一、概述
1、是什么
RAM++(RAM plus plus)论文全称 《Open-Set Image Tagging with Multi-Grained Text Supervision》。区别于图像领域常见的分类、检测、分割,他是标记任务——多标签分类任务(一张图片命中一个类别),区分于分类(一张图片命中一个类别)。然后他这里提到的Open-Set,需要注意,模型本身原始支持6449个标签(去掉同义词后4585个标签),但是可以通过GPT(后面会详细介绍)实现未知的标签(6449以外)识别。
如下是原生支持的6449个标签(去掉同义词后4585个标签)的官方地址,需要注意其中英文和中文是一一对应的,都是4585组。
原生支持的中文标签:https://github.com/xinyu1205/recognize-anything/blob/main/ram/data/ram_tag_list_chinese.txt
原生支持的英文标签:https://github.com/xinyu1205/recognize-anything/blob/main/ram/data/ram_tag_list.txt
2、亮点
1)集成图片-标记(属性识别)-文本(整图识别)到一个统一的对齐框架中,实现了强大的图片标记能力和Open set识别能力。
2)第一个集成了LLM的知识到图像Tag 的训练阶段,提升了模型推理阶段Open set 的能力。
3)在三个测试集(OpenImages, ImageNet, HICO)上超过了RAM 和 Tag2Text 以及 CLIP,并且做了很多消融实验证明这种架构的高效性;
-)同RAM:可较低成本复现,使用的都是开源和免人工标记的数据集(有部分自己标注的数据),最强版本的RAM(14M)也只需要8卡A100训练3天;
-)同RAM:灵活并且可以满足各种应用场景:可以单独使用作为标记系统;也可以结合Grounding DINO 和SAM 多标签分割。
3、对比RAM的提升
* 文本不再用可学习的query,改成了GPT写的句子,然后用CLIP 文本编码器编码(训练&测试)
* 整个句子的损失不在是生成损失,变为了ASL损失,整个模型进行了精简。
RAM 的Image Tag recognize decoder 和 RAM ++ 的alignment decoder 几乎是参数量、结构啥相同。
PS
*这篇来自OPPO的论文,写的相对真的很详细,有任何细节疑问可以参考论文
*论文中不含的数据部分细节需要配合RAM论文《Recognize Anything: A Strong Image Tagging Model》
