数后,子线程中的任务函数继续执行,知道任务处理完毕,此时join()清理回收当前线程的相关资源,此时子线程和主线程连接断开了,此时调用join()函数之后再调用joinable()返回false。
三.C++ 线程同步
进行多线程编程,如果多个线程需要对同一块内存进行操作,如:同时读、同时写、同时读写 对后两种情况而言如果不做任何的人为干涉会出现各种错误数据。这是因为线程在运行的时候需要先得到 CPU 时间片,时间片用完之后需要放弃已获得的 CPU 资源,就这样线程频繁地在就绪态和运行态之间切换,更复杂一点还可以在就绪态、运行态、挂起态之间切换,这样就会导致线程的执行顺序并不是有序的,而是随机的混乱的。
3.1互斥锁
解决多线程数据混乱的方案就是进行线程同步,最常用的是互斥锁 ,在C++11 中提供了四种互斥锁:
1.std::mutex : 独占的互斥锁,不能递归使用;
2.std::timed_mutex: 带超时的独占互斥锁,不能递归使用;
3.std::recursive_mutex: 递归互斥锁,不带超时功能;
4.std::recursive_timed_mutex : 带超时的递归互斥锁;
3.1.1 std::mutex
独占互斥锁对象有两种状态:锁定和未锁定
如果互斥锁是打开的,调用 lock() 函数的线程会得到互斥锁的所有权,并将其上锁。其他线程再调用该函数时由于得不到互斥锁的所有权,就会被 lock()函数阻塞。
当拥有互斥锁所有权的线程将互斥锁解锁 ,此时被 lock() 阻塞的线程解除阻塞 ,抢到互斥锁所有权的线程加锁成功并继续开锁,没抢到互斥锁所有权的线程继续阻塞;
还可以使用 try_lock() 获取互斥锁的所有权并对互斥锁加锁:
和 lock()的区别在于 ,try_lock()不会阻塞线程,lock()会阻塞线程:
如果互斥锁是未锁定状态,得到了互斥锁所有权并加锁成功,函数返回 true;
如果互斥锁是锁定状态,无法得到互斥锁所有权加锁失败,函数返回 false;
互斥锁被锁定之后可以通过 unlock()进行解锁,但是需要注意:只有拥有互斥锁所有权的线程(对互斥锁上锁的线程)才能将其解锁,其他线程没有权限做这件事;
使用互斥锁进行线程同步的流程:
1.找到多个线程操作的共享资源(全局变量、堆内存、类成员变量),成为临界资源 ;
2.找到共享资源相关的上下文代码,即临界区
3.再临界区的上边调用互斥锁类的 lock() 方法;
4.再临界区的下边调用互斥锁类的 unlock() 方法;
线程同步的目的:使多线程按照顺序依次进行执行临界区代码,对共享资源的访问从并行访问变成线性访问,访问效率降低了但是保证了数据的正确性;
当线程对互斥锁对象加锁,并且执行完临界区代码之后,一定要使用这个线程对互斥锁解锁,否则最终会造成线程的死锁。死锁之后当前应用程序中的所有线程都会被阻塞,并且阻塞无法解除,应用程序也无法继续运行。
#include <iostream>
#include <thread>
#include <mutex>
int g_number = 0;
std::mutex g_mtx;
void func(int id) {
for (size_t i = 0; i < 5; ++i) {
g_mtx.lock();
g_number++;
std::cout << "id:" << id << " number =" << g_number << std::endl;
g_mtx.unlock();
std::this_thread::sleep_for(std::chrono::seconds(2));
}
}
int main() {
std::thread t1(func, 0);
std::thread t2(func, 1);
t1.join();
t2.join();
return 0;
}
注意:
1.在所有线程的任务函数执行完毕之前,互斥锁对象是不能被析构的,一定要在程序中保证对象的可用性;
2.互斥锁的个数和共享资源的个数相等,每一个共享资源对应一个互斥锁对象,与线程数无关;
3.1.2 std::lock_guard
lock_guard 是C++11新增的一个模板类,可以简化互斥锁 lock()和unlock()的写法,同时也更安全。
void func(int id) {
for (size_t i = 0; i < 5; ++i) {
std::lock_guard<std::mutex> lock_mtx(g_mtx);
g_number++;
std::cout << "id:" << id << " number =" << g_number << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(2));
}
}
lock_guard 在使用构造函数构造对象时,会自动锁定互斥量,且在退出作用域后进行析构就会自动解锁,以保证互斥量的正确性,避免忘记 unlock() 而导致的线程死锁。
3.1.3 std::recursive_mutex
递归互斥锁: std::recursive_mutex 允许同一线程多次获得互斥锁,可以用来解决同一线程需要多次获取互斥量时的死锁问题 ,以下案例使用独占非递归互斥量会发生死锁:
#include <iostream>
#include <thread>
#include <mutex>
class Calculate
{
public:
Calculate() :m_num(2) {}
void mul(int x) {
std::lock_guard<std::mutex>lock(m_mutex);
m_num *= x;
}
void div(int x) {
std::lock_guard<std::mutex>lock(m_mutex);
m_num = m_num / x;
}
void both(int x, int y) {
std::lock_guard<std::mutex>lock(m_mutex);
mul(x);
div(x);
}
private:
int m_num;
std::mutex m_mutex;
};
int main() {
Calculate cal;
cal.both(3, 4);
return 0;
}
在执行到 cal.both(3,4); 调用之后程序会发生死锁,在 both() 中已经对互斥锁加锁了,继续调用 mult() 函数,已经得到互斥锁所有权的线程再次获取这个互斥锁的所有权便会造成死锁 (C++异常退出);使用递归互斥锁 std::recursive_mutex ,其允许一个线程多次获取互斥锁的所有权。
#include <iostream>
#include <thread>
#include <mutex>
class Calculate
{
public:
Calculate() :m_num(2) {}
void mul(int x) {
std::lock_guard<std::recursive_mutex>lock(m_mutex);
m_num *= x;
}
