代码学习总结(一)
这个系列的博客是记录下自己学习代码的历程,有来自平台上的,有来自笔试题回忆的,主要基于 C++ 语言,包括题目内容,代码实现,思路,并会注明题目难度,保证代码运行结果
1 最长公共前缀
简单 字典树 匹配
编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 “”。
示例输入输出 1:
输入:strs = [“flower”,“flow”,“flight”]
输出:“fl”
示例输入输出 2:
输入:strs = [“dog”,“racecar”,“car”]
输出:“”
解释:输入不存在公共前缀。
提示:
- 1 <= strs.length <= 200
- 0 <= strs[i].length <= 200
- strs[i] 如果非空,则仅由小写英文字母组成
思路解析:
- 把第一个字符串作为基准,然后把它和第二个进行匹配,把二者的公共前缀取出来
- 把基准替换为公共前缀,分别和其他的字符串进行比较,再把新的公共替换为基准
- 返回最终的基准
本地 debug 代码
#include <iostream>
#include <vector>
#include <string>
using namespace std;
string longestCommonPrefix(vector<string>& strs) {
if (strs.empty()) return "";
// 取第一个字符串作为基准
string prefix = strs[0];
// 从第二个字符串开始比较
for (int i = 1; i < strs.size(); ++i) {
int j = 0;
// 比较当前前缀和 strs[i] 的公共部分
while (j < prefix.size() && j < strs[i].size() && prefix[j] == strs[i][j]) {
++j;
}
// 截断前缀
prefix = prefix.substr(0, j);
// 如果公共前缀为空,直接返回
if (prefix.empty()) return "";
}
return prefix;
}
// 测试用例
int main() {
vector<string> strs1 = {"flower", "flow", "flight"};
vector<string> strs2 = {"dog", "racecar", "car"};
cout << "示例 1 输出: " << longestCommonPrefix(strs1) << endl; // 输出: "fl"
cout << "示例 2 输出: " << longestCommonPrefix(strs2) << endl; // 输出: ""
return 0;
}
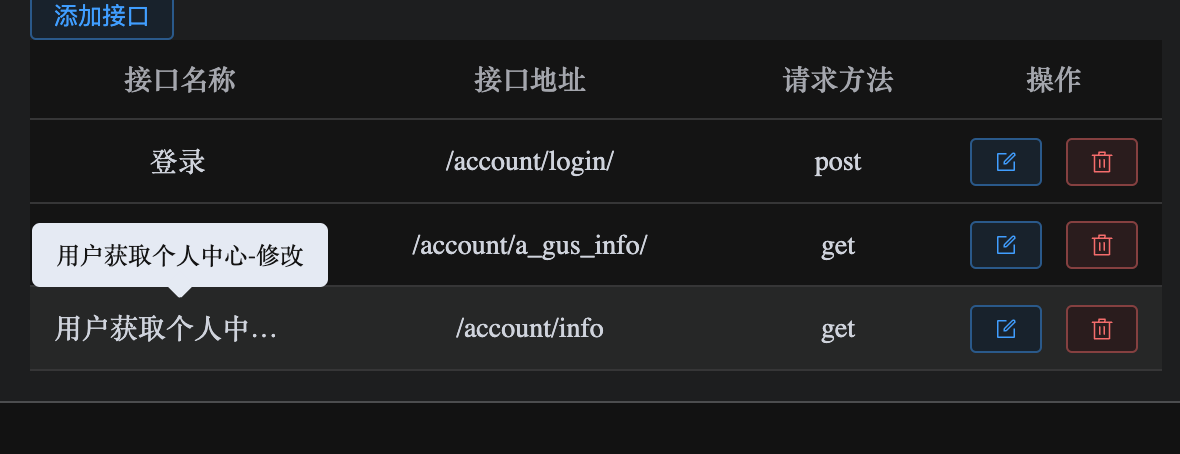
上述代码的运行结果为
 代码运行结果1
代码运行结果1
可用于提交的代码
string longestCommonPrefix(vector<string>& strs) {
if (strs.empty()) return "";
// 取第一个字符串作为基准
string prefix = strs[0];
// 从第二个字符串开始比较
for (int i = 1; i < strs.size(); ++i) {
int j = 0;
// 比较当前前缀和 strs[i] 的公共部分
while (j < prefix.size() && j < strs[i].size() && prefix[j] == strs[i][j]) {
++j;
}
// 截断前缀
prefix = prefix.substr(0, j);
// 如果公共前缀为空,直接返回
if (prefix.empty()) return "";
}
return prefix;
}
2 单词拆分 II
中等 字典树 单词拆分
给定一个字符串 s s s 和一个字符串字典 wordDict ,在字符串 s s s 中增加空格来构建一个句子,使得句子中所有的单词都在词典中。以任意顺序 返回所有这些可能的句子。
注意:词典中的同一个单词可能在分段中被重复使用多次。
示例输入输出 1:
输入: s = “catsanddog”, wordDict = [“cat”,“cats”,“and”,“sand”,“dog”]
输出: [“cats and dog”,“cat sand dog”]
示例 2:
输入: s = “pineapplepenapple”, wordDict = [“apple”,“pen”,“applepen”,“pine”,“pineapple”]
输出: [“pine apple pen apple”,“pineapple pen apple”,“pine applepen apple”]
解释: 注意你可以重复使用字典中的单词。
示例 3:
输入: s = “catsandog”, wordDict = [“cats”,“dog”,“sand”,“and”,“cat”]
输出 :[]
思路解析:
- 由于需要寻找同一个字符串在某个给定字典下所有可能的单词组合,所以最好是使用递归解决
- 而为了方便搜索,可以将给定字典转化为无序字典,并使用一个单独的字典用来存储已经搜索出的结果
- 这里的递归对象因为是一个字符串,所以可以从左开始搜索,拿到第一个成型的单词后,将右侧的部分作为新的对象,进行递归,然后把左侧的单词压入结果字典中
本地 debug 代码
#include <iostream>
#include <vector>
#include <string>
#include <unordered_set>
#include <unordered_map>
using namespace std;
class Solution {
public:
vector<string> wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> dict(wordDict.begin(), wordDict.end()); // 初始化无序集合
unordered_map<string, vector<string>> memo; // 初始化记忆化搜索
return dfs(s, dict, memo);
}
private:
vector<string> dfs(const string& s, unordered_set<string>& dict,