*论文中不含的其余细节也在本博客末尾写到作为后续待解决项
二、模型
1、整体模型结构
包括三个部分:Image encoder、Text encoder、 alignment decoder,如下图。
* Image encoder 是 swin transformer, 这里作者最终用的是swin-base,RAM 最终用的swin-large,并且作者也做了消融实验。参数是在ImageNet 上pre-train过的然后参数会再训练中被更新。
*Text encoder 是CLIP 的 Text encoder, 权重也是CLIP 的原始权重并且在整个RAM ++ 的pre-train 和fine tune阶段参数不更新。
*alignment decoder 是 2层的transformer,权重对于文本和Tag 是共享的,里面的cross attention的query 是整个句子的CLIP 编码(对于图片的描述是一个句子,对于Tag,后面会讲,是利用GPT讲单个词汇如cat 描述成了句子)value 和 key 是Image encoder 的编码结果。
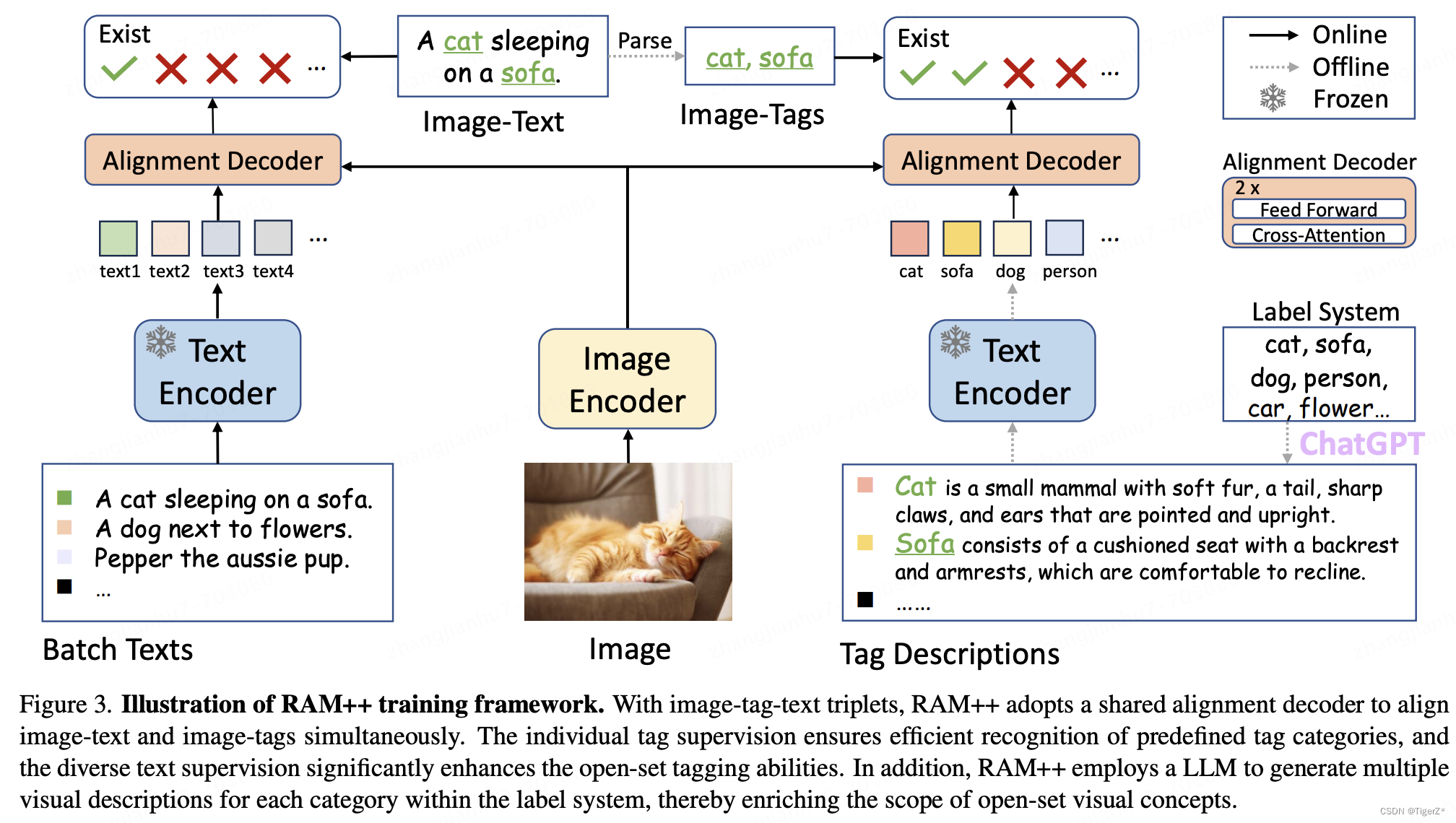
2、alignment decoder 注意点
虽然对于整句文本和Tag alignment decoder 是共享参数,但是由于Tag 的增广问题,就是作者一个Tag 生成了50个句子,那么怎么处理这50个句子,作者加了一个自动学习权重的子模块来给每个句子增加权重,然后再正常操作,具体来讲,可以参考右边的论文段落:
*将Tag 用GPT生成50个句子的文本编码器输出经过一个全连接层投射到指定维度(这样才能和视觉特征点乘得到一个标量数字);
*将图像编码器输出的全局特征经过一个全连接层投射到指定维度(这样才能和文本特征点乘得到一个标量数字);
*将上述投射后的1个图像特征与50个文本特征点乘得到50个数字,经过一个可学习的缩放系数t 后,通过计算sortmax归一化;
*将上一步归一化的50个值作为权重分别加权到50个未投影的文本编码器输出上,并求和得到一个未投影的文本编码特征值;
* 此时的文本编码值作为query,图像编码器的value、key 来正常的经过两层的transformer。


三、数据
RAM++ 的数据部分和RAM是几乎相同的,唯一不同是对于属性的处理,见后面数据清洗部分。数据都是三元组的形式:图像、属性、整图描述,格式可以参考官方链接如下:
GitHub - xinyu1205/recognize-anything: Open-source and strong foundation image recognition models.