void div(int x) {
std::lock_guard<std::recursive_mutex>lock(m_mutex);
m_num = m_num / x;
}
void both(int x, int y) {
std::lock_guard<std::recursive_mutex>lock(m_mutex);
mul(x);
div(x);
}
private:
int m_num;
std::recursive_mutex m_mutex;
};
int main() {
Calculate cal;
cal.both(3, 4);
return 0;
}
总结:
递归互斥锁可以解决同一个互斥锁频繁获取互斥锁资源的问题,但是建议少用:
1.使用递归锁的场景往往可以都是简化的,使用递归锁可能会导致复杂逻辑产生,可能会导致bug产生;
2.互斥递归锁比非互斥递归锁效率低一些;
3.递归互斥锁虽运行同一个线程多次获取同一个互斥锁的所有权,但是最大使用次数未知,使用次数过多可能会抛出异常 std::system 错误;
3.1.4 std::timed_mutex
std::timed_mutex 是独占超时互斥锁 ,在获取互斥锁资源是增加一个超时等待功能 ,因为不知道获取锁资源需要等待多长时间,为了保证不一直等待下去,设置一个超时时长,超时后线程会解除阻塞做其他事情。
std::timed_mutex 比 std::mutex 多了两个成员函数:try_lock_for() 和 try_lock_until() :
1.try_lock_for 函数是当线程获取不到互斥锁资源之后,让线程阻塞一定的时间长度;
2.try_lock_until 函数是当线程获取不到互斥锁资源时,让线程阻塞到某一个时间点;
当两个函数返回值:当得到互斥锁所有权后,函数会马上解除阻塞 ,返回true ,如果阻塞的时长用完或达到某时间点后,函数会解除阻塞 ,返回false。
#include <iostream>
#include <thread>
#include <mutex>
std::timed_mutex g_mutex;
void func()
{
std::chrono::seconds timeout(2);
while (true)
{
/* 通过阻塞一定的时长来争取得到互斥锁所有权 */
if (g_mutex.try_lock_for(timeout)) {
std::cout << "当前线程ID: " << std::this_thread::get_id() << ", 得到互斥锁所有权..." << std::endl;
/* 模拟处理任务用了一定的时长 */
std::this_thread::sleep_for(std::chrono::seconds(10));
/* 互斥锁解锁 */
g_mutex.unlock();
break;
} else {
std::cout << "当前线程ID: " << std::this_thread::get_id() << ", 没有得到互斥锁所有权..." << std::endl;
/* 模拟处理其他任务用了一定的时长 */
std::this_thread::sleep_for(std::chrono::milliseconds(50));
}
}
}
int main() {
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
return 0;
}
关于递归超时互斥锁 std::recursive_timed_mutex 的使用方式和 std::timed_mutex 是一样的,只不过它可以允许一个线程多次获得互斥锁所有权,而 std::timed_mutex 只允许线程获取一次互斥锁所有权。另外,递归超时互斥锁 std::recursive_timed_mutex 也拥有和 std::recursive_mutex 一样的弊端,不建议频繁使用。
3.2 条件变量
C++11 提供了另一种用于等待的同步机制,能阻塞一个或多个线程,直到收到另一个线程发出的通知或超时时,才能唤醒当前阻塞的线程。条件变量需要和互斥量配合使用。
C++11 提供了两种条件变量:
condition_variable: 配合 std::unique_lock<std::mutex> 进行 wait 操作,也就是阻塞线程的操作;
conditon_variable_any : 可以和任意带有 lock() 、unlock()语义的 mutex 搭配使用,即存在四种:
1.std::mutex : 独占的非递归互斥锁;
2.std::timed_mutex: 带超时的独占非递归锁;
3.std::recursive_mutex: 不带超时功能的递归互斥锁;
4.std::recursive_timed_mutex: 带超时的递归互斥锁;
void Worker() {
std::unique_lock<std::mutex> lock(mutex);
// 等待主线程发送数据。
cv.wait(lock, [] { return ready; });
// 等待后,继续拥有锁。
std::cout << "工作线程正在处理数据..." << std::endl;
// 睡眠一秒以模拟数据处理。
std::this_thread::sleep_for(std::chrono::seconds(1));
data += " 已处理";
// 把数据发回主线程。
processed = true;
std::cout << "工作线程通知数据已经处理完毕。" << std::endl;
// 通知前,手动解锁以防正在等待的线程被唤醒后又立即被阻塞。
lock.unlock();
cv.notify_one();
}
int main() {
std::thread worker(Worker);
// 把数据发送给工作线程。
{
std::lock_guard<std::mutex> lock(mutex);
std::cout << "主线程正在准备数据..." << std::endl;
// 睡眠一秒以模拟数据准备。
std::this_thread::sleep_for(std::chrono::seconds(1));
data = "样本数据";
ready = true;
std::cout << "主线程通知数据已经准备完毕。" << std::endl;
}
cv.notify_one();
// 等待工作线程处理数据。
{
std::unique_lock<std::mutex> lock(mutex);
cv.wait(lock, [] { return processed; });
}
std::cout << "回到主线程,数据 = " << data << std::endl;
worker.join();
return 0;
}
主线程正在准备数据... 主线程通知数据已经准备完毕。 工作线程正在处理数据... 工作线程通知数据已经处理完毕。 回到主线程,数据 = 样本数据 已处理