unordered_map<string, vector<string>>& memo) {
// 因为memo 是空的,所以如果 s 存在于这个空的变量中,它也是空的
if (memo.count(s)) return memo[s];
// 如果整个输入都存在于字典中,那直接返回
vector<string> result;
if (dict.count(s)) {
result.push_back(s);
}
// 针对字符串本身进行搜索
for (int i = 1; i < s.size(); ++i) {
string left = s.substr(0, i); // 往左搜索,字符的左侧部分
string right = s.substr(i); // 往右搜索,字符的右侧部分
if (dict.count(left)) { //如果左侧部分存在于字典中
vector<string> rightPart = dfs(right, dict, memo); // 递归对右侧部分进行处理
for (const string& sub : rightPart) {
result.push_back(left + " " + sub); // 将左侧部分和右侧部分都压入到结果中
}
}
}
memo[s] = result;
return result;
}
};
void printResults(const std::vector<std::string>& results) {
std::cout << "[";
for (size_t i = 0; i < results.size(); ++i) {
std::cout << "\"" << results[i] << "\"";
if (i != results.size() - 1) {
std::cout << ",";
}
}
std::cout << "]" << std::endl;
}
// 测试用例
int main() {
Solution sol;
string s1 = "catsanddog";
vector<string> wordDict1 = {"cat","cats","and","sand","dog"};
string s2 = "pineapplepenapple";
vector<string> wordDict2 = {"apple","pen","applepen","pine","pineapple"};
string s3 = "catsandog";
vector<string> wordDict3 = {"cats","dog","sand","and","cat"};
vector<string> results1 = sol.wordBreak(s1, wordDict1);
printResults(results1); // 输出: ["cats and dog","cat sand dog"]
vector<string> results2 = sol.wordBreak(s2, wordDict2);
printResults(results2); // 输出: ["pine apple pen apple","pineapple pen apple","pine applepen apple"]
vector<string> results3 = sol.wordBreak(s3, wordDict3);
printResults(results3); // 输出: []
return 0;
}
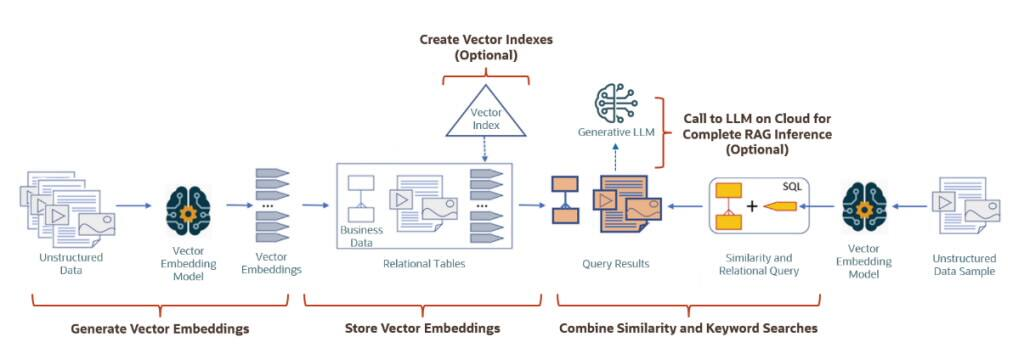
上述代码的运行结果为
 代码运行结果2
代码运行结果2
可用于提交的代码
class Solution {
public:
vector<string> wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> dict(wordDict.begin(), wordDict.end()); // 初始化无序集合
unordered_map<string, vector<string>> memo; // 初始化记忆化搜索
return dfs(s, dict, memo);
}
private:
vector<string> dfs(const string& s, unordered_set<string>& dict,
unordered_map<string, vector<string>>& memo) {
// 因为memo 是空的,所以如果 s 存在于这个空的变量中,它也是空的
if (memo.count(s)) return memo[s];
// 如果整个输入都存在于字典中,那直接返回
vector<string> result;
if (dict.count(s)) {
result.push_back(s);
}
// 针对字符串本身进行搜索
for (int i = 1; i < s.size(); ++i) {
string left = s.substr(0, i); // 往左搜索,字符的左侧部分
string right = s.substr(i); // 往右搜索,字符的右侧部分
if (dict.count(left)) { //如果左侧部分存在于字典中
vector<string> rightPart = dfs(right, dict, memo); // 递归对右侧部分进行处理
for (const string& sub : rightPart) {
result.push_back(left + " " + sub); // 将左侧部分和右侧部分都压入到结果中
}
}
}
memo[s] = result;
return result;
}
};
void printResults(const std::vector<std::string>& results) {
std::cout << "[";
for (size_t i = 0; i < results.size(); ++i) {
std::cout << "\"" << results[i] << "\"";
if (i != results.size() - 1) {
std::cout << ",";
}
}
std::cout << "]" << std::endl;
}
这里的题目是 leetcode 中的,感兴趣的同学们可以去提交下试试,可以直接运行通过,每日二题,努力加油😉!!!