1、数据标签
见RAM相关部分
2、数据构成
见RAM相关部分
3、数据清洗
见RAM相关部分
不同的点是Tag的处理。
RAM:训练阶段直接将属性作为了可学习的参数表示。推理阶段支持的类目直接输出结果,不支持的类目是使用一些作者定义的模板将类目单词组成很多句子然后用CLIP 文本编码器编码,然后进行求平均来当做这个单词的特征替代可学习参数,这里说一下另一点就是在训练过程中作者也特别实用了CLIP 的image encoder 进行蒸馏 RAM 的image encoder ,这其实相当于为这里的open set 使用CLIP Text encoder 作了文本和图片的特征对齐,作者的实验也显示提高了模型的性能。总结就是对于支持的类别训练和推理时一致的,对于不支持的类别训练和推理是有gap的,并且支持类别和自定义二选一。CLIP模板:https://github.com/xinyu1205/recognize-anything/blob/main/ram/utils/openset_utils.py#L24
RAM++ :训练阶段是通过GPT对每个属性生成50个句子,然后用CLIP文本编码器编码成50条特征然后加权成1条特征。推理阶段支持的类别一样,不支持的类别操作相同只不过需要你自己再去重新调用GPT生成一次描述,而且同样存在支持类别和自定义二选一问题。prompt如下:
llm_prompts = [ f"Describe concisely what a(n) {tag} looks like:", \
f"How can you identify a(n) {tag} concisely?", \
f"What does a(n) {tag} look like concisely?",\
f"What are the identifying characteristics of a(n) {tag}:", \
f"Please provide a concise description of the visual characteristics of {tag}:"]4、消融结果
见RAM相关部分
四、策略
1、训练过程
数据同RAM(除了Tag 产生部分),使用的是RAM的过程清洗出的数据。
如上模型结构图,还要注意Image encoder和alignment decoder 更新权重,tex encoder 冻结权重,Tag 的GPT 增强部分是离线处理,其余是在线处理。
细节可以参考论文的“ More Implementation Details ”章节,分为 Pre-traian 和 finetune 两步:
1) pre-train
epoch=5、bs=720、AdamW、weight decay=0.05、Image size=224 × 224、learning rate warmed-up 到 1e−4 3000 iterations 然后 linear decay= 0.9
2) Finetune
epoch=1、Image size=384 × 384、learning rate= 5e−6、并且使用了CLIP 的图像编码器进行蒸馏图像特征(充分利用于原始的图像文本对齐属性)
PS: bs 、优化器等论文没有写
Pre-traian 和 finetune 步骤:GitHub - xinyu1205/recognize-anything: Open-source and strong foundation image recognition models.
Pre-traian 配置参数:https://github.com/xinyu1205/recognize-anything/blob/main/ram/configs/pretrain.yaml
finetune 配置参数:https://github.com/xinyu1205/recognize-anything/blob/main/ram/configs/finetune.yaml
PS:如果默认类目不支持,需要生成你自己的描述。 并且需要修改标签列表和类别数等。
2、推理过程
没有左侧的Text encoder 分支,Tag 的GPT 增强部分是离线处理。
推理分两种情况:模型支持的属性类别和不支持的。
1)模型支持的属性
可以先查看自己想要的类目是否支持,然后调取接口即可。
中文支持标签: https://github.com/xinyu1205/recognize-anything/blob/main/ram/data/ram_tag_list_chinese.txt
英文支持标签: https://github.com/xinyu1205/recognize-anything/blob/main/ram/data/ram_tag_list.txt
调用方法:GitHub - xinyu1205/recognize-anything: Open-source and strong foundation image recognition models.
2)模型不支持的属性
这时候就需要你调用GPT3.5 turbo来生成你需要的属性对应的文本描述。然后用生成的描述来推理。分两步:
Step1:调用GPT3.5 turbo来生成你需要的属性对应的文本描述
Step2:用生成的描述来推理
PS:
* 你需要有GPT账号,建议3.5turbo,因为RAM++ 的训练描述也是GPT 3.5turbo生成,生成的其实就是50条描述,具体见后面数据章节。
* 默认你自定义Tag 和本来支持的Tag 不能同时输出,所以要么你输出两遍,要么把想要的所有Tag 都要重新描述(或者摘出来作者已有Tag 的描述)
* 官方的过程是反的:GitHub - xinyu1205/recognize-anything: Open-source and strong foundation image recognition models.
* 修改支持的类别本身就是一个字符串列表,自己在这个位置直接改为一个字符串列表就可以:
https://github.com/xinyu1205/recognize-anything/blob/main/generate_tag_des_llm.py#L56
categories = openimages_rare_unseen 改为 categories = [‘第一个属性’, ‘第二个属性’, '第三个属性']
3、消融对比
1)tag 描述
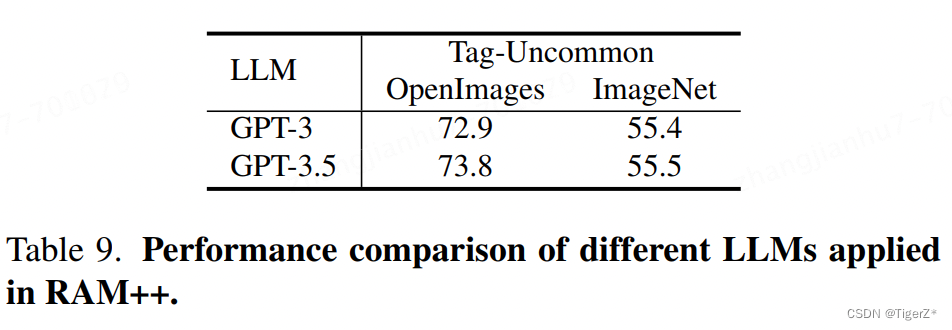
GPT3.5 turbo 好于GPT3;使用5个prompt * 每个生成10个描述 好于 直接让GPT生成50个。
2)模型&数据
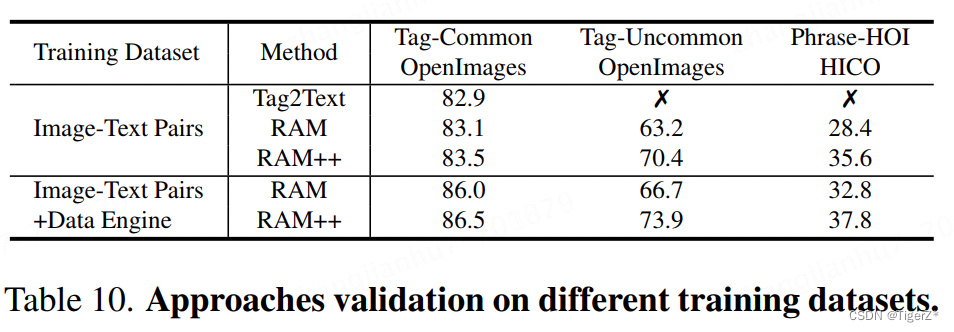
*在4M未经过RAM 的data engine 清洗的数据上,在支持的类别上几乎等价,重点是不支持的类别上RAM++ 提升大。
*data engine 也主要是提升了开放集合上的表现
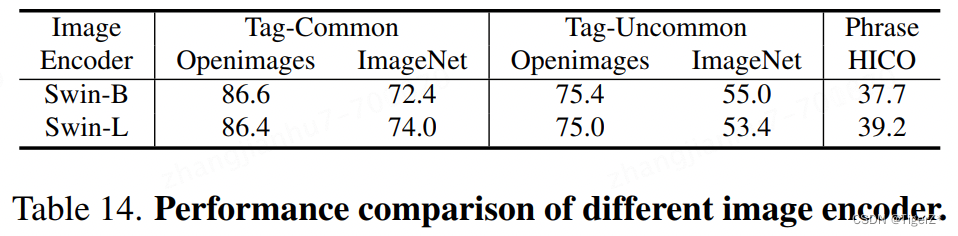
*在RAM++ 上,更大的swin-L 对比swin-B 却没有碾压性提升(支持类别提高,不支持类别反而降低)
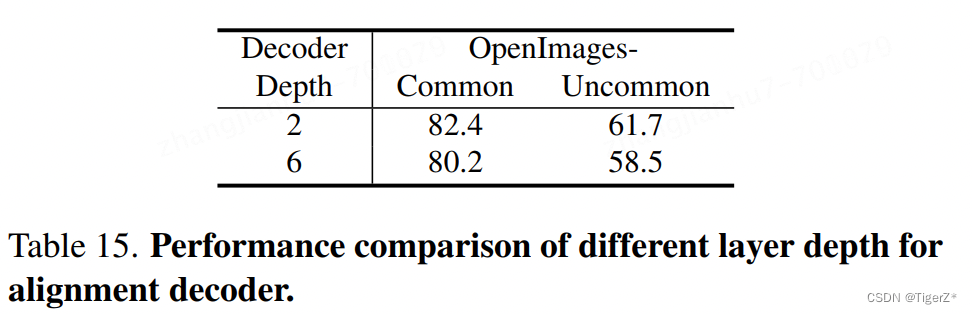
*alignment decoder 深度越深反而越差。
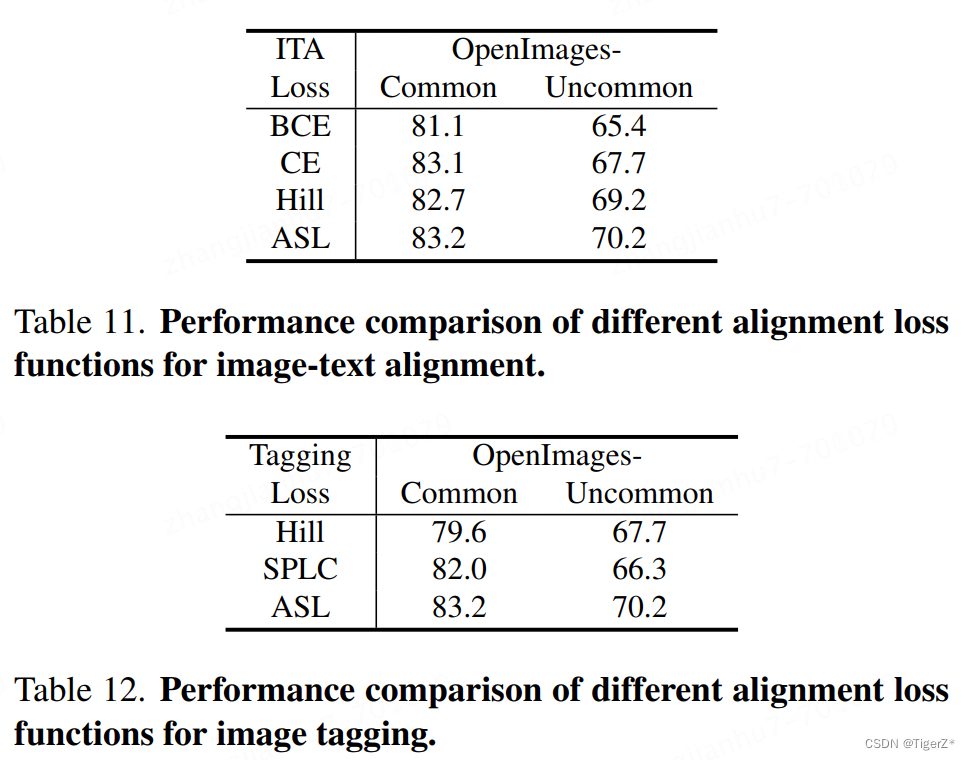
3)loss消融
显示ASL最好,但是其实ASL本身是很难调节的,并且官方也是建议逐步进化到ASL。
五、结果
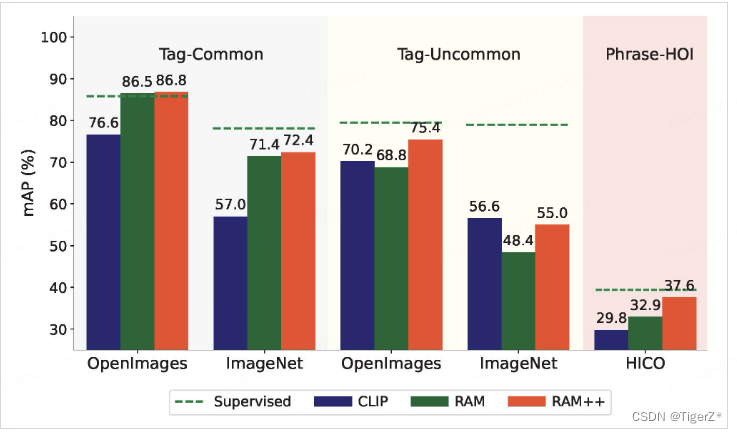
1、识别能力
RAM++ 在支持的4K类别和开放类别上都是最优,但是对于细粒度识别(Image Net和开放类别上均比不过监督学习的模型)。
2、分割能力
可以结合grounding dino 和 SAM, 分割一切,当然由于识别能力强,分割也就强于Tag2Text和RAM。

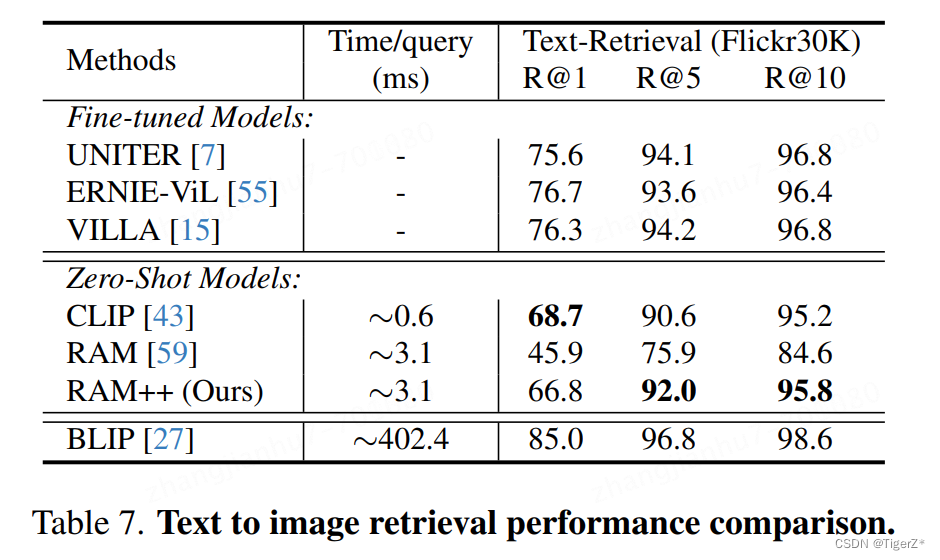
3、图文检索能力(文本检索图像)
综合推理速度和精召,CLIP任然最好;具有性价比的是RAM++;BLIP最好但是最慢。
六、使用方法
无法链接hugging face:
1、离线下载
下载如下图,并保存到一个目录下如“bert_base_uncased”:https://huggingface.co/bert-base-uncased/tree/main

2、指定目录
修改 recognize-anything/ram/models/utils.py

3、运行
TRANSFORMERS_OFFLINE=1 python inference_ram.py --image images/1641173_2291260800.jpg --pretrained pretrained/ram_swin_large_14m.pth七、待解决
1、聚类的内容是什么?图像特征?
八、参考链接
GitHub - xinyu1205/recognize-anything: Open-source and strong foundation image recognition models.
pre-train 和 finetune 阶段,swin-transformer、CLIP text encoder和 tag embedding 都反传梯度吗,学习率也都是相同的吗? · Issue #124 · xinyu1205/recognize-anything · GitHub
https://arxiv.org/pdf/2310.15200.pdf
https://arxiv.org/pdf/2306.03514.pdf
RAM(recognize anything)—— 论文详解-CSDN博客
ASL: 多标签分类之非对称损失-Asymmetric Loss_asl loss-CSDN